 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bib2vec: An Embedding-based Search System for Bibliographic Information
Apr 05, 2018
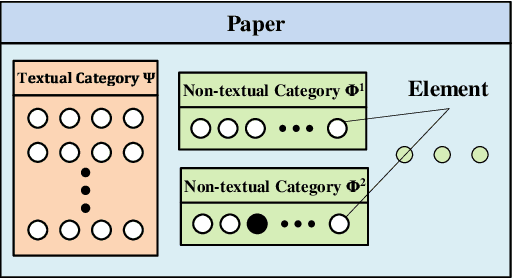
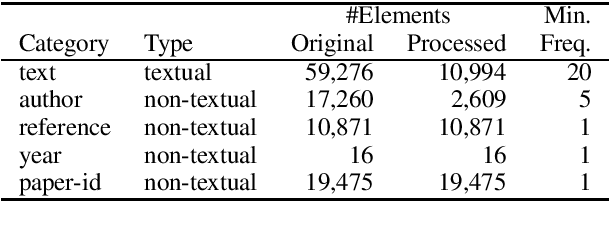
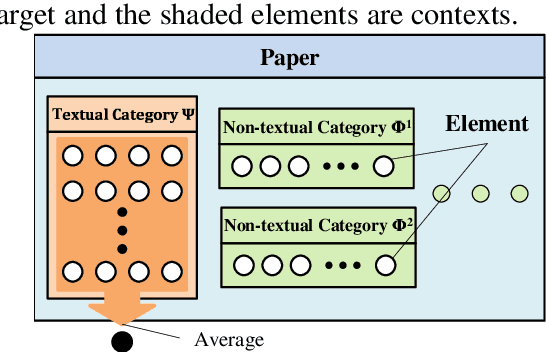
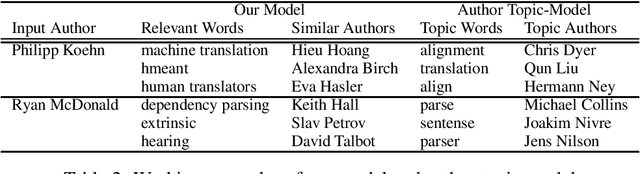
We propose a novel embedding model that represents relationships among several elements in bibliographic information with high representation ability and flexibility. Based on this model, we present a novel search system that shows the relationships among the elements in the ACL Anthology Reference Corpus. The evaluation results show that our model can achieve a high prediction ability and produce reasonable search results.
* EACL2017 extended version. The demonstration is available at http://tti-coin.jp/demo/bib2vec/
$α$-Geodesical Skew Divergence
Apr 26, 2021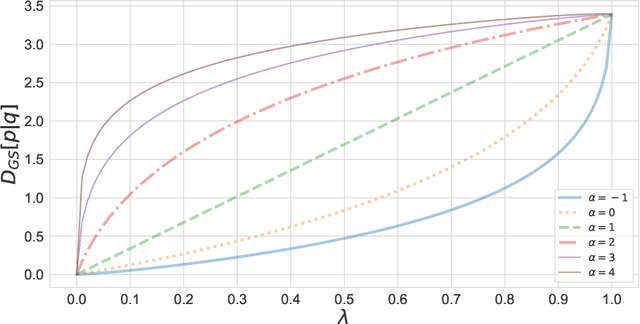
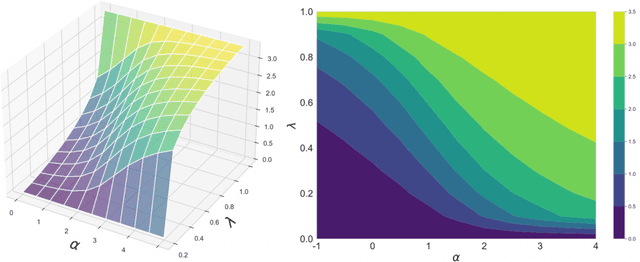
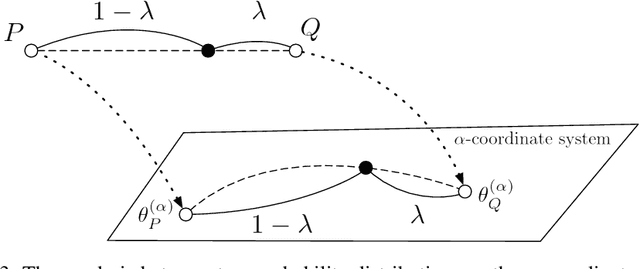
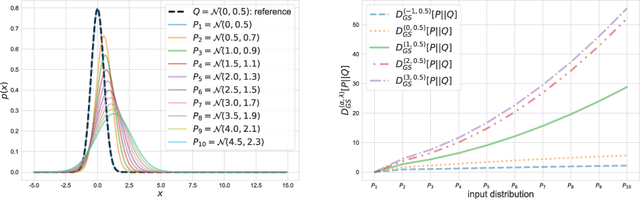
The asymmetric skew divergence smooths one of the distributions by mixing it, to a degree determined by the parameter $\lambda$, with the other distribution. Such divergence is an approximation of the KL divergence that does not require the target distribution to be absolutely continuous with respect to the source distribution. In this paper, an information geometric generalization of the skew divergence called the $\alpha$-geodesical skew divergence is proposed, and its properties are studied.
