 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Channel-Feedback-Free Transmission for Downlink FD-RAN: A Radio Map based Complex-valued Precoding Network Approach
Nov 30, 2023
As the demand for high-quality services proliferates, an innovative network architecture, the fully-decoupled RAN (FD-RAN), has emerged for more flexible spectrum resource utilization and lower network costs. However, with the decoupling of uplink base stations and downlink base stations in FD-RAN, the traditional transmission mechanism, which relies on real-time channel feedback, is not suitable as the receiver is not able to feedback accurate and timely channel state information to the transmitter. This paper proposes a novel transmission scheme without relying on physical layer channel feedback. Specifically, we design a radio map based complex-valued precoding network~(RMCPNet) model, which outputs the base station precoding based on user location. RMCPNet comprises multiple subnets, with each subnet responsible for extracting unique modal features from diverse input modalities. Furthermore, the multi-modal embeddings derived from these distinct subnets are integrated within the information fusion layer, culminating in a unified representation. We also develop a specific RMCPNet training algorithm that employs the negative spectral efficiency as the loss function. We evaluate the performance of the proposed scheme on the public DeepMIMO dataset and show that RMCPNet can achieve 16\% and 76\% performance improvements over the conventional real-valued neural network and statistical codebook approach, respectively.
DEVIAS: Learning Disentangled Video Representations of Action and Scene for Holistic Video Understanding
Nov 30, 2023When watching a video, humans can naturally extract human actions from the surrounding scene context, even when action-scene combinations are unusual. However, unlike humans, video action recognition models often learn scene-biased action representations from the spurious correlation in training data, leading to poor performance in out-of-context scenarios. While scene-debiased models achieve improved performance in out-of-context scenarios, they often overlook valuable scene information in the data. Addressing this challenge, we propose Disentangled VIdeo representations of Action and Scene (DEVIAS), which aims to achieve holistic video understanding. Disentangled action and scene representations with our method could provide flexibility to adjust the emphasis on action or scene information depending on downstream task and dataset characteristics. Disentangled action and scene representations could be beneficial for both in-context and out-of-context video understanding. To this end, we employ slot attention to learn disentangled action and scene representations with a single model, along with auxiliary tasks that further guide slot attention. We validate the proposed method on both in-context datasets: UCF-101 and Kinetics-400, and out-of-context datasets: SCUBA and HAT. Our proposed method shows favorable performance across different datasets compared to the baselines, demonstrating its effectiveness in diverse video understanding scenarios.
Learning to Cooperate and Communicate Over Imperfect Channels
Nov 24, 2023Information exchange in multi-agent systems improves the cooperation among agents, especially in partially observable settings. In the real world, communication is often carried out over imperfect channels. This requires agents to handle uncertainty due to potential information loss. In this paper, we consider a cooperative multi-agent system where the agents act and exchange information in a decentralized manner using a limited and unreliable channel. To cope with such channel constraints, we propose a novel communication approach based on independent Q-learning. Our method allows agents to dynamically adapt how much information to share by sending messages of different sizes, depending on their local observations and the channel's properties. In addition to this message size selection, agents learn to encode and decode messages to improve their jointly trained policies. We show that our approach outperforms approaches without adaptive capabilities in a novel cooperative digit-prediction environment and discuss its limitations in the traffic junction environment.
U-Net v2: Rethinking the Skip Connections of U-Net for Medical Image Segmentation
Nov 29, 2023In this paper, we introduce U-Net v2, a new robust and efficient U-Net variant for medical image segmentation. It aims to augment the infusion of semantic information into low-level features while simultaneously refining high-level features with finer details. For an input image, we begin by extracting multi-level features with a deep neural network encoder. Next, we enhance the feature map of each level by infusing semantic information from higher-level features and integrating finer details from lower-level features through Hadamard product. Our novel skip connections empower features of all the levels with enriched semantic characteristics and intricate details. The improved features are subsequently transmitted to the decoder for further processing and segmentation. Our method can be seamlessly integrated into any Encoder-Decoder network. We evaluate our method on several public medical image segmentation datasets for skin lesion segmentation and polyp segmentation, and the experimental results demonstrate the segmentation accuracy of our new method over state-of-the-art methods, while preserving memory and computational efficiency. Code is available at: https://github.com/yaoppeng/U-Net\_v2
Using Ornstein-Uhlenbeck Process to understand Denoising Diffusion Probabilistic Model and its Noise Schedules
Nov 29, 2023The aim of this short note is to show that Denoising Diffusion Probabilistic Model DDPM, a non-homogeneous discrete-time Markov process, can be represented by a time-homogeneous continuous-time Markov process observed at non-uniformly sampled discrete times. Surprisingly, this continuous-time Markov process is the well-known and well-studied Ornstein-Ohlenbeck (OU) process, which was developed in 1930's for studying Brownian particles in Harmonic potentials. We establish the formal equivalence between DDPM and the OU process using its analytical solution. We further demonstrate that the design problem of the noise scheduler for non-homogeneous DDPM is equivalent to designing observation times for the OU process. We present several heuristic designs for observation times based on principled quantities such as auto-variance and Fisher Information and connect them to ad hoc noise schedules for DDPM. Interestingly, we show that the Fisher-Information-motivated schedule corresponds exactly the cosine schedule, which was developed without any theoretical foundation but is the current state-of-the-art noise schedule.
