 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DeltaSpace: A Semantic-aligned Feature Space for Flexible Text-guided Image Editing
Oct 12, 2023
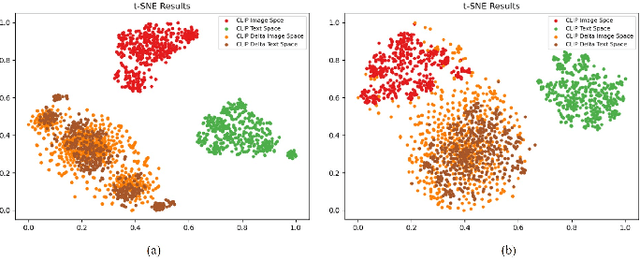
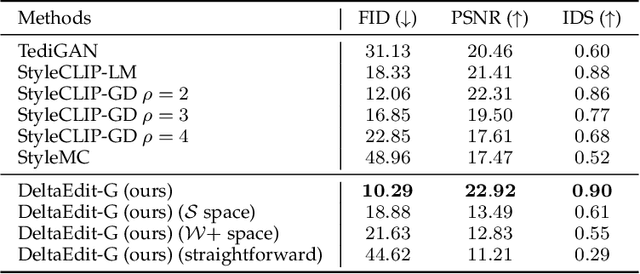


Text-guided image editing faces significant challenges to training and inference flexibility. Much literature collects large amounts of annotated image-text pairs to train text-conditioned generative models from scratch, which is expensive and not efficient. After that, some approaches that leverage pre-trained vision-language models are put forward to avoid data collection, but they are also limited by either per text-prompt optimization or inference-time hyper-parameters tuning. To address these issues, we investigate and identify a specific space, referred to as CLIP DeltaSpace, where the CLIP visual feature difference of two images is semantically aligned with the CLIP textual feature difference of their corresponding text descriptions. Based on DeltaSpace, we propose a novel framework called DeltaEdit, which maps the CLIP visual feature differences to the latent space directions of a generative model during the training phase, and predicts the latent space directions from the CLIP textual feature differences during the inference phase. And this design endows DeltaEdit with two advantages: (1) text-free training; (2) generalization to various text prompts for zero-shot inference. Extensive experiments validate the effectiveness and versatility of DeltaEdit with different generative models, including both the GAN model and the diffusion model, in achieving flexible text-guided image editing. Code is available at https://github.com/Yueming6568/DeltaEdit.
MeanAP-Guided Reinforced Active Learning for Object Detection
Oct 12, 2023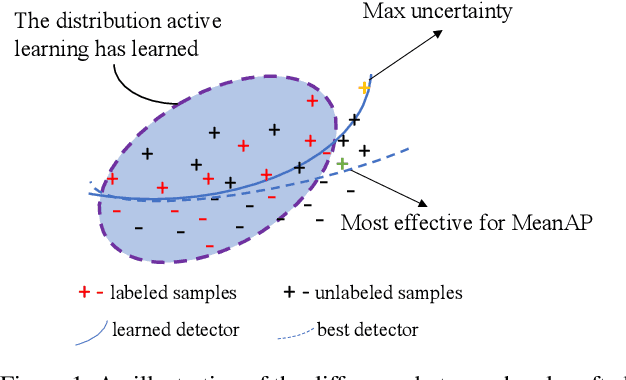
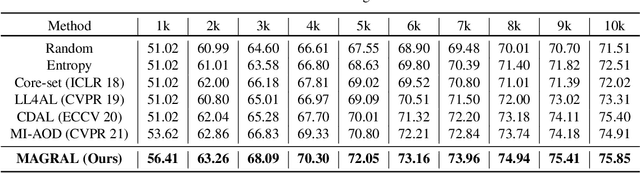
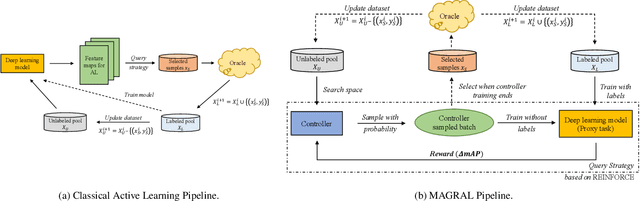
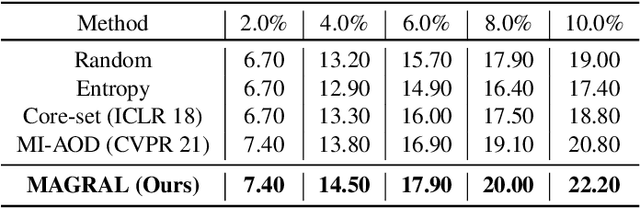
Active learning presents a promising avenue for training high-performance models with minimal labeled data, achieved by judiciously selecting the most informative instances to label and incorporating them into the task learner. Despite notable advancements in active learning for image recognition, metrics devised or learned to gauge the information gain of data, crucial for query strategy design, do not consistently align with task model performance metrics, such as Mean Average Precision (MeanAP) in object detection tasks. This paper introduces MeanAP-Guided Reinforced Active Learning for Object Detection (MAGRAL), a novel approach that directly utilizes the MeanAP metric of the task model to devise a sampling strategy employing a reinforcement learning-based sampling agent. Built upon LSTM architecture, the agent efficiently explores and selects subsequent training instances, and optimizes the process through policy gradient with MeanAP serving as reward. Recognizing the time-intensive nature of MeanAP computation at each step, we propose fast look-up tables to expedite agent training. We assess MAGRAL's efficacy across popular benchmarks, PASCAL VOC and MS COCO, utilizing different backbone architectures. Empirical findings substantiate MAGRAL's superiority over recent state-of-the-art methods, showcasing substantial performance gains. MAGRAL establishes a robust baseline for reinforced active object detection, signifying its potential in advancing the field.
