 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
U3DS$^3$: Unsupervised 3D Semantic Scene Segmentation
Nov 10, 2023
Contemporary point cloud segmentation approaches largely rely on richly annotated 3D training data. However, it is both time-consuming and challenging to obtain consistently accurate annotations for such 3D scene data. Moreover, there is still a lack of investigation into fully unsupervised scene segmentation for point clouds, especially for holistic 3D scenes. This paper presents U3DS$^3$, as a step towards completely unsupervised point cloud segmentation for any holistic 3D scenes. To achieve this, U3DS$^3$ leverages a generalized unsupervised segmentation method for both object and background across both indoor and outdoor static 3D point clouds with no requirement for model pre-training, by leveraging only the inherent information of the point cloud to achieve full 3D scene segmentation. The initial step of our proposed approach involves generating superpoints based on the geometric characteristics of each scene. Subsequently, it undergoes a learning process through a spatial clustering-based methodology, followed by iterative training using pseudo-labels generated in accordance with the cluster centroids. Moreover, by leveraging the invariance and equivariance of the volumetric representations, we apply the geometric transformation on voxelized features to provide two sets of descriptors for robust representation learning. Finally, our evaluation provides state-of-the-art results on the ScanNet and SemanticKITTI, and competitive results on the S3DIS, benchmark datasets.
How to Bridge the Gap between Modalities: A Comprehensive Survey on Multimodal Large Language Model
Nov 10, 2023This review paper explores Multimodal Large Language Models (MLLMs), which integrate Large Language Models (LLMs) like GPT-4 to handle multimodal data such as text and vision. MLLMs demonstrate capabilities like generating image narratives and answering image-based questions, bridging the gap towards real-world human-computer interactions and hinting at a potential pathway to artificial general intelligence. However, MLLMs still face challenges in processing the semantic gap in multimodality, which may lead to erroneous generation, posing potential risks to society. Choosing the appropriate modality alignment method is crucial, as improper methods might require more parameters with limited performance improvement. This paper aims to explore modality alignment methods for LLMs and their existing capabilities. Implementing modality alignment allows LLMs to address environmental issues and enhance accessibility. The study surveys existing modal alignment methods in MLLMs into four groups: (1) Multimodal Converters that change data into something LLMs can understand; (2) Multimodal Perceivers to improve how LLMs perceive different types of data; (3) Tools Assistance for changing data into one common format, usually text; and (4) Data-Driven methods that teach LLMs to understand specific types of data in a dataset. This field is still in a phase of exploration and experimentation, and we will organize and update various existing research methods for multimodal information alignment.
Follow-Up Differential Descriptions: Language Models Resolve Ambiguities for Image Classification
Nov 10, 2023A promising approach for improving the performance of vision-language models like CLIP for image classification is to extend the class descriptions (i.e., prompts) with related attributes, e.g., using brown sparrow instead of sparrow. However, current zero-shot methods select a subset of attributes regardless of commonalities between the target classes, potentially providing no useful information that would have helped to distinguish between them. For instance, they may use color instead of bill shape to distinguish between sparrows and wrens, which are both brown. We propose Follow-up Differential Descriptions (FuDD), a zero-shot approach that tailors the class descriptions to each dataset and leads to additional attributes that better differentiate the target classes. FuDD first identifies the ambiguous classes for each image, and then uses a Large Language Model (LLM) to generate new class descriptions that differentiate between them. The new class descriptions resolve the initial ambiguity and help predict the correct label. In our experiments, FuDD consistently outperforms generic description ensembles and naive LLM-generated descriptions on 12 datasets. We show that differential descriptions are an effective tool to resolve class ambiguities, which otherwise significantly degrade the performance. We also show that high quality natural language class descriptions produced by FuDD result in comparable performance to few-shot adaptation methods.
