 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Domain Adaptation for Video Semantic Segmentation
Jul 23, 2021
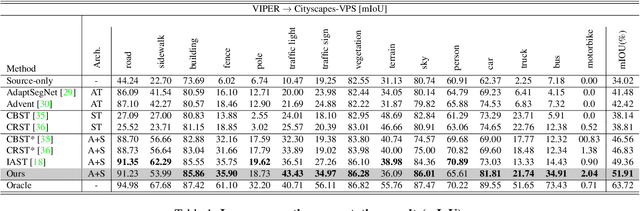
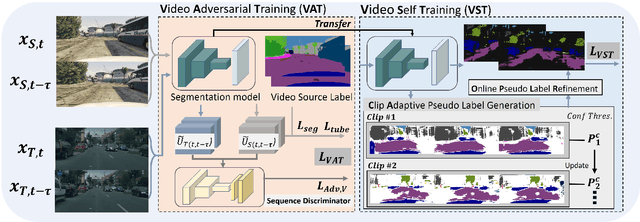
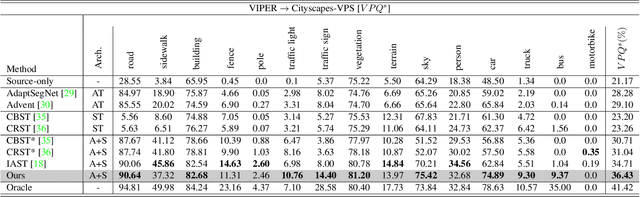
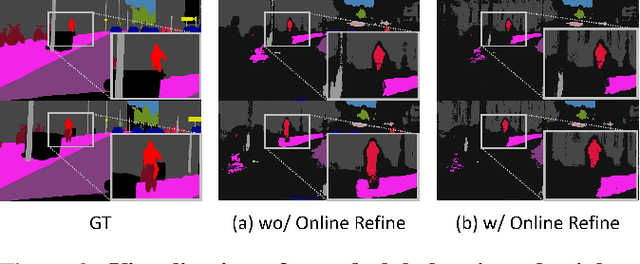
Unsupervised Domain Adaptation for semantic segmentation has gained immense popularity since it can transfer knowledge from simulation to real (Sim2Real) by largely cutting out the laborious per pixel labeling efforts at real. In this work, we present a new video extension of this task, namely Unsupervised Domain Adaptation for Video Semantic Segmentation. As it became easy to obtain large-scale video labels through simulation, we believe attempting to maximize Sim2Real knowledge transferability is one of the promising directions for resolving the fundamental data-hungry issue in the video. To tackle this new problem, we present a novel two-phase adaptation scheme. In the first step, we exhaustively distill source domain knowledge using supervised loss functions. Simultaneously, video adversarial training (VAT) is employed to align the features from source to target utilizing video context. In the second step, we apply video self-training (VST), focusing only on the target data. To construct robust pseudo labels, we exploit the temporal information in the video, which has been rarely explored in the previous image-based self-training approaches. We set strong baseline scores on 'VIPER to CityscapeVPS' adaptation scenario. We show that our proposals significantly outperform previous image-based UDA methods both on image-level (mIoU) and video-level (VPQ) evaluation metrics.