Fast Word Error Rate Estimation Using Self-Supervised Representations For Speech And Text
Oct 12, 2023The quality of automatic speech recognition (ASR) is typically measured by word error rate (WER). WER estimation is a task aiming to predict the WER of an ASR system, given a speech utterance and a transcription. This task has gained increasing attention while advanced ASR systems are trained on large amounts of data. In this case, WER estimation becomes necessary in many scenarios, for example, selecting training data with unknown transcription quality or estimating the testing performance of an ASR system without ground truth transcriptions. Facing large amounts of data, the computation efficiency of a WER estimator becomes essential in practical applications. However, previous works usually did not consider it as a priority. In this paper, a Fast WER estimator (Fe-WER) using self-supervised learning representation (SSLR) is introduced. The estimator is built upon SSLR aggregated by average pooling. The results show that Fe-WER outperformed the e-WER3 baseline relatively by 19.69% and 7.16% on Ted-Lium3 in both evaluation metrics of root mean square error and Pearson correlation coefficient, respectively. Moreover, the estimation weighted by duration was 10.43% when the target was 10.88%. Lastly, the inference speed was about 4x in terms of a real-time factor.
Receive, Reason, and React: Drive as You Say with Large Language Models in Autonomous Vehicles
Oct 12, 2023The fusion of human-centric design and artificial intelligence (AI) capabilities has opened up new possibilities for next-generation autonomous vehicles that go beyond transportation. These vehicles can dynamically interact with passengers and adapt to their preferences. This paper proposes a novel framework that leverages Large Language Models (LLMs) to enhance the decision-making process in autonomous vehicles. By utilizing LLMs' linguistic and contextual understanding abilities with specialized tools, we aim to integrate the language and reasoning capabilities of LLMs into autonomous vehicles. Our research includes experiments in HighwayEnv, a collection of environments for autonomous driving and tactical decision-making tasks, to explore LLMs' interpretation, interaction, and reasoning in various scenarios. We also examine real-time personalization, demonstrating how LLMs can influence driving behaviors based on verbal commands. Our empirical results highlight the substantial advantages of utilizing chain-of-thought prompting, leading to improved driving decisions, and showing the potential for LLMs to enhance personalized driving experiences through ongoing verbal feedback. The proposed framework aims to transform autonomous vehicle operations, offering personalized support, transparent decision-making, and continuous learning to enhance safety and effectiveness. We achieve user-centric, transparent, and adaptive autonomous driving ecosystems supported by the integration of LLMs into autonomous vehicles.
