 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Characterizing Residential Load Patterns by Household Demographic and Socioeconomic Factors
Jun 04, 2021
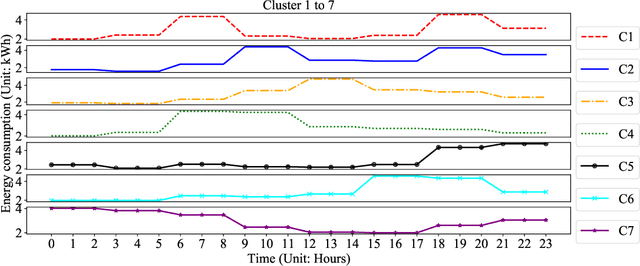
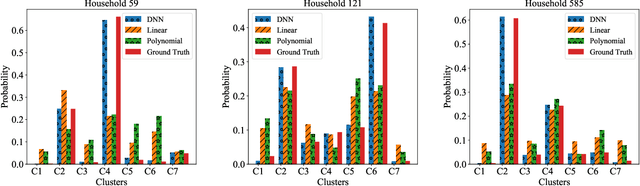
The wide adoption of smart meters makes residential load data available and thus improves the understanding of the energy consumption behavior. Many existing studies have focused on smart-meter data analysis, but the drivers of energy consumption behaviors are not well understood. This paper aims to characterize and estimate users' load patterns based on their demographic and socioeconomic information. We adopt the symbolic aggregate approximation (SAX) method to process the load data and use the K-Means method to extract key load patterns. We develop a deep neural network (DNN) to analyze the relationship between users' load patterns and their demographic and socioeconomic features. Using real-world load data, we validate our framework and demonstrate the connections between load patterns and household demographic and socioeconomic features. We also take two regression models as benchmarks for comparisons.
Modelling the Influence of Cultural Information on Vision-Based Human Home Activity Recognition
Mar 21, 2018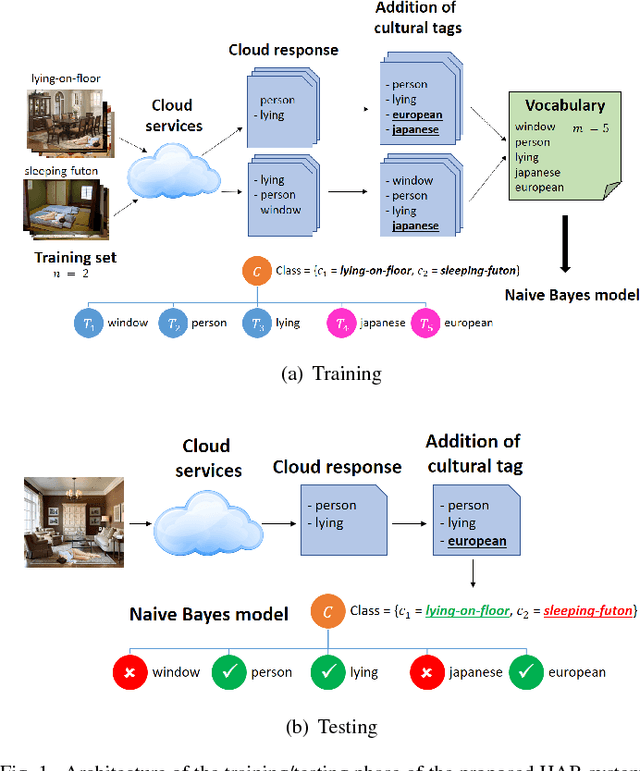
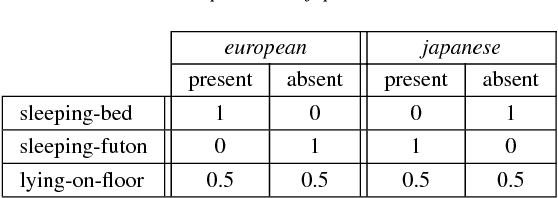

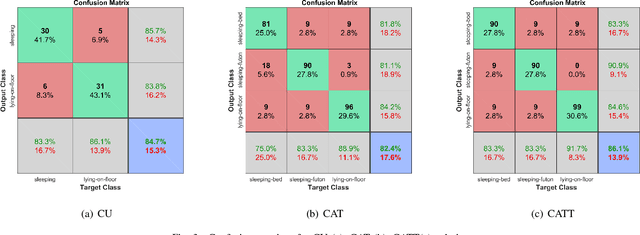
Daily life activities, such as eating and sleeping, are deeply influenced by a person's culture, hence generating differences in the way a same activity is performed by individuals belonging to different cultures. We argue that taking cultural information into account can improve the performance of systems for the automated recognition of human activities. We propose four different solutions to the problem and present a system which uses a Naive Bayes model to associate cultural information with semantic information extracted from still images. Preliminary experiments with a dataset of images of individuals lying on the floor, sleeping on a futon and sleeping on a bed suggest that: i) solutions explicitly taking cultural information into account are more accurate than culture-unaware solutions; and ii) the proposed system is a promising starting point for the development of culture-aware Human Activity Recognition methods.
