 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders
Aug 02, 2021
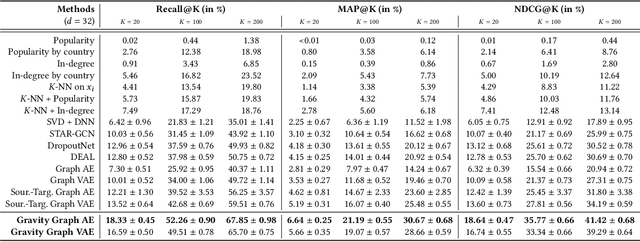
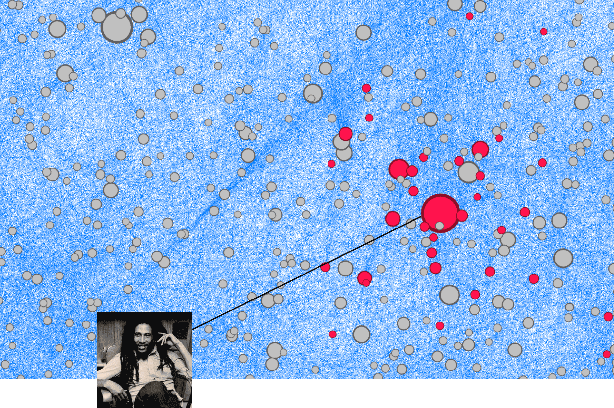
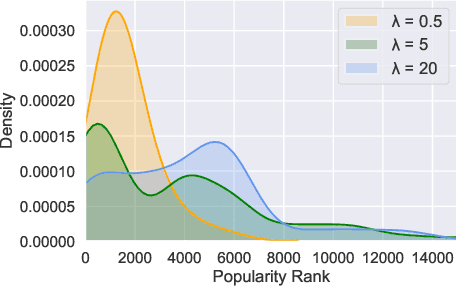
On an artist's profile page, music streaming services frequently recommend a ranked list of "similar artists" that fans also liked. However, implementing such a feature is challenging for new artists, for which usage data on the service (e.g. streams or likes) is not yet available. In this paper, we model this cold start similar artists ranking problem as a link prediction task in a directed and attributed graph, connecting artists to their top-k most similar neighbors and incorporating side musical information. Then, we leverage a graph autoencoder architecture to learn node embedding representations from this graph, and to automatically rank the top-k most similar neighbors of new artists using a gravity-inspired mechanism. We empirically show the flexibility and the effectiveness of our framework, by addressing a real-world cold start similar artists ranking problem on a global music streaming service. Along with this paper, we also publicly release our source code as well as the industrial graph data from our experiments.
Deep Reader: Information extraction from Document images via relation extraction and Natural Language
Dec 11, 2018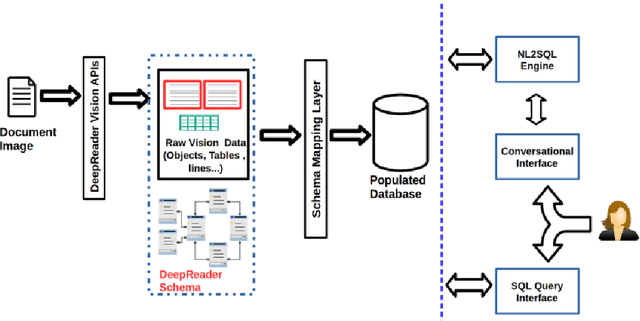
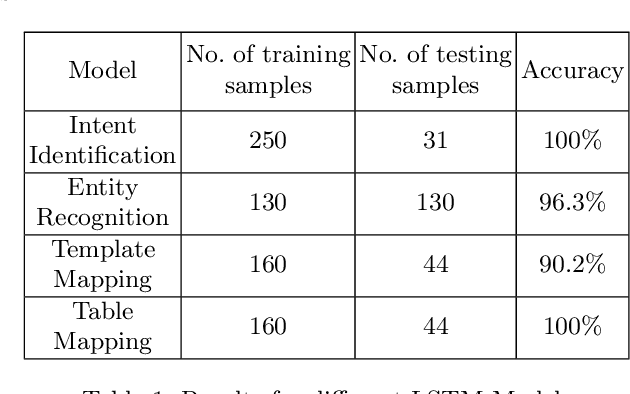
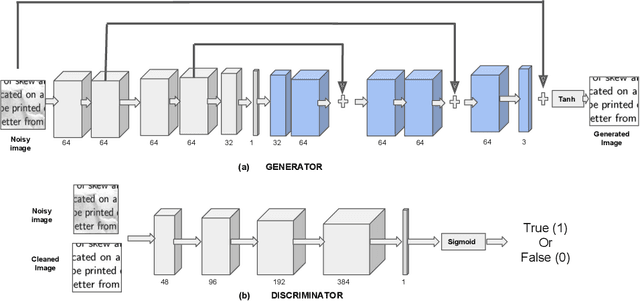

Recent advancements in the area of Computer Vision with state-of-art Neural Networks has given a boost to Optical Character Recognition (OCR) accuracies. However, extracting characters/text alone is often insufficient for relevant information extraction as documents also have a visual structure that is not captured by OCR. Extracting information from tables, charts, footnotes, boxes, headings and retrieving the corresponding structured representation for the document remains a challenge and finds application in a large number of real-world use cases. In this paper, we propose a novel enterprise based end-to-end framework called DeepReader which facilitates information extraction from document images via identification of visual entities and populating a meta relational model across different entities in the document image. The model schema allows for an easy to understand abstraction of the entities detected by the deep vision models and the relationships between them. DeepReader has a suite of state-of-the-art vision algorithms which are applied to recognize handwritten and printed text, eliminate noisy effects, identify the type of documents and detect visual entities like tables, lines and boxes. Deep Reader maps the extracted entities into a rich relational schema so as to capture all the relevant relationships between entities (words, textboxes, lines etc) detected in the document. Relevant information and fields can then be extracted from the document by writing SQL queries on top of the relationship tables. A natural language based interface is added on top of the relationship schema so that a non-technical user, specifying the queries in natural language, can fetch the information with minimal effort. In this paper, we also demonstrate many different capabilities of Deep Reader and report results on a real-world use case.
