 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Text-Aware Predictive Monitoring of Business Processes
Apr 20, 2021
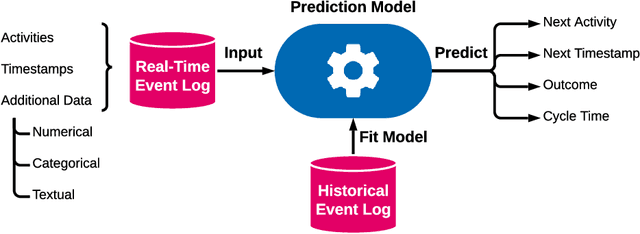

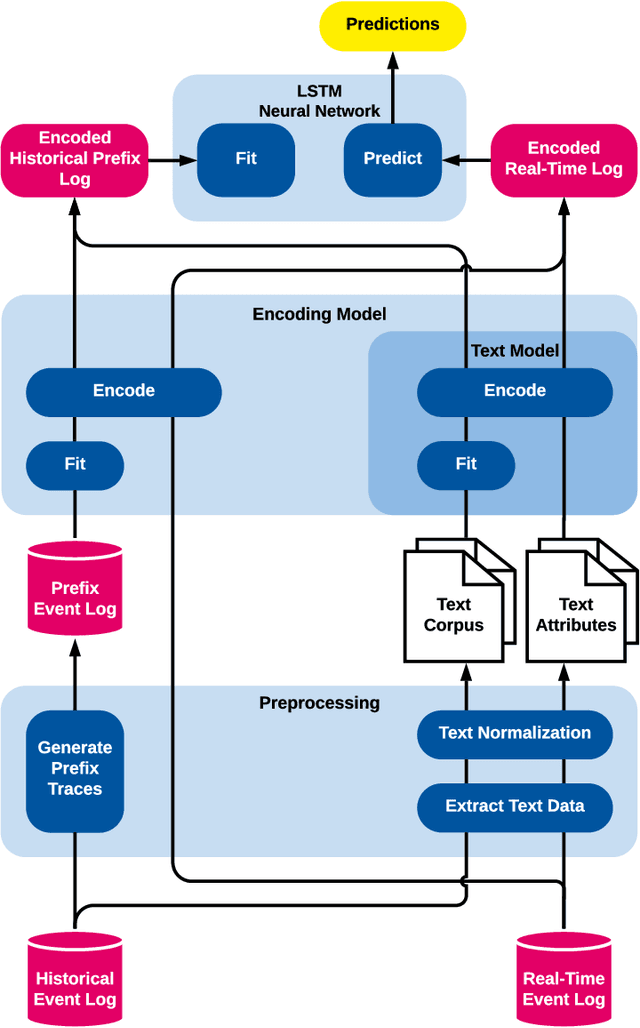
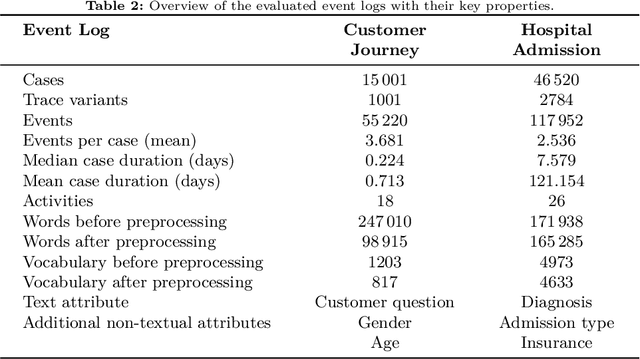
The real-time prediction of business processes using historical event data is an important capability of modern business process monitoring systems. Existing process prediction methods are able to also exploit the data perspective of recorded events, in addition to the control-flow perspective. However, while well-structured numerical or categorical attributes are considered in many prediction techniques, almost no technique is able to utilize text documents written in natural language, which can hold information critical to the prediction task. In this paper, we illustrate the design, implementation, and evaluation of a novel text-aware process prediction model based on Long Short-Term Memory (LSTM) neural networks and natural language models. The proposed model can take categorical, numerical and textual attributes in event data into account to predict the activity and timestamp of the next event, the outcome, and the cycle time of a running process instance. Experiments show that the text-aware model is able to outperform state-of-the-art process prediction methods on simulated and real-world event logs containing textual data.
