 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
YOLOPoint Joint Keypoint and Object Detection
Feb 06, 2024
Intelligent vehicles of the future must be capable of understanding and navigating safely through their surroundings. Camera-based vehicle systems can use keypoints as well as objects as low- and high-level landmarks for GNSS-independent SLAM and visual odometry. To this end we propose YOLOPoint, a convolutional neural network model that simultaneously detects keypoints and objects in an image by combining YOLOv5 and SuperPoint to create a single forward-pass network that is both real-time capable and accurate. By using a shared backbone and a light-weight network structure, YOLOPoint is able to perform competitively on both the HPatches and KITTI benchmarks.
* 12 pages, 5 figures
A Comprehensive Survey of Convolutions in Deep Learning: Applications, Challenges, and Future Trends
Feb 23, 2024In today's digital age, Convolutional Neural Networks (CNNs), a subset of Deep Learning (DL), are widely used for various computer vision tasks such as image classification, object detection, and image segmentation. There are numerous types of CNNs designed to meet specific needs and requirements, including 1D, 2D, and 3D CNNs, as well as dilated, grouped, attention, depthwise convolutions, and NAS, among others. Each type of CNN has its unique structure and characteristics, making it suitable for specific tasks. It's crucial to gain a thorough understanding and perform a comparative analysis of these different CNN types to understand their strengths and weaknesses. Furthermore, studying the performance, limitations, and practical applications of each type of CNN can aid in the development of new and improved architectures in the future. We also dive into the platforms and frameworks that researchers utilize for their research or development from various perspectives. Additionally, we explore the main research fields of CNN like 6D vision, generative models, and meta-learning. This survey paper provides a comprehensive examination and comparison of various CNN architectures, highlighting their architectural differences and emphasizing their respective advantages, disadvantages, applications, challenges, and future trends.
Squeezed Edge YOLO: Onboard Object Detection on Edge Devices
Dec 18, 2023Demand for efficient onboard object detection is increasing due to its key role in autonomous navigation. However, deploying object detection models such as YOLO on resource constrained edge devices is challenging due to the high computational requirements of such models. In this paper, an compressed object detection model named Squeezed Edge YOLO is examined. This model is compressed and optimized to kilobytes of parameters in order to fit onboard such edge devices. To evaluate Squeezed Edge YOLO, two use cases - human and shape detection - are used to show the model accuracy and performance. Moreover, the model is deployed onboard a GAP8 processor with 8 RISC-V cores and an NVIDIA Jetson Nano with 4GB of memory. Experimental results show Squeezed Edge YOLO model size is optimized by a factor of 8x which leads to 76% improvements in energy efficiency and 3.3x faster throughout.