* 7 pages, 4 figures, Proc. URAI2017, International Conference on Ubiquitous Robots and Ambient Intelligence, Maison Glad Jeju, Jeju, Korea from June 28-July 2017
ESAI: Efficient Split Artificial Intelligence via Early Exiting Using Neural Architecture Search
Jun 21, 2021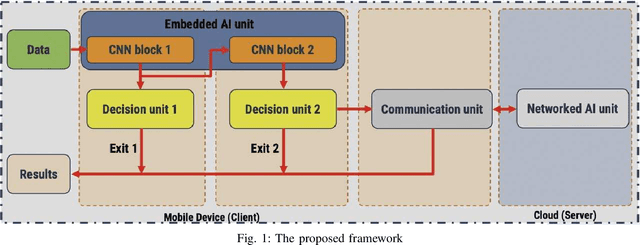
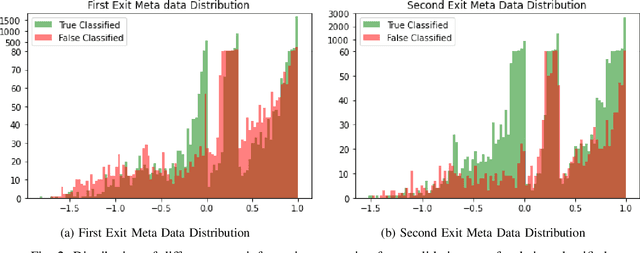
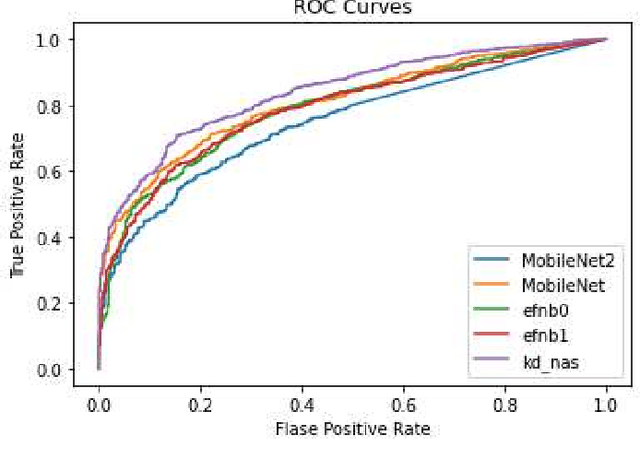
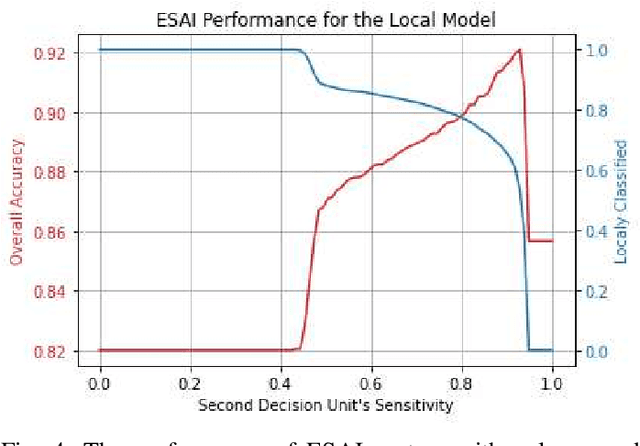
Recently, deep neural networks have been outperforming conventional machine learning algorithms in many computer vision-related tasks. However, it is not computationally acceptable to implement these models on mobile and IoT devices and the majority of devices are harnessing the cloud computing methodology in which outstanding deep learning models are responsible for analyzing the data on the server. This can bring the communication cost for the devices and make the whole system useless in those times where the communication is not available. In this paper, a new framework for deploying on IoT devices has been proposed which can take advantage of both the cloud and the on-device models by extracting the meta-information from each sample's classification result and evaluating the classification's performance for the necessity of sending the sample to the server. Experimental results show that only 40 percent of the test data should be sent to the server using this technique and the overall accuracy of the framework is 92 percent which improves the accuracy of both client and server models.