Multi-Satellite Cooperative Networks: Joint Hybrid Beamforming and User Scheduling Design
Oct 12, 2023In this paper, we consider a cooperative communication network where multiple low-Earth-orbit satellites provide services for ground users (GUs) (at the same time and on the same frequency). The multi-satellite cooperative network has great potential for satellite communications due to its dense configuration, extensive coverage, and large spectral efficiency. However, the communication and computational resources on satellites are usually restricted. Therefore, considering the limitation of the on-board radio-frequency chains of satellites, we first propose a hybrid beamforming method consisting of analog beamforming for beam alignment and digital beamforming for interference mitigation. Then, to establish appropriate connections between the satellites and GUs, we propose a low-complexity heuristic user scheduling algorithm which determines the connections according to the total spectral efficiency increment of the multi-satellite cooperative network. Next, considering the intrinsic connection between beamforming and user scheduling, a joint hybrid beamforming and user scheduling (JHU) scheme is proposed to dramatically improve the performance of the multi-satellite cooperative network. In addition to the single-connection scenario, we also consider the multi-connection case using the JHU scheme. Moreover, simulations are conducted to compare the proposed schemes with representative baselines and to analyze the key factors influencing the performance of the multi-satellite cooperative network.
Volumetric Medical Image Segmentation via Scribble Annotations and Shape Priors
Oct 12, 2023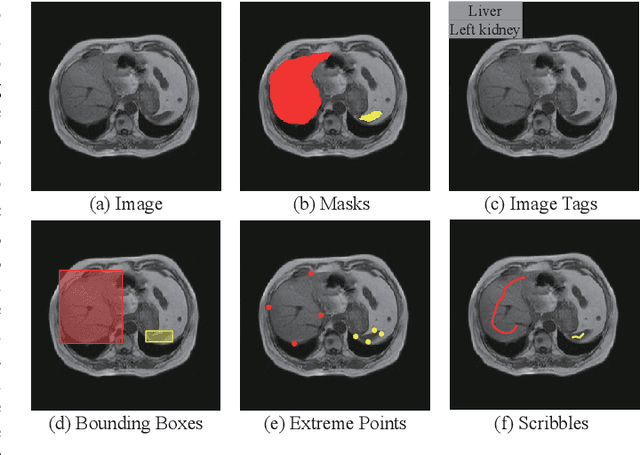
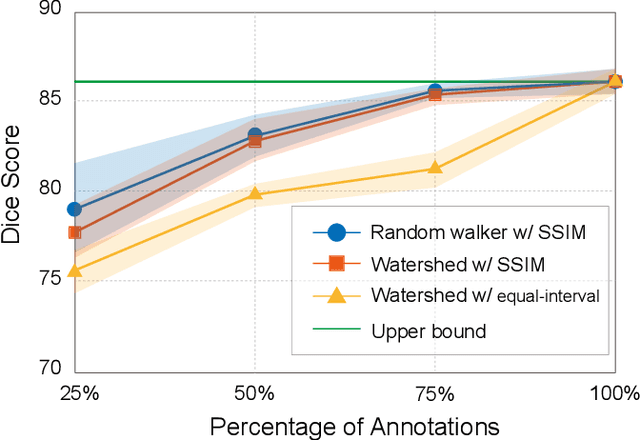
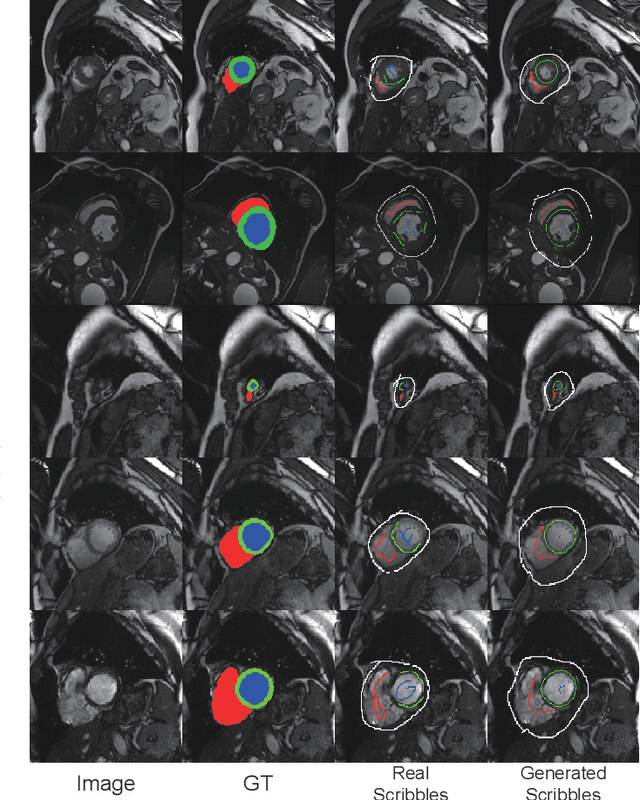
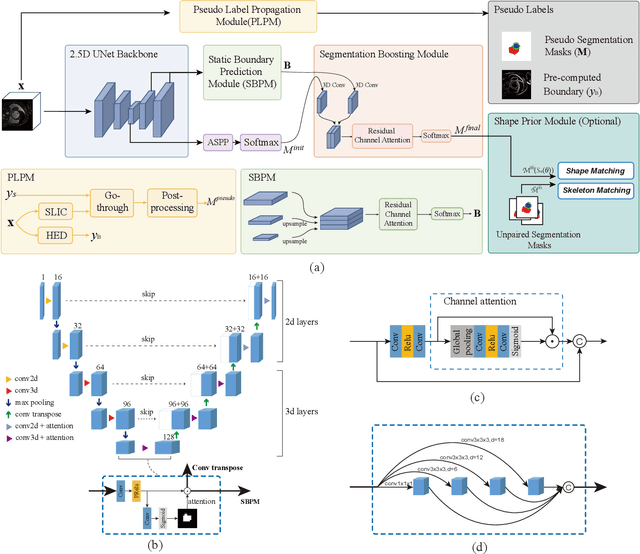
Recently, weakly-supervised image segmentation using weak annotations like scribbles has gained great attention in computer vision and medical image analysis, since such annotations are much easier to obtain compared to time-consuming and labor-intensive labeling at the pixel/voxel level. However, due to a lack of structure supervision on regions of interest (ROIs), existing scribble-based methods suffer from poor boundary localization. Furthermore, most current methods are designed for 2D image