The World as a Graph: Improving El Niño Forecasts with Graph Neural Networks
Apr 11, 2021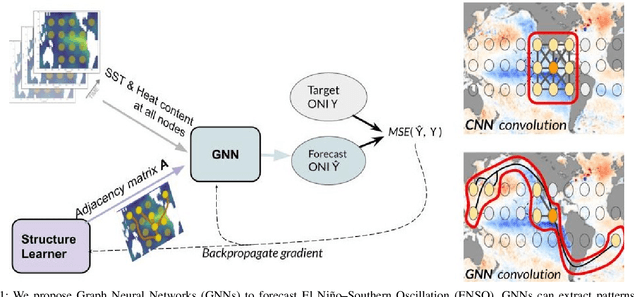
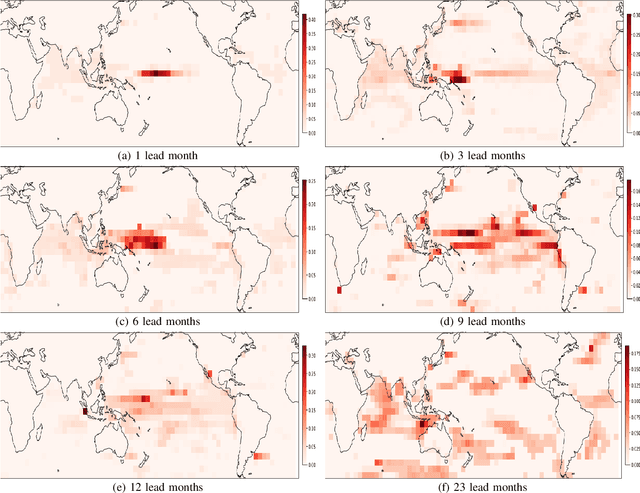
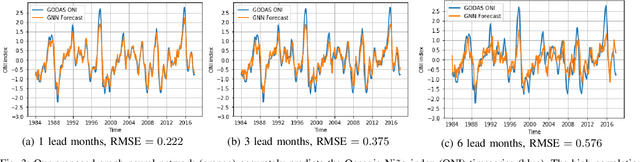
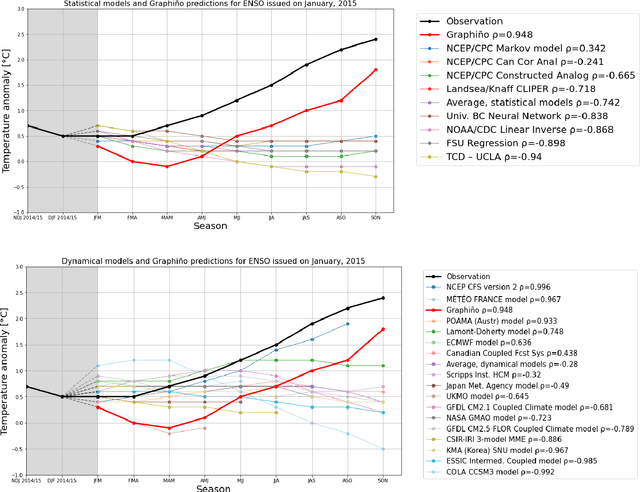
Deep learning-based models have recently outperformed state-of-the-art seasonal forecasting models, such as for predicting El Ni\~no-Southern Oscillation (ENSO). However, current deep learning models are based on convolutional neural networks which are difficult to interpret and can fail to model large-scale atmospheric patterns. In comparison, graph neural networks (GNNs) are capable of modeling large-scale spatial dependencies and are more interpretable due to the explicit modeling of information flow through edge connections. We propose the first application of graph neural networks to seasonal forecasting. We design a novel graph connectivity learning module that enables our GNN model to learn large-scale spatial interactions jointly with the actual ENSO forecasting task. Our model, \graphino, outperforms state-of-the-art deep learning-based models for forecasts up to six months ahead. Additionally, we show that our model is more interpretable as it learns sensible connectivity structures that correlate with the ENSO anomaly pattern.