Play the Shannon Game With Language Models: A Human-Free Approach to Summary Evaluation
Mar 19, 2021
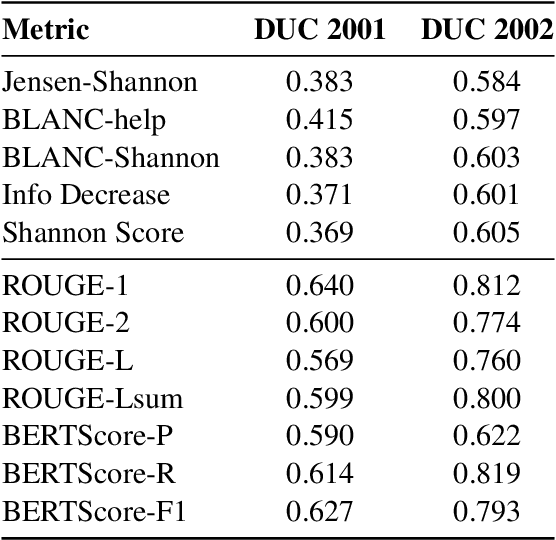
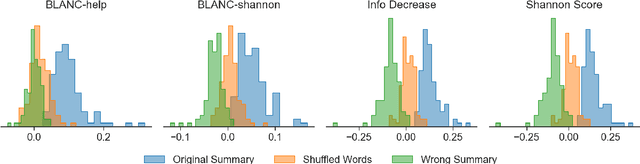
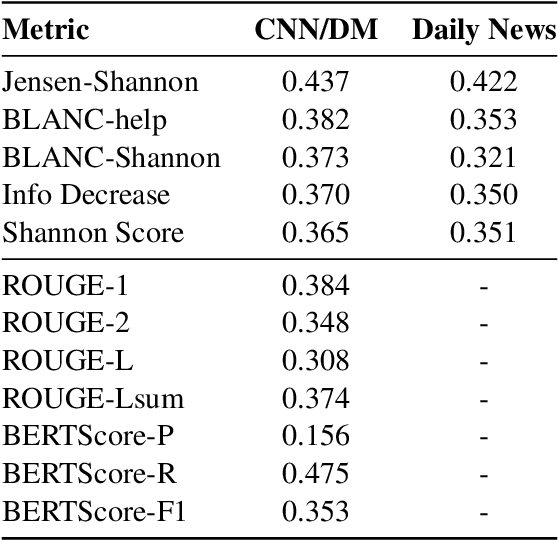
The goal of a summary is to concisely state the most important information in a document. With this principle in mind, we introduce new reference-free summary evaluation metrics that use a pretrained language model to estimate the information shared between a document and its summary. These metrics are a modern take on the Shannon Game, a method for summary quality scoring proposed decades ago, where we replace human annotators with language models. We also view these metrics as an extension of BLANC, a recently proposed approach to summary quality measurement based on the performance of a language model with and without the help of a summary. Using GPT-2, we empirically verify that the introduced metrics correlate with human judgement based on coverage, overall quality, and five summary dimensions.
