 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An analysis of large speech models-based representations for speech emotion recognition
Nov 01, 2023
Large speech models-derived features have recently shown increased performance over signal-based features across multiple downstream tasks, even when the networks are not finetuned towards the target task. In this paper we show the results of an analysis of several signal- and neural models-derived features for speech emotion recognition. We use pretrained models and explore their inherent potential abstractions of emotions. Simple classification methods are used so as to not interfere or add knowledge to the task. We show that, even without finetuning, some of these large neural speech models' representations can enclose information that enables performances close to, and even beyond state-of-the-art results across six standard speech emotion recognition datasets.
SAGE: Smart home Agent with Grounded Execution
Nov 01, 2023This article introduces SAGE (Smart home Agent with Grounded Execution), a framework designed to maximize the flexibility of smart home assistants by replacing manually-defined inference logic with an LLM-powered autonomous agent system. SAGE integrates information about user preferences, device states, and external factors (such as weather and TV schedules) through the orchestration of a collection of tools. SAGE's capabilities include learning user preferences from natural-language utterances, interacting with devices by reading their API documentation, writing code to continuously monitor devices, and understanding natural device references. To evaluate SAGE, we develop a benchmark of 43 highly challenging smart home tasks, where SAGE successfully achieves 23 tasks, significantly outperforming existing LLM-enabled baselines (5/43).
Transformer-based nowcasting of radar composites from satellite images for severe weather
Oct 30, 2023Weather radar data are critical for nowcasting and an integral component of numerical weather prediction models. While weather radar data provide valuable information at high resolution, their ground-based nature limits their availability, which impedes large-scale applications. In contrast, meteorological satellites cover larger domains but with coarser resolution. However, with the rapid advancements in data-driven methodologies and modern sensors aboard geostationary satellites, new opportunities are emerging to bridge the gap between ground- and space-based observations, ultimately leading to more skillful weather prediction with high accuracy. Here, we present a Transformer-based model for nowcasting ground-based radar image sequences using satellite data up to two hours lead time. Trained on a dataset reflecting severe weather conditions, the model predicts radar fields occurring under different weather phenomena and shows robustness against rapidly growing/decaying fields and complex field structures. Model interpretation reveals that the infrared channel centered at 10.3 $\mu m$ (C13) contains skillful information for all weather conditions, while lightning data have the highest relative feature importance in severe weather conditions, particularly in shorter lead times. The model can support precipitation nowcasting across large domains without an explicit need for radar towers, enhance numerical weather prediction and hydrological models, and provide radar proxy for data-scarce regions. Moreover, the open-source framework facilitates progress towards operational data-driven nowcasting.
One-for-All: Bridge the Gap Between Heterogeneous Architectures in Knowledge Distillation
Oct 30, 2023Knowledge distillation~(KD) has proven to be a highly effective approach for enhancing model performance through a teacher-student training scheme. However, most existing distillation methods are designed under the assumption that the teacher and student models belong to the same model family, particularly the hint-based approaches. By using centered kernel alignment (CKA) to compare the learned features between heterogeneous teacher and student models, we observe significant feature divergence. This divergence illustrates the ineffectiveness of previous hint-based methods in cross-architecture distillation. To tackle the challenge in distilling heterogeneous models, we propose a simple yet effective one-for-all KD framework called OFA-KD, which significantly improves the distillation performance between heterogeneous architectures. Specifically, we project intermediate features into an aligned latent space such as the logits space, where architecture-specific information is discarded. Additionally, we introduce an adaptive target enhancement scheme to prevent the student from being disturbed by irrelevant information. Extensive experiments with various architectures, including CNN, Transformer, and MLP, demonstrate the superiority of our OFA-KD framework in enabling distillation between heterogeneous architectures. Specifically, when equipped with our OFA-KD, the student models achieve notable performance improvements, with a maximum gain of 8.0% on the CIFAR-100 dataset and 0.7% on the ImageNet-1K dataset. PyTorch code and checkpoints can be found at https://github.com/Hao840/OFAKD.
