 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Research on Multilingual Natural Scene Text Detection Algorithm
Dec 18, 2023
Natural scene text detection is a significant challenge in computer vision, with tremendous potential applications in multilingual, diverse, and complex text scenarios. We propose a multilingual text detection model to address the issues of low accuracy and high difficulty in detecting multilingual text in natural scenes. In response to the challenges posed by multilingual text images with multiple character sets and various font styles, we introduce the SFM Swin Transformer feature extraction network to enhance the model's robustness in detecting characters and fonts across different languages. Dealing with the considerable variation in text scales and complex arrangements in natural scene text images, we present the AS-HRFPN feature fusion network by incorporating an Adaptive Spatial Feature Fusion module and a Spatial Pyramid Pooling module. The feature fusion network improvements enhance the model's ability to detect text sizes and orientations. Addressing diverse backgrounds and font variations in multilingual scene text images is a challenge for existing methods. Limited local receptive fields hinder detection performance. To overcome this, we propose a Global Semantic Segmentation Branch, extracting and preserving global features for more effective text detection, aligning with the need for comprehensive information. In this study, we collected and built a real-world multilingual natural scene text image dataset and conducted comprehensive experiments and analyses. The experimental results demonstrate that the proposed algorithm achieves an F-measure of 85.02\%, which is 4.71\% higher than the baseline model. We also conducted extensive cross-dataset validation on MSRA-TD500, ICDAR2017MLT, and ICDAR2015 datasets to verify the generality of our approach. The code and dataset can be found at https://github.com/wangmelon/CEMLT.
Data and Approaches for German Text simplification -- towards an Accessibility-enhanced Communication
Dec 15, 2023This paper examines the current state-of-the-art of German text simplification, focusing on parallel and monolingual German corpora. It reviews neural language models for simplifying German texts and assesses their suitability for legal texts and accessibility requirements. Our findings highlight the need for additional training data and more appropriate approaches that consider the specific linguistic characteristics of German, as well as the importance of the needs and preferences of target groups with cognitive or language impairments. The authors launched the interdisciplinary OPEN-LS project in April 2023 to address these research gaps. The project aims to develop a framework for text formats tailored to individuals with low literacy levels, integrate legal texts, and enhance comprehensibility for those with linguistic or cognitive impairments. It will also explore cost-effective ways to enhance the data with audience-specific illustrations using image-generating AI. For more and up-to-date information, please visit our project homepage https://open-ls.entavis.com
Context-Driven Interactive Query Simulations Based on Generative Large Language Models
Dec 15, 2023Simulating user interactions enables a more user-oriented evaluation of information retrieval (IR) systems. While user simulations are cost-efficient and reproducible, many approaches often lack fidelity regarding real user behavior. Most notably, current user models neglect the user's context, which is the primary driver of perceived relevance and the interactions with the search results. To this end, this work introduces the simulation of context-driven query reformulations. The proposed query generation methods build upon recent Large Language Model (LLM) approaches and consider the user's context throughout the simulation of a search session. Compared to simple context-free query generation approaches, these methods show better effectiveness and allow the simulation of more efficient IR sessions. Similarly, our evaluations consider more interaction context than current session-based measures and reveal interesting complementary insights in addition to the established evaluation protocols. We conclude with directions for future work and provide an entirely open experimental setup.
Leveraging Language ID to Calculate Intermediate CTC Loss for Enhanced Code-Switching Speech Recognition
Dec 15, 2023In recent years, end-to-end speech recognition has emerged as a technology that integrates the acoustic, pronunciation dictionary, and language model components of the traditional Automatic Speech Recognition model. It is possible to achieve human-like recognition without the need to build a pronunciation dictionary in advance. However, due to the relative scarcity of training data on code-switching, the performance of ASR models tends to degrade drastically when encountering this phenomenon. Most past studies have simplified the learning complexity of the model by splitting the code-switching task into multiple tasks dealing with a single language and then learning the domain-specific knowledge of each language separately. Therefore, in this paper, we attempt to introduce language identification information into the middle layer of the ASR model's encoder. We aim to generate acoustic features that imply language distinctions in a more implicit way, reducing the model's confusion when dealing with language switching.
Image Restoration Through Generalized Ornstein-Uhlenbeck Bridge
Dec 16, 2023Diffusion models possess powerful generative capabilities enabling the mapping of noise to data using reverse stochastic differential equations. However, in image restoration tasks, the focus is on the mapping relationship from low-quality images to high-quality images. To address this, we introduced the Generalized Ornstein-Uhlenbeck Bridge (GOUB) model. By leveraging the natural mean-reverting property of the generalized OU process and further adjusting the variance of its steady-state distribution through the Doob's h-transform, we achieve diffusion mappings from point to point with minimal cost. This allows for end-to-end training, enabling the recovery of high-quality images from low-quality ones. Additionally, we uncovered the mathematical essence of some bridge models, all of which are special cases of the GOUB and empirically demonstrated the optimality of our proposed models. Furthermore, benefiting from our distinctive parameterization mechanism, we proposed the Mean-ODE model that is better at capturing pixel-level information and structural perceptions. Experimental results show that both models achieved state-of-the-art results in various tasks, including inpainting, deraining, and super-resolution. Code is available at https://github.com/Hammour-steak/GOUB.