Machine Learning Characterization of Cancer Patients-Derived Extracellular Vesicles using Vibrational Spectroscopies
Jul 21, 2021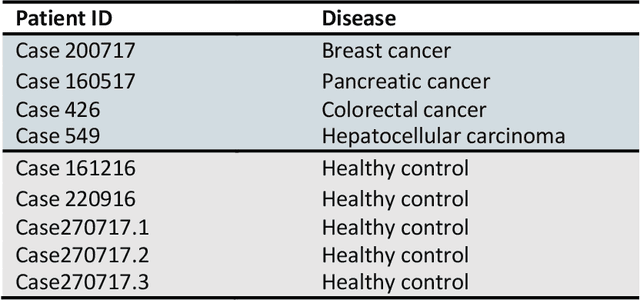
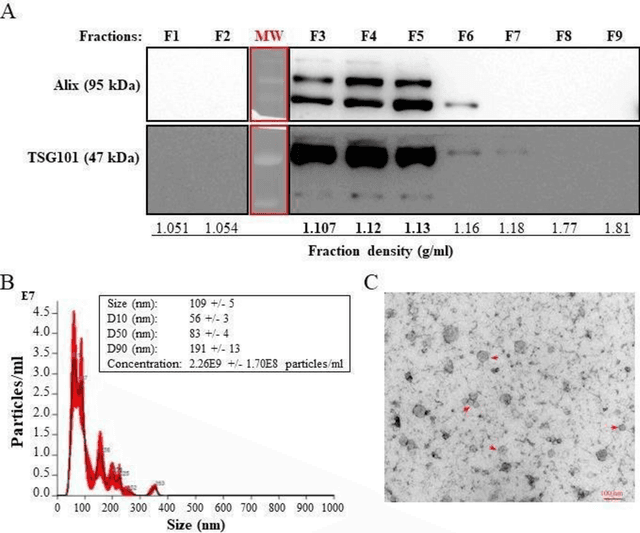
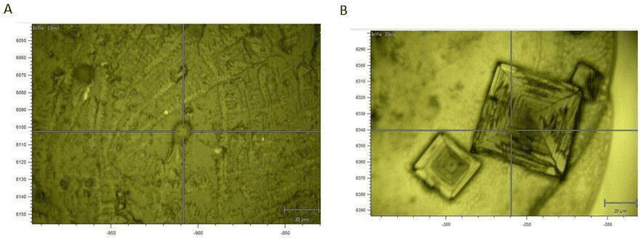
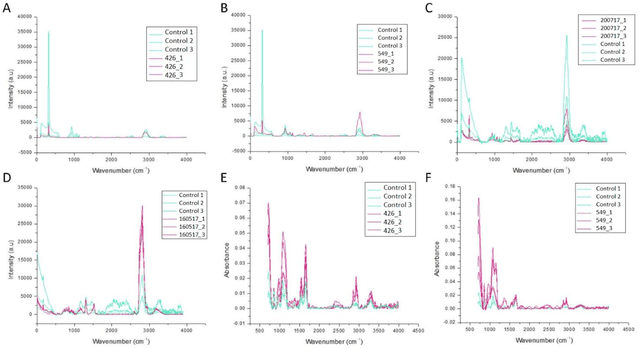
The early detection of cancer is a challenging problem in medicine. The blood sera of cancer patients are enriched with heterogeneous secretory lipid bound extracellular vesicles (EVs), which present a complex repertoire of information and biomarkers, representing their cell of origin, that are being currently studied in the field of liquid biopsy and cancer screening. Vibrational spectroscopies provide non-invasive approaches for the assessment of structural and biophysical properties in complex biological samples. In this study, multiple Raman spectroscopy measurements were performed on the EVs extracted from the blood sera of 9 patients consisting of four different cancer subtypes (colorectal cancer, hepatocellular carcinoma, breast cancer and pancreatic cancer) and five healthy patients (controls). FTIR(Fourier Transform Infrared) spectroscopy measurements were performed as a complementary approach to Raman analysis, on two of the four cancer subtypes. The AdaBoost Random Forest Classifier, Decision Trees, and Support Vector Machines (SVM) distinguished the baseline corrected Raman spectra of cancer EVs from those of healthy controls (18 spectra) with a classification accuracy of greater than 90% when reduced to a spectral frequency range of 1800 to 1940 inverse cm, and subjected to a 0.5 training/testing split. FTIR classification accuracy on 14 spectra showed an 80% classification accuracy. Our findings demonstrate that basic machine learning algorithms are powerful tools to distinguish the complex vibrational spectra of cancer patient EVs from those of healthy patients. These experimental methods hold promise as valid and efficient liquid biopsy for machine intelligence-assisted early cancer screening.