PARE: Part Attention Regressor for 3D Human Body Estimation
Apr 17, 2021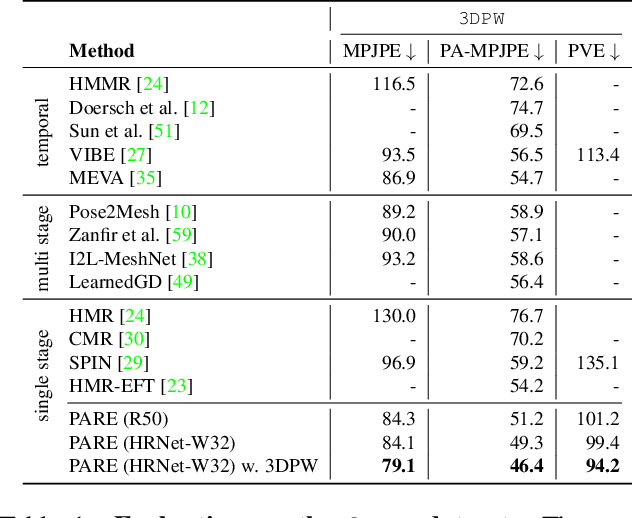
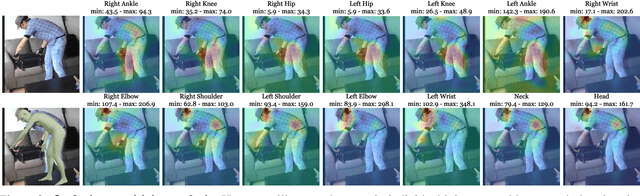
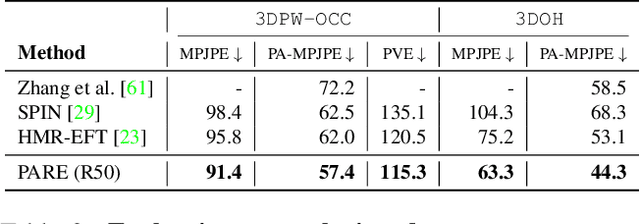
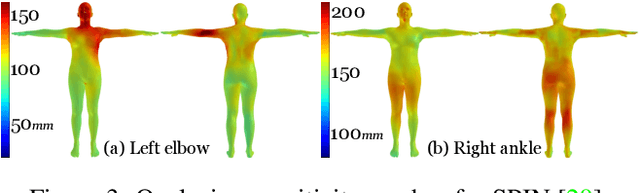
Despite significant progress, we show that state of the art 3D human pose and shape estimation methods remain sensitive to partial occlusion and can produce dramatically wrong predictions although much of the body is observable. To address this, we introduce a soft attention mechanism, called the Part Attention REgressor (PARE), that learns to predict body-part-guided attention masks. We observe that state-of-the-art methods rely on global feature representations, making them sensitive to even small occlusions. In contrast, PARE's part-guided attention mechanism overcomes these issues by exploiting information about the visibility of individual body parts while leveraging information from neighboring body-parts to predict occluded parts. We show qualitatively that PARE learns sensible attention masks, and quantitative evaluation confirms that PARE achieves more accurate and robust reconstruction results than existing approaches on both occlusion-specific and standard benchmarks. Code will be available for research purposes at https://pare.is.tue.mpg.de/.
Generalized Source-free Domain Adaptation
Aug 03, 2021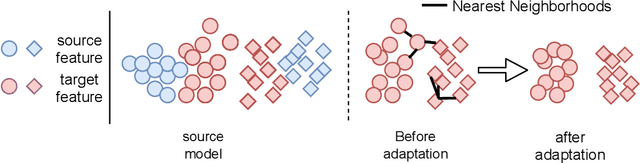
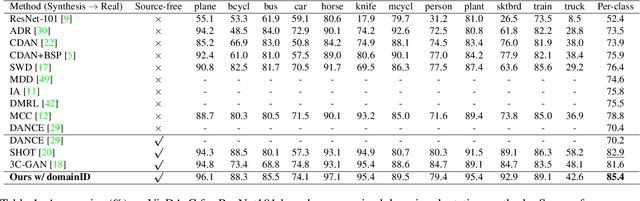
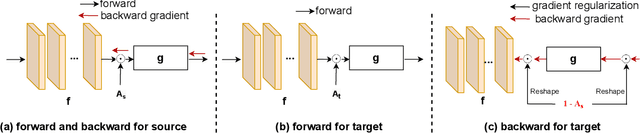
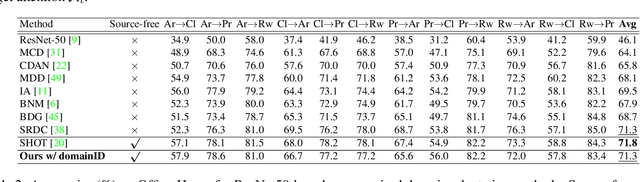
Domain adaptation (DA) aims to transfer the knowledge learned from a source domain to an unlabeled target domain. Some recent works tackle source-free domain adaptation (SFDA) where only a source pre-trained model is available for adaptation to the target domain. However, those methods do not consider keeping source performance which is of high practical value in real world applications. In this paper, we propose a new domain adaptation paradigm called Generalized Source-free Domain Adaptation (G-SFDA), where the learned model needs to perform well on both the target and source domains, with only access to current unlabeled target data during adaptation. First, we propose local structure clustering (LSC), aiming to cluster the target features with its semantically similar neighbors, which successfully adapts the model to the target domain in the absence of source data. Second, we propose sparse domain attention (SDA), it produces a binary domain specific attention to activate different feature channels for different domains, meanwhile the domain attention will be utilized to regularize the gradient during adaptation to keep source information. In the experiments, for target performance our method is on par with or better than existing DA and SFDA methods, specifically it achieves state-of-the-art performance (85.4%) on VisDA, and our method works well for all domains after adapting to single or multiple target domains. Code is available in https://github.com/Albert0147/G-SFDA.