The principle of weight divergence facilitation for unsupervised pattern recognition in spiking neural networks
Apr 20, 2021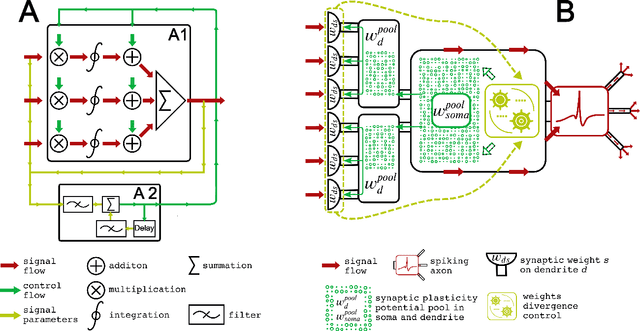
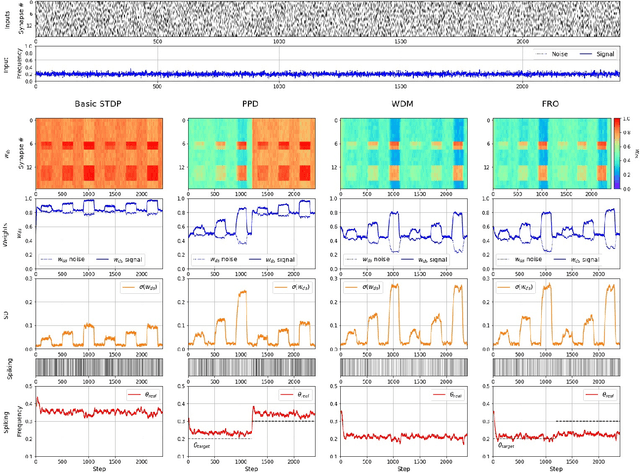
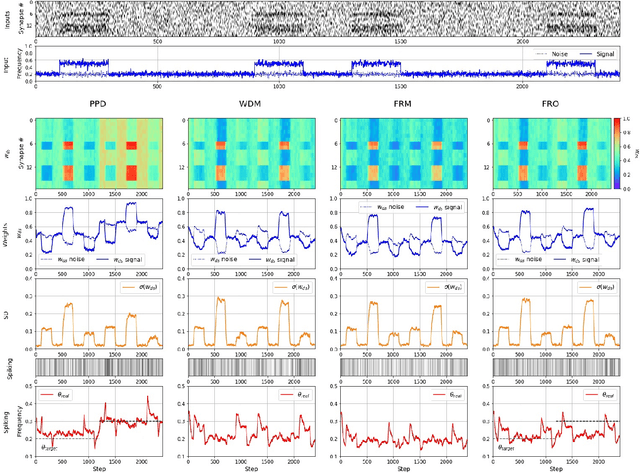
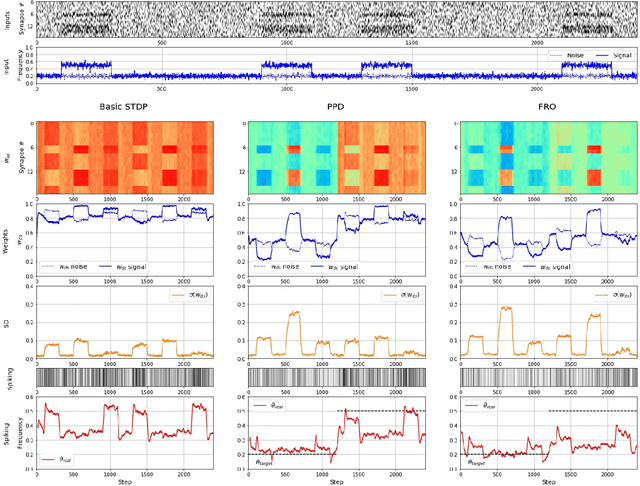
Parallels between the signal processing tasks and biological neurons lead to an understanding of the principles of self-organized optimization of input signal recognition. In the present paper, we discuss such similarities among biological and technical systems. We propose the addition to the well-known STDP synaptic plasticity rule to directs the weight modification towards the state associated with the maximal difference between the background noise and correlated signals. The principle of physically constrained weight growth is used as a basis for such control of the modification of the weights. It is proposed, that biological synaptic straight modification is restricted by the existence and production of bio-chemical 'substances' needed for plasticity development. In this paper, the information about the noise-to-signal ratio is used to control such a substances' production and storage and to drive the neuron's synaptic pressures towards the state with the best signal-to-noise ratio. Several experiments with different input signal regimes are considered to understand the functioning of the proposed approach.