Representation and Correlation Enhanced Encoder-Decoder Framework for Scene Text Recognition
Jun 13, 2021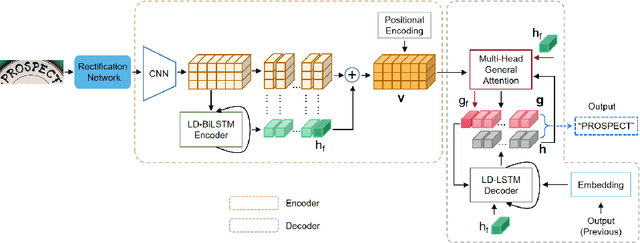
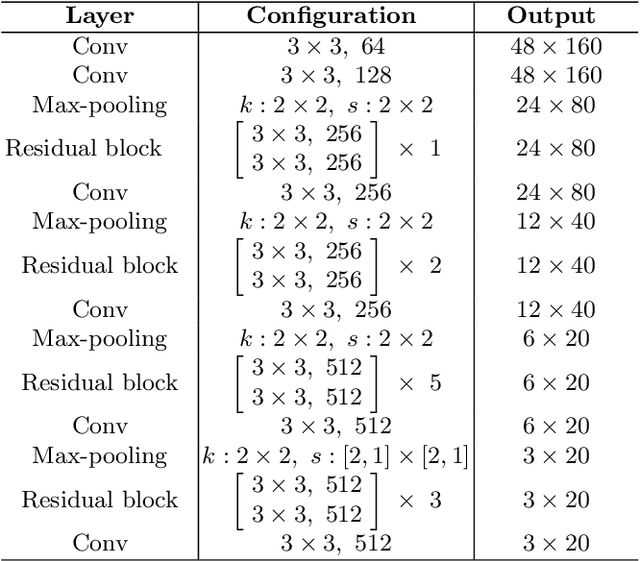

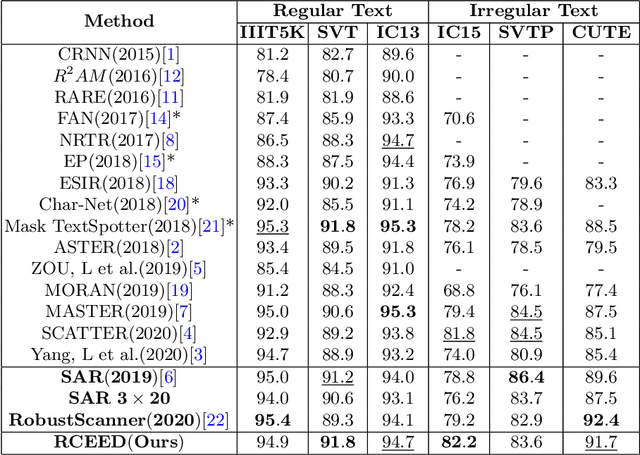
Attention-based encoder-decoder framework is widely used in the scene text recognition task. However, for the current state-of-the-art(SOTA) methods, there is room for improvement in terms of the efficient usage of local visual and global context information of the input text image, as well as the robust correlation between the scene processing module(encoder) and the text processing module(decoder). In this paper, we propose a Representation and Correlation Enhanced Encoder-Decoder Framework(RCEED) to address these deficiencies and break performance bottleneck. In the encoder module, local visual feature, global context feature, and position information are aligned and fused to generate a small-size comprehensive feature map. In the decoder module, two methods are utilized to enhance the correlation between scene and text feature space. 1) The decoder initialization is guided by the holistic feature and global glimpse vector exported from the encoder. 2) The feature enriched glimpse vector produced by the Multi-Head General Attention is used to assist the RNN iteration and the character prediction at each time step. Meanwhile, we also design a Layernorm-Dropout LSTM cell to improve model's generalization towards changeable texts. Extensive experiments on the benchmarks demonstrate the advantageous performance of RCEED in scene text recognition tasks, especially the irregular ones.