Stage-wise Fine-tuning for Graph-to-Text Generation
May 30, 2021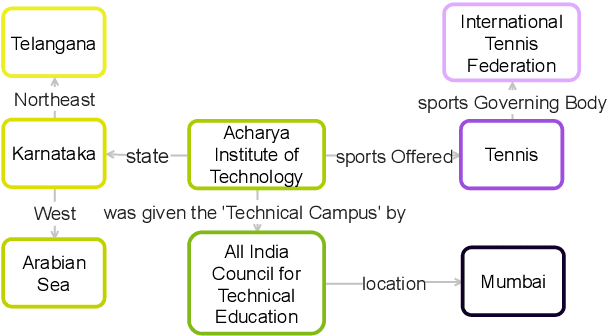

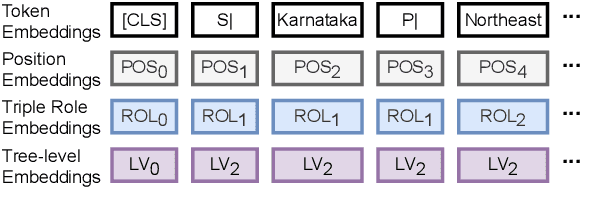
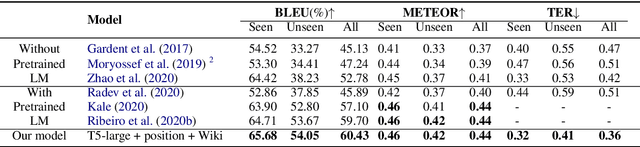
Graph-to-text generation has benefited from pre-trained language models (PLMs) in achieving better performance than structured graph encoders. However, they fail to fully utilize the structure information of the input graph. In this paper, we aim to further improve the performance of the pre-trained language model by proposing a structured graph-to-text model with a two-step fine-tuning mechanism which first fine-tunes the model on Wikipedia before adapting to the graph-to-text generation. In addition to using the traditional token and position embeddings to encode the knowledge graph (KG), we propose a novel tree-level embedding method to capture the inter-dependency structures of the input graph. This new approach has significantly improved the performance of all text generation metrics for the English WebNLG 2017 dataset.