The Mixtures and the Neural Critics: On the Pointwise Mutual Information Profiles of Fine Distributions
Oct 16, 2023Mutual information quantifies the dependence between two random variables and remains invariant under diffeomorphisms. In this paper, we explore the pointwise mutual information profile, an extension of mutual information that maintains this invariance. We analytically describe the profiles of multivariate normal distributions and introduce the family of fine distributions, for which the profile can be accurately approximated using Monte Carlo methods. We then show how fine distributions can be used to study the limitations of existing mutual information estimators, investigate the behavior of neural critics used in variational estimators, and understand the effect of experimental outliers on mutual information estimation. Finally, we show how fine distributions can be used to obtain model-based Bayesian estimates of mutual information, suitable for problems with available domain expertise in which uncertainty quantification is necessary.
Learning optimal integration of spatial and temporal information in noisy chemotaxis
Oct 16, 2023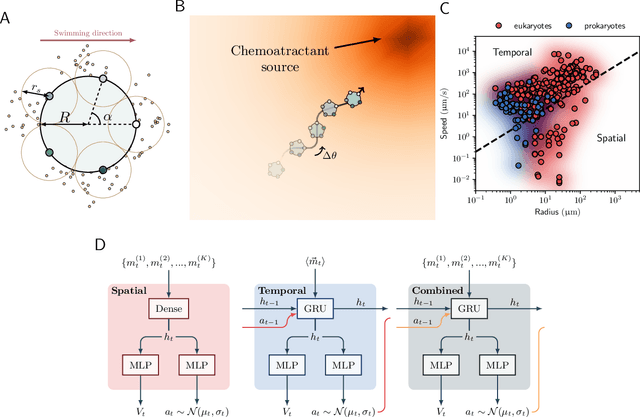
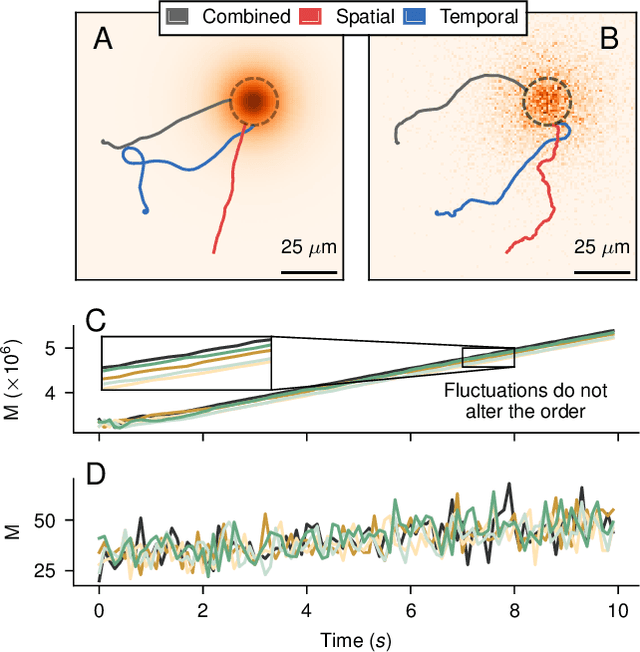
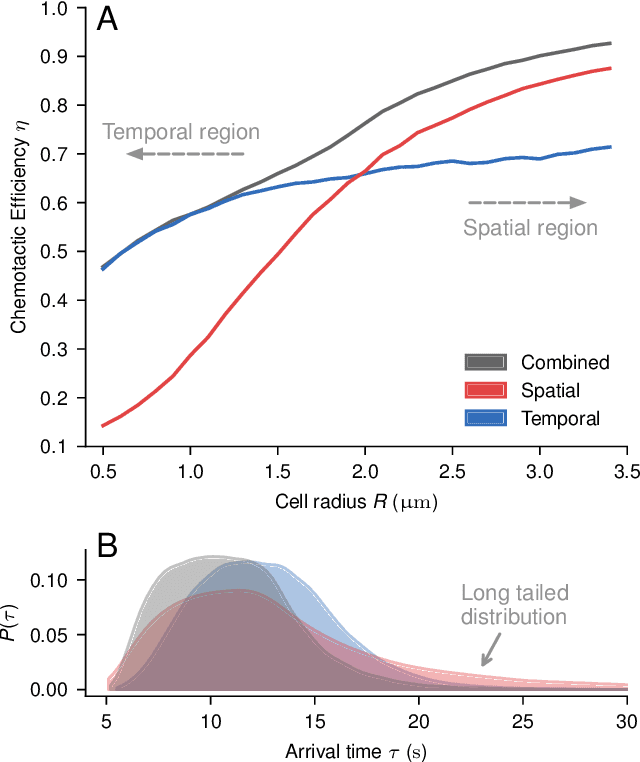
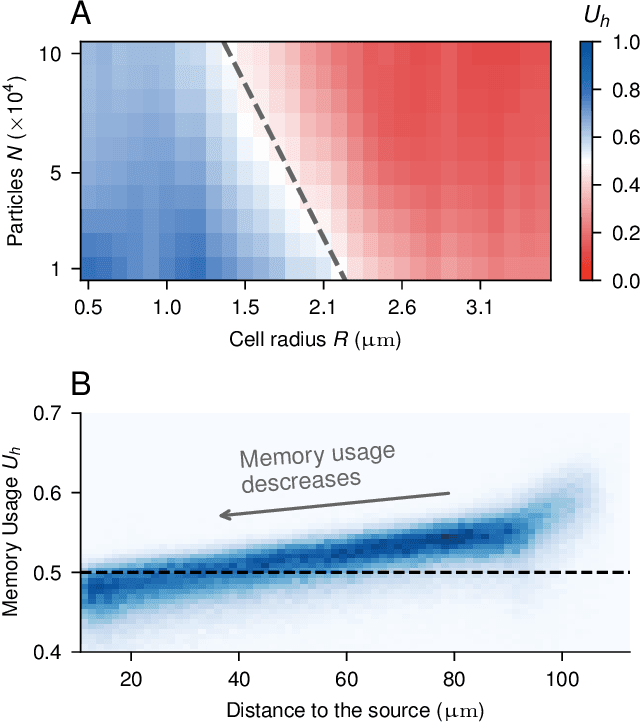
We investigate the boundary between chemotaxis driven by spatial estimation of gradients and chemotaxis driven by temporal estimation. While it is well known that spatial chemotaxis becomes disadvantageous for small organisms at high noise levels, it is unclear whether there is a discontinuous switch of optimal strategies or a continuous transition exists. Here, we employ deep reinforcement learning to study the possible integration of spatial and temporal information in an a priori unconstrained manner. We parameterize such a combined chemotactic policy by a recurrent neural network and evaluate it using a minimal theoretical model of a chemotactic cell. By comparing with constrained variants of the policy, we show that it converges to purely temporal and spatial strategies at small and large cell sizes, respectively. We find that the transition between the regimes is continuous, with the combined strategy outperforming in the transition region both the constrained variants as well as models that explicitly integrate spatial and temporal information. Finally, by utilizing the attribution method of integrated gradients, we show that the policy relies on a non-trivial combination of spatially and temporally derived gradient information in a ratio that varies dynamically during the chemotactic trajectories.