"The Squawk Bot": Joint Learning of Time Series and Text Data Modalities for Automated Financial Information Filtering
Dec 20, 2019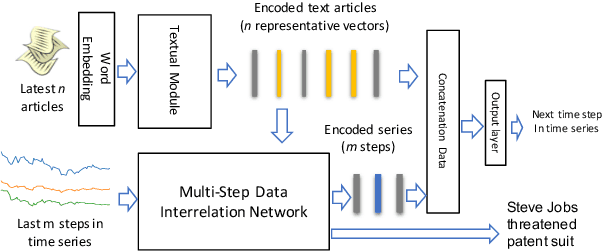
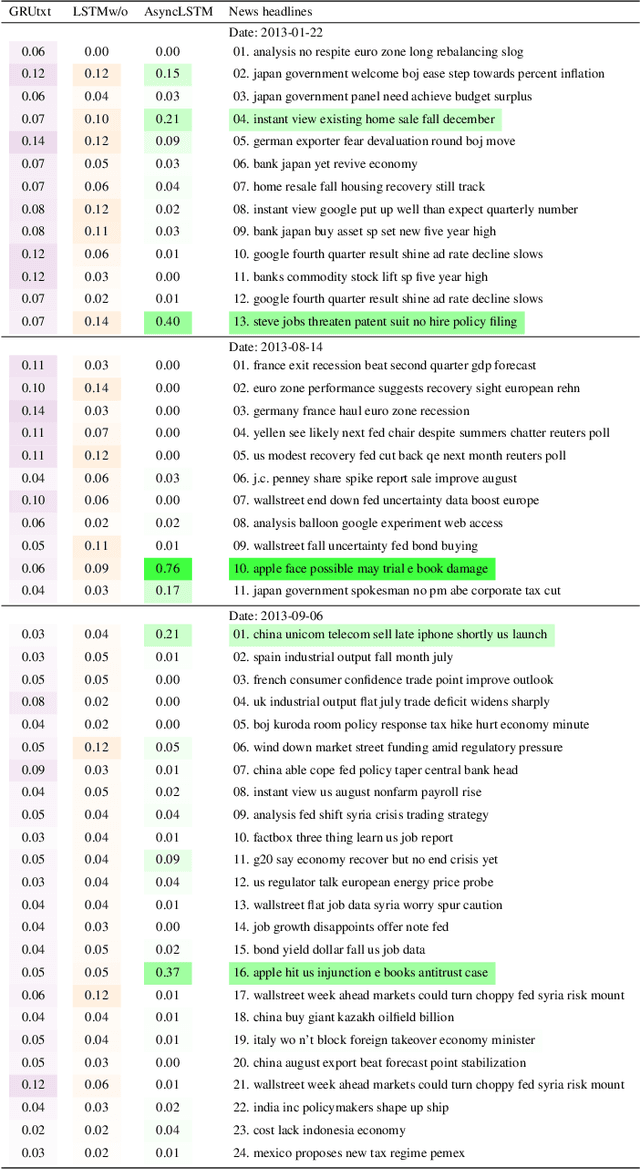
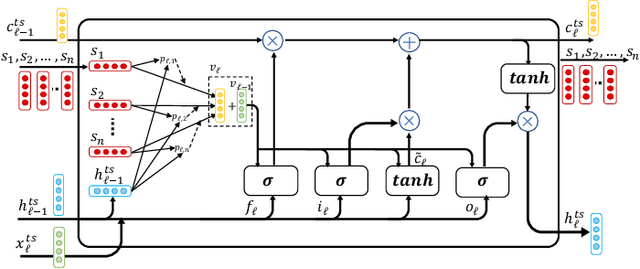
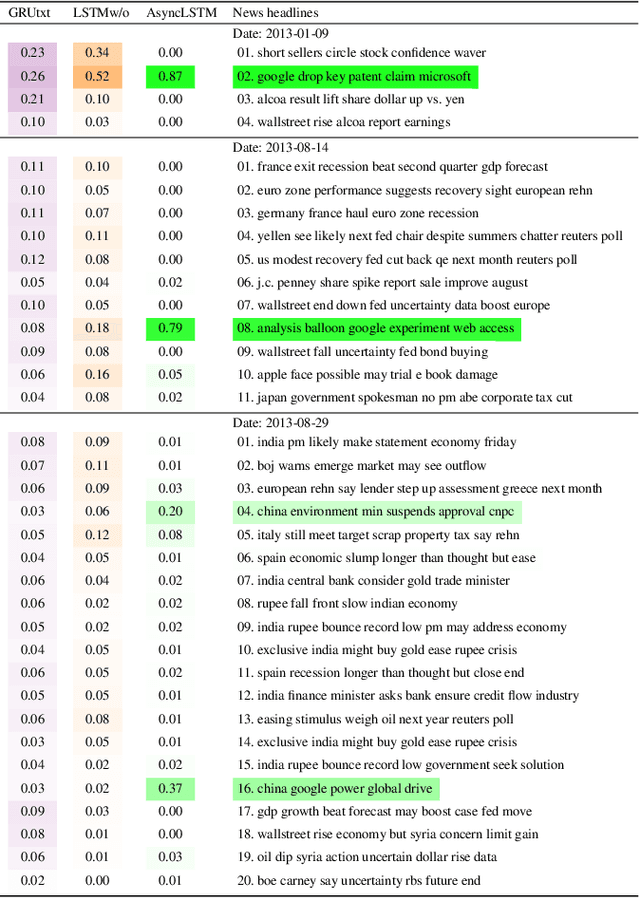
Multimodal analysis that uses numerical time series and textual corpora as input data sources is becoming a promising approach, especially in the financial industry. However, the main focus of such analysis has been on achieving high prediction accuracy while little effort has been spent on the important task of understanding the association between the two data modalities. Performance on the time series hence receives little explanation though human-understandable textual information is available. In this work, we address the problem of given a numerical time series, and a general corpus of textual stories collected in the same period of the time series, the task is to timely discover a succinct set of textual stories associated with that time series. Towards this goal, we propose a novel multi-modal neural model called MSIN that jointly learns both numerical time series and categorical text articles in order to unearth the association between them. Through multiple steps of data interrelation between the two data modalities, MSIN learns to focus on a small subset of text articles that best align with the performance in the time series. This succinct set is timely discovered and presented as recommended documents, acting as automated information filtering, for the given time series. We empirically evaluate the performance of our model on discovering relevant news articles for two stock time series from Apple and Google companies, along with the daily news articles collected from the Thomson Reuters over a period of seven consecutive years. The experimental results demonstrate that MSIN achieves up to 84.9% and 87.2% in recalling the ground truth articles respectively to the two examined time series, far more superior to state-of-the-art algorithms that rely on conventional attention mechanism in deep learning.