Neural Language Models with Distant Supervision to Identify Major Depressive Disorder from Clinical Notes
Apr 19, 2021
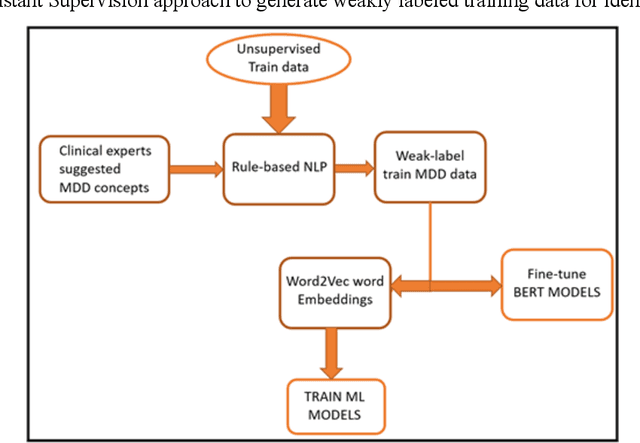
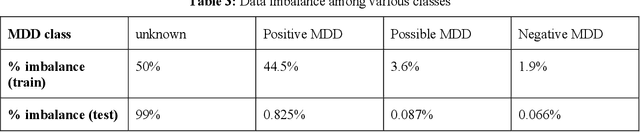
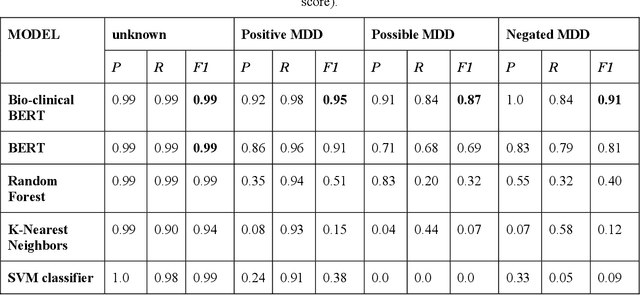
Major depressive disorder (MDD) is a prevalent psychiatric disorder that is associated with significant healthcare burden worldwide. Phenotyping of MDD can help early diagnosis and consequently may have significant advantages in patient management. In prior research MDD phenotypes have been extracted from structured Electronic Health Records (EHR) or using Electroencephalographic (EEG) data with traditional machine learning models to predict MDD phenotypes. However, MDD phenotypic information is also documented in free-text EHR data, such as clinical notes. While clinical notes may provide more accurate phenotyping information, natural language processing (NLP) algorithms must be developed to abstract such information. Recent advancements in NLP resulted in state-of-the-art neural language models, such as Bidirectional Encoder Representations for Transformers (BERT) model, which is a transformer-based model that can be pre-trained from a corpus of unsupervised text data and then fine-tuned on specific tasks. However, such neural language models have been underutilized in clinical NLP tasks due to the lack of large training datasets. In the literature, researchers have utilized the distant supervision paradigm to train machine learning models on clinical text classification tasks to mitigate the issue of lacking annotated training data. It is still unknown whether the paradigm is effective for neural language models. In this paper, we propose to leverage the neural language models in a distant supervision paradigm to identify MDD phenotypes from clinical notes. The experimental results indicate that our proposed approach is effective in identifying MDD phenotypes and that the Bio- Clinical BERT, a specific BERT model for clinical data, achieved the best performance in comparison with conventional machine learning models.
