 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Knowledge Graph Reasoning with Relational Directed Graph
Aug 13, 2021
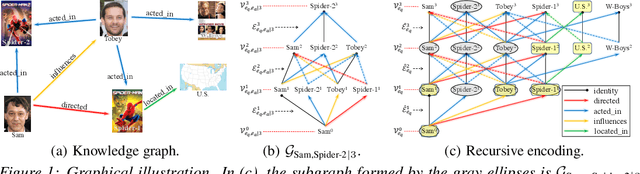
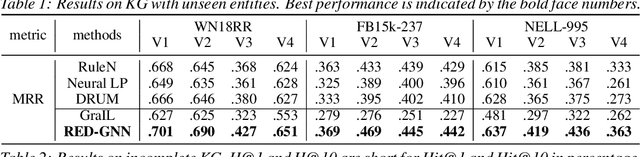
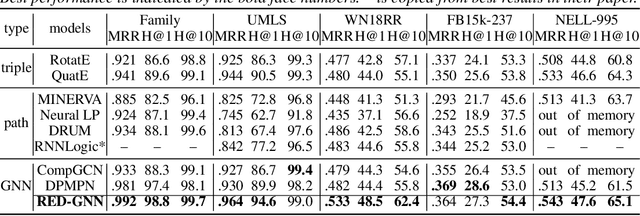
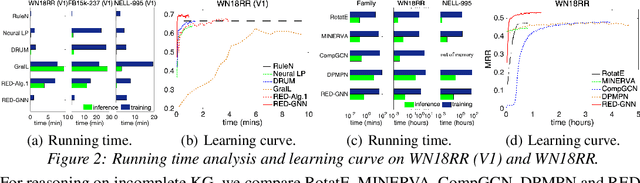
Reasoning on the knowledge graph (KG) aims to infer new facts from existing ones. Methods based on the relational path in the literature have shown strong, interpretable, and inductive reasoning ability. However, the paths are naturally limited in capturing complex topology in KG. In this paper, we introduce a novel relational structure, i.e., relational directed graph (r-digraph), which is composed of overlapped relational paths, to capture the KG's structural information. Since the digraph exhibits more complex structure than paths, constructing and learning on the r-digraph are challenging. Here, we propose a variant of graph neural network, i.e., RED-GNN, to address the above challenges by learning the RElational Digraph with a variant of GNN. Specifically, RED-GNN recursively encodes multiple r-digraphs with shared edges and selects the strongly correlated edges through query-dependent attention weights. We demonstrate the significant gains on reasoning both KG with unseen entities and incompletion KG benchmarks by the r-digraph, the efficiency of RED-GNN, and the interpretable dependencies learned on the r-digraph.
Zero-shot Medical Entity Retrieval without Annotation: Learning From Rich Knowledge Graph Semantics
May 26, 2021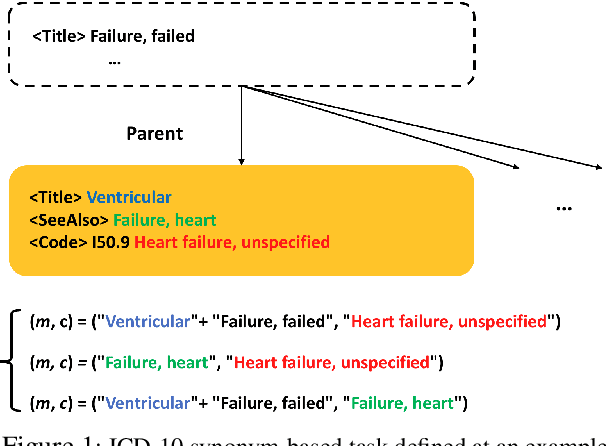
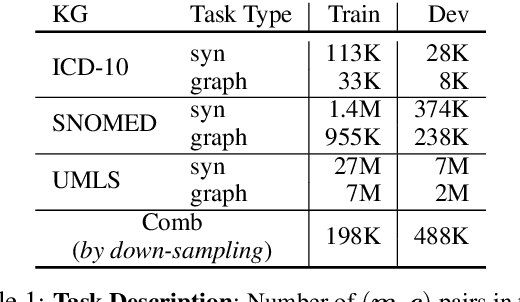
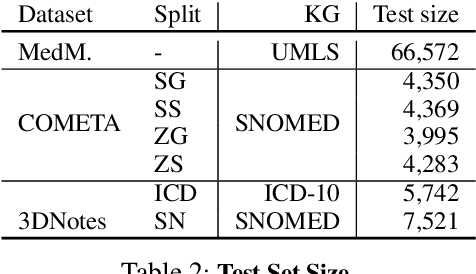
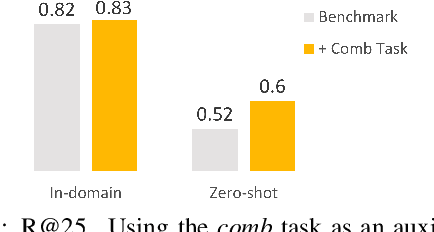