Deep Learning for Market by Order Data
Feb 17, 2021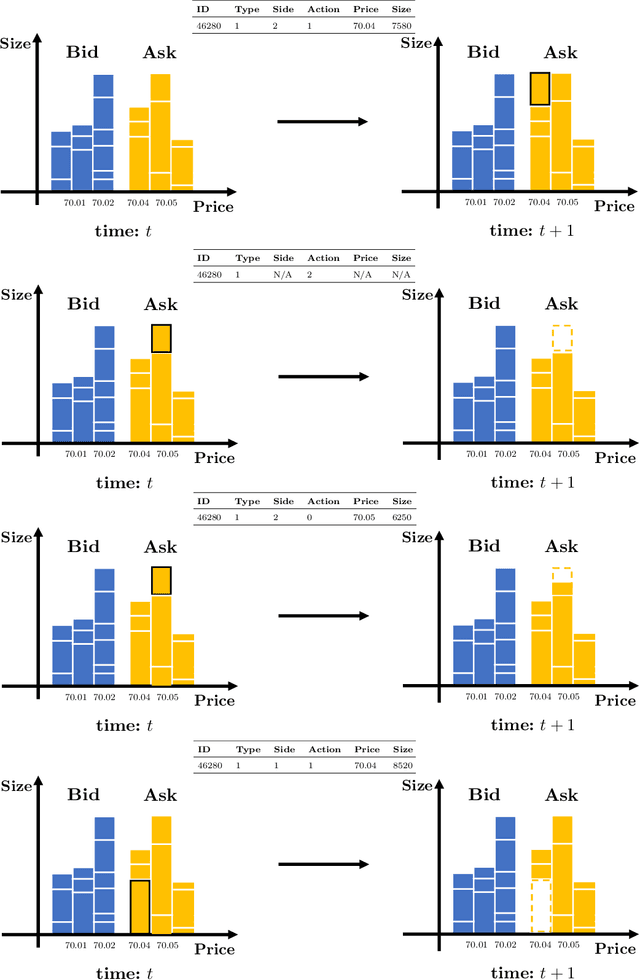
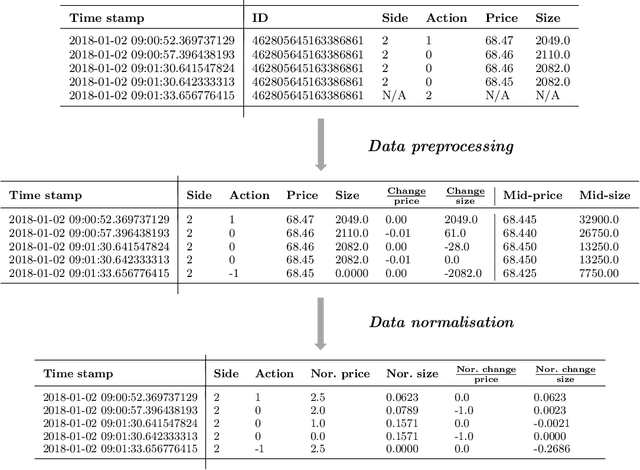
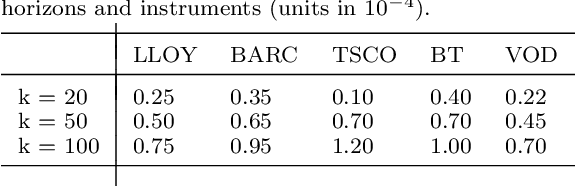
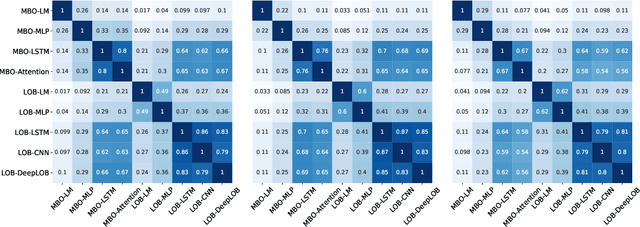
Market by order (MBO) data - a detailed feed of individual trade instructions for a given stock on an exchange - is arguably one of the most granular sources of microstructure information. While limit order books (LOBs) are implicitly derived from it, MBO data is largely neglected by current academic literature which focuses primarily on LOB modelling. In this paper, we demonstrate the utility of MBO data for forecasting high-frequency price movements, providing an orthogonal source of information to LOB snapshots. We provide the first predictive analysis on MBO data by carefully introducing the data structure and presenting a specific normalisation scheme to consider level information in order books and to allow model training with multiple instruments. Through forecasting experiments using deep neural networks, we show that while MBO-driven and LOB-driven models individually provide similar performance, ensembles of the two can lead to improvements in forecasting accuracy -- indicating that MBO data is additive to LOB-based features.