Surrogate assisted active subspace and active subspace assisted surrogate -- A new paradigm for high dimensional structural reliability analysis
May 12, 2021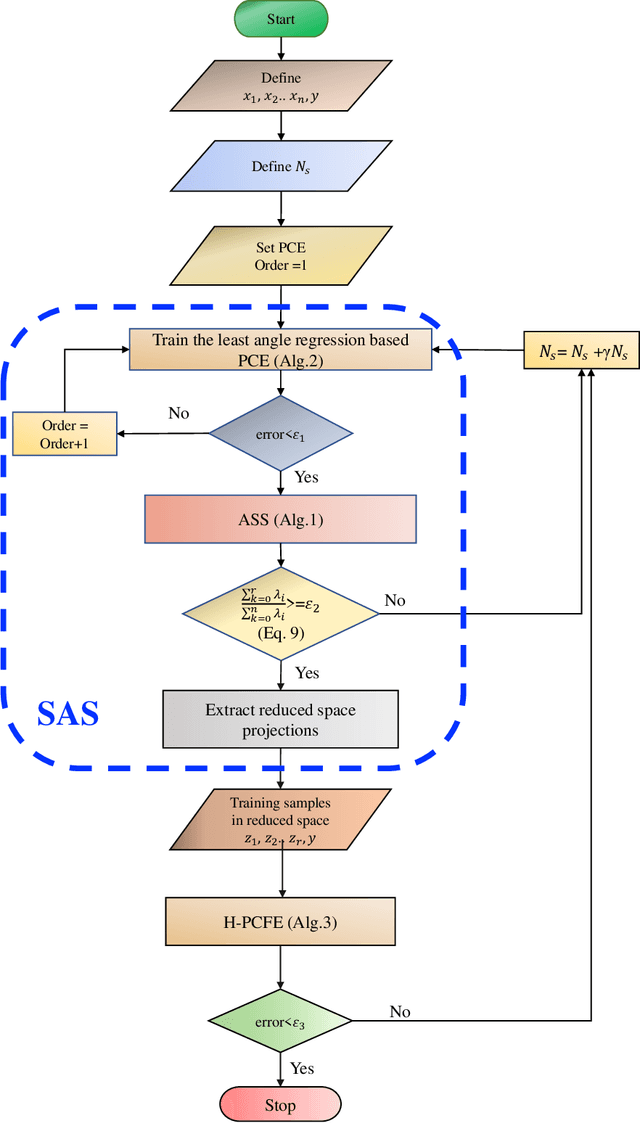
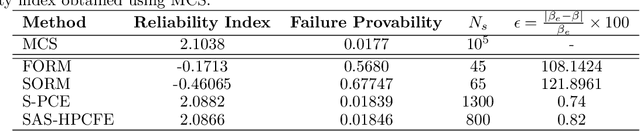
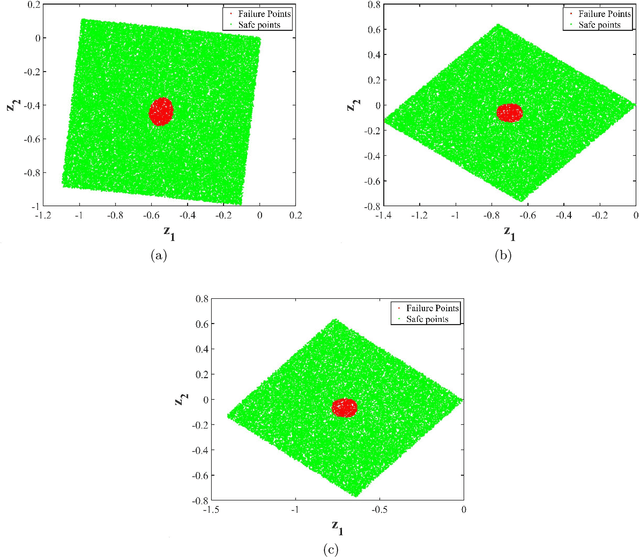
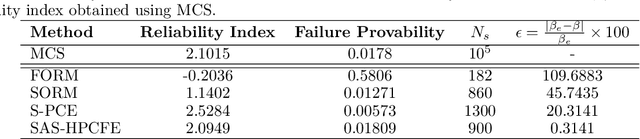
Performing reliability analysis on complex systems is often computationally expensive. In particular, when dealing with systems having high input dimensionality, reliability estimation becomes a daunting task. A popular approach to overcome the problem associated with time-consuming and expensive evaluations is building a surrogate model. However, these computationally efficient models often suffer from the curse of dimensionality. Hence, training a surrogate model for high-dimensional problems is not straightforward. Henceforth, this paper presents a framework for solving high-dimensional reliability analysis problems. The basic premise is to train the surrogate model on a low-dimensional manifold, discovered using the active subspace algorithm. However, learning the low-dimensional manifold using active subspace is non-trivial as it requires information on the gradient of the response variable. To address this issue, we propose using sparse learning algorithms in conjunction with the active subspace algorithm; the resulting algorithm is referred to as the sparse active subspace (SAS) algorithm. We project the high-dimensional inputs onto the identified low-dimensional manifold identified using SAS. A high-fidelity surrogate model is used to map the inputs on the low-dimensional manifolds to the output response. We illustrate the efficacy of the proposed framework by using three benchmark reliability analysis problems from the literature. The results obtained indicate the accuracy and efficiency of the proposed approach compared to already established reliability analysis methods in the literature.