Autoregressive Attention Neural Networks for Non-Line-of-Sight User Tracking with Dynamic Metasurface Antennas
Oct 30, 2023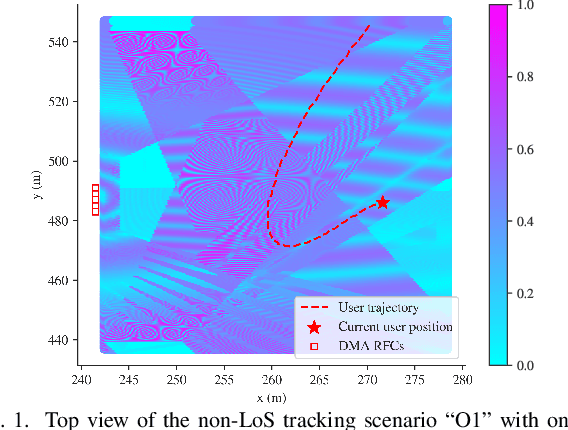
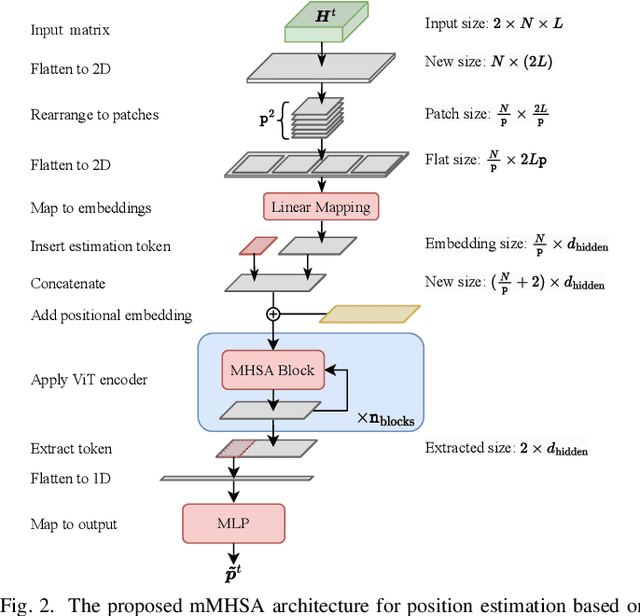
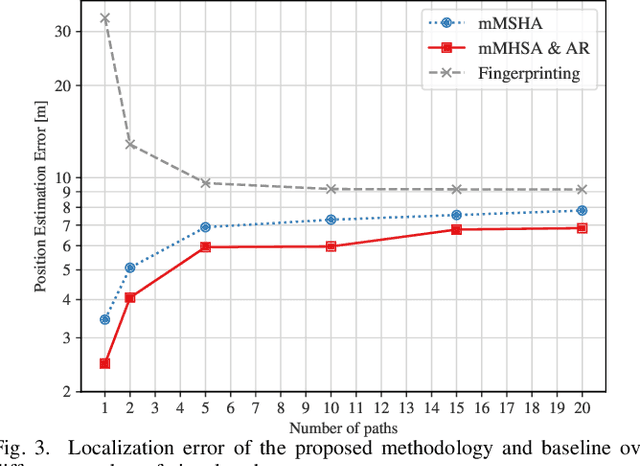
User localization and tracking in the upcoming generation of wireless networks have the potential to be revolutionized by technologies such as the Dynamic Metasurface Antennas (DMAs). Commonly proposed algorithmic approaches rely on assumptions about relatively dominant Line-of-Sight (LoS) paths, or require pilot transmission sequences whose length is comparable to the number of DMA elements, thus, leading to limited effectiveness and considerable measurement overheads in blocked LoS and dynamic multipath environments. In this paper, we present a two-stage machine-learning-based approach for user tracking, specifically designed for non-LoS multipath settings. A newly proposed attention-based Neural Network (NN) is first trained to map noisy channel responses to potential user positions, regardless of user mobility patterns. This architecture constitutes a modification of the prominent vision transformer, specifically modified for extracting information from high-dimensional frequency response signals. As a second stage, the NN's predictions for the past user positions are passed through a learnable autoregressive model to exploit the time-correlated channel information and obtain the final position predictions. The channel estimation procedure leverages a DMA receive architecture with partially-connected radio frequency chains, which results to reduced numbers of pilots. The numerical evaluation over an outdoor ray-tracing scenario illustrates that despite LoS blockage, this methodology is capable of achieving high position accuracy across various multipath settings.
Distil the informative essence of loop detector data set: Is network-level traffic forecasting hungry for more data?
Oct 31, 2023Network-level traffic condition forecasting has been intensively studied for decades. Although prediction accuracy has been continuously improved with emerging deep learning models and ever-expanding traffic data, traffic forecasting still faces many challenges in practice. These challenges include the robustness of data-driven models, the inherent unpredictability of traffic dynamics, and whether further improvement of traffic forecasting requires more sensor data. In this paper, we focus on this latter question and particularly on data from loop detectors. To answer this, we propose an uncertainty-aware traffic forecasting framework to explore how many samples of loop data are truly effective for training forecasting models. Firstly, the model design combines traffic flow theory with graph neural networks, ensuring the robustness of prediction and uncertainty quantification. Secondly, evidential learning is employed to quantify different sources of uncertainty in a single pass. The estimated uncertainty is used to "distil" the essence of the dataset that sufficiently covers the information content. Results from a case study of a highway network around Amsterdam show that, from 2018 to 2021, more than 80\% of the data during daytime can be removed. The remaining 20\% samples have equal prediction power for training models. This result suggests that indeed large traffic datasets can be subdivided into significantly smaller but equally informative datasets. From these findings, we conclude that the proposed methodology proves valuable in evaluating large traffic datasets' true information content. Further extensions, such as extracting smaller, spatially non-redundant datasets, are possible with this method.
