 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
A Flow-based Credibility Metric for Safety-critical Pedestrian Detection
Feb 12, 2024
Safety is of utmost importance for perception in automated driving (AD). However, a prime safety concern in state-of-the art object detection is that standard evaluation schemes utilize safety-agnostic metrics to argue sufficient detection performance. Hence, it is imperative to leverage supplementary domain knowledge to accentuate safety-critical misdetections during evaluation tasks. To tackle the underspecification, this paper introduces a novel credibility metric, called c-flow, for pedestrian bounding boxes. To this end, c-flow relies on a complementary optical flow signal from image sequences and enhances the analyses of safety-critical misdetections without requiring additional labels. We implement and evaluate c-flow with a state-of-the-art pedestrian detector on a large AD dataset. Our analysis demonstrates that c-flow allows developers to identify safety-critical misdetections.
Explainable Multi-Camera 3D Object Detection with Transformer-Based Saliency Maps
Dec 22, 2023Vision Transformers (ViTs) have achieved state-of-the-art results on various computer vision tasks, including 3D object detection. However, their end-to-end implementation also makes ViTs less explainable, which can be a challenge for deploying them in safety-critical applications, such as autonomous driving, where it is important for authorities, developers, and users to understand the model's reasoning behind its predictions. In this paper, we propose a novel method for generating saliency maps for a DetR-like ViT with multiple camera inputs used for 3D object detection. Our method is based on the raw attention and is more efficient than gradient-based methods. We evaluate the proposed method on the nuScenes dataset using extensive perturbation tests and show that it outperforms other explainability methods in terms of visual quality and quantitative metrics. We also demonstrate the importance of aggregating attention across different layers of the transformer. Our work contributes to the development of explainable AI for ViTs, which can help increase trust in AI applications by establishing more transparency regarding the inner workings of AI models.
Improving Image Coding for Machines through Optimizing Encoder via Auxiliary Loss
Feb 13, 2024Image coding for machines (ICM) aims to compress images for machine analysis using recognition models rather than human vision. Hence, in ICM, it is important for the encoder to recognize and compress the information necessary for the machine recognition task. There are two main approaches in learned ICM; optimization of the compression model based on task loss, and Region of Interest (ROI) based bit allocation. These approaches provide the encoder with the recognition capability. However, optimization with task loss becomes difficult when the recognition model is deep, and ROI-based methods often involve extra overhead during evaluation. In this study, we propose a novel training method for learned ICM models that applies auxiliary loss to the encoder to improve its recognition capability and rate-distortion performance. Our method achieves Bjontegaard Delta rate improvements of 27.7% and 20.3% in object detection and semantic segmentation tasks, compared to the conventional training method.
Depth-discriminative Metric Learning for Monocular 3D Object Detection
Jan 02, 2024Monocular 3D object detection poses a significant challenge due to the lack of depth information in RGB images. Many existing methods strive to enhance the object depth estimation performance by allocating additional parameters for object depth estimation, utilizing extra modules or data. In contrast, we introduce a novel metric learning scheme that encourages the model to extract depth-discriminative features regardless of the visual attributes without increasing inference time and model size. Our method employs the distance-preserving function to organize the feature space manifold in relation to ground-truth object depth. The proposed (K, B, eps)-quasi-isometric loss leverages predetermined pairwise distance restriction as guidance for adjusting the distance among object descriptors without disrupting the non-linearity of the natural feature manifold. Moreover, we introduce an auxiliary head for object-wise depth estimation, which enhances depth quality while maintaining the inference time. The broad applicability of our method is demonstrated through experiments that show improvements in overall performance when integrated into various baselines. The results show that our method consistently improves the performance of various baselines by 23.51% and 5.78% on average across KITTI and Waymo, respectively.
