 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Knowledge Graphs Enhance Medical Question Answering: Bridging the Gap Between LLMs and Evolving Medical Knowledge
Feb 18, 2025



Large Language Models (LLMs) have significantly advanced medical question-answering by leveraging extensive clinical data and medical literature. However, the rapid evolution of medical knowledge and the labor-intensive process of manually updating domain-specific resources pose challenges to the reliability of these systems. To address this, we introduce Adaptive Medical Graph-RAG (AMG-RAG), a comprehensive framework that automates the construction and continuous updating of medical knowledge graphs, integrates reasoning, and retrieves current external evidence, such as PubMed and WikiSearch. By dynamically linking new findings and complex medical concepts, AMG-RAG not only improves accuracy but also enhances interpretability in medical queries. Evaluations on the MEDQA and MEDMCQA benchmarks demonstrate the effectiveness of AMG-RAG, achieving an F1 score of 74.1 percent on MEDQA and an accuracy of 66.34 percent on MEDMCQA, outperforming both comparable models and those 10 to 100 times larger. Notably, these improvements are achieved without increasing computational overhead, highlighting the critical role of automated knowledge graph generation and external evidence retrieval in delivering up-to-date, trustworthy medical insights.
Stochastic Sparse Sampling: A Framework for Variable-Length Medical Time Series Classification
Oct 08, 2024While the majority of time series classification research has focused on modeling fixed-length sequences, variable-length time series classification (VTSC) remains critical in healthcare, where sequence length may vary among patients and events. To address this challenge, we propose $\textbf{S}$tochastic $\textbf{S}$parse $\textbf{S}$ampling (SSS), a novel VTSC framework developed for medical time series. SSS manages variable-length sequences by sparsely sampling fixed windows to compute local predictions, which are then aggregated and calibrated to form a global prediction. We apply SSS to the task of seizure onset zone (SOZ) localization, a critical VTSC problem requiring identification of seizure-inducing brain regions from variable-length electrophysiological time series. We evaluate our method on the Epilepsy iEEG Multicenter Dataset, a heterogeneous collection of intracranial electroencephalography (iEEG) recordings obtained from four independent medical centers. SSS demonstrates superior performance compared to state-of-the-art (SOTA) baselines across most medical centers, and superior performance on all out-of-distribution (OOD) unseen medical centers. Additionally, SSS naturally provides post-hoc insights into local signal characteristics related to the SOZ, by visualizing temporally averaged local predictions throughout the signal.
Implicit Dynamical Flow Fusion (IDFF) for Generative Modeling
Sep 22, 2024



Conditional Flow Matching (CFM) models can generate high-quality samples from a non-informative prior, but they can be slow, often needing hundreds of network evaluations (NFE). To address this, we propose Implicit Dynamical Flow Fusion (IDFF); IDFF learns a new vector field with an additional momentum term that enables taking longer steps during sample generation while maintaining the fidelity of the generated distribution. Consequently, IDFFs reduce the NFEs by a factor of ten (relative to CFMs) without sacrificing sample quality, enabling rapid sampling and efficient handling of image and time-series data generation tasks. We evaluate IDFF on standard benchmarks such as CIFAR-10 and CelebA for image generation. We achieved likelihood and quality performance comparable to CFMs and diffusion-based models with fewer NFEs. IDFF also shows superior performance on time-series datasets modeling, including molecular simulation and sea surface temperature (SST) datasets, highlighting its versatility and effectiveness across different domains.
Uncovering the Origins of Instability in Dynamical Systems: How Attention Mechanism Can Help?
Dec 19, 2022The behavior of the network and its stability are governed by both dynamics of individual nodes as well as their topological interconnections. Attention mechanism as an integral part of neural network models was initially designed for natural language processing (NLP), and so far, has shown excellent performance in combining dynamics of individual nodes and the coupling strengths between them within a network. Despite undoubted impact of attention mechanism, it is not yet clear why some nodes of a network get higher attention weights. To come up with more explainable solutions, we tried to look at the problem from stability perspective. Based on stability theory, negative connections in a network can create feedback loops or other complex structures by allowing information to flow in the opposite direction. These structures play a critical role in the dynamics of a complex system and can contribute to abnormal synchronization, amplification, or suppression. We hypothesized that those nodes that are involved in organizing such structures can push the entire network into instability modes and therefore need higher attention during analysis. To test this hypothesis, attention mechanism along with spectral and topological stability analyses was performed on a real-world numerical problem, i.e., a linear Multi Input Multi Output state-space model of a piezoelectric tube actuator. The findings of our study suggest that the attention should be directed toward the collective behaviour of imbalanced structures and polarity-driven structural instabilities within the network. The results demonstrated that the nodes receiving more attention cause more instability in the system. Our study provides a proof of concept to understand why perturbing some nodes of a network may cause dramatic changes in the network dynamics.
