 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriShGAN: Enhancing Sparsity and Robustness in Multivariate Time Series Counterfactuals Explanation
Nov 09, 2025In decision-making processes, stakeholders often rely on counterfactual explanations, which provide suggestions about what should be changed in the queried instance to alter the outcome of an AI system. However, generating these explanations for multivariate time series presents challenges due to their complex, multi-dimensional nature. Traditional Nearest Unlike Neighbor-based methods typically substitute subsequences in a queried time series with influential subsequences from an NUN, which is not always realistic in real-world scenarios due to the rigid direct substitution. Counterfactual with Residual Generative Adversarial Networks-based methods aim to address this by learning from the distribution of observed data to generate synthetic counterfactual explanations. However, these methods primarily focus on minimizing the cost from the queried time series to the counterfactual explanations and often neglect the importance of distancing the counterfactual explanation from the decision boundary. This oversight can result in explanations that no longer qualify as counterfactual if minor changes occur within the model. To generate a more robust counterfactual explanation, we introduce TriShGAN, under the CounteRGAN framework enhanced by the incorporation of triplet loss. This unsupervised learning approach uses distance metric learning to encourage the counterfactual explanations not only to remain close to the queried time series but also to capture the feature distribution of the instance with the desired outcome, thereby achieving a better balance between minimal cost and robustness. Additionally, we integrate a Shapelet Extractor that strategically selects the most discriminative parts of the high-dimensional queried time series to enhance the sparsity of counterfactual explanation and efficiency of the training process.
TDViT: Temporal Dilated Video Transformer for Dense Video Tasks
Feb 14, 2024Deep video models, for example, 3D CNNs or video transformers, have achieved promising performance on sparse video tasks, i.e., predicting one result per video. However, challenges arise when adapting existing deep video models to dense video tasks, i.e., predicting one result per frame. Specifically, these models are expensive for deployment, less effective when handling redundant frames, and difficult to capture long-range temporal correlations. To overcome these issues, we propose a Temporal Dilated Video Transformer (TDViT) that consists of carefully designed temporal dilated transformer blocks (TDTB). TDTB can efficiently extract spatiotemporal representations and effectively alleviate the negative effect of temporal redundancy. Furthermore, by using hierarchical TDTBs, our approach obtains an exponentially expanded temporal receptive field and therefore can model long-range dynamics. Extensive experiments are conducted on two different dense video benchmarks, i.e., ImageNet VID for video object detection and YouTube VIS for video instance segmentation. Excellent experimental results demonstrate the superior efficiency, effectiveness, and compatibility of our method. The code is available at https://github.com/guanxiongsun/vfe.pytorch.
Efficient One-stage Video Object Detection by Exploiting Temporal Consistency
Feb 14, 2024Recently, one-stage detectors have achieved competitive accuracy and faster speed compared with traditional two-stage detectors on image data. However, in the field of video object detection (VOD), most existing VOD methods are still based on two-stage detectors. Moreover, directly adapting existing VOD methods to one-stage detectors introduces unaffordable computational costs. In this paper, we first analyse the computational bottlenecks of using one-stage detectors for VOD. Based on the analysis, we present a simple yet efficient framework to address the computational bottlenecks and achieve efficient one-stage VOD by exploiting the temporal consistency in video frames. Specifically, our method consists of a location-prior network to filter out background regions and a size-prior network to skip unnecessary computations on low-level feature maps for specific frames. We test our method on various modern one-stage detectors and conduct extensive experiments on the ImageNet VID dataset. Excellent experimental results demonstrate the superior effectiveness, efficiency, and compatibility of our method. The code is available at https://github.com/guanxiongsun/vfe.pytorch.
Spatio-temporal Prompting Network for Robust Video Feature Extraction
Feb 04, 2024Frame quality deterioration is one of the main challenges in the field of video understanding. To compensate for the information loss caused by deteriorated frames, recent approaches exploit transformer-based integration modules to obtain spatio-temporal information. However, these integration modules are heavy and complex. Furthermore, each integration module is specifically tailored for its target task, making it difficult to generalise to multiple tasks. In this paper, we present a neat and unified framework, called Spatio-Temporal Prompting Network (STPN). It can efficiently extract robust and accurate video features by dynamically adjusting the input features in the backbone network. Specifically, STPN predicts several video prompts containing spatio-temporal information of neighbour frames. Then, these video prompts are prepended to the patch embeddings of the current frame as the updated input for video feature extraction. Moreover, STPN is easy to generalise to various video tasks because it does not contain task-specific modules. Without bells and whistles, STPN achieves state-of-the-art performance on three widely-used datasets for different video understanding tasks, i.e., ImageNetVID for video object detection, YouTubeVIS for video instance segmentation, and GOT-10k for visual object tracking. Code is available at https://github.com/guanxiongsun/vfe.pytorch.