IODeep: an IOD for the introduction of deep learning in the DICOM standard
Nov 10, 2023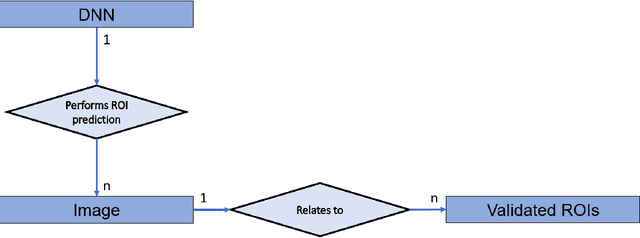
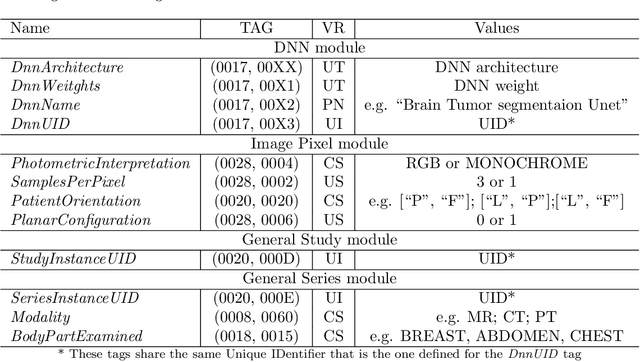
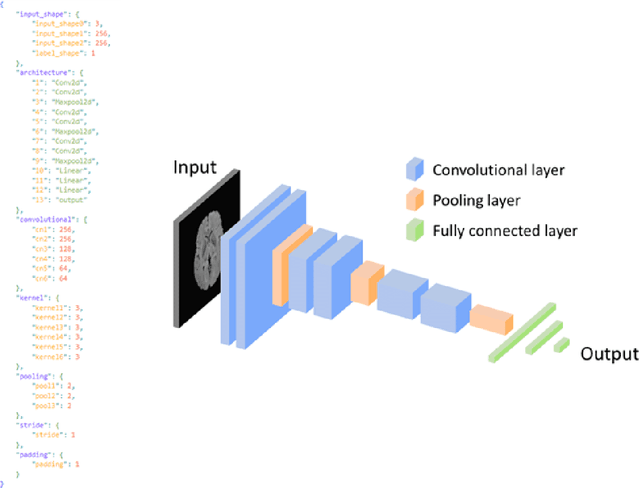
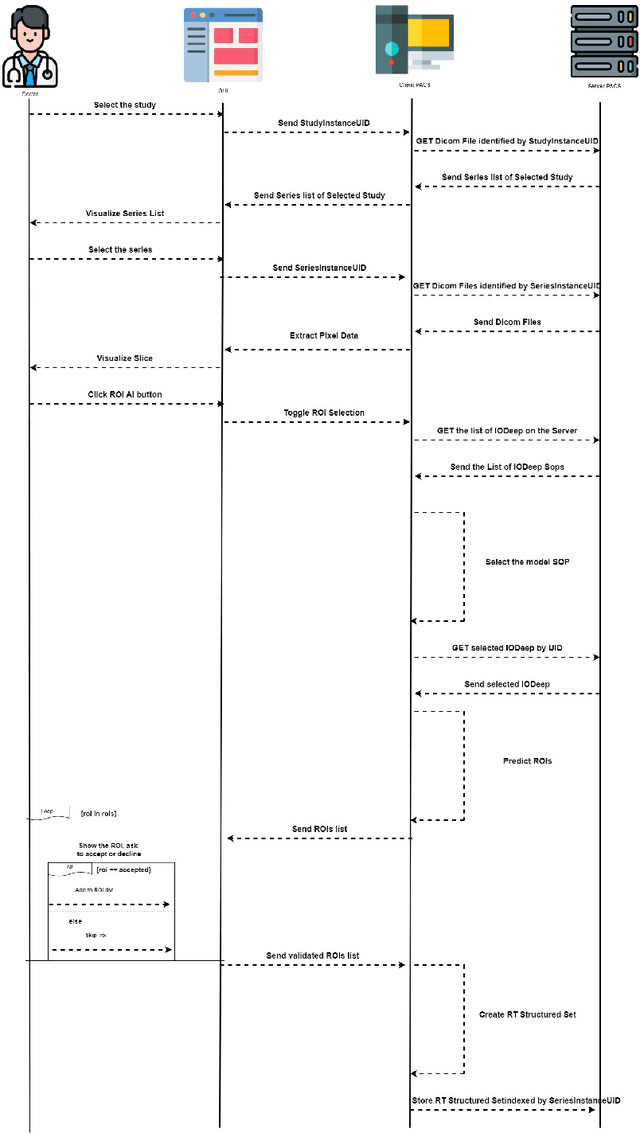
In recent years, Artificial Intelligence (AI) and in particular Deep Neural Networks (DNN) became a relevant research topic in biomedical image segmentation due to the availability of more and more data sets along with the establishment of well known competitions. Despite the popularity of DNN based segmentation on the research side, these techniques are almost unused in the daily clinical practice even if they could support effectively the physician during the diagnostic process. Apart from the issues related to the explainability of the predictions of a neural model, such systems are not integrated in the diagnostic workflow, and a standardization of their use is needed to achieve this goal. This paper presents \textit{IODeep} a new DICOM Information Object Definition (IOD) aimed at storing both the weights and the architecture of a DNN already trained on a particular image dataset that is labeled as regards the acquisition modality, the anatomical region, and the disease under investigation. The IOD architecture is presented along with a DNN selection algorithm from the PACS server based on the labels outlined above, and a simple PACS viewer purposely designed for demonstrating the effectiveness of the DICOM integration, while no modifications are required on the PACS server side. The source code are freely available at https://github.com/CHILab1/IODeep.git
Proceedings of the 5th International Workshop on Reading Music Systems
Nov 07, 2023The International Workshop on Reading Music Systems (WoRMS) is a workshop that tries to connect researchers who develop systems for reading music, such as in the field of Optical Music Recognition, with other researchers and practitioners that could benefit from such systems, like librarians or musicologists. The relevant topics of interest for the workshop include, but are not limited to: Music reading systems; Optical music recognition; Datasets and performance evaluation; Image processing on music scores; Writer identification; Authoring, editing, storing and presentation systems for music scores; Multi-modal systems; Novel input-methods for music to produce written music; Web-based Music Information Retrieval services; Applications and projects; Use-cases related to written music. These are the proceedings of the 5th International Workshop on Reading Music Systems, held in Milan, Italy on Nov. 4th 2023.