Selective nonlinearities removal from digital signals
Mar 13, 2024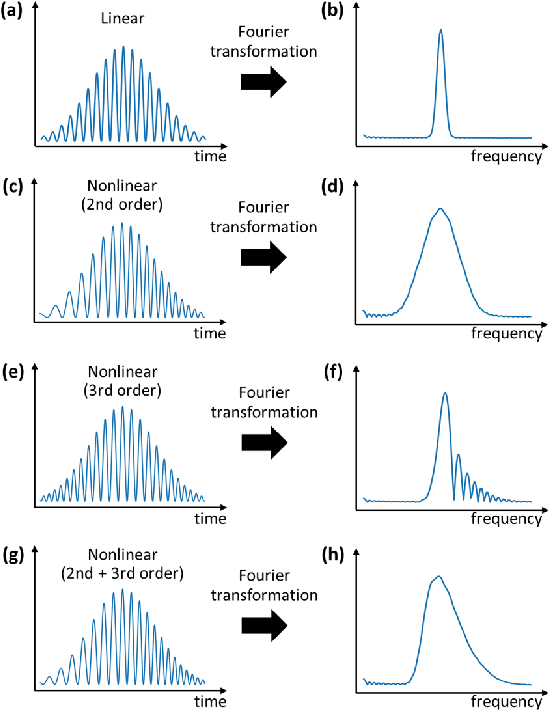
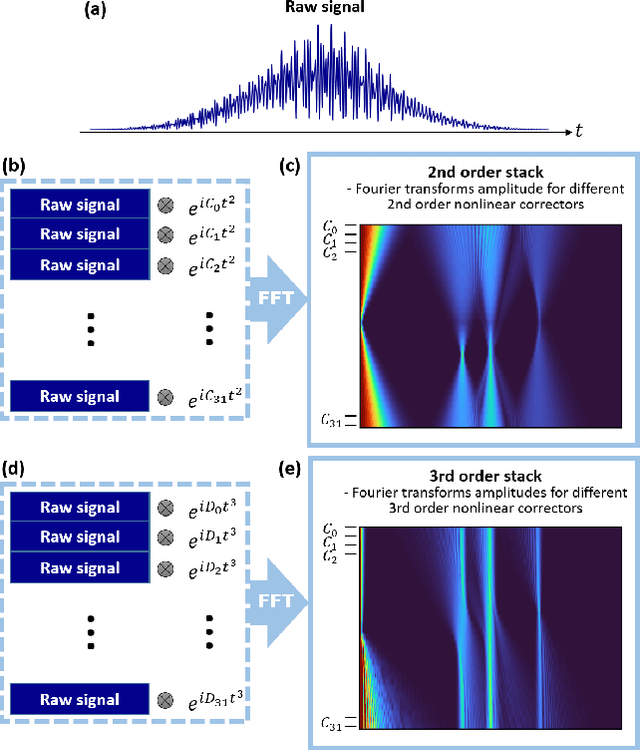
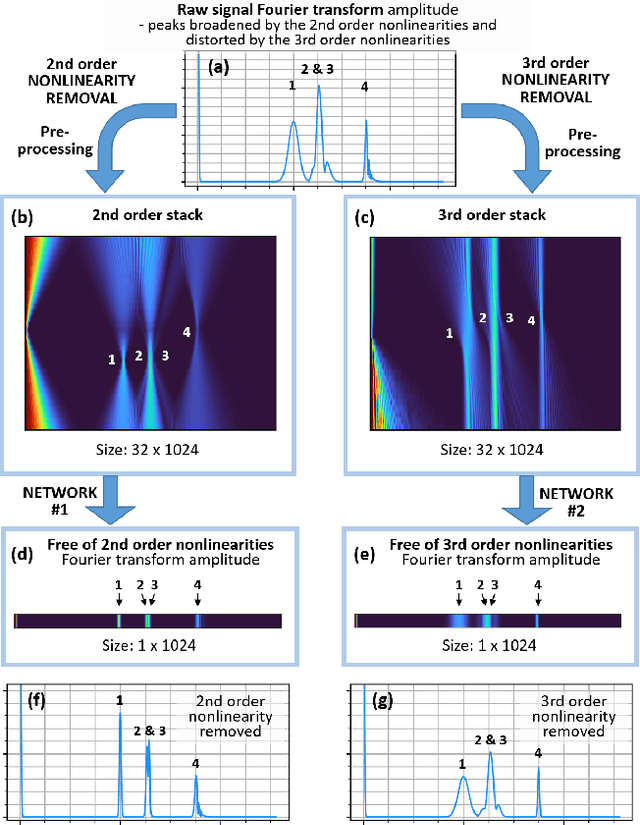
Many instruments performing optical and non-optical imaging and sensing, such as Optical Coherence Tomography (OCT), Magnetic Resonance Imaging or Fourier-transform spectrometry, produce digital signals containing modulations, sine-like components, which only after Fourier transformation give information about the structure or characteristics of the investigated object. Due to the fundamental physics-related limitations of such methods, the distribution of these signal components is often nonlinear and, when not properly compensated, leads to the resolution, precision or quality drop in the final image. Here, we propose an innovative approach that has the potential to allow cleaning of the signal from the nonlinearities but most of all, it now allows to switch the given order off, leaving all others intact. The latter provides a tool for more in-depth analysis of the nonlinearity-inducing properties of the investigated object, which can lead to applications in early disease detection or more sensitive sensing of chemical compounds. We consider OCT signals and nonlinearities up to the third order. In our approach, we propose two neural networks: one to remove solely the second-order nonlinearity and the other for removing solely the third-order nonlinearity. The input of the networks is a novel two-dimensional data structure with all the information needed for the network to infer a nonlinearity-free signal. We describe the developed networks and present the results for second-order and third-order nonlinearity removal in OCT data representing the images of various objects: a mirror, glass, and fruits.
CLIP-guided Source-free Object Detection in Aerial Images
Jan 10, 2024Domain adaptation is crucial in aerial imagery, as the visual representation of these images can significantly vary based on factors such as geographic location, time, and weather conditions. Additionally, high-resolution aerial images often require substantial storage space and may not be readily accessible to the public. To address these challenges, we propose a novel Source-Free Object Detection (SFOD) method. Specifically, our approach is built upon a self-training framework; however, self-training can lead to inaccurate learning in the absence of labeled training data. To address this issue, we further integrate Contrastive Language-Image Pre-training (CLIP) to guide the generation of pseudo-labels, termed CLIP-guided Aggregation. By leveraging CLIP's zero-shot classification capability, we use it to aggregate scores with the original predicted bounding boxes, enabling us to obtain refined scores for the pseudo-labels. To validate the effectiveness of our method, we constructed two new datasets from different domains based on the DIOR dataset, named DIOR-C and DIOR-Cloudy. Experiments demonstrate that our method outperforms other comparative algorithms.