MAMBA: Multi-level Aggregation via Memory Bank for Video Object Detection
Feb 01, 2024



State-of-the-art video object detection methods maintain a memory structure, either a sliding window or a memory queue, to enhance the current frame using attention mechanisms. However, we argue that these memory structures are not efficient or sufficient because of two implied operations: (1) concatenating all features in memory for enhancement, leading to a heavy computational cost; (2) frame-wise memory updating, preventing the memory from capturing more temporal information. In this paper, we propose a multi-level aggregation architecture via memory bank called MAMBA. Specifically, our memory bank employs two novel operations to eliminate the disadvantages of existing methods: (1) light-weight key-set construction which can significantly reduce the computational cost; (2) fine-grained feature-wise updating strategy which enables our method to utilize knowledge from the whole video. To better enhance features from complementary levels, i.e., feature maps and proposals, we further propose a generalized enhancement operation (GEO) to aggregate multi-level features in a unified manner. We conduct extensive evaluations on the challenging ImageNetVID dataset. Compared with existing state-of-the-art methods, our method achieves superior performance in terms of both speed and accuracy. More remarkably, MAMBA achieves mAP of 83.7/84.6% at 12.6/9.1 FPS with ResNet-101. Code is available at https://github.com/guanxiongsun/vfe.pytorch.
* update code url https://github.com/guanxiongsun/vfe.pytorch
Neural Sign Actors: A diffusion model for 3D sign language production from text
Dec 05, 2023Sign Languages (SL) serve as the predominant mode of communication for the Deaf and Hard of Hearing communities. The advent of deep learning has aided numerous methods in SL recognition and translation, achieving remarkable results. However, Sign Language Production (SLP) poses a challenge for the computer vision community as the motions generated must be realistic and have precise semantic meanings. Most SLP methods rely on 2D data, thus impeding their ability to attain a necessary level of realism. In this work, we propose a diffusion-based SLP model trained on a curated large-scale dataset of 4D signing avatars and their corresponding text transcripts. The proposed method can generate dynamic sequences of 3D avatars from an unconstrained domain of discourse using a diffusion process formed on a novel and anatomically informed graph neural network defined on the SMPL-X body skeleton. Through a series of quantitative and qualitative experiments, we show that the proposed method considerably outperforms previous methods of SLP. We believe that this work presents an important and necessary step towards realistic neural sign avatars, bridging the communication gap between Deaf and hearing communities. The code, method and generated data will be made publicly available.
Focus On What's Important: Self-Attention Model for Human Pose Estimation
Sep 22, 2018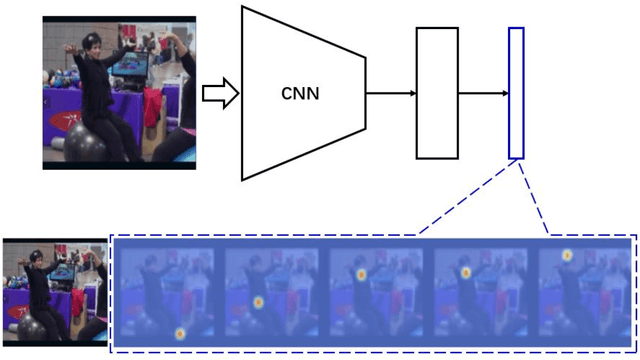
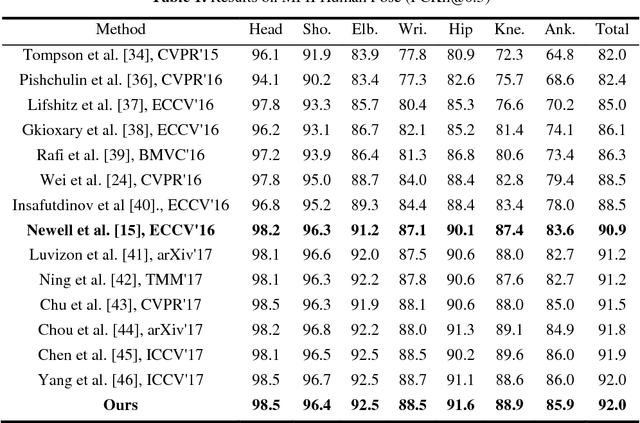
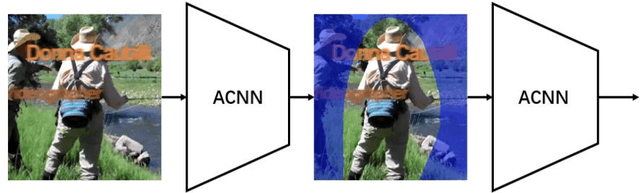
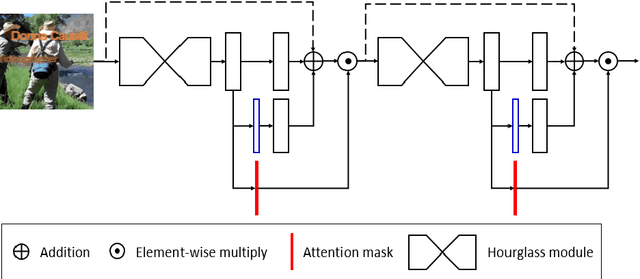
Human pose estimation is an essential yet challenging task in computer vision. One of the reasons for this difficulty is that there are many redundant regions in the images. In this work, we proposed a convolutional network architecture combined with the novel attention model. We named it attention convolutional neural network (ACNN). ACNN learns to focus on specific regions of different input features. It's a multi-stage architecture. Early stages filtrate the "nothing-regions", such as background and redundant body parts. And then, they submit the important regions which contain the joints of the human body to the following stages to get a more accurate result. What's more, it does not require extra manual annotations and self-learning is one of our intentions. We separately trained the network because the attention learning task and the pose estimation task are not independent. State-of-the-art performance is obtained on the MPII benchmarks.