Intelligent Reflecting Surface Empowered UAV SWIPT Networks
Jul 23, 2021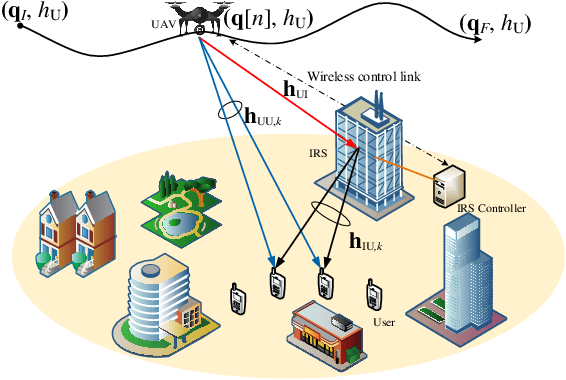
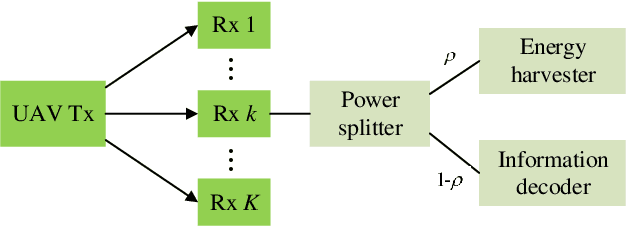
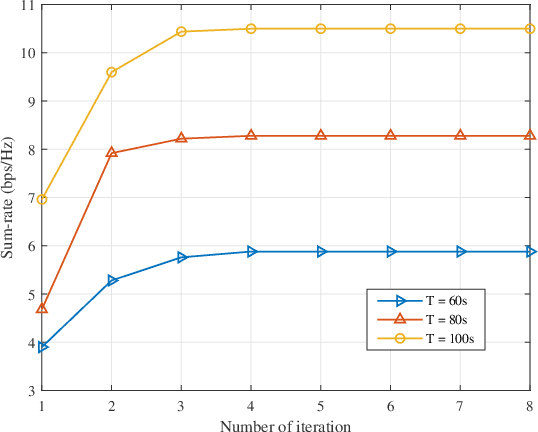
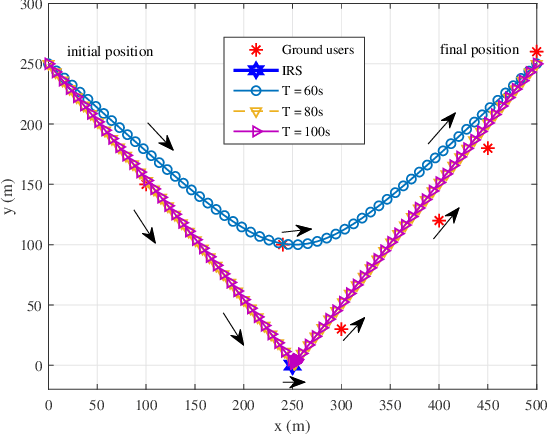
Aiming at the limited battery capacity of a large number of widely deployed low-power smart devices in the Internet-of-things (IoT), this paper proposes a novel intelligent reflecting surface (IRS) empowered unmanned aerial vehicle (UAV) simultaneous wireless information and power transfer (SWIPT) network framework, in which IRS is used to reconstruct the wireless channel to enhance the energy transmission efficiency and coverage of the UAV SWIPT networks. In this paper, we formulate an achievable sum-rate maximization problem by jointly optimizing UAV trajectory, UAV transmission power allocation, power splitting (PS) ratio and IRS reflection coefficient under a non-linear energy harvesting model. Due to the coupling of optimization variables, this problem is a complex non-convex optimization problem, and it is challenging to solve it directly. We first transform the problem, and then apply the alternating optimization (AO) algorithm framework to divide the transformed problem into four blocks to solve it. Specifically, by applying successive convex approximation (SCA) and difference-convex (DC) programming, UAV trajectory, UAV transmission power allocation, PS ratio and IRS reflection coefficient are alternately optimized when the other three are given until convergence is achieved. Numerical simulation results verify the effectiveness of our proposed algorithm compared to other algorithms.