3D-Mol: A Novel Contrastive Learning Framework for Molecular Property Prediction with 3D Information
Sep 28, 2023Molecular property prediction offers an effective and efficient approach for early screening and optimization of drug candidates. Although deep learning based methods have made notable progress, most existing works still do not fully utilize 3D spatial information. This can lead to a single molecular representation representing multiple actual molecules. To address these issues, we propose a novel 3D structure-based molecular modeling method named 3D-Mol. In order to accurately represent complete spatial structure, we design a novel encoder to extract 3D features by deconstructing the molecules into three geometric graphs. In addition, we use 20M unlabeled data to pretrain our model by contrastive learning. We consider conformations with the same topological structure as positive pairs and the opposites as negative pairs, while the weight is determined by the dissimilarity between the conformations. We compare 3D-Mol with various state-of-the-art (SOTA) baselines on 7 benchmarks and demonstrate our outstanding performance in 5 benchmarks.
An End-Cloud Computing Enabled Surveillance Video Transmission System
Nov 08, 2023The enormous data volume of video poses a significant burden on the network. Particularly, transferring high-definition surveillance videos to the cloud consumes a significant amount of spectrum resources. To address these issues, we propose a surveillance video transmission system enabled by end-cloud computing. Specifically, the cameras actively down-sample the original video and then a redundant frame elimination module is employed to further reduce the data volume of surveillance videos. Then we develop a key-frame assisted video super-resolution model to reconstruct the high-quality video at the cloud side. Moreover, we propose a strategy of extracting key frames from source videos for better reconstruction performance by utilizing the peak signal-to-noise ratio (PSNR) of adjacent frames to measure the propagation distance of key frame information. Simulation results show that the developed system can effectively reduce the data volume by the end-cloud collaboration and outperforms existing video super-resolution models significantly in terms of PSNR and structural similarity index (SSIM).
MTGER: Multi-view Temporal Graph Enhanced Temporal Reasoning over Time-Involved Document
Nov 08, 2023The facts and time in the document are intricately intertwined, making temporal reasoning over documents challenging. Previous work models time implicitly, making it difficult to handle such complex relationships. To address this issue, we propose MTGER, a novel Multi-view Temporal Graph Enhanced Temporal Reasoning framework for temporal reasoning over time-involved documents. Concretely, MTGER explicitly models the temporal relationships among facts by multi-view temporal graphs. On the one hand, the heterogeneous temporal graphs explicitly model the temporal and discourse relationships among facts; on the other hand, the multi-view mechanism captures both time-focused and fact-focused information, allowing the two views to complement each other through adaptive fusion. To further improve the implicit reasoning capability of the model, we design a self-supervised time-comparing objective. Extensive experimental results demonstrate the effectiveness of our method on the TimeQA and SituatedQA datasets. Furthermore, MTGER gives more consistent answers under question perturbations.