Introducing the Talk Markup Language (TalkML):Adding a little social intelligence to industrial speech interfaces
May 24, 2021



Virtual Personal Assistants like Siri have great potential but such developments hit the fundamental problem of how to make computational devices that understand human speech. Natural language understanding is one of the more disappointing failures of AI research and it seems there is something we computer scientists don't get about the nature of language. Of course philosophers and linguists think quite differently about language and this paper describes how we have taken ideas from other disciplines and implemented them. The background to the work is to take seriously the notion of language as action and look at what people actually do with language using the techniques of Conversation Analysis. The observation has been that human communication is (behind the scenes) about the management of social relations as well as the (foregrounded) passing of information. To claim this is one thing but to implement it requires a mechanism. The mechanism described here is based on the notion of language being intentional - we think intentionally, talk about them and recognise them in others - and cooperative in that we are compelled to help out. The way we are compelled points to a solution to the ever present problem of keeping the human on topic. The approach has led to a recent success in which we significantly improve user satisfaction independent of task completion. Talk Markup Language (TalkML) is a draft alternative to VoiceXML that, we propose, greatly simplifies the scripting of interaction by providing default behaviours for no input and not recognised speech events.
Hierarchical Representation via Message Propagation for Robust Model Fitting
Dec 29, 2020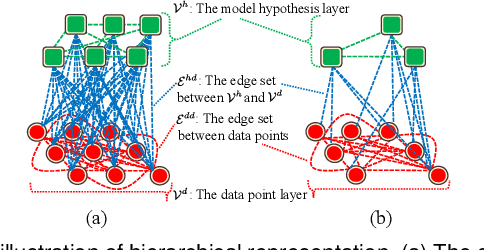


In this paper, we propose a novel hierarchical representation via message propagation (HRMP) method for robust model fitting, which simultaneously takes advantages of both the consensus analysis and the preference analysis to estimate the parameters of multiple model instances from data corrupted by outliers, for robust model fitting. Instead of analyzing the information of each data point or each model hypothesis independently, we formulate the consensus information and the preference information as a hierarchical representation to alleviate the sensitivity to gross outliers. Specifically, we firstly construct a hierarchical representation, which consists of a model hypothesis layer and a data point layer. The model hypothesis layer is used to remove insignificant model hypotheses and the data point layer is used to remove gross outliers. Then, based on the hierarchical representation, we propose an effective hierarchical message propagation (HMP) algorithm and an improved affinity propagation (IAP) algorithm to prune insignificant vertices and cluster the remaining data points, respectively. The proposed HRMP can not only accurately estimate the number and parameters of multiple model instances, but also handle multi-structural data contaminated with a large number of outliers. Experimental results on both synthetic data and real images show that the proposed HRMP significantly outperforms several state-of-the-art model fitting methods in terms of fitting accuracy and speed.