Language Grounding with 3D Objects
Jul 26, 2021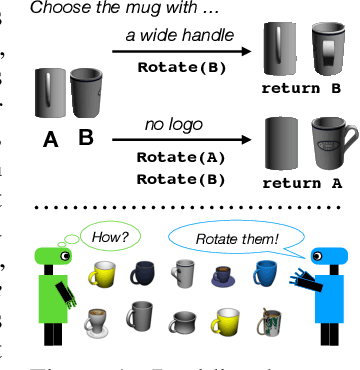
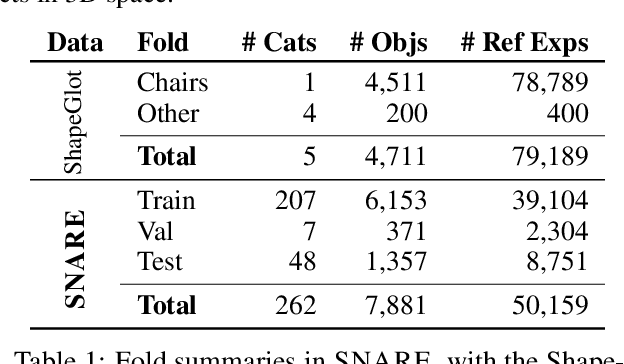
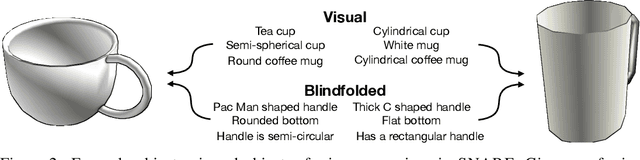
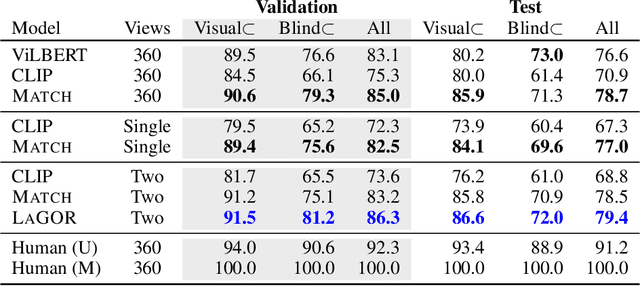
Seemingly simple natural language requests to a robot are generally underspecified, for example "Can you bring me the wireless mouse?" When viewing mice on the shelf, the number of buttons or presence of a wire may not be visible from certain angles or positions. Flat images of candidate mice may not provide the discriminative information needed for "wireless". The world, and objects in it, are not flat images but complex 3D shapes. If a human requests an object based on any of its basic properties, such as color, shape, or texture, robots should perform the necessary exploration to accomplish the task. In particular, while substantial effort and progress has been made on understanding explicitly visual attributes like color and category, comparatively little progress has been made on understanding language about shapes and contours. In this work, we introduce a novel reasoning task that targets both visual and non-visual language about 3D objects. Our new benchmark, ShapeNet Annotated with Referring Expressions (SNARE), requires a model to choose which of two objects is being referenced by a natural language description. We introduce several CLIP-based models for distinguishing objects and demonstrate that while recent advances in jointly modeling vision and language are useful for robotic language understanding, it is still the case that these models are weaker at understanding the 3D nature of objects -- properties which play a key role in manipulation. In particular, we find that adding view estimation to language grounding models improves accuracy on both SNARE and when identifying objects referred to in language on a robot platform.