Deep Discriminative Direct Decoders for High-dimensional Time-series Analysis
May 22, 2022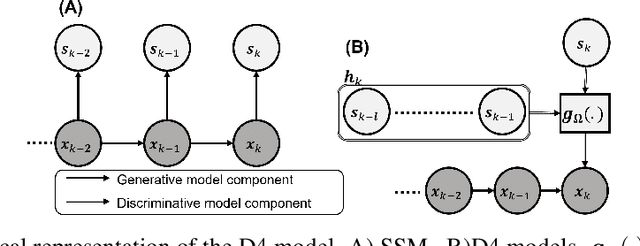
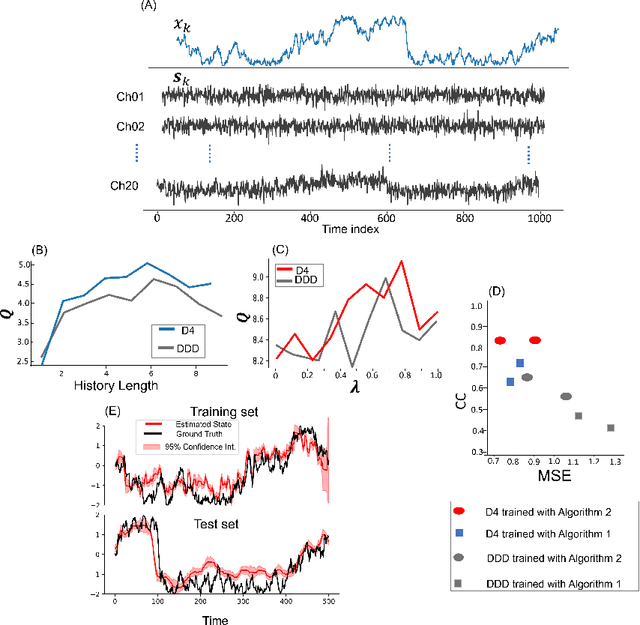
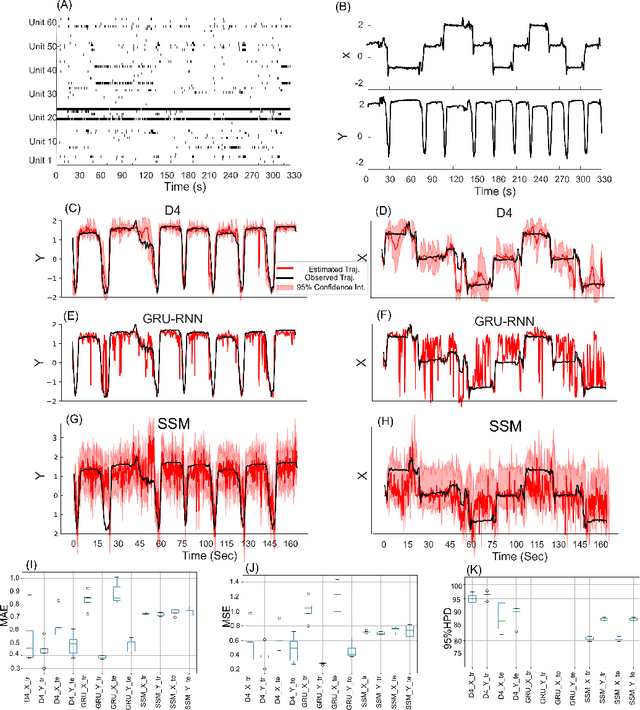
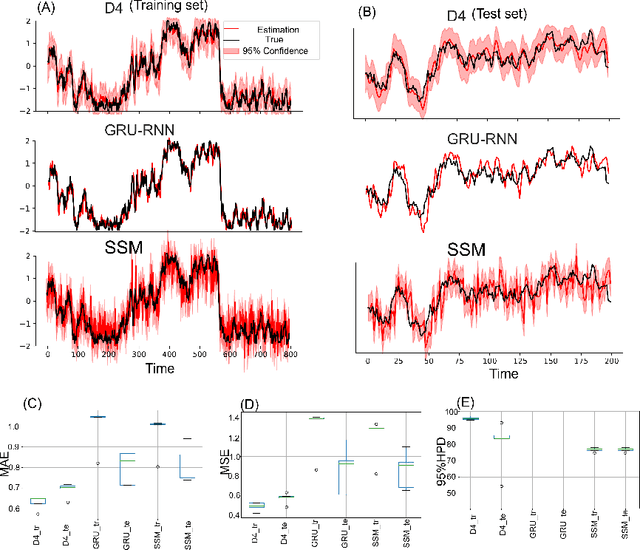
Dynamical latent variable modeling has been significantly invested over the last couple of decades with established solutions encompassing generative processes like the state-space model (SSM) and discriminative processes like a recurrent or a deep neural network (DNN). These solutions are powerful tools with promising results; however, surprisingly they were never put together in a unified model to analyze complex multivariate time-series data. A very recent modeling approach, called the direct discriminative decoder (DDD) model, proposes a principal solution to combine SMM and DNN models, with promising results in decoding underlying latent processes, e.g. rat movement trajectory, through high-dimensional neural recordings. The DDD consists of a) a state transition process, as per the classical dynamical models, and b) a discriminative process, like DNN, in which the conditional distribution of states is defined as a function of the current observations and their recent history. Despite promising results of the DDD model, no training solutions, in the context of DNN, have been utilized for this model. Here, we propose how DNN parameters along with an optimal history term can be simultaneously estimated as a part of the DDD model. We use the D4 abbreviation for a DDD with a DNN as its discriminative process. We showed the D4 decoding performance in both simulation and (relatively) high-dimensional neural data. In both datasets, D4 performance surpasses the state-of-art decoding solutions, including those of SSM and DNNs. The key success of DDD and potentially D4 is efficient utilization of the recent history of observation along with the state-process that carries long-term information, which is not addressed in either SSM or DNN solutions. We argue that D4 can be a powerful tool for the analysis of high-dimensional time-series data.