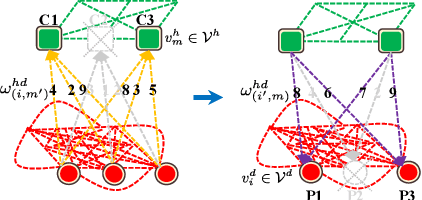
Gradient-Free Neural Network Training via Synaptic-Level Reinforcement Learning
May 29, 2021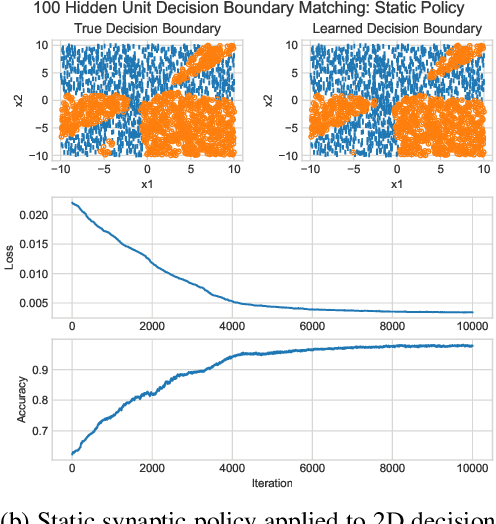
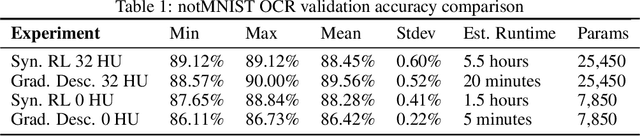
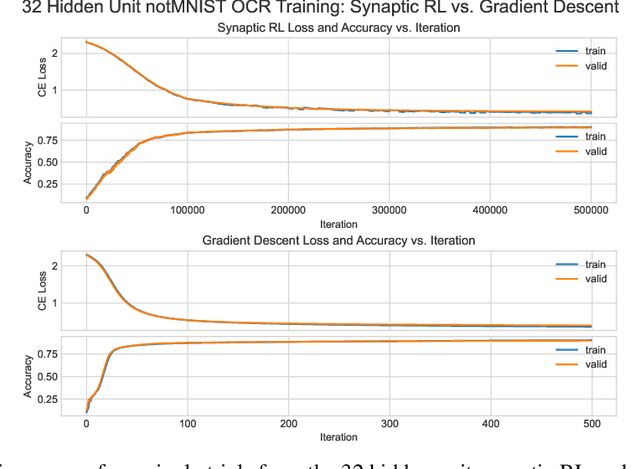
An ongoing challenge in neural information processing is: how do neurons adjust their connectivity to improve task performance over time (i.e., actualize learning)? It is widely believed that there is a consistent, synaptic-level learning mechanism in specific brain regions that actualizes learning. However, the exact nature of this mechanism remains unclear. Here we propose an algorithm based on reinforcement learning (RL) to generate and apply a simple synaptic-level learning policy for multi-layer perceptron (MLP) models. In this algorithm, the action space for each MLP synapse consists of a small increase, decrease, or null action on the synapse weight, and the state for each synapse consists of the last two actions and reward signals. A binary reward signal indicates improvement or deterioration in task performance. The static policy produces superior training relative to the adaptive policy and is agnostic to activation function, network shape, and task. Trained MLPs yield character recognition performance comparable to identically shaped networks trained with gradient descent. 0 hidden unit character recognition tests yielded an average validation accuracy of 88.28%, 1.86$\pm$0.47% higher than the same MLP trained with gradient descent. 32 hidden unit character recognition tests yielded an average validation accuracy of 88.45%, 1.11$\pm$0.79% lower than the same MLP trained with gradient descent. The robustness and lack of reliance on gradient computations opens the door for new techniques for training difficult-to-differentiate artificial neural networks such as spiking neural networks (SNNs) and recurrent neural networks (RNNs). Further, the method's simplicity provides a unique opportunity for further development of local rule-driven multi-agent connectionist models for machine intelligence analogous to cellular automata.