Continual Learning via Inter-Task Synaptic Mapping
Jun 26, 2021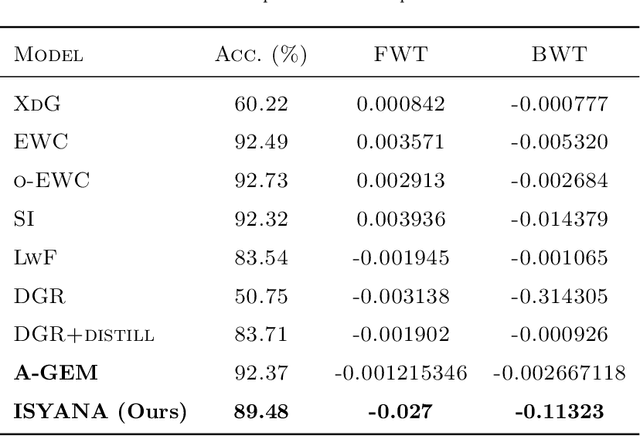
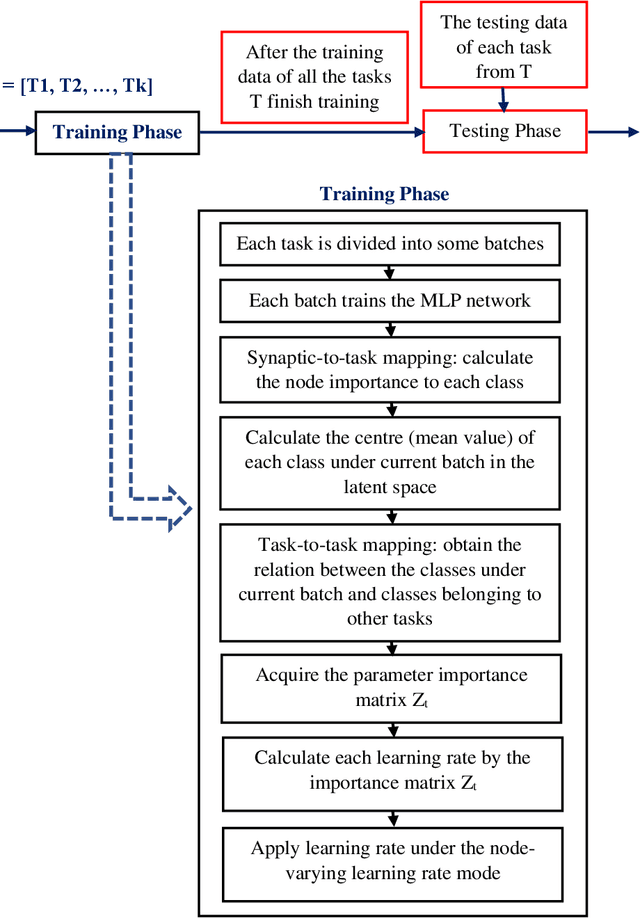
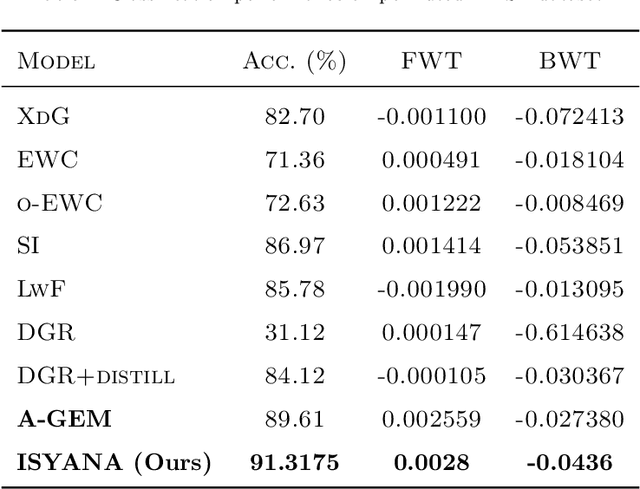
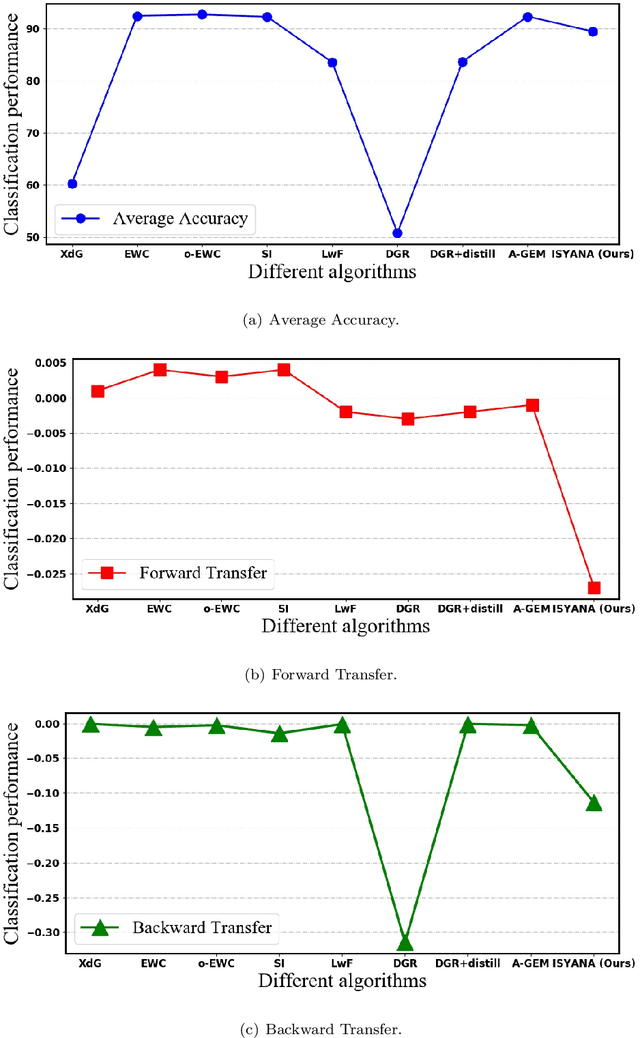
Learning from streaming tasks leads a model to catastrophically erase unique experiences it absorbs from previous episodes. While regularization techniques such as LWF, SI, EWC have proven themselves as an effective avenue to overcome this issue by constraining important parameters of old tasks from changing when accepting new concepts, these approaches do not exploit common information of each task which can be shared to existing neurons. As a result, they do not scale well to large-scale problems since the parameter importance variables quickly explode. An Inter-Task Synaptic Mapping (ISYANA) is proposed here to underpin knowledge retention for continual learning. ISYANA combines task-to-neuron relationship as well as concept-to-concept relationship such that it prevents a neuron to embrace distinct concepts while merely accepting relevant concept. Numerical study in the benchmark continual learning problems has been carried out followed by comparison against prominent continual learning algorithms. ISYANA exhibits competitive performance compared to state of the arts. Codes of ISYANA is made available in \url{https://github.com/ContinualAL/ISYANAKBS}.