segmentation, which do not fully leverage the volumetric information if directly applied to each image slice. In this paper, we propose a scribble-based volumetric image segmentation, Scribble2D5, which tackles 3D anisotropic image segmentation and aims to its improve boundary prediction. To achieve this, we augment a 2.5D attention UNet with a proposed label propagation module to extend semantic information from scribbles and use a combination of static and active boundary prediction to learn ROI's boundary and regularize its shape. Also, we propose an optional add-on component, which incorporates the shape prior information from unpaired segmentation masks to further improve model accuracy. Extensive experiments on three public datasets and one private dataset demonstrate our Scribble2D5 achieves state-of-the-art performance on volumetric image segmentation using scribbles and shape prior if available.
End-to-end Online Speaker Diarization with Target Speaker Tracking
Oct 12, 2023This paper proposes an online target speaker voice activity detection system for speaker diarization tasks, which does not require a priori knowledge from the clustering-based diarization system to obtain the target speaker embeddings. By adapting the conventional target speaker voice activity detection for real-time operation, this framework can identify speaker activities using self-generated embeddings, resulting in consistent performance without permutation inconsistencies in the inference phase. During the inference process, we employ a front-end model to extract the frame-level speaker embeddings for each coming block of a signal. Next, we predict the detection state of each speaker based on these frame-level speaker embeddings and the previously estimated target speaker embedding. Then, the target speaker embeddings are updated by aggregating these frame-level speaker embeddings according to the predictions in the current block. Our model predicts the results for each block and updates the target speakers' embeddings until reaching the end of the signal. Experimental results show that the proposed method outperforms the offline clustering-based diarization system on the DIHARD III and AliMeeting datasets. The proposed method is further extended to multi-channel data, which achieves similar performance with the state-of-the-art offline diarization systems.