Rank-R FNN: A Tensor-Based Learning Model for High-Order Data Classification
Apr 11, 2021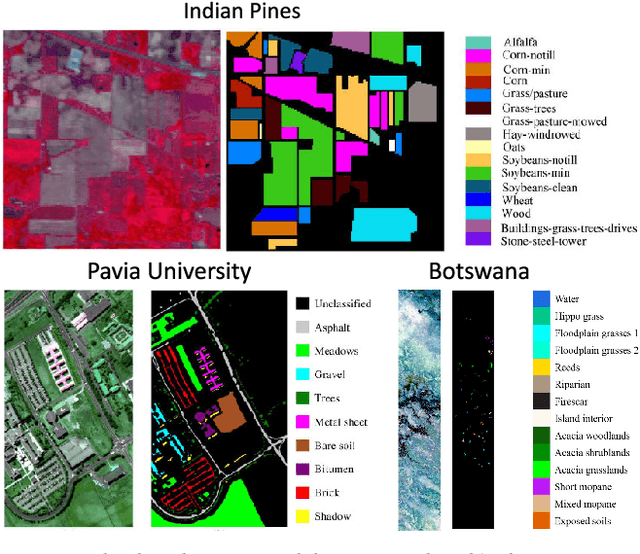
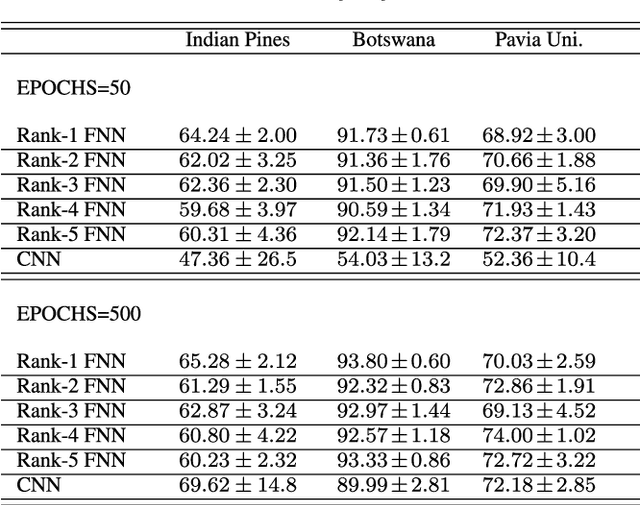
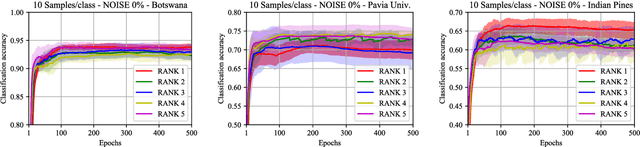
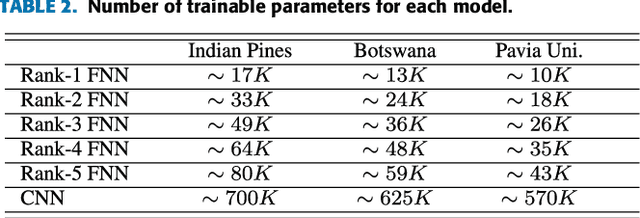
An increasing number of emerging applications in data science and engineering are based on multidimensional and structurally rich data. The irregularities, however, of high-dimensional data often compromise the effectiveness of standard machine learning algorithms. We hereby propose the Rank-R Feedforward Neural Network (FNN), a tensor-based nonlinear learning model that imposes Canonical/Polyadic decomposition on its parameters, thereby offering two core advantages compared to typical machine learning methods. First, it handles inputs as multilinear arrays, bypassing the need for vectorization, and can thus fully exploit the structural information along every data dimension. Moreover, the number of the model's trainable parameters is substantially reduced, making it very efficient for small sample setting problems. We establish the universal approximation and learnability properties of Rank-R FNN, and we validate its performance on real-world hyperspectral datasets. Experimental evaluations show that Rank-R FNN is a computationally inexpensive alternative of ordinary FNN that achieves state-of-the-art performance on higher-order tensor data.
Symmetry Breaking in Symmetric Tensor Decomposition
Mar 10, 2021
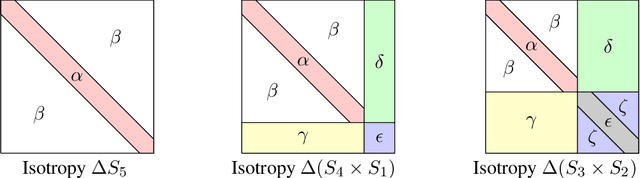
In this note, we consider the optimization problem associated with computing the rank decomposition of a symmetric tensor. We show that, in a well-defined sense, minima in this highly nonconvex optimization problem break the symmetry of the target tensor -- but not too much. This phenomenon of symmetry breaking applies to various choices of tensor norms, and makes it possible to study the optimization landscape using a set of recently-developed symmetry-based analytical tools. The fact that the objective function under consideration is a multivariate polynomial allows us to apply symbolic methods from computational algebra to obtain more refined information on the symmetry breaking phenomenon.