A Predictive Application Offloading Algorithm Using Small Datasets for Cloud Robotics
Aug 28, 2021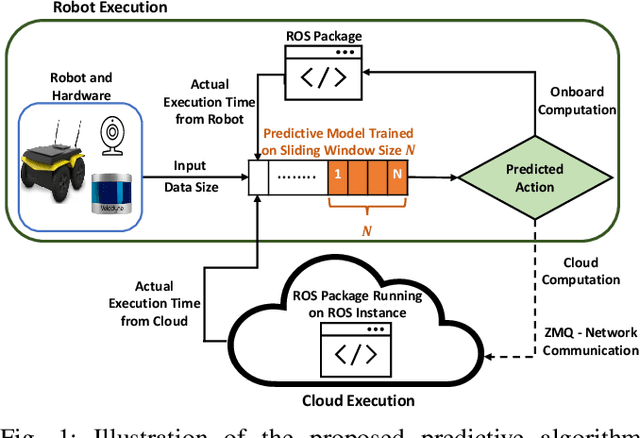
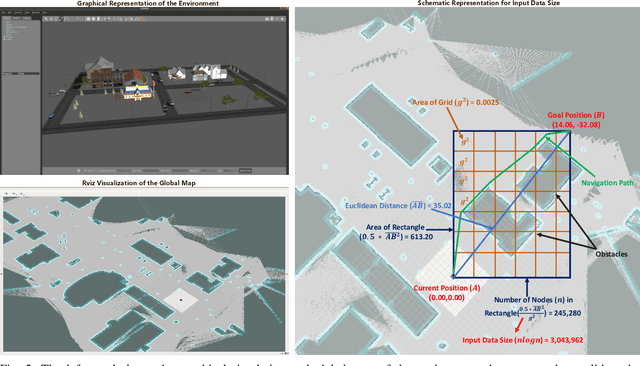
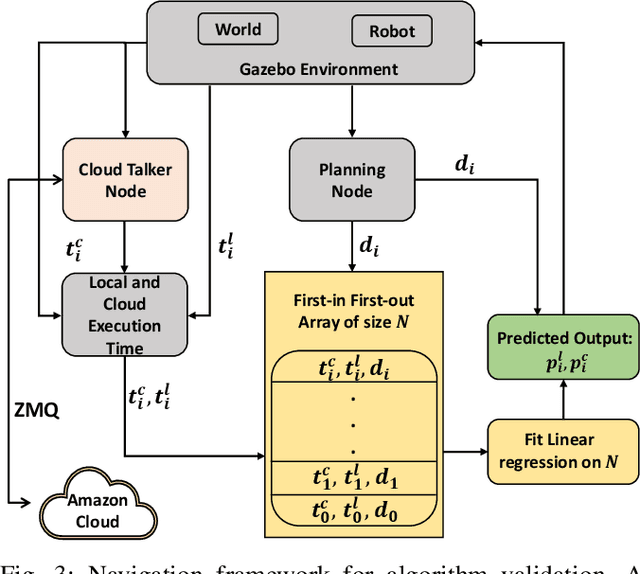

Many robotic applications that are critical for robot performance require immediate feedback, hence execution time is a critical concern. Furthermore, it is common that robots come with a fixed quantity of hardware resources; if an application requires more computational resources than the robot can accommodate, its onboard execution might be extended to a degree that degrades the robot performance. Cloud computing, on the other hand, features on-demand computational resources; by enabling robots to leverage those resources, application execution time can be reduced. The key to enabling robot use of cloud computing is designing an efficient offloading algorithm that makes optimum use of the robot onboard capabilities and also forms a quick consensus on when to offload without any prior knowledge or information about the application. In this paper, we propose a predictive algorithm to anticipate the time needed to execute an application for a given application data input size with the help of a small number of previous observations. To validate the algorithm, we train it on the previous N observations, which include independent (input data size) and dependent (execution time) variables. To understand how algorithm performance varies in terms of prediction accuracy and error, we tested various N values using linear regression and a mobile robot path planning application. From our experiments and analysis, we determined the algorithm to have acceptable error and prediction accuracy when N>40.