CUDA-GR: Controllable Unsupervised Domain Adaptation for Gaze Redirection
Jun 21, 2021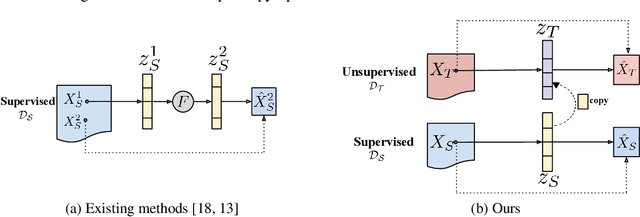
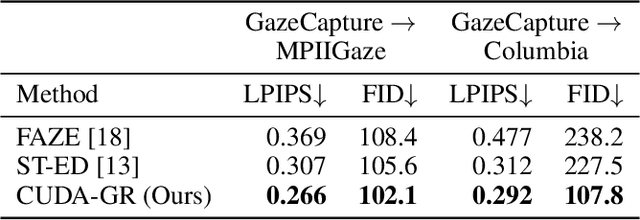
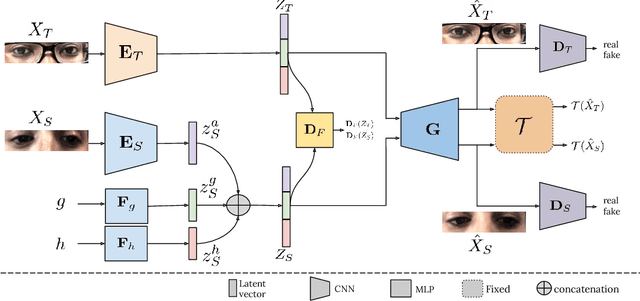

The aim of gaze redirection is to manipulate the gaze in an image to the desired direction. However, existing methods are inadequate in generating perceptually reasonable images. Advancement in generative adversarial networks has shown excellent results in generating photo-realistic images. Though, they still lack the ability to provide finer control over different image attributes. To enable such fine-tuned control, one needs to obtain ground truth annotations for the training data which can be very expensive. In this paper, we propose an unsupervised domain adaptation framework, called CUDA-GR, that learns to disentangle gaze representations from the labeled source domain and transfers them to an unlabeled target domain. Our method enables fine-grained control over gaze directions while preserving the appearance information of the person. We show that the generated image-labels pairs in the target domain are effective in knowledge transfer and can boost the performance of the downstream tasks. Extensive experiments on the benchmarking datasets show that the proposed method can outperform state-of-the-art techniques in both quantitative and qualitative evaluation.
Improving Computer Generated Dialog with Auxiliary Loss Functions and Custom Evaluation Metrics
Jun 04, 2021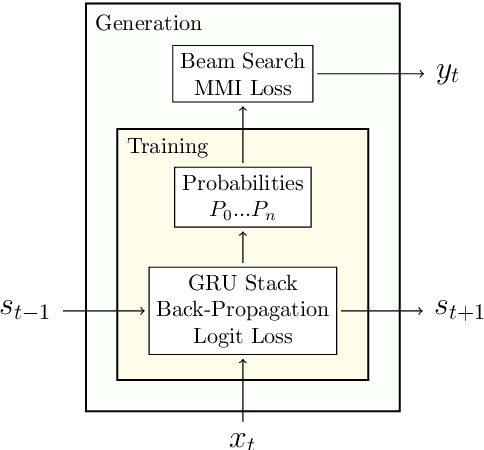
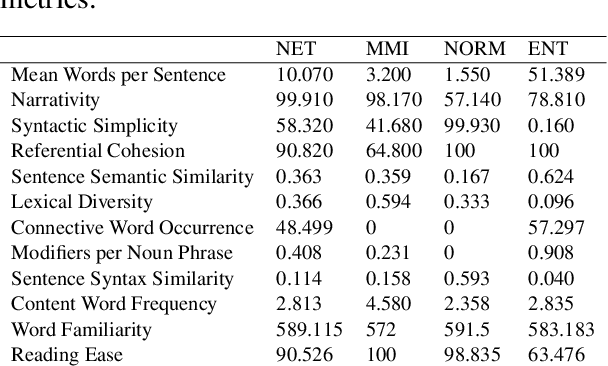
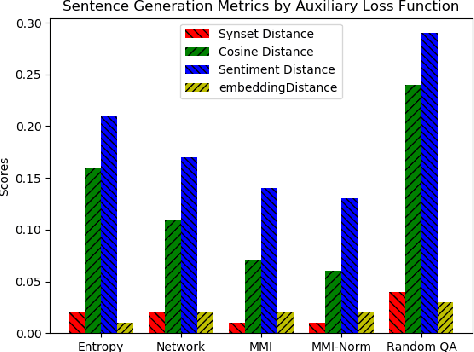
Although people have the ability to engage in vapid dialogue without effort, this may not be a uniquely human trait. Since the 1960's researchers have been trying to create agents that can generate artificial conversation. These programs are commonly known as chatbots. With increasing use of neural networks for dialog generation, some conclude that this goal has been achieved. This research joins the quest by creating a dialog generating Recurrent Neural Network (RNN) and by enhancing the ability of this network with auxiliary loss functions and a beam search. Our custom loss functions achieve better cohesion and coherence by including calculations of Maximum Mutual Information (MMI) and entropy. We demonstrate the effectiveness of this system by using a set of custom evaluation metrics inspired by an abundance of previous research and based on tried-and-true principles of Natural Language Processing.