Mind the map! Accounting for existing map information when estimating online HDMaps from sensor data
Nov 17, 2023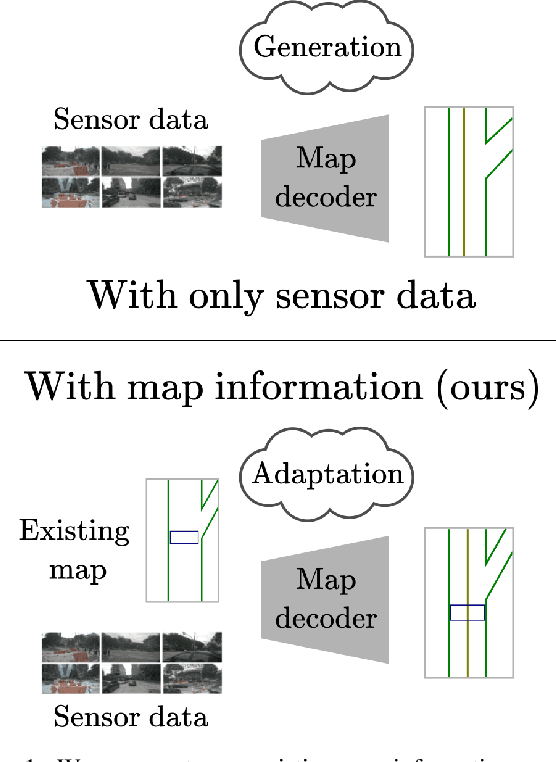
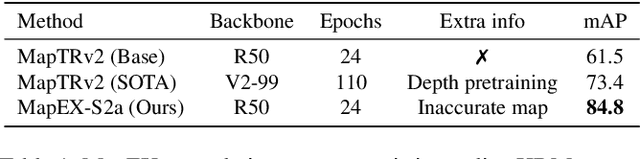
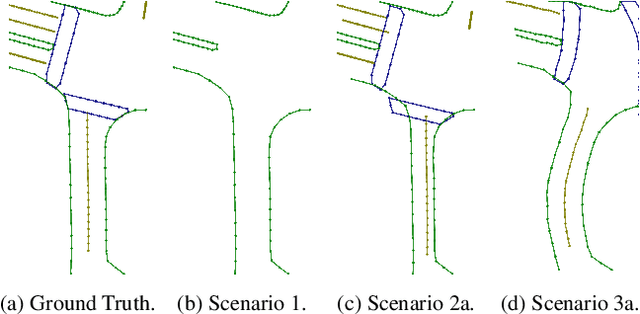
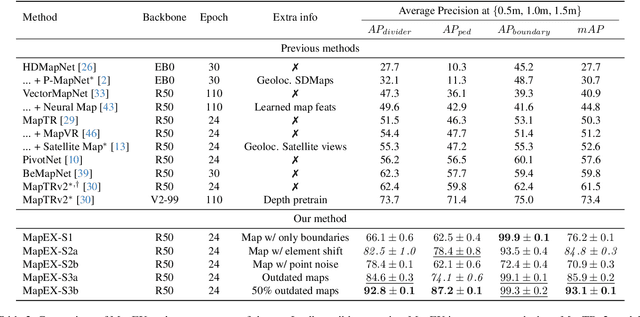
Online High Definition Map (HDMap) estimation from sensors offers a low-cost alternative to manually acquired HDMaps. As such, it promises to lighten costs for already HDMap-reliant Autonomous Driving systems, and potentially even spread their use to new systems. In this paper, we propose to improve online HDMap estimation by accounting for already existing maps. We identify 3 reasonable types of useful existing maps (minimalist, noisy, and outdated). We also introduce MapEX, a novel online HDMap estimation framework that accounts for existing maps. MapEX achieves this by encoding map elements into query tokens and by refining the matching algorithm used to train classic query based map estimation models. We demonstrate that MapEX brings significant improvements on the nuScenes dataset. For instance, MapEX - given noisy maps - improves by 38% over the MapTRv2 detector it is based on and by 16% over the current SOTA.
ImageDream: Image-Prompt Multi-view Diffusion for 3D Generation
Dec 02, 2023We introduce "ImageDream," an innovative image-prompt, multi-view diffusion model for 3D object generation. ImageDream stands out for its ability to produce 3D models of higher quality compared to existing state-of-the-art, image-conditioned methods. Our approach utilizes a canonical camera coordination for the objects in images, improving visual geometry accuracy. The model is designed with various levels of control at each block inside the diffusion model based on the input image, where global control shapes the overall object layout and local control fine-tunes the image details. The effectiveness of ImageDream is demonstrated through extensive evaluations using a standard prompt list. For more information, visit our project page at https://Image-Dream.github.io.
Design and Performance Analysis of Index Modulation Empowered AFDM System
Dec 02, 2023In this letter, we incorporate index modulation (IM) into affine frequency division multiplexing (AFDM), called AFDM-IM, to enhance the bit error rate (BER) and energy efficiency (EE) performance. In this scheme, the information bits are conveyed not only by $M$-ary constellation symbols, but also by the activation of the chirp subcarriers (SCs) indices, which are determined based on the incoming bit streams. Then, two power allocation strategies, namely power reallocation (PR) strategy and power saving (PS) strategy, are proposed to enhance BER and EE performance, respectively. Furthermore, the average bit error probability (ABEP) is theoretically analyzed. Simulation results demonstrate that the proposed AFDM-IM scheme achieves better BER performance than the conventional AFDM scheme.