* This paper has been published in Knowledge-based Systems
General Data Analytics with Applications to Visual Information Analysis: A Provable Backward-Compatible Semisimple Paradigm over T-Algebra
Nov 16, 2020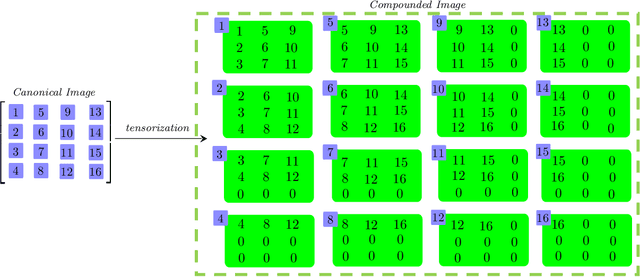
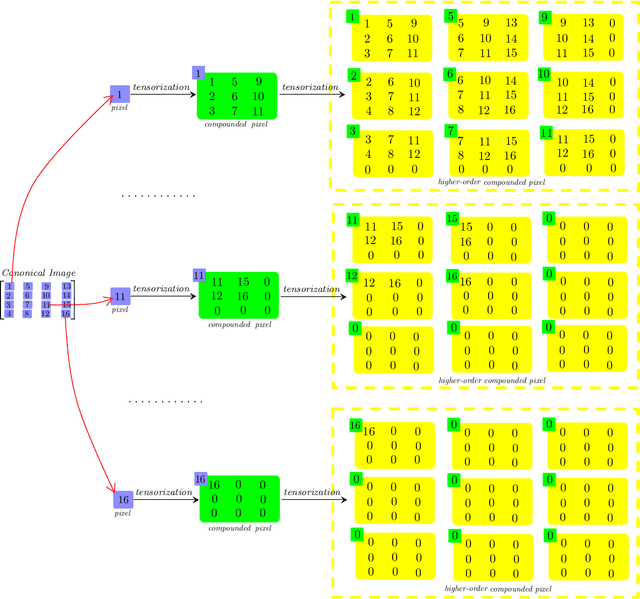

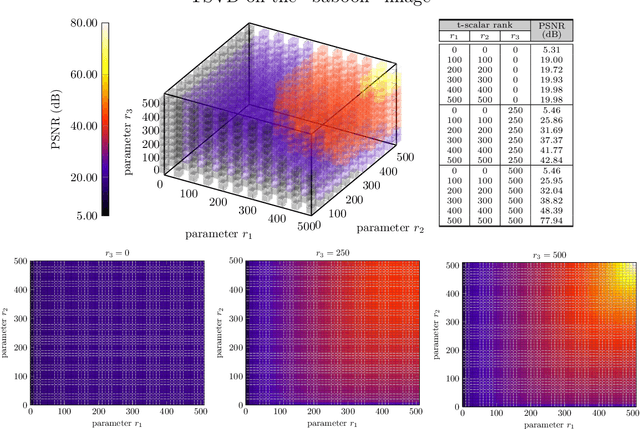
We consider a novel backward-compatible paradigm of general data analytics over a recently-reported semisimple algebra (called t-algebra). We study the abstract algebraic framework over the t-algebra by representing the elements of t-algebra by fix-sized multi-way arrays of complex numbers and the algebraic structure over the t-algebra by a collection of direct-product constituents. Over the t-algebra, many algorithms, if not all, are generalized in a straightforward manner using this new semisimple paradigm. To demonstrate the new paradigm's performance and its backward-compatibility, we generalize some canonical algorithms for visual pattern analysis. Experiments on public datasets show that the generalized algorithms compare favorably with their canonical counterparts.