Swimmer Stroke Rate Estimation From Overhead Race Video
May 20, 2021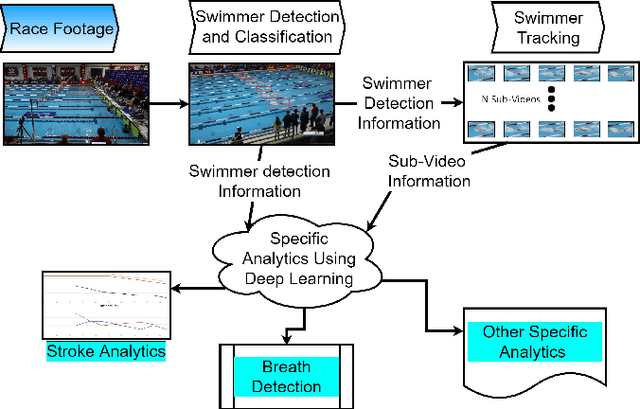
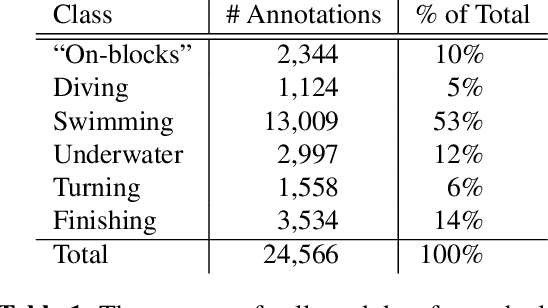

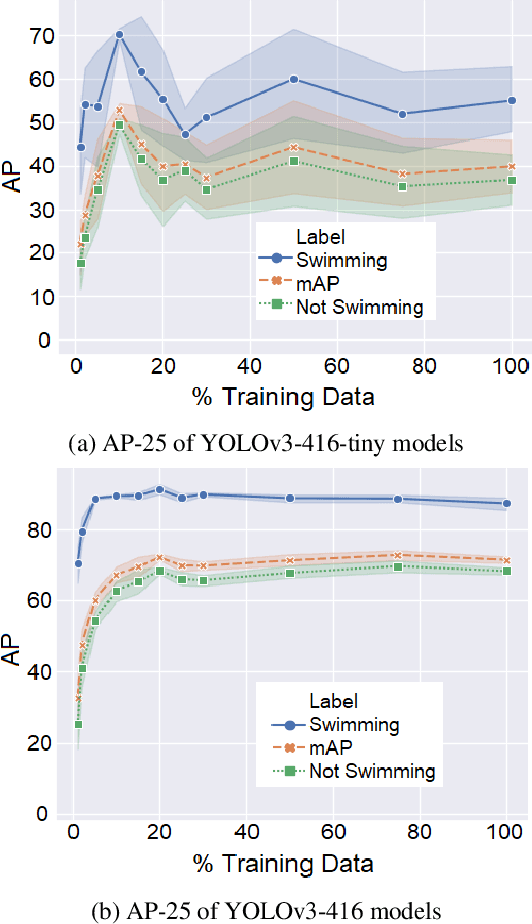
In this work, we propose a swimming analytics system for automatically determining swimmer stroke rates from overhead race video (ORV). General ORV is defined as any footage of swimmers in competition, taken for the purposes of viewing or analysis. Examples of this are footage from live streams, broadcasts, or specialized camera equipment, with or without camera motion. These are the most typical forms of swimming competition footage. We detail how to create a system that will automatically collect swimmer stroke rates in any competition, given the video of the competition of interest. With this information, better systems can be created and additions to our analytics system can be proposed to automatically extract other swimming metrics of interest.