Semantic Object-level Modeling for Robust Visual Camera Relocalization
Feb 10, 2024Visual relocalization is crucial for autonomous visual localization and navigation of mobile robotics. Due to the improvement of CNN-based object detection algorithm, the robustness of visual relocalization is greatly enhanced especially in viewpoints where classical methods fail. However, ellipsoids (quadrics) generated by axis-aligned object detection may limit the accuracy of the object-level representation and degenerate the performance of visual relocalization system. In this paper, we propose a novel method of automatic object-level voxel modeling for accurate ellipsoidal representations of objects. As for visual relocalization, we design a better pose optimization strategy for camera pose recovery, to fully utilize the projection characteristics of 2D fitted ellipses and the 3D accurate ellipsoids. All of these modules are entirely intergrated into visual SLAM system. Experimental results show that our semantic object-level mapping and object-based visual relocalization methods significantly enhance the performance of visual relocalization in terms of robustness to new viewpoints.
SPGroup3D: Superpoint Grouping Network for Indoor 3D Object Detection
Dec 21, 2023Current 3D object detection methods for indoor scenes mainly follow the voting-and-grouping strategy to generate proposals. However, most methods utilize instance-agnostic groupings, such as ball query, leading to inconsistent semantic information and inaccurate regression of the proposals. To this end, we propose a novel superpoint grouping network for indoor anchor-free one-stage 3D object detection. Specifically, we first adopt an unsupervised manner to partition raw point clouds into superpoints, areas with semantic consistency and spatial similarity. Then, we design a geometry-aware voting module that adapts to the centerness in anchor-free detection by constraining the spatial relationship between superpoints and object centers. Next, we present a superpoint-based grouping module to explore the consistent representation within proposals. This module includes a superpoint attention layer to learn feature interaction between neighboring superpoints, and a superpoint-voxel fusion layer to propagate the superpoint-level information to the voxel level. Finally, we employ effective multiple matching to capitalize on the dynamic receptive fields of proposals based on superpoints during the training. Experimental results demonstrate our method achieves state-of-the-art performance on ScanNet V2, SUN RGB-D, and S3DIS datasets in the indoor one-stage 3D object detection. Source code is available at https://github.com/zyrant/SPGroup3D.
MODIPHY: Multimodal Obscured Detection for IoT using PHantom Convolution-Enabled Faster YOLO
Feb 12, 2024Low-light conditions and occluded scenarios impede object detection in real-world Internet of Things (IoT) applications like autonomous vehicles and security systems. While advanced machine learning models strive for accuracy, their computational demands clash with the limitations of resource-constrained devices, hampering real-time performance. In our current research, we tackle this challenge, by introducing "YOLO Phantom", one of the smallest YOLO models ever conceived. YOLO Phantom utilizes the novel Phantom Convolution block, achieving comparable accuracy to the latest YOLOv8n model while simultaneously reducing both parameters and model size by 43%, resulting in a significant 19% reduction in Giga Floating Point Operations (GFLOPs). YOLO Phantom leverages transfer learning on our multimodal RGB-infrared dataset to address low-light and occlusion issues, equipping it with robust vision under adverse conditions. Its real-world efficacy is demonstrated on an IoT platform with advanced low-light and RGB cameras, seamlessly connecting to an AWS-based notification endpoint for efficient real-time object detection. Benchmarks reveal a substantial boost of 17% and 14% in frames per second (FPS) for thermal and RGB detection, respectively, compared to the baseline YOLOv8n model. For community contribution, both the code and the multimodal dataset are available on GitHub.
TimePillars: Temporally-Recurrent 3D LiDAR Object Detection
Dec 22, 2023Object detection applied to LiDAR point clouds is a relevant task in robotics, and particularly in autonomous driving. Single frame methods, predominant in the field, exploit information from individual sensor scans. Recent approaches achieve good performance, at relatively low inference time. Nevertheless, given the inherent high sparsity of LiDAR data, these methods struggle in long-range detection (e.g. 200m) which we deem to be critical in achieving safe automation. Aggregating multiple scans not only leads to a denser point cloud representation, but it also brings time-awareness to the system, and provides information about how the environment is changing. Solutions of this kind, however, are often highly problem-specific, demand careful data processing, and tend not to fulfil runtime requirements. In this context we propose TimePillars, a temporally-recurrent object detection pipeline which leverages the pillar representation of LiDAR data across time, respecting hardware integration efficiency constraints, and exploiting the diversity and long-range information of the novel Zenseact Open Dataset (ZOD). Through experimentation, we prove the benefits of having recurrency, and show how basic building blocks are enough to achieve robust and efficient results.
Object-Aware Domain Generalization for Object Detection
Dec 19, 2023Single-domain generalization (S-DG) aims to generalize a model to unseen environments with a single-source domain. However, most S-DG approaches have been conducted in the field of classification. When these approaches are applied to object detection, the semantic features of some objects can be damaged, which can lead to imprecise object localization and misclassification. To address these problems, we propose an object-aware domain generalization (OA-DG) method for single-domain generalization in object detection. Our method consists of data augmentation and training strategy, which are called OA-Mix and OA-Loss, respectively. OA-Mix generates multi-domain data with multi-level transformation and object-aware mixing strategy. OA-Loss enables models to learn domain-invariant representations for objects and backgrounds from the original and OA-Mixed images. Our proposed method outperforms state-of-the-art works on standard benchmarks. Our code is available at https://github.com/WoojuLee24/OA-DG.