Gradient-Free Neural Network Training via Synaptic-Level Reinforcement Learning
May 29, 2021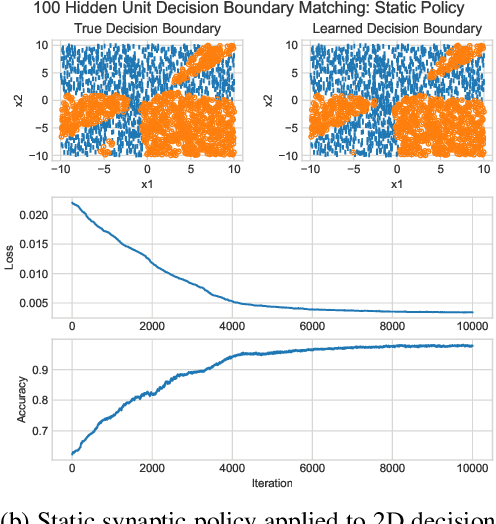
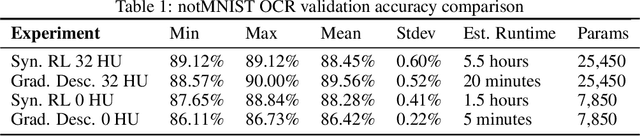
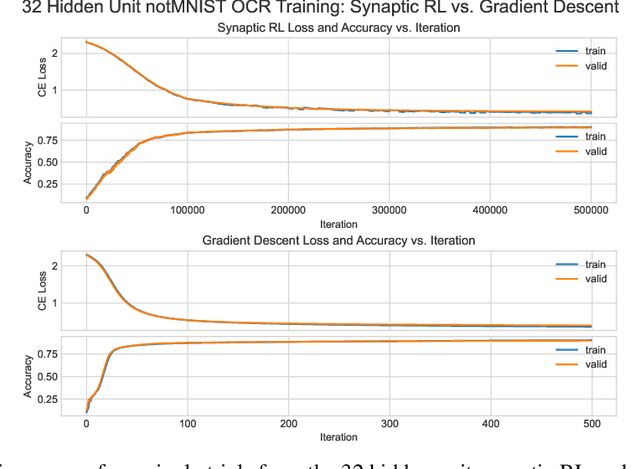
An ongoing challenge in neural information processing is: how do neurons adjust their connectivity to improve task performance over time (i.e., actualize learning)? It is widely believed that there is a consistent, synaptic-level learning mechanism in specific brain regions that actualizes learning. However, the exact nature of this mechanism remains unclear. Here we propose an algorithm based on reinforcement learning (RL) to generate and apply a simple synaptic-level learning policy for multi-layer perceptron (MLP) models. In this algorithm, the action space for each MLP synapse consists of a small increase, decrease, or null action on the synapse weight, and the state for each synapse consists of the last two actions and reward signals. A binary reward signal indicates improvement or deterioration in task performance. The static policy produces superior training relative to the adaptive policy and is agnostic to activation function, network shape, and task. Trained MLPs yield character recognition performance comparable to identically shaped networks trained with gradient descent. 0 hidden unit character recognition tests yielded an average validation accuracy of 88.28%, 1.86$\pm$0.47% higher than the same MLP trained with gradient descent. 32 hidden unit character recognition tests yielded an average validation accuracy of 88.45%, 1.11$\pm$0.79% lower than the same MLP trained with gradient descent. The robustness and lack of reliance on gradient computations opens the door for new techniques for training difficult-to-differentiate artificial neural networks such as spiking neural networks (SNNs) and recurrent neural networks (RNNs). Further, the method's simplicity provides a unique opportunity for further development of local rule-driven multi-agent connectionist models for machine intelligence analogous to cellular automata.