Dependent Multi-Task Learning with Causal Intervention for Image Captioning
May 18, 2021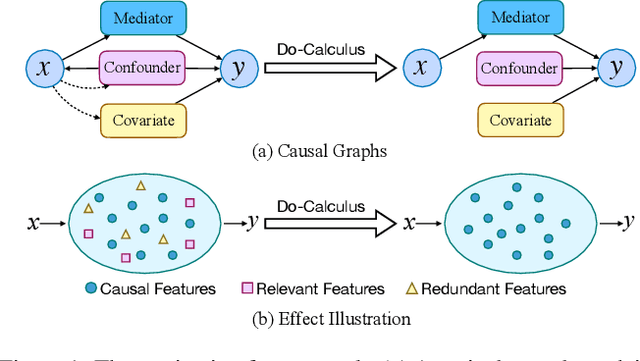
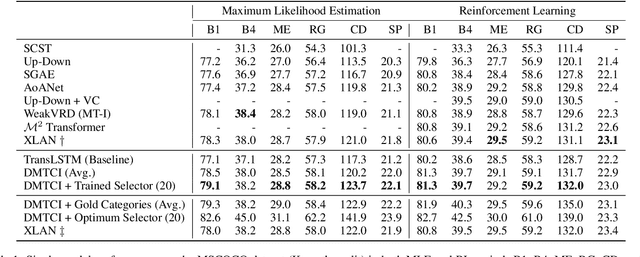
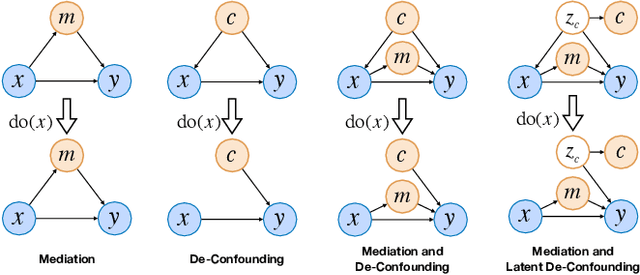
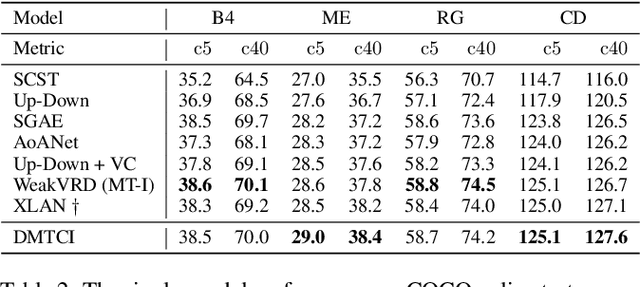
Recent work for image captioning mainly followed an extract-then-generate paradigm, pre-extracting a sequence of object-based features and then formulating image captioning as a single sequence-to-sequence task. Although promising, we observed two problems in generated captions: 1) content inconsistency where models would generate contradicting facts; 2) not informative enough where models would miss parts of important information. From a causal perspective, the reason is that models have captured spurious statistical correlations between visual features and certain expressions (e.g., visual features of "long hair" and "woman"). In this paper, we propose a dependent multi-task learning framework with the causal intervention (DMTCI). Firstly, we involve an intermediate task, bag-of-categories generation, before the final task, image captioning. The intermediate task would help the model better understand the visual features and thus alleviate the content inconsistency problem. Secondly, we apply Pearl's do-calculus on the model, cutting off the link between the visual features and possible confounders and thus letting models focus on the causal visual features. Specifically, the high-frequency concept set is considered as the proxy confounders where the real confounders are inferred in the continuous space. Finally, we use a multi-agent reinforcement learning (MARL) strategy to enable end-to-end training and reduce the inter-task error accumulations. The extensive experiments show that our model outperforms the baseline models and achieves competitive performance with state-of-the-art models.