Large-scale quantum machine learning
Aug 02, 2021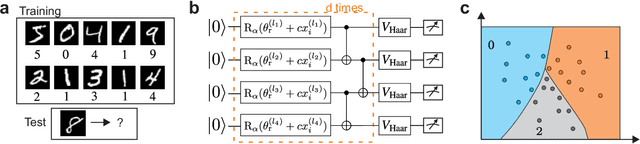
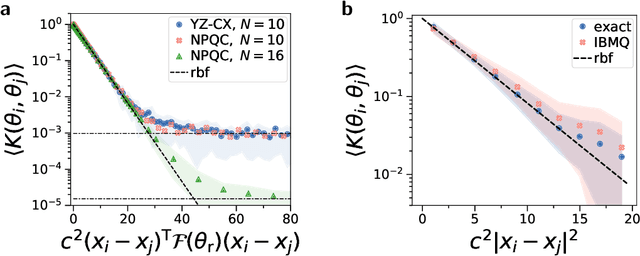
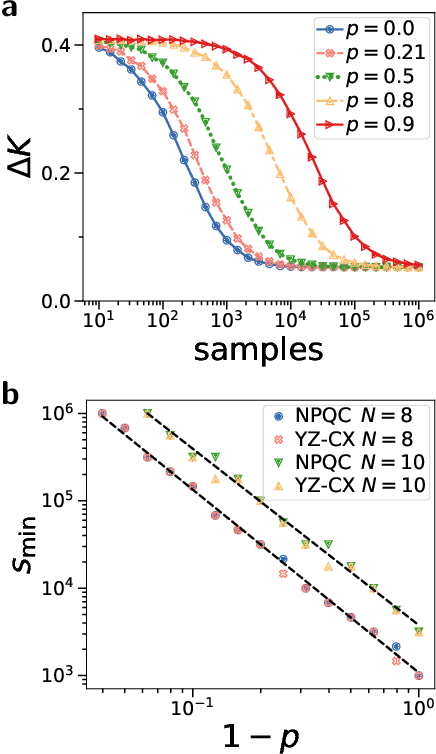
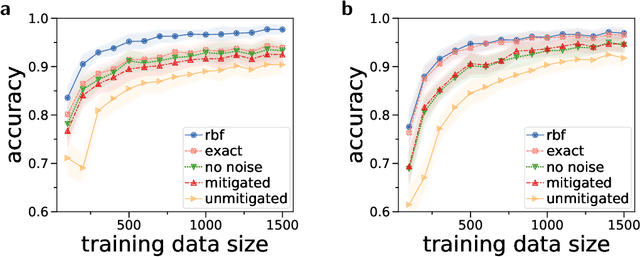
Quantum computers promise to enhance machine learning for practical applications. Quantum machine learning for real-world data has to handle extensive amounts of high-dimensional data. However, conventional methods for measuring quantum kernels are impractical for large datasets as they scale with the square of the dataset size. Here, we measure quantum kernels using randomized measurements to gain a quadratic speedup in computation time and quickly process large datasets. Further, we efficiently encode high-dimensional data into quantum computers with the number of features scaling linearly with the circuit depth. The encoding is characterized by the quantum Fisher information metric and is related to the radial basis function kernel. We demonstrate the advantages and speedups of our methods by classifying images with the IBM quantum computer. Our approach is exceptionally robust to noise via a complementary error mitigation scheme. Using currently available quantum computers, the MNIST database can be processed within 220 hours instead of 10 years which opens up industrial applications of quantum machine learning.