Pay Better Attention to Attention: Head Selection in Multilingual and Multi-Domain Sequence Modeling
Jun 21, 2021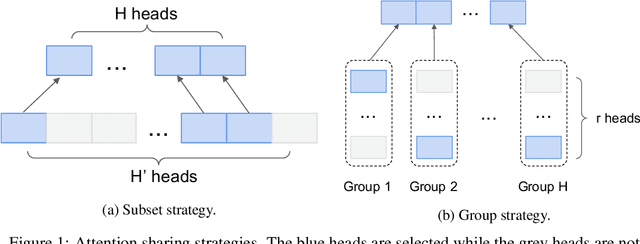
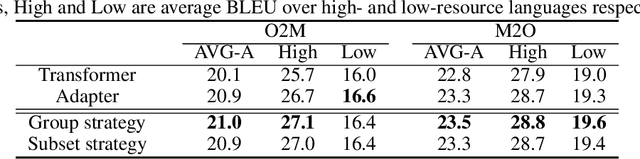

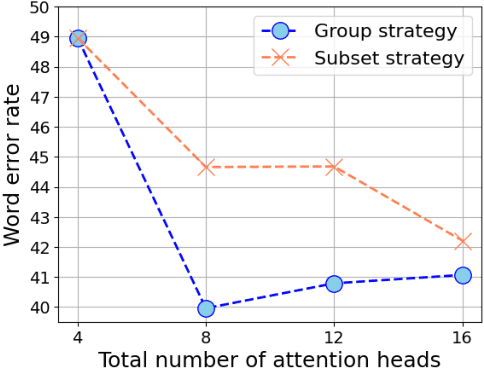
Multi-head attention has each of the attention heads collect salient information from different parts of an input sequence, making it a powerful mechanism for sequence modeling. Multilingual and multi-domain learning are common scenarios for sequence modeling, where the key challenge is to maximize positive transfer and mitigate negative transfer across languages and domains. In this paper, we find that non-selective attention sharing is sub-optimal for achieving good generalization across all languages and domains. We further propose attention sharing strategies to facilitate parameter sharing and specialization in multilingual and multi-domain sequence modeling. Our approach automatically learns shared and specialized attention heads for different languages and domains to mitigate their interference. Evaluated in various tasks including speech recognition, text-to-text and speech-to-text translation, the proposed attention sharing strategies consistently bring gains to sequence models built upon multi-head attention. For speech-to-text translation, our approach yields an average of $+2.0$ BLEU over $13$ language directions in multilingual setting and $+2.0$ BLEU over $3$ domains in multi-domain setting.
INADVERT: An Interactive and Adaptive Counterdeception Platform for Attention Enhancement and Phishing Prevention
Jun 13, 2021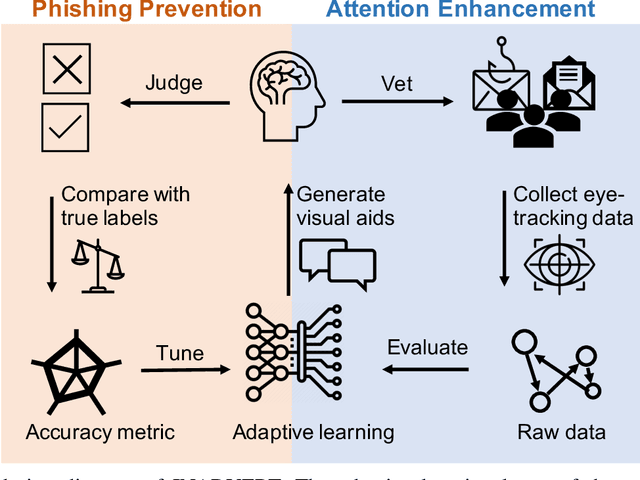

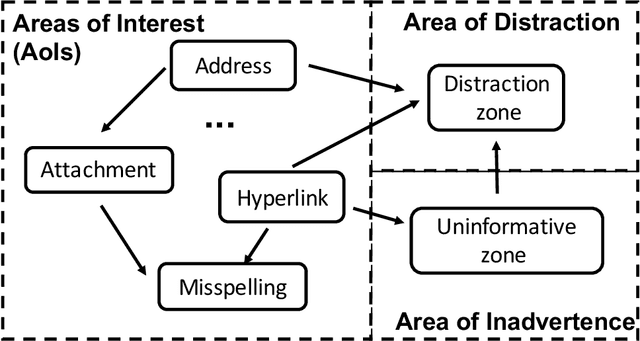
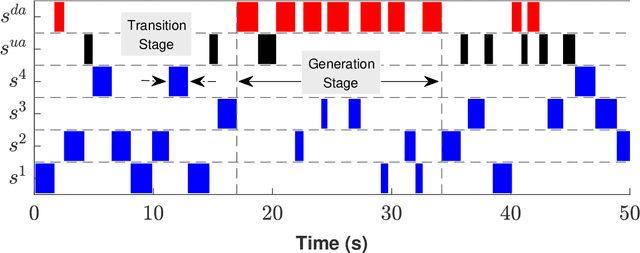
Deceptive attacks exploiting the innate and the acquired vulnerabilities of human users have posed severe threats to information and infrastructure security. This work proposes INADVERT, a systematic solution that generates interactive visual aids in real-time to prevent users from inadvertence and counter visual-deception attacks. Based on the eye-tracking outcomes and proper data compression, the INADVERT platform automatically adapts the visual aids to the user's varying attention status captured by the gaze location and duration. We extract system-level metrics to evaluate the user's average attention level and characterize