Straight to the Gradient: Learning to Use Novel Tokens for Neural Text Generation
Jun 14, 2021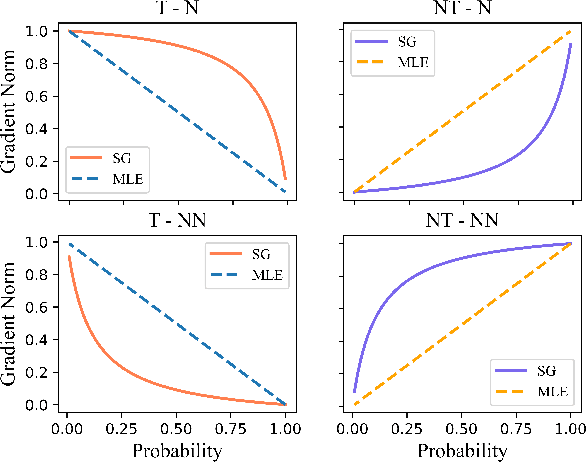

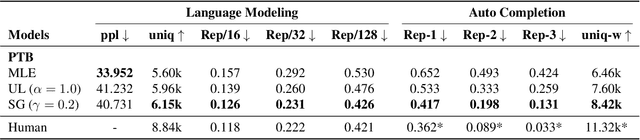
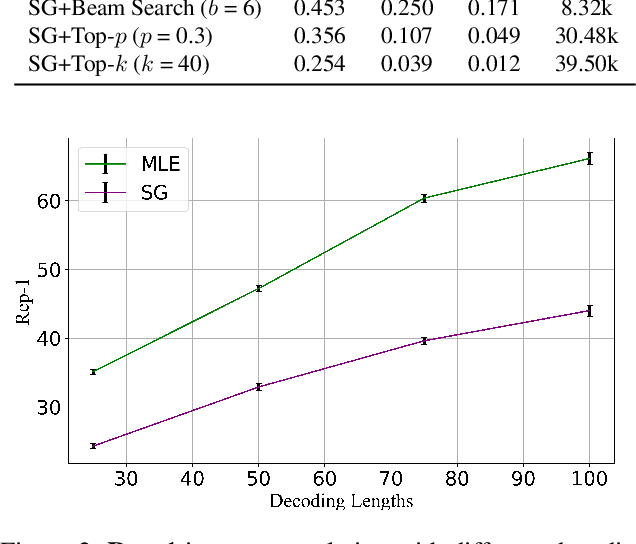
Advanced large-scale neural language models have led to significant success in many language generation tasks. However, the most commonly used training objective, Maximum Likelihood Estimation (MLE), has been shown problematic, where the trained model prefers using dull and repetitive phrases. In this work, we introduce ScaleGrad, a modification straight to the gradient of the loss function, to remedy the degeneration issue of the standard MLE objective. By directly maneuvering the gradient information, ScaleGrad makes the model learn to use novel tokens. Empirical results show the effectiveness of our method not only in open-ended generation, but also in directed generation tasks. With the simplicity in architecture, our method can serve as a general training objective that is applicable to most of the neural text generation tasks.