Medical entity retrieval is an integral component for understanding and communicating information across various health systems. Current approaches tend to work well on specific medical domains but generalize poorly to unseen sub-specialties. This is of increasing concern under a public health crisis as new medical conditions and drug treatments come to light frequently. Zero-shot retrieval is challenging due to the high degree of ambiguity and variability in medical corpora, making it difficult to build an accurate similarity measure between mentions and concepts. Medical knowledge graphs (KG), however, contain rich semantics including large numbers of synonyms as well as its curated graphical structures. To take advantage of this valuable information, we propose a suite of learning tasks designed for training efficient zero-shot entity retrieval models. Without requiring any human annotation, our knowledge graph enriched architecture significantly outperforms common zero-shot benchmarks including BM25 and Clinical BERT with 7% to 30% higher recall across multiple major medical ontologies, such as UMLS, SNOMED, and ICD-10.
A Multi-modal and Multi-task Learning Method for Action Unit and Expression Recognition
Jul 15, 2021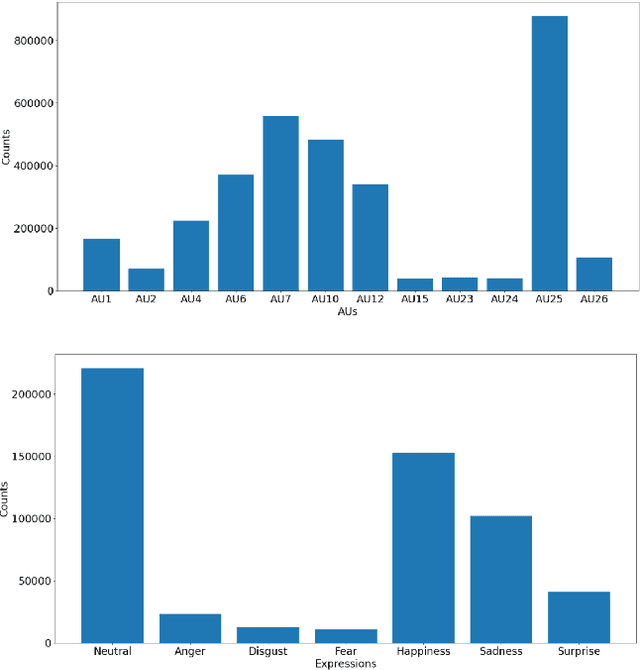

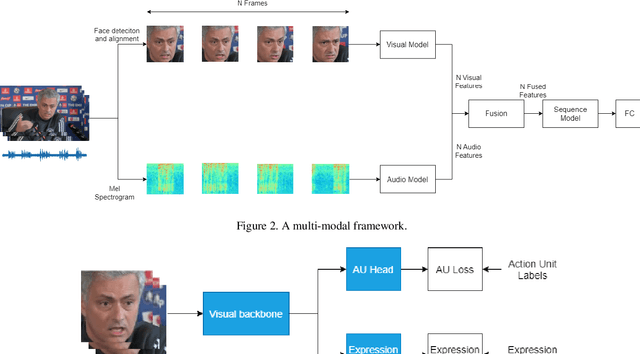
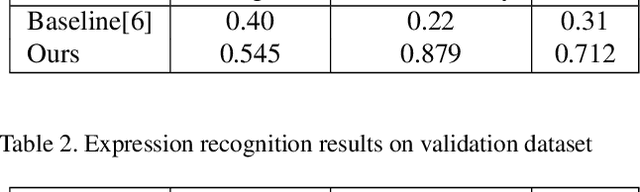
Analyzing human affect is vital for human-computer interaction systems. Most methods are developed in restricted scenarios which are not practical for in-the-wild settings. The Affective Behavior Analysis in-the-wild (ABAW) 2021 Contest provides a benchmark for this in-the-wild problem. In this paper, we introduce a multi-modal and multi-task learning method by using both visual and audio information. We use both AU and expression annotations to train the model and apply a sequence model to further extract associations between video frames. We achieve an AU score of 0.712 and an expression score of 0.477 on the validation set. These results demonstrate the effectiveness of our approach in improving model performance.
A Model-Agnostic Algorithm for Bayes Error Determination in Binary Classification
Jul 24, 2021

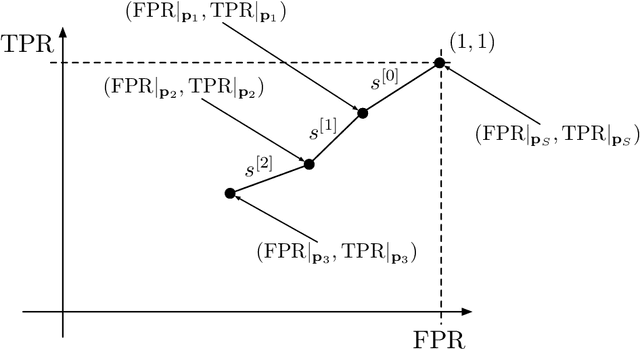
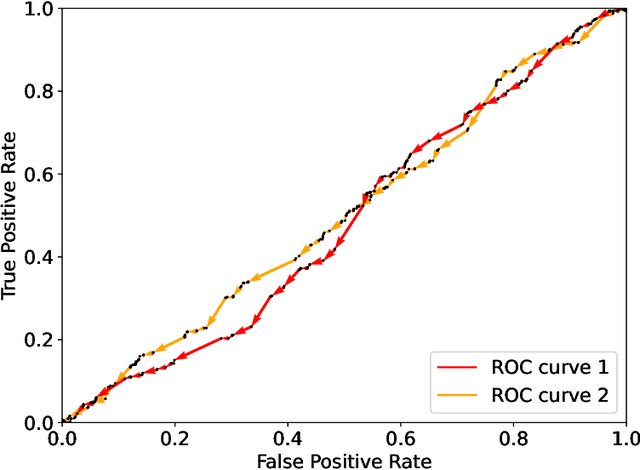
This paper presents the intrinsic limit determination algorithm (ILD Algorithm), a novel technique to determine the best possible performance, measured in terms of the AUC (area under the ROC curve) and accuracy, that can be obtained from a specific dataset in a binary classification problem with categorical features {\sl regardless} of the model used. This limit, namely the Bayes error, is completely independent of any model used and describes an intrinsic property of the dataset. The ILD algorithm thus provides important information regarding the prediction limits of any binary classification algorithm when applied to the considered dataset. In this paper the algorithm is described in detail, its entire mathematical framework is presented and the pseudocode is given to facilitate its implementation. Finally, an example with a real dataset is given.
Context-aware Adversarial Training for Name Regularity Bias in Named Entity Recognition
Jul 24, 2021In this work, we examine the ability of NER models to use contextual information when predicting the type of an ambiguous entity. We introduce NRB, a new testbed carefully designed to diagnose Name Regularity Bias of NER models. Our results indicate that all state-of-the-art models we tested show such a bias; BERT fine-tuned models significantly outperforming feature-based (LSTM-CRF) ones on NRB, despite having comparable (sometimes lower) performance on standard benchmarks. To mitigate this bias, we propose a novel model-agnostic training method that adds learnable adversarial noise to some entity mentions, thus enforcing models to focus more strongly on the contextual signal, leading to significant gains on NRB. Combining it with two other training strategies, data augmentation and parameter freezing, leads to further gains.
* MIT Press\TACL 2021\Presented at ACL 2021 This is the exact same content of the TACL version, except the figures and tables are better aligned
Integrating Human-Provided Information Into Belief State Representation Using Dynamic Factorization
Jul 30, 2018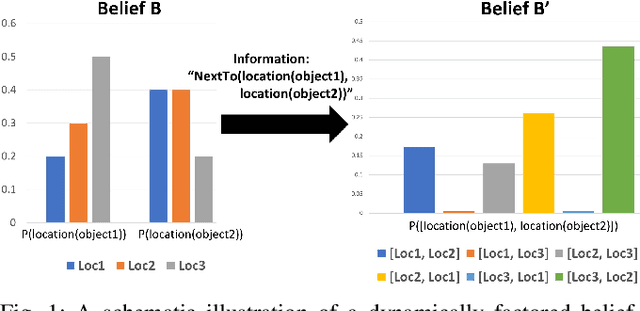
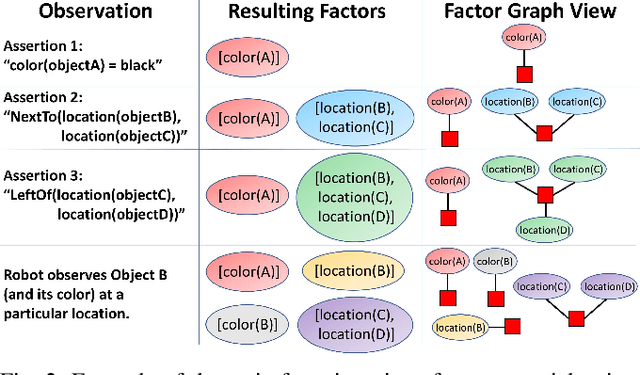
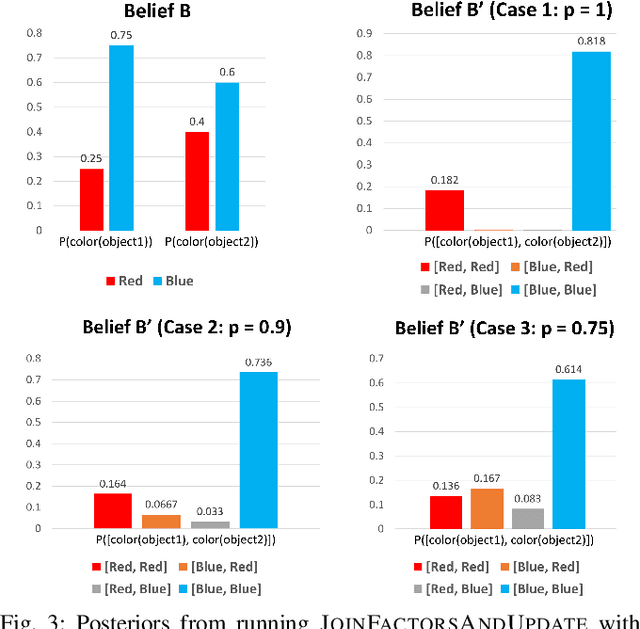
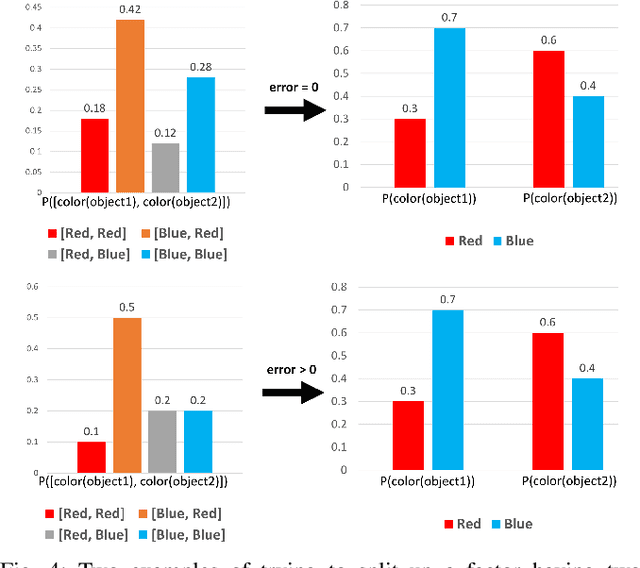
In partially observed environments, it can be useful for a human to provide the robot with declarative information that represents probabilistic relational constraints on properties of objects in the world, augmenting the robot's sensory observations. For instance, a robot tasked with a search-and-rescue mission may be informed by the human that two victims are probably in the same room. An important question arises: how should we represent the robot's internal knowledge so that this information is correctly processed and combined with raw sensory information? In this paper, we provide an efficient belief state representation that dynamically selects an appropriate factoring, combining aspects of the belief when they are correlated through information and separating them when they are not. This strategy works in open domains, in which the set of possible objects is not known in advance, and provides significant improvements in inference time over a static factoring, leading to more efficient planning for complex partially observed tasks. We validate our approach experimentally in two open-domain planning problems: a 2D discrete gridworld task and a 3D continuous cooking task. A supplementary video can be found at http://tinyurl.com/chitnis-iros-18.
SiReN: Sign-Aware Recommendation Using Graph Neural Networks
Aug 19, 2021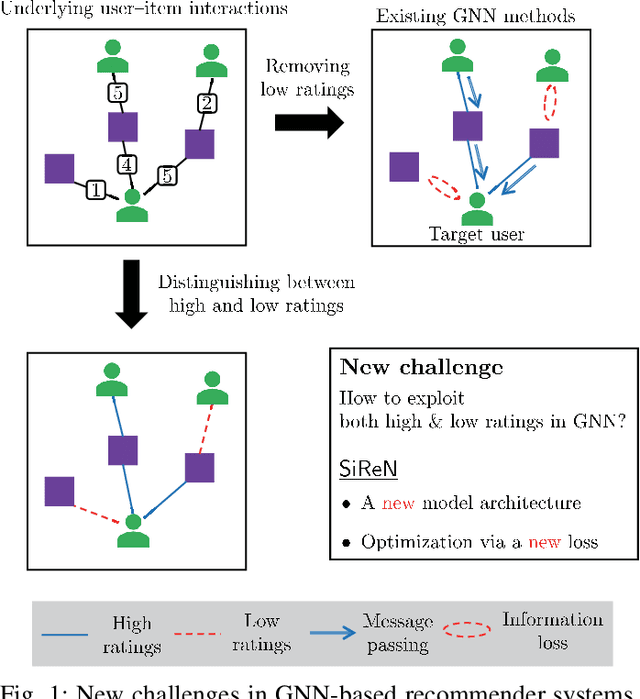
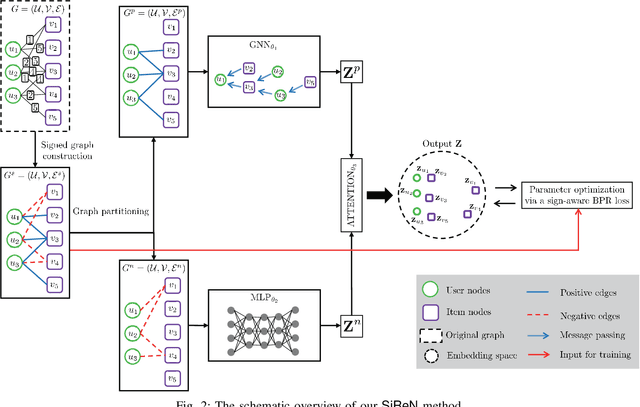
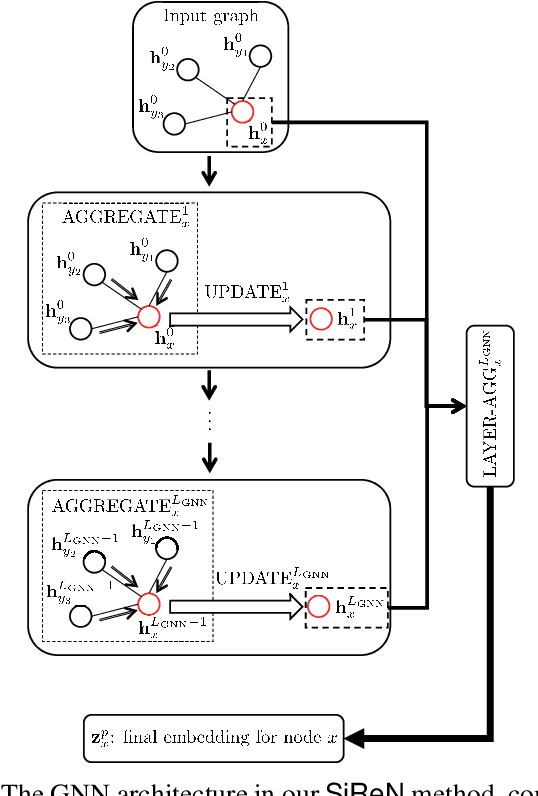
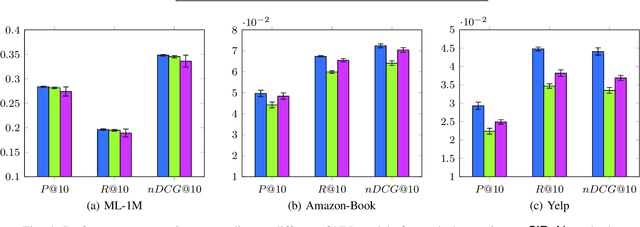
In recent years, many recommender systems using network embedding (NE) such as graph neural networks (GNNs) have been extensively studied in the sense of improving recommendation accuracy. However, such attempts have focused mostly on utilizing only the information of positive user-item interactions with high ratings. Thus, there is a challenge on how to make use of low rating scores for representing users' preferences since low ratings can be still informative in designing NE-based recommender systems. In this study, we present SiReN, a new sign-aware recommender system based on GNN models. Specifically, SiReN has three key components: 1) constructing a signed bipartite graph for more precisely representing users' preferences, which is split into two edge-disjoint graphs with positive and negative edges each, 2) generating two embeddings for the partitioned graphs with positive and negative edges via a GNN model and a multi-layer perceptron (MLP), respectively, and then using an attention model to obtain the final embeddings, and 3) establishing a sign-aware Bayesian personalized ranking (BPR) loss function in the process of optimization. Through comprehensive experiments, we empirically demonstrate that SiReN consistently outperforms state-of-the-art NE-aided recommendation methods.
A color temperature-based high-speed decolorization: an empirical approach for tone mapping applications
Aug 31, 2021Grayscale images are fundamental to many image processing applications like data compression, feature extraction, printing and tone mapping. However, some image information is lost when converting from color to grayscale. In this paper, we propose a light-weight and high-speed image decolorization method based on human perception of color temperatures. Chromatic aberration results from differential refraction of light depending on its wavelength. It causes some rays corresponding to cooler colors (like blue, green) to converge before the warmer colors (like red, orange). This phenomena creates a perception of warm colors "advancing" toward the eye, while the cool colors to be "receding" away. In this proposed color to gray conversion model, we implement a weighted blending function to combine red (perceived warm) and blue (perceived cool) channel. Our main contribution is threefold: First, we implement a high-speed color processing method using exact pixel by pixel processing, and we report a $5.7\times$ speed up when compared to other new algorithms. Second, our optimal color conversion method produces luminance in images that are comparable to other state of the art methods which we quantified using the objective metrics (E-score and C2G-SSIM) and a subjective user study. Third, we demonstrate that an effective luminance distribution can be achieved using our algorithm by using global and local tone mapping applications.
Quantum Continual Learning Overcoming Catastrophic Forgetting
Aug 05, 2021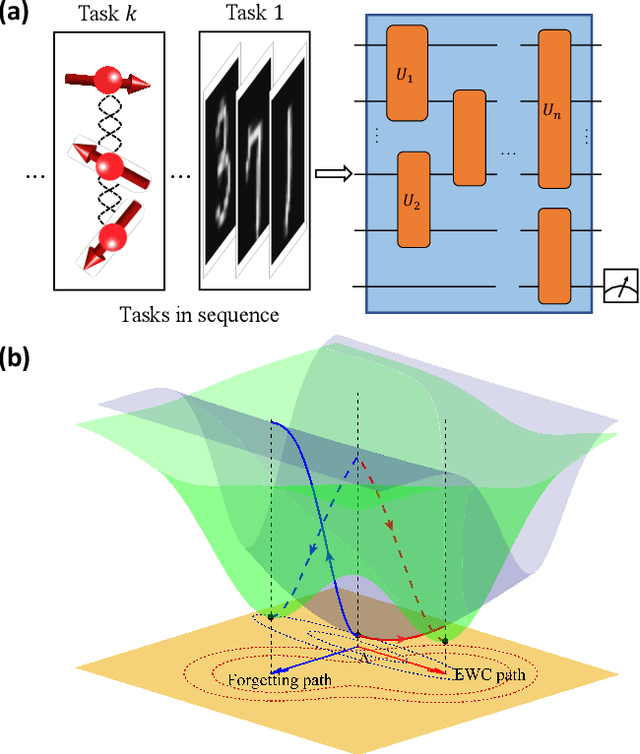
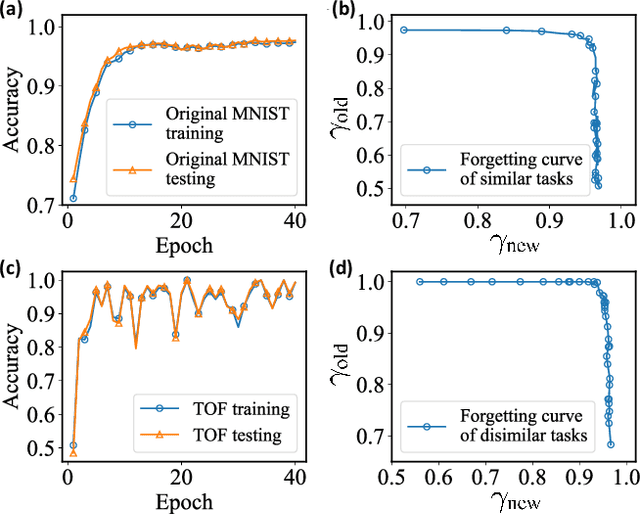
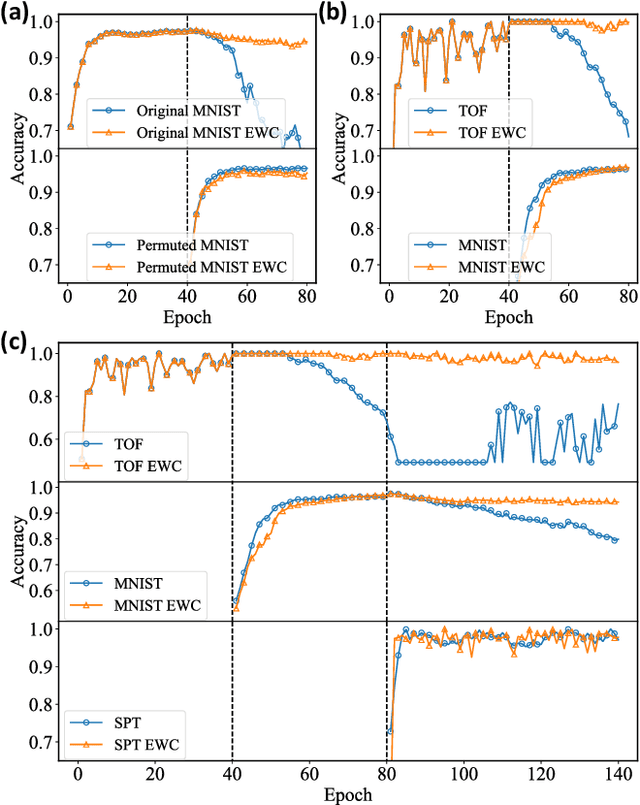
Catastrophic forgetting describes the fact that machine learning models will likely forget the knowledge of previously learned tasks after the learning process of a new one. It is a vital problem in the continual learning scenario and recently has attracted tremendous concern across different communities. In this paper, we explore the catastrophic forgetting phenomena in the context of quantum machine learning. We find that, similar to those classical learning models based on neural networks, quantum learning systems likewise suffer from such forgetting problem in classification tasks emerging from various application scenes. We show that based on the local geometrical information in the loss function landscape of the trained model, a uniform strategy can be adapted to overcome the forgetting problem in the incremental learning setting. Our results uncover the catastrophic forgetting phenomena in quantum machine learning and offer a practical method to overcome this problem, which opens a new avenue for exploring potential quantum advantages towards continual learning.
How to cheat with metrics in single-image HDR reconstruction
Aug 19, 2021