the magnitude and frequency of the user's mind-wandering behaviors. These metrics contribute to an adaptive enhancement of the user's attention through reinforcement learning. To determine the optimal hyper-parameters in the attention enhancement mechanism, we develop an algorithm based on Bayesian optimization to efficiently update the design of the INADVERT platform and maximize the accuracy of the users' phishing recognition.
JS Fake Chorales: a Synthetic Dataset of Polyphonic Music with Human Annotation
Jul 21, 2021
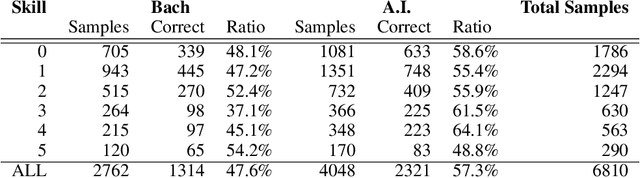
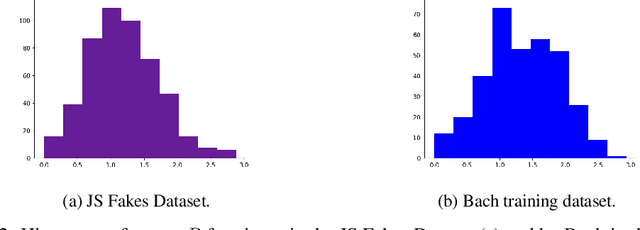
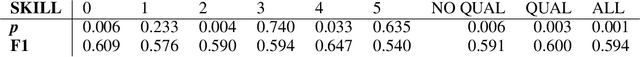
High quality datasets for learning-based modelling of polyphonic symbolic music remain less readily-accessible at scale than in other domains, such as language modelling or image classification. In particular, datasets which contain information revealing insights about human responses to the given music samples are rare. The issue of scale persists as a general hindrance towards breakthroughs in the field, while the lack of listener evaluation is especially relevant to the generative modelling problem-space, where clear objective metrics correlating strongly with qualitative success remain elusive. We propose the JS Fake Chorales, a dataset of 500 pieces generated by a new learning-based algorithm, provided in MIDI form. We take consecutive outputs from the algorithm and avoid cherry-picking in order to validate the potential to further scale this dataset on-demand. We conduct an online experiment for human evaluation, designed to be as fair to the listener as possible, and find that respondents were on average only 7\% better than random guessing at distinguishing JS Fake Chorales from real chorales composed by JS Bach. Furthermore, we make anonymised data collected from experiments available along with the MIDI samples, such as the respondents' musical experience and how long they took to submit their response for each sample. Finally, we conduct ablation studies to demonstrate the effectiveness of using the synthetic pieces for research in polyphonic music modelling, and find that we can improve on state-of-the-art validation set loss for the canonical JSB Chorales dataset, using a known algorithm, by simply augmenting the training set with the JS Fake Chorales.