Electroencephalogram Signal Processing with Independent Component Analysis and Cognitive Stress Classification using Convolutional Neural Networks
Aug 22, 2021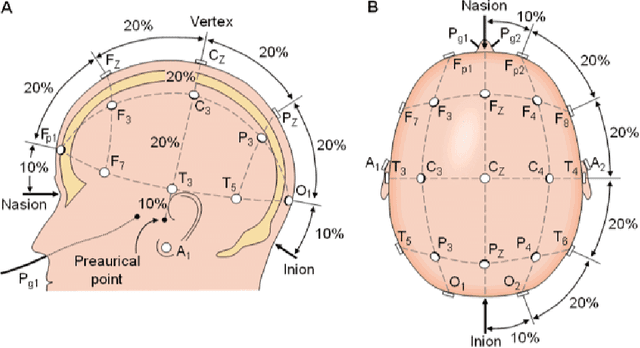
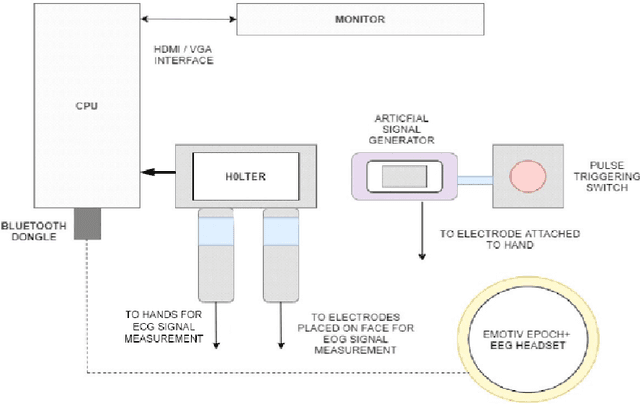
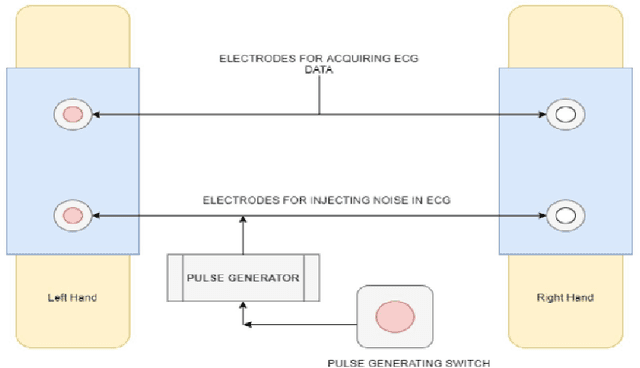
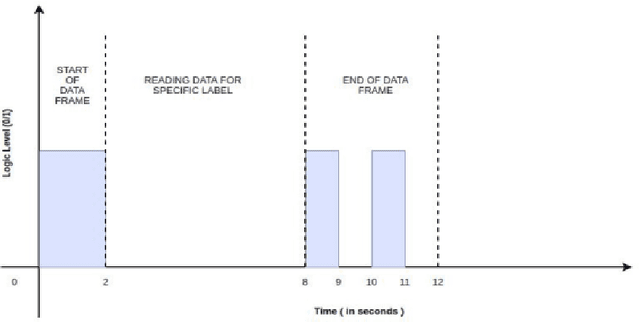
Electroencephalogram (EEG) is the recording which is the result due to the activity of bio-electrical signals that is acquired from electrodes placed on the scalp. In Electroencephalogram signal(EEG) recordings, the signals obtained are contaminated predominantly by the Electrooculogram(EOG) signal. Since this artifact has higher magnitude compared to EEG signals, these noise signals have to be removed in order to have a better understanding regarding the functioning of a human brain for applications such as medical diagnosis. This paper proposes an idea of using Independent Component Analysis(ICA) along with cross-correlation to de-noise EEG signal. This is done by selecting the component based on the cross-correlation coefficient with a threshold value and reducing its effect instead of zeroing it out completely, thus reducing the information loss. The results of the recorded data show that this algorithm can eliminate the EOG signal artifact with little loss in EEG data. The denoising is verified by an increase in SNR value and the decrease in cross-correlation coefficient value. The denoised signals are used to train an Artificial Neural Network(ANN) which would examine the features of the input EEG signal and predict the stress levels of the individual.
Rule-Based Classification of Hyperspectral Imaging Data
Jul 21, 2021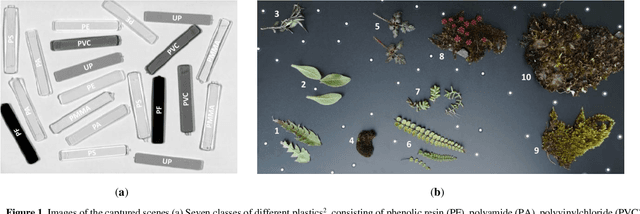
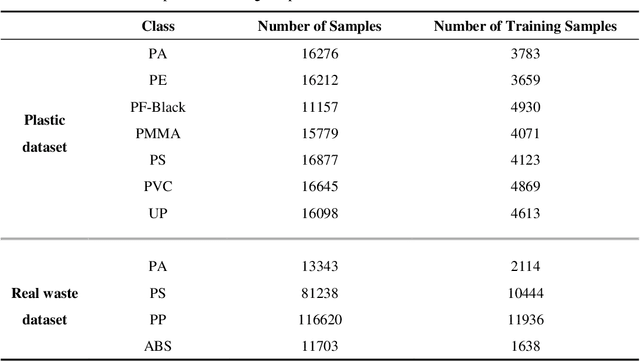
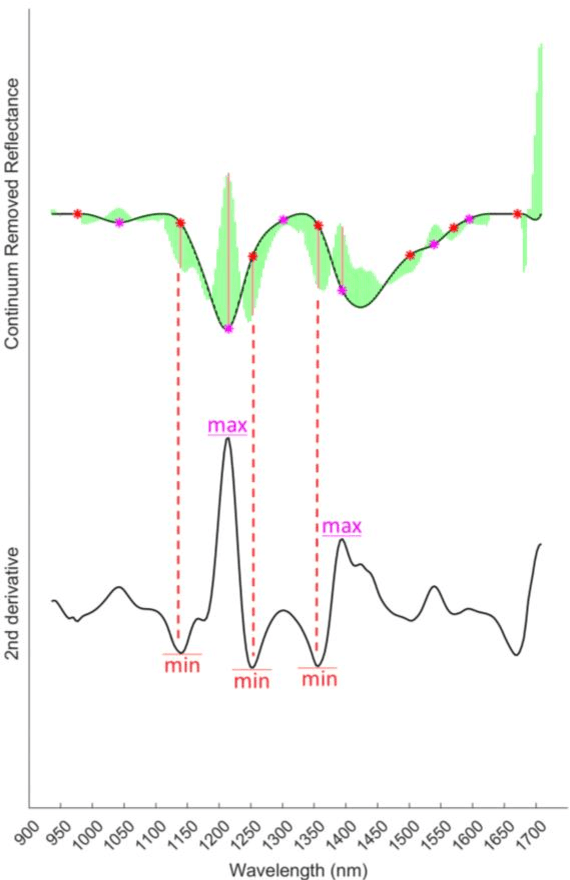
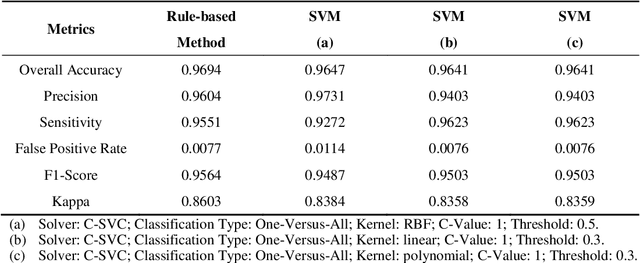