Demiguise Attack: Crafting Invisible Semantic Adversarial Perturbations with Perceptual Similarity
Jul 03, 2021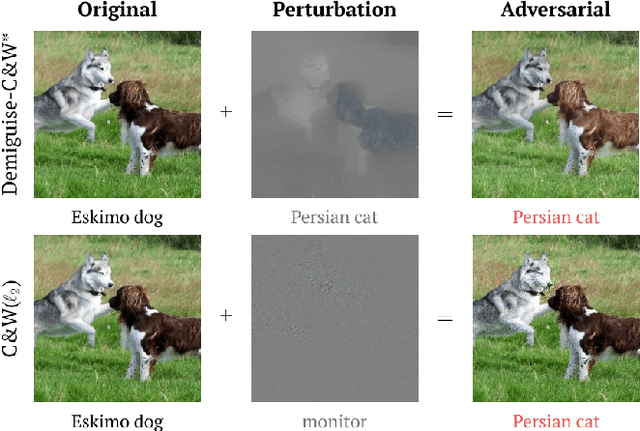

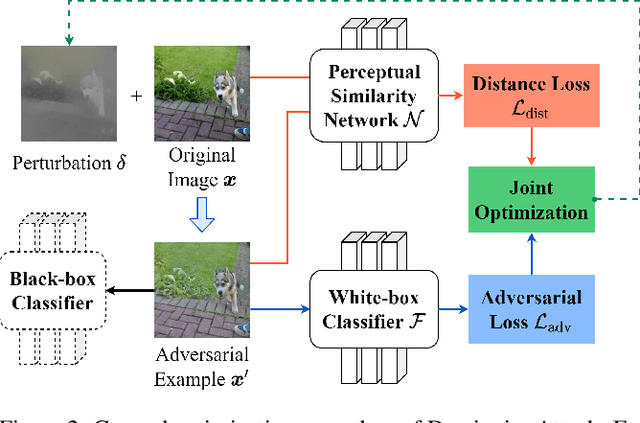

Deep neural networks (DNNs) have been found to be vulnerable to adversarial examples. Adversarial examples are malicious images with visually imperceptible perturbations. While these carefully crafted perturbations restricted with tight $\Lp$ norm bounds are small, they are still easily perceivable by humans. These perturbations also have limited success rates when attacking black-box models or models with defenses like noise reduction filters. To solve these problems, we propose Demiguise Attack, crafting ``unrestricted'' perturbations with Perceptual Similarity. Specifically, we can create powerful and photorealistic adversarial examples by manipulating semantic information based on Perceptual Similarity. Adversarial examples we generate are friendly to the human visual system (HVS), although the perturbations are of large magnitudes. We extend widely-used attacks with our approach, enhancing adversarial effectiveness impressively while contributing to imperceptibility. Extensive experiments show that the proposed method not only outperforms various state-of-the-art attacks in terms of fooling rate, transferability, and robustness against defenses but can also improve attacks effectively. In addition, we also notice that our implementation can simulate illumination and contrast changes that occur in real-world scenarios, which will contribute to exposing the blind spots of DNNs.
Meta-control of social learning strategies
Jun 18, 2021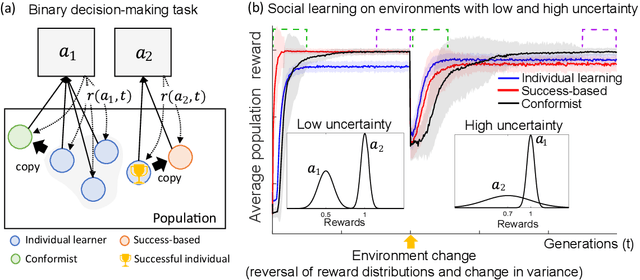

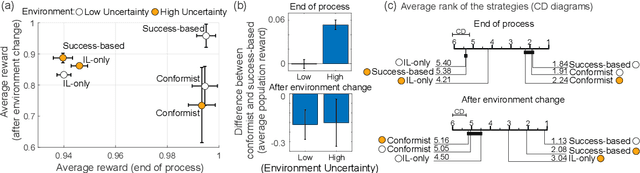

Social learning, copying other's behavior without actual experience, offers a cost-effective means of knowledge acquisition. However, it raises the fundamental question of which individuals have reliable information: successful individuals versus the majority. The former and the latter are known respectively as success-based and conformist social learning strategies. We show here that while the success-based strategy fully exploits the benign environment of low uncertainly, it fails in uncertain environments. On the other hand, the conformist strategy can effectively mitigate this adverse effect. Based on these findings, we hypothesized that meta-control of individual and social learning strategies provides effective and sample-efficient learning in volatile and uncertain environments. Simulations on a set of environments with various levels of volatility and uncertainty confirmed our hypothesis. The results imply that meta-control of social learning affords agents the leverage to resolve environmental uncertainty with minimal exploration cost, by exploiting others' learning as an external knowledge base.