A Mass-Conserving-Perceptron for Machine Learning-Based Modeling of Geoscientific Systems
Oct 12, 2023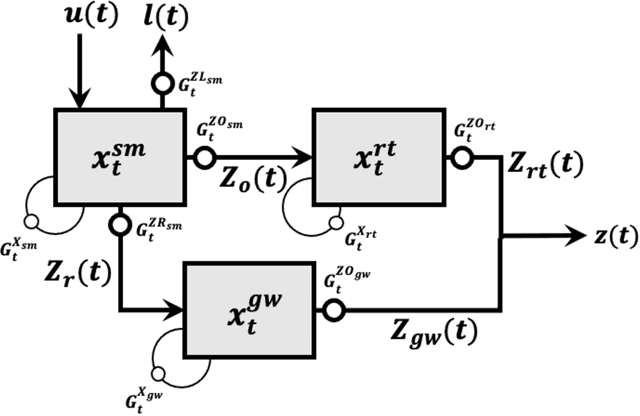
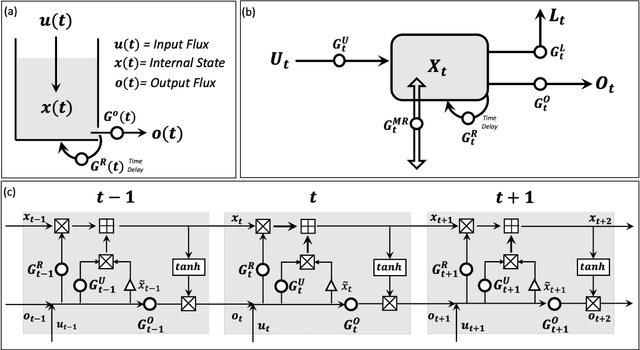
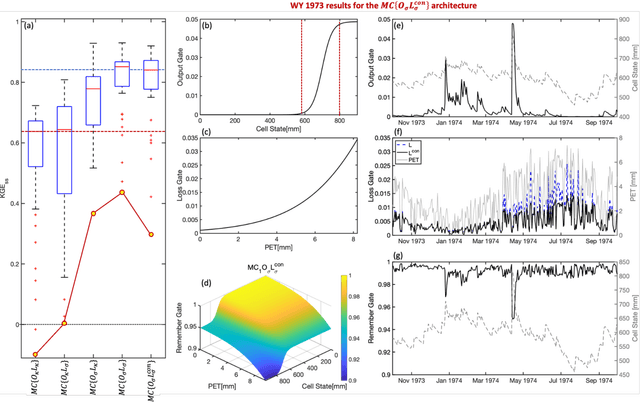
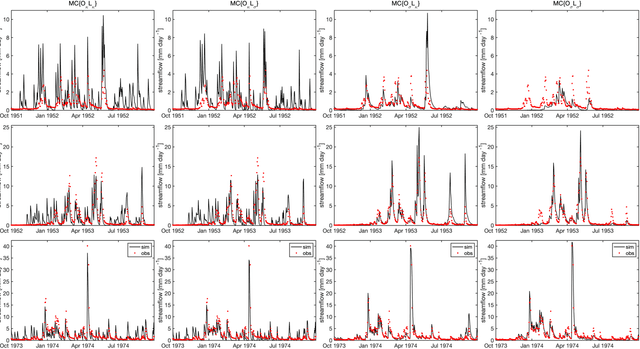
Although decades of effort have been devoted to building Physical-Conceptual (PC) models for predicting the time-series evolution of geoscientific systems, recent work shows that Machine Learning (ML) based Gated Recurrent Neural Network technology can be used to develop models that are much more accurate. However, the difficulty of extracting physical understanding from ML-based models complicates their utility for enhancing scientific knowledge regarding system structure and function. Here, we propose a physically-interpretable Mass Conserving Perceptron (MCP) as a way to bridge the gap between PC-based and ML-based modeling approaches. The MCP exploits the inherent isomorphism between the directed graph structures underlying both PC models and GRNNs to explicitly represent the mass-conserving nature of physical processes while enabling the functional nature of such processes to be directly learned (in an interpretable manner) from available data using off-the-shelf ML technology. As a proof of concept, we investigate the functional expressivity (capacity) of the MCP, explore its ability to parsimoniously represent the rainfall-runoff (RR) dynamics of the Leaf River Basin, and demonstrate its utility for scientific hypothesis testing. To conclude, we discuss extensions of the concept to enable ML-based physical-conceptual representation of the coupled nature of mass-energy-information flows through geoscientific systems.
Is ImageNet worth 1 video? Learning strong image encoders from 1 long unlabelled video
Oct 12, 2023
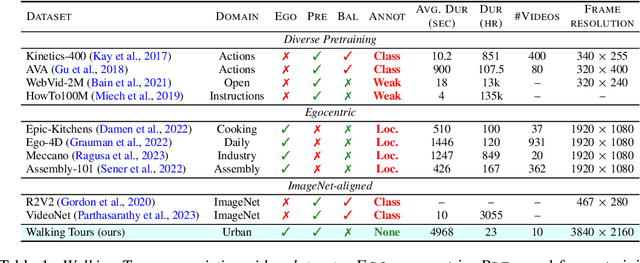
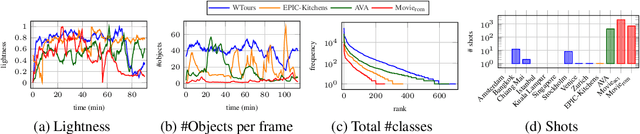
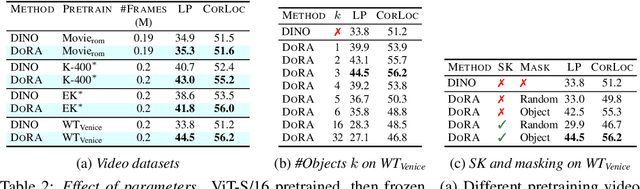
Self-supervised learning has unlocked the potential of scaling up pretraining to billions of images, since annotation is unnecessary. But are we making the best use of data? How more economical can we be? In this work, we attempt to answer this question by making two contributions. First, we investigate first-person videos and introduce a "Walking Tours" dataset. These videos are high-resolution, hours-long, captured in a single uninterrupted take, depicting a large number of objects and actions with natural scene transitions. They are unlabeled and uncurated, thus realistic for self-supervision and comparable with human learning. Second, we introduce a novel self-supervised image pretraining method tailored for learning from continuous videos. Existing methods typically adapt image-based pretraining approaches to incorporate more frames. Instead, we advocate a "tracking to learn to recognize" approach. Our method called DoRA, leads to attention maps that Discover and tRAck objects over time in an end-to-end manner, using transformer cross-attention. We derive multiple views from the tracks and use them in a classical self-supervised distillation loss. Using our novel approach, a single Walking Tours video remarkably becomes a strong competitor to ImageNet for several image and video downstream tasks.