Enhancing Drug-Drug Interaction Extraction from Texts by Molecular Structure Information
May 15, 2018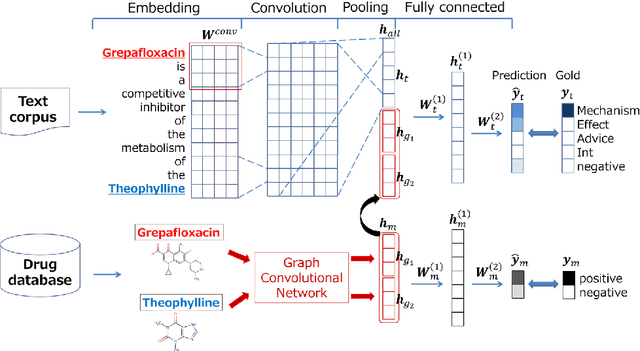
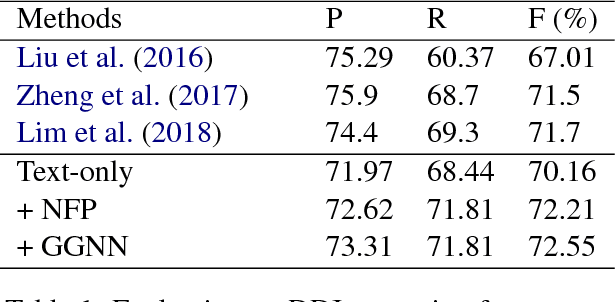
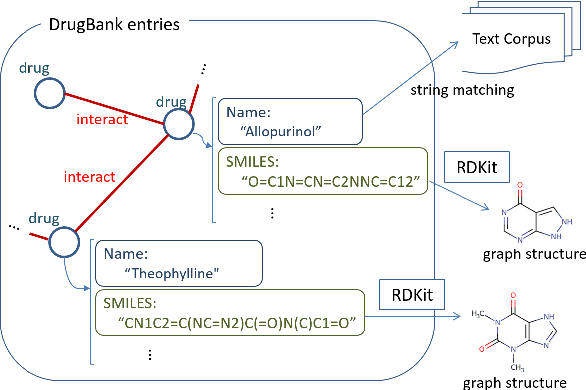

We propose a novel neural method to extract drug-drug interactions (DDIs) from texts using external drug molecular structure information. We encode textual drug pairs with convolutional neural networks and their molecular pairs with graph convolutional networks (GCNs), and then we concatenate the outputs of these two networks. In the experiments, we show that GCNs can predict DDIs from the molecular structures of drugs in high accuracy and the molecular information can enhance text-based DDI extraction by 2.39 percent points in the F-score on the DDIExtraction 2013 shared task data set.
STMTrack: Template-free Visual Tracking with Space-time Memory Networks
Apr 02, 2021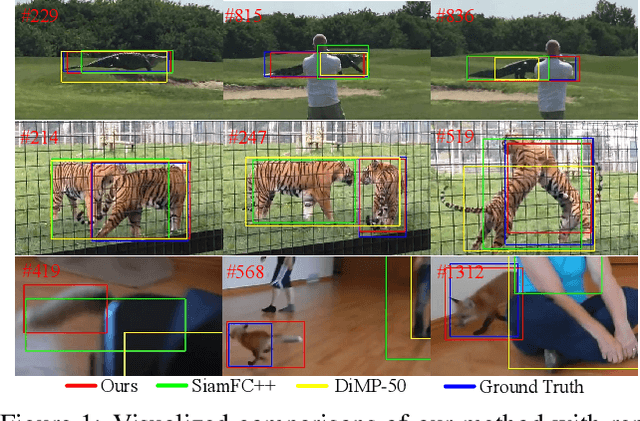
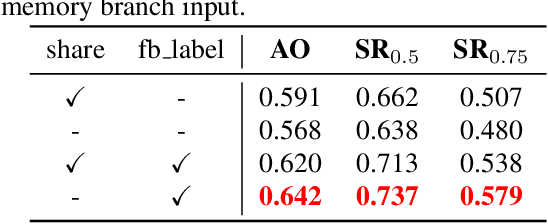
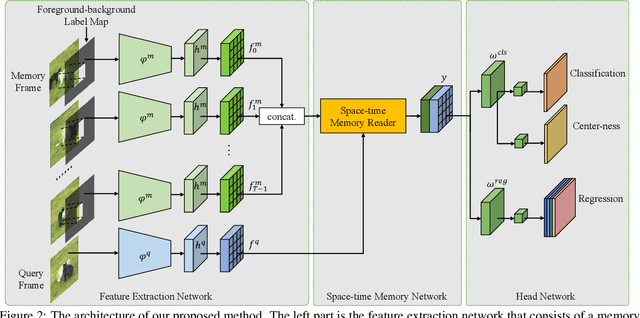

Boosting performance of the offline trained siamese trackers is getting harder nowadays since the fixed information of the template cropped from the first frame has been almost thoroughly mined, but they are poorly capable of resisting target appearance changes. Existing trackers with template updating mechanisms rely on time-consuming numerical optimization and complex hand-designed strategies to achieve competitive performance, hindering them from real-time tracking and practical applications. In this paper, we propose a novel tracking framework built on top of a space-time memory network that is competent to make full use of historical information related to the target for better adapting to appearance variations during tracking. Specifically, a novel memory mechanism is introduced, which