Due to its high spatial and spectral information content, hyperspectral imaging opens up new possibilities for a better understanding of data and scenes in a wide variety of applications. An essential part of this process of understanding is the classification part. In this article we present a general classification approach based on the shape of spectral signatures. In contrast to classical classification approaches (e.g. SVM, KNN), not only reflectance values are considered, but also parameters such as curvature points, curvature values, and the curvature behavior of spectral signatures are used to develop shape-describing rules in order to use them for classification by a rule-based procedure using IF-THEN queries. The flexibility and efficiency of the methodology is demonstrated using datasets from two different application fields and leads to convincing results with good performance.
Distributed Attention for Grounded Image Captioning
Aug 22, 2021
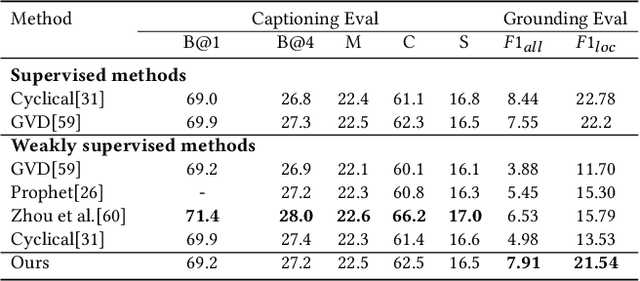
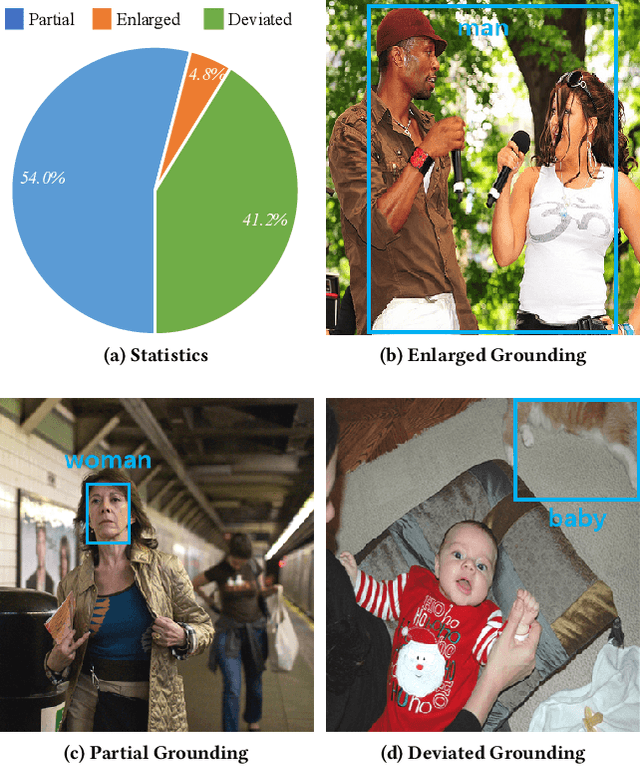
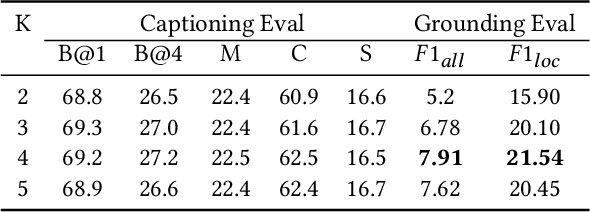
We study the problem of weakly supervised grounded image captioning. That is, given an image, the goal is to automatically generate a sentence describing the context of the image with each noun word grounded to the corresponding region in the image. This task is challenging due to the lack of explicit fine-grained region word alignments as supervision. Previous weakly supervised methods mainly explore various kinds of regularization schemes to improve attention accuracy. However, their performances are still far from the fully supervised ones. One main issue that has been ignored is that the attention for generating visually groundable words may only focus on the most discriminate parts and can not cover the whole object. To this end, we propose a simple yet effective method to alleviate the issue, termed as partial grounding problem in our paper. Specifically, we design a distributed attention mechanism to enforce the network to aggregate information from multiple spatially different regions with consistent semantics while generating the words. Therefore, the union of the focused region proposals should form a visual region that encloses the object of interest completely. Extensive experiments have demonstrated the superiority of our proposed method compared with the state-of-the-arts.