Baird Counterexample is Solved: with an example of How to Debug a Two-time-scale Algorithm
Sep 02, 2023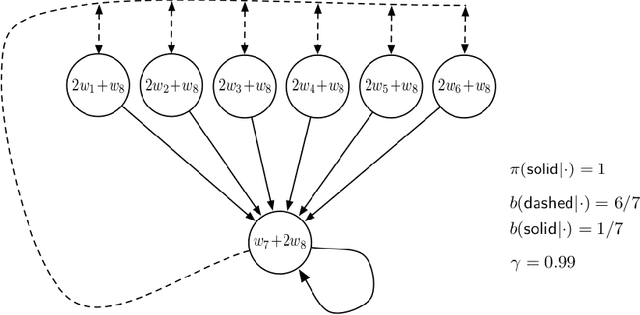
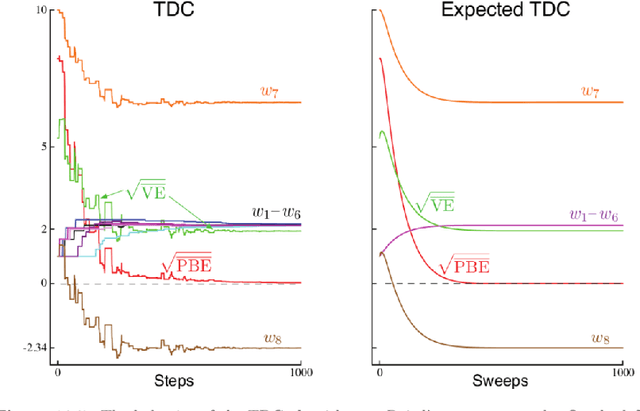
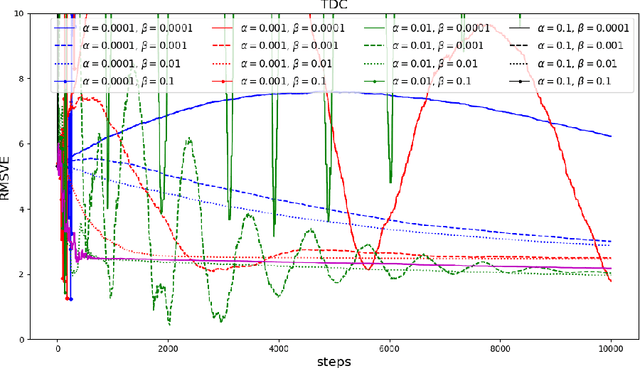
Baird counterexample was proposed by Leemon Baird in 1995, first used to show that the Temporal Difference (TD(0)) algorithm diverges on this example. Since then, it is often used to test and compare off-policy learning algorithms. Gradient TD algorithms solved the divergence issue of TD on Baird counterexample. However, their convergence on this example is still very slow, and the nature of the slowness is not well understood, e.g., see (Sutton and Barto 2018). This note is to understand in particular, why TDC is slow on this example, and provide a debugging analysis to understand this behavior. Our debugging technique can be used to study the convergence behavior of two-time-scale stochastic approximation algorithms. We also provide empirical results of the recent Impression GTD algorithm on this example, showing the convergence is very fast, in fact, in a linear rate. We conclude that Baird counterexample is solved, by an algorithm with the convergence guarantee to the TD solution in general, and a fast convergence rate.