stores the historical information of the target to guide the tracker to focus on the most informative regions in the current frame. Furthermore, the pixel-level similarity computation of the memory network enables our tracker to generate much more accurate bounding boxes of the target. Extensive experiments and comparisons with many competitive trackers on challenging large-scale benchmarks, OTB-2015, TrackingNet, GOT-10k, LaSOT, UAV123, and VOT2018, show that, without bells and whistles, our tracker outperforms all previous state-of-the-art real-time methods while running at 37 FPS. The code is available at https://github.com/fzh0917/STMTrack.
TopicTracker: A Platform for Topic Trajectory Identification and Visualisation
Mar 02, 2021
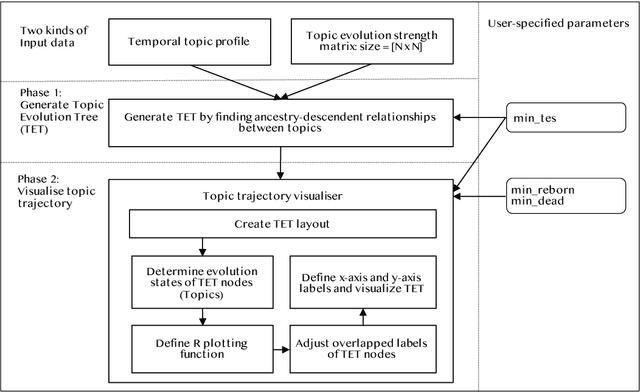
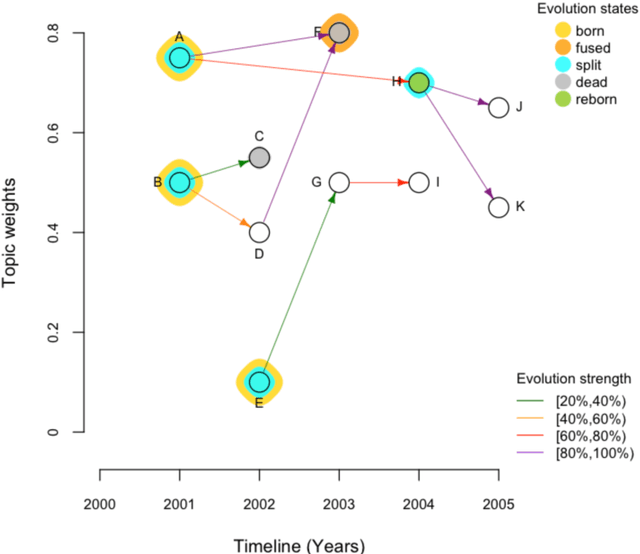
Topic trajectory information provides crucial insight into the dynamics of topics and their evolutionary relationships over a given time. Also, this information can help to improve our understanding on how new topics have emerged or formed through a sequential or interrelated events of emergence, modification and integration of prior topics. Nevertheless, the implementation of the existing methods for topic trajectory identification is rarely available as usable software. In this paper, we present TopicTracker, a platform for topic trajectory identification and visualisation. The key of Topic Tracker is that it can represent the three facets of information together, given two kinds of input: a time-stamped topic profile consisting of the set of the underlying topics over time, and the evolution strength matrix among them: evolutionary pathways of dynamic topics, evolution states of the topics, and topic importance. TopicTracker is a publicly available software implemented using the R software.