Multimodal Anomaly Detection based on Deep Auto-Encoder for Object Slip Perception of Mobile Manipulation Robots
Mar 06, 2024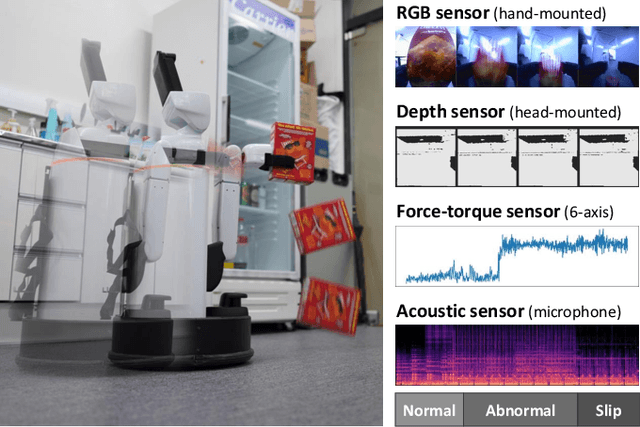
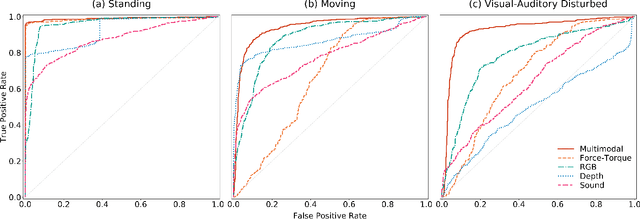
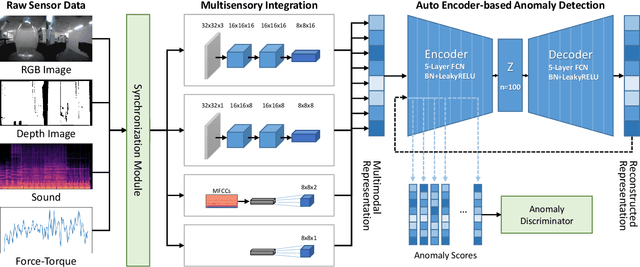
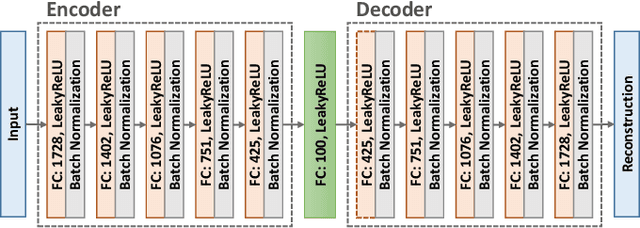
Object slip perception is essential for mobile manipulation robots to perform manipulation tasks reliably in the dynamic real-world. Traditional approaches to robot arms' slip perception use tactile or vision sensors. However, mobile robots still have to deal with noise in their sensor signals caused by the robot's movement in a changing environment. To solve this problem, we present an anomaly detection method that utilizes multisensory data based on a deep autoencoder model. The proposed framework integrates heterogeneous data streams collected from various robot sensors, including RGB and depth cameras, a microphone, and a force-torque sensor. The integrated data is used to train a deep autoencoder to construct latent representations of the multisensory data that indicate the normal status. Anomalies can then be identified by error scores measured by the difference between the trained encoder's latent values and the latent values of reconstructed input data. In order to evaluate the proposed framework, we conducted an experiment that mimics an object slip by a mobile service robot operating in a real-world environment with diverse household objects and different moving patterns. The experimental results verified that the proposed framework reliably detects anomalies in object slip situations despite various object types and robot behaviors, and visual and auditory noise in the environment.
Deep Active Perception for Object Detection using Navigation Proposals
Dec 15, 2023Deep Learning (DL) has brought significant advances to robotics vision tasks. However, most existing DL methods have a major shortcoming, they rely on a static inference paradigm inherent in traditional computer vision pipelines. On the other hand, recent studies have found that active perception improves the perception abilities of various models by going beyond these static paradigms. Despite the significant potential of active perception, it poses several challenges, primarily involving significant changes in training pipelines for deep learning models. To overcome these limitations, in this work, we propose a generic supervised active perception pipeline for object detection that can be trained using existing off-the-shelf object detectors, while also leveraging advances in simulation environments. To this end, the proposed method employs an additional neural network architecture that estimates better viewpoints in cases where the object detector confidence is insufficient. The proposed method was evaluated on synthetic datasets, constructed within the Webots robotics simulator, showcasing its effectiveness in two object detection cases.
Modular Graph Extraction for Handwritten Circuit Diagram Images
Feb 16, 2024As digitization in engineering progressed, circuit diagrams (also referred to as schematics) are typically developed and maintained in computer-aided engineering (CAE) systems, thus allowing for automated verification, simulation and further processing in downstream engineering steps. However, apart from printed legacy schematics, hand-drawn circuit diagrams are still used today in the educational domain, where they serve as an easily accessible mean for trainees and students to learn drawing this type of diagrams. Furthermore, hand-drawn schematics are typically used in examinations due to legal constraints. In order to harness the capabilities of digital circuit representations, automated means for extracting the electrical graph from raster graphics are required. While respective approaches have been proposed in literature, they are typically conducted on small or non-disclosed datasets. This paper describes a modular end-to-end solution on a larger, public dataset, in which approaches for the individual sub-tasks are evaluated to form a new baseline. These sub-tasks include object detection (for electrical symbols and texts), binary segmentation (drafter's stroke vs. background), handwritten character recognition and orientation regression for electrical symbols and texts. Furthermore, computer-vision graph assembly and rectification algorithms are presented. All methods are integrated in a publicly available prototype.