Scalable Knowledge Graph Construction and Inference on Human Genome Variants
Dec 07, 2023Real-world knowledge can be represented as a graph consisting of entities and relationships between the entities. The need for efficient and scalable solutions arises when dealing with vast genomic data, like RNA-sequencing. Knowledge graphs offer a powerful approach for various tasks in such large-scale genomic data, such as analysis and inference. In this work, variant-level information extracted from the RNA-sequences of vaccine-na\"ive COVID-19 patients have been represented as a unified, large knowledge graph. Variant call format (VCF) files containing the variant-level information were annotated to include further information for each variant. The data records in the annotated files were then converted to Resource Description Framework (RDF) triples. Each VCF file obtained had an associated CADD scores file that contained the raw and Phred-scaled scores for each variant. An ontology was defined for the VCF and CADD scores files. Using this ontology and the extracted information, a large, scalable knowledge graph was created. Available graph storage was then leveraged to query and create datasets for further downstream tasks. We also present a case study using the knowledge graph and perform a classification task using graph machine learning. We also draw comparisons between different Graph Neural Networks (GNNs) for the case study.
Channel Charting for Streaming CSI Data
Dec 07, 2023Channel charting (CC) applies dimensionality reduction to channel state information (CSI) data at the infrastructure basestation side with the goal of extracting pseudo-position information for each user. The self-supervised nature of CC enables predictive tasks that depend on user position without requiring any ground-truth position information. In this work, we focus on the practically relevant streaming CSI data scenario, in which CSI is constantly estimated. To deal with storage limitations, we develop a novel streaming CC architecture that maintains a small core CSI dataset from which the channel charts are learned. Curation of the core CSI dataset is achieved using a min-max-similarity criterion. Numerical validation with measured CSI data demonstrates that our method approaches the accuracy obtained from the complete CSI dataset while using only a fraction of CSI storage and avoiding catastrophic forgetting of old CSI data.
Contrastive Multi-view Subspace Clustering of Hyperspectral Images based on Graph Convolutional Networks
Dec 11, 2023High-dimensional and complex spectral structures make the clustering of hyperspectral images (HSI) a challenging task. Subspace clustering is an effective approach for addressing this problem. However, current subspace clustering algorithms are primarily designed for a single view and do not fully exploit the spatial or textural feature information in HSI. In this study, contrastive multi-view subspace clustering of HSI was proposed based on graph convolutional networks. Pixel neighbor textural and spatial-spectral information were sent to construct two graph convolutional subspaces to learn their affinity matrices. To maximize the interaction between different views, a contrastive learning algorithm was introduced to promote the consistency of positive samples and assist the model in extracting robust features. An attention-based fusion module was used to adaptively integrate these affinity matrices, constructing a more discriminative affinity matrix. The model was evaluated using four popular HSI datasets: Indian Pines, Pavia University, Houston, and Xu Zhou. It achieved overall accuracies of 97.61%, 96.69%, 87.21%, and 97.65%, respectively, and significantly outperformed state-of-the-art clustering methods. In conclusion, the proposed model effectively improves the clustering accuracy of HSI.
Uncertainty Propagation through Trained Deep Neural Networks Using Factor Graphs
Dec 10, 2023Predictive uncertainty estimation remains a challenging problem precluding the use of deep neural networks as subsystems within safety-critical applications. Aleatoric uncertainty is a component of predictive uncertainty that cannot be reduced through model improvements. Uncertainty propagation seeks to estimate aleatoric uncertainty by propagating input uncertainties to network predictions. Existing uncertainty propagation techniques use one-way information flows, propagating uncertainties layer-by-layer or across the entire neural network while relying either on sampling or analytical techniques for propagation. Motivated by the complex information flows within deep neural networks (e.g. skip connections), we developed and evaluated a novel approach by posing uncertainty propagation as a non-linear optimization problem using factor graphs. We observed statistically significant improvements in performance over prior work when using factor graphs across most of our experiments that included three datasets and two neural network architectures. Our implementation balances the benefits of sampling and analytical propagation techniques, which we believe, is a key factor in achieving performance improvements.
Interpretable Diffusion via Information Decomposition
Oct 12, 2023


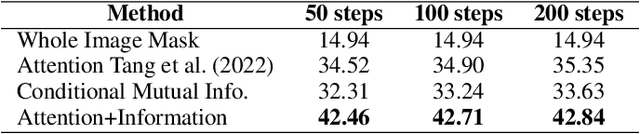
Denoising diffusion models enable conditional generation and density modeling of complex relationships like images and text. However, the nature of the learned relationships is opaque making it difficult to understand precisely what relationships between words and parts of an image are captured, or to predict the effect of an intervention. We illuminate the fine-grained relationships learned by diffusion models by noticing a precise relationship between diffusion and information decomposition. Exact expressions for mutual information and conditional mutual information can be written in terms of the denoising model. Furthermore, pointwise estimates can be easily estimated as well, allowing us to ask questions about the relationships between specific images and captions. Decomposing information even further to understand which variables in a high-dimensional space carry information is a long-standing problem. For diffusion models, we show that a natural non-negative decomposition of mutual information emerges, allowing us to quantify informative relationships between words and pixels in an image. We exploit these new relations to measure the compositional understanding of diffusion models, to do unsupervised localization of objects in images, and to measure effects when selectively editing images through prompt interventions.