Wind Power Projection using Weather Forecasts by Novel Deep Neural Networks
Aug 22, 2021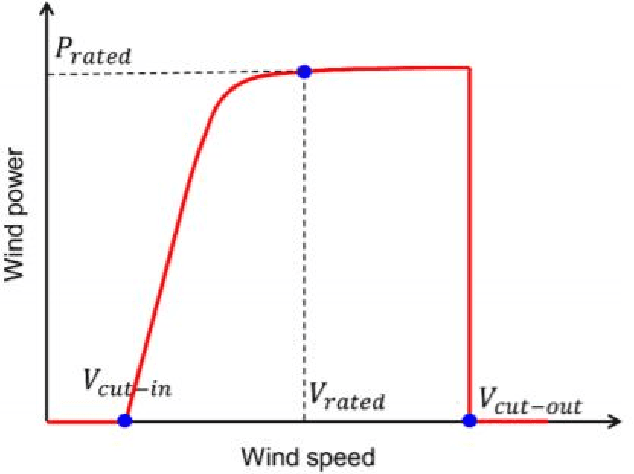
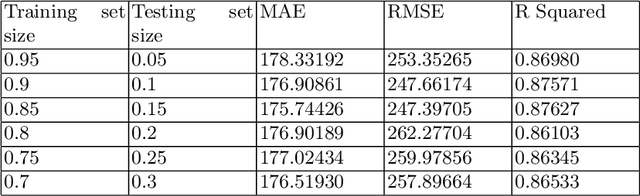
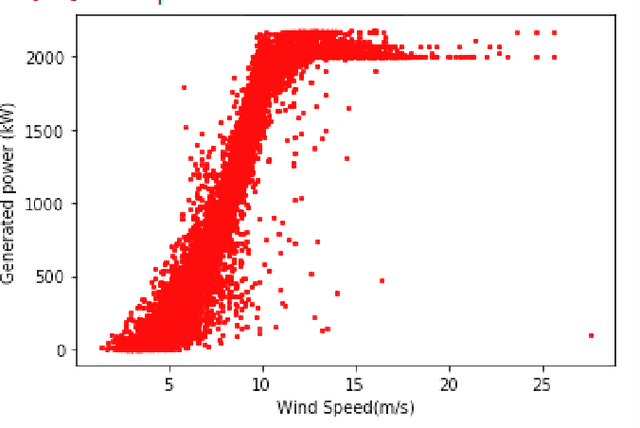
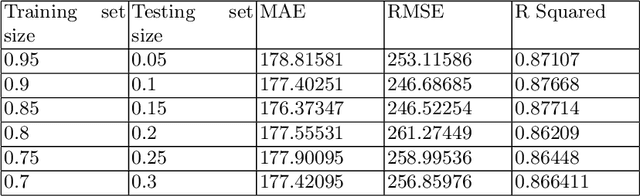
The transition from conventional methods of energy production to renewable energy production necessitates better prediction models of the upcoming supply of renewable energy. In wind power production, error in forecasting production is impossible to negate owing to the intermittence of wind. For successful power grid integration, it is crucial to understand the uncertainties that arise in predicting wind power production and use this information to build an accurate and reliable forecast. This can be achieved by observing the fluctuations in wind power production with changes in different parameters such as wind speed, temperature, and wind direction, and deriving functional dependencies for the same. Using optimized machine learning algorithms, it is possible to find obscured patterns in the observations and obtain meaningful data, which can then be used to accurately predict wind power requirements . Utilizing the required data provided by the Gamesa's wind farm at Bableshwar, the paper explores the use of both parametric and the non-parametric models for calculating wind power prediction using power curves. The obtained results are subject to comparison to better understand the accuracy of the utilized models and to determine the most suitable model for predicting wind power production based on the given data set.