VioLA: Aligning Videos to 2D LiDAR Scans
Nov 08, 2023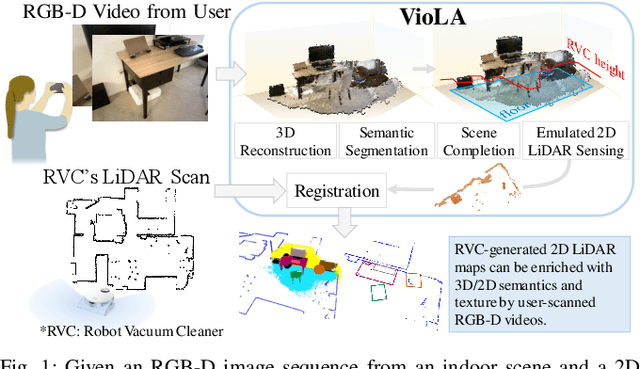
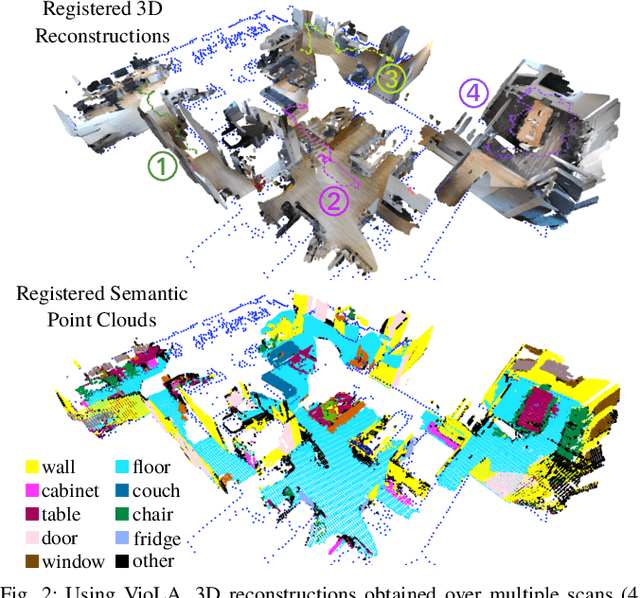
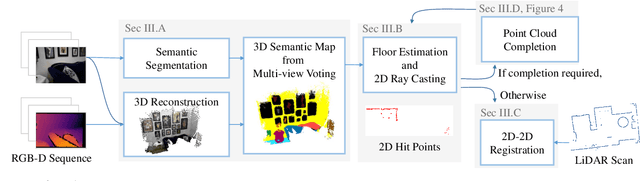
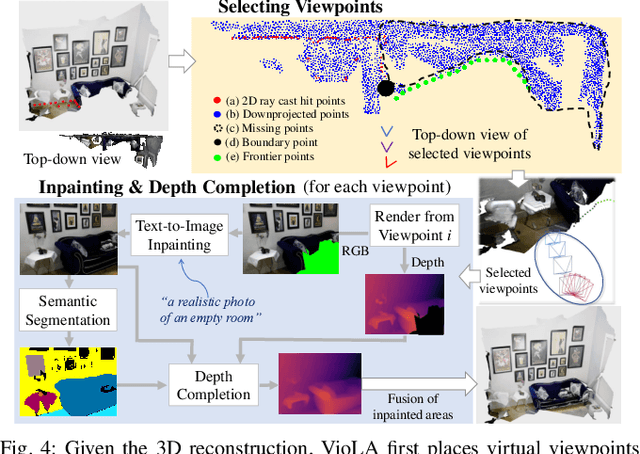
We study the problem of aligning a video that captures a local portion of an environment to the 2D LiDAR scan of the entire environment. We introduce a method (VioLA) that starts with building a semantic map of the local scene from the image sequence, then extracts points at a fixed height for registering to the LiDAR map. Due to reconstruction errors or partial coverage of the camera scan, the reconstructed semantic map may not contain sufficient information for registration. To address this problem, VioLA makes use of a pre-trained text-to-image inpainting model paired with a depth completion model for filling in the missing scene content in a geometrically consistent fashion to support pose registration. We evaluate VioLA on two real-world RGB-D benchmarks, as well as a self-captured dataset of a large office scene. Notably, our proposed scene completion module improves the pose registration performance by up to 20%.
Enhancing Multi-Agent Coordination through Common Operating Picture Integration
Nov 08, 2023In multi-agent systems, agents possess only local observations of the environment. Communication between teammates becomes crucial for enhancing coordination. Past research has primarily focused on encoding local information into embedding messages which are unintelligible to humans. We find that using these messages in agent's policy learning leads to brittle policies when tested on out-of-distribution initial states. We present an approach to multi-agent coordination, where each agent is equipped with the capability to integrate its (history of) observations, actions and messages received into a Common Operating Picture (COP) and disseminate the COP. This process takes into account the dynamic nature of the environment and the shared mission. We conducted experiments in the StarCraft2 environment to validate our approach. Our results demonstrate the efficacy of COP integration, and show that COP-based training leads to robust policies compared to state-of-the-art Multi-Agent Reinforcement Learning (MARL) methods when faced with out-of-distribution initial states.