Open World Object Detection in the Era of Foundation Models
Dec 10, 2023Object detection is integral to a bevy of real-world applications, from robotics to medical image analysis. To be used reliably in such applications, models must be capable of handling unexpected - or novel - objects. The open world object detection (OWD) paradigm addresses this challenge by enabling models to detect unknown objects and learn discovered ones incrementally. However, OWD method development is hindered due to the stringent benchmark and task definitions. These definitions effectively prohibit foundation models. Here, we aim to relax these definitions and investigate the utilization of pre-trained foundation models in OWD. First, we show that existing benchmarks are insufficient in evaluating methods that utilize foundation models, as even naive integration methods nearly saturate these benchmarks. This result motivated us to curate a new and challenging benchmark for these models. Therefore, we introduce a new benchmark that includes five real-world application-driven datasets, including challenging domains such as aerial and surgical images, and establish baselines. We exploit the inherent connection between classes in application-driven datasets and introduce a novel method, Foundation Object detection Model for the Open world, or FOMO, which identifies unknown objects based on their shared attributes with the base known objects. FOMO has ~3x unknown object mAP compared to baselines on our benchmark. However, our results indicate a significant place for improvement - suggesting a great research opportunity in further scaling object detection methods to real-world domains. Our code and benchmark are available at https://orrzohar.github.io/projects/fomo/.
TDViT: Temporal Dilated Video Transformer for Dense Video Tasks
Feb 14, 2024Deep video models, for example, 3D CNNs or video transformers, have achieved promising performance on sparse video tasks, i.e., predicting one result per video. However, challenges arise when adapting existing deep video models to dense video tasks, i.e., predicting one result per frame. Specifically, these models are expensive for deployment, less effective when handling redundant frames, and difficult to capture long-range temporal correlations. To overcome these issues, we propose a Temporal Dilated Video Transformer (TDViT) that consists of carefully designed temporal dilated transformer blocks (TDTB). TDTB can efficiently extract spatiotemporal representations and effectively alleviate the negative effect of temporal redundancy. Furthermore, by using hierarchical TDTBs, our approach obtains an exponentially expanded temporal receptive field and therefore can model long-range dynamics. Extensive experiments are conducted on two different dense video benchmarks, i.e., ImageNet VID for video object detection and YouTube VIS for video instance segmentation. Excellent experimental results demonstrate the superior efficiency, effectiveness, and compatibility of our method. The code is available at https://github.com/guanxiongsun/vfe.pytorch.
Reinforcement Learning as a Parsimonious Alternative to Prediction Cascades: A Case Study on Image Segmentation
Feb 19, 2024Deep learning architectures have achieved state-of-the-art (SOTA) performance on computer vision tasks such as object detection and image segmentation. This may be attributed to the use of over-parameterized, monolithic deep learning architectures executed on large datasets. Although such architectures lead to increased accuracy, this is usually accompanied by a large increase in computation and memory requirements during inference. While this is a non-issue in traditional machine learning pipelines, the recent confluence of machine learning and fields like the Internet of Things has rendered such large architectures infeasible for execution in low-resource settings. In such settings, previous efforts have proposed decision cascades where inputs are passed through models of increasing complexity until desired performance is achieved. However, we argue that cascaded prediction leads to increased computational cost due to wasteful intermediate computations. To address this, we propose PaSeR (Parsimonious Segmentation with Reinforcement Learning) a non-cascading, cost-aware learning pipeline as an alternative to cascaded architectures. Through experimental evaluation on real-world and standard datasets, we demonstrate that PaSeR achieves better accuracy while minimizing computational cost relative to cascaded models. Further, we introduce a new metric IoU/GigaFlop to evaluate the balance between cost and performance. On the real-world task of battery material phase segmentation, PaSeR yields a minimum performance improvement of 174% on the IoU/GigaFlop metric with respect to baselines. We also demonstrate PaSeR's adaptability to complementary models trained on a noisy MNIST dataset, where it achieved a minimum performance improvement on IoU/GigaFlop of 13.4% over SOTA models. Code and data are available at https://github.com/scailab/paser .