Design of the Propulsion System of Nano satellite: StudSat2
Jul 23, 2021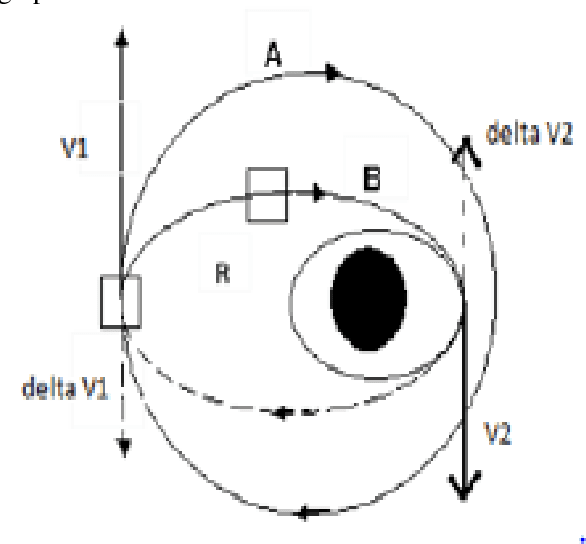
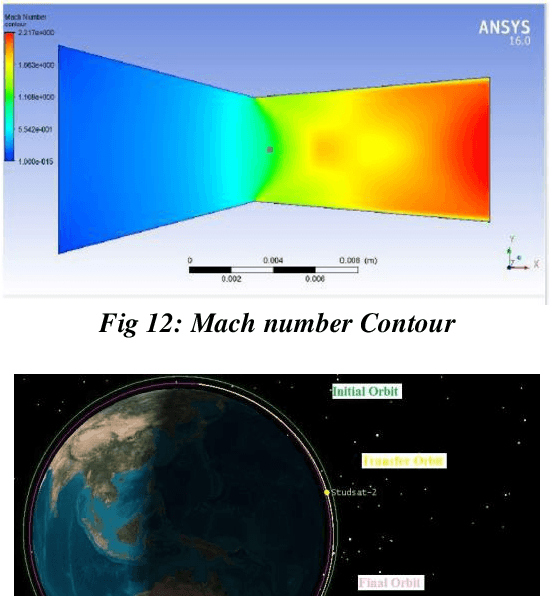
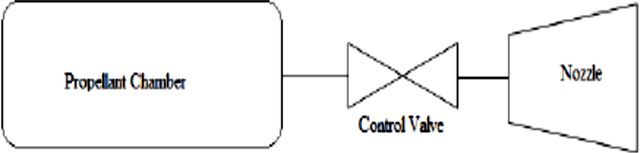

The increase in the application of the satellite has skyrocketed the number of satellites, especially in the low earth orbit. The major concern today is after the end of life, these satellites become debris which negatively affects the space environment. As per the international guidelines of the European Space Agency, it is mandatory to deorbit the satellite within 25 years of the end of life. StudSat1, which was successfully launched on 12th July 2010, is the first Pico satellite developed in India by undergraduate students from seven different engineering colleges across South India. Now, the team is developing StudSat2, which is India's first twin satellite mission having two nanosatellites whose overall mass is less than 10kg. This paper is aimed to design the propulsion system, cold gas thruster, to deorbit StudSat2 from its original orbit i.e. 600 km to lower orbit i.e. 400km. The propulsion system mainly consists of a storage tank, pipes, Convergent Divergent nozzle, and electronic actuators. The paper also gives information about the components of cold gas thruster, which have been designed in the CATIA V5, and the structural and flow analysis of the same has been done in ANSYS. The concept of Hohmann transfer has been used to deorbit the satellite and STK has been used to simulate it.