Relation Extraction from News Articles (RENA): A Tool for Epidemic Surveillance
Oct 31, 2023Relation Extraction from News Articles (RENA) is a browser-based tool designed to extract key entities and their semantic relationships in English language news articles related to infectious diseases. Constructed using the React framework, this system presents users with an elegant and user-friendly interface. It enables users to input a news article and select from a choice of two models to generate a comprehensive list of relations within the provided text. As a result, RENA allows real-time parsing of news articles to extract key information for epidemic surveillance, contributing to EPIWATCH, an open-source intelligence-based epidemic warning system.
Generalized Information Criteria for Structured Sparse Models
Sep 04, 2023Regularized m-estimators are widely used due to their ability of recovering a low-dimensional model in high-dimensional scenarios. Some recent efforts on this subject focused on creating a unified framework for establishing oracle bounds, and deriving conditions for support recovery. Under this same framework, we propose a new Generalized Information Criteria (GIC) that takes into consideration the sparsity pattern one wishes to recover. We obtain non-asymptotic model selection bounds and sufficient conditions for model selection consistency of the GIC. Furthermore, we show that the GIC can also be used for selecting the regularization parameter within a regularized $m$-estimation framework, which allows practical use of the GIC for model selection in high-dimensional scenarios. We provide examples of group LASSO in the context of generalized linear regression and low rank matrix regression.
3D Masked Autoencoders for Enhanced Privacy in MRI Scans
Oct 24, 2023MRI scans provide valuable medical information, however they also contain sensitive and personally identifiable information (PII) that needs to be protected. Whereas MRI metadata is easily sanitized, MRI image data is a privacy risk because it contains information to render highly-realistic 3D visualizations of a patient's head, enabling malicious actors to possibly identify the subject by cross-referencing a database. Data anonymization and de-identification is concerned with ensuring the privacy and confidentiality of individuals' personal information. Traditional MRI de-identification methods remove privacy-sensitive parts (e.g. eyes, nose etc.) from a given scan. This comes at the expense of introducing a domain shift that can throw off downstream analyses. Recently, a GAN-based approach was proposed to de-identify a patient's scan by remodeling it (e.g. changing the face) rather than by removing parts. In this work, we propose CP-MAE, a model that de-identifies the face using masked autoencoders and that outperforms all previous approaches in terms of downstream task performance as well as de-identification. With our method we are able to synthesize scans of resolution up to $256^3$ (previously 128 cubic) which constitutes an eight-fold increase in the number of voxels. Using our construction we were able to design a system that exhibits a highly robust training stage, making it easy to fit the network on novel data.
Generative Structural Design Integrating BIM and Diffusion Model
Nov 07, 2023Intelligent structural design using AI can effectively reduce time overhead and increase efficiency. It has potential to become the new design paradigm in the future to assist and even replace engineers, and so it has become a research hotspot in the academic community. However, current methods have some limitations to be addressed, whether in terms of application scope, visual quality of generated results, or evaluation metrics of results. This study proposes a comprehensive solution. Firstly, we introduce building information modeling (BIM) into intelligent structural design and establishes a structural design pipeline integrating BIM and generative AI, which is a powerful supplement to the previous frameworks that only considered CAD drawings. In order to improve the perceptual quality and details of generations, this study makes 3 contributions. Firstly, in terms of generation framework, inspired by the process of human drawing, a novel 2-stage generation framework is proposed to replace the traditional end-to-end framework to reduce the generation difficulty for AI models. Secondly, in terms of generative AI tools adopted, diffusion models (DMs) are introduced to replace widely used generative adversarial network (GAN)-based models, and a novel physics-based conditional diffusion model (PCDM) is proposed to consider different design prerequisites. Thirdly, in terms of neural networks, an attention block (AB) consisting of a self-attention block (SAB) and a parallel cross-attention block (PCAB) is designed to facilitate cross-domain data fusion. The quantitative and qualitative results demonstrate the powerful generation and representation capabilities of PCDM. Necessary ablation studies are conducted to examine the validity of the methods. This study also shows that DMs have the potential to replace GANs and become the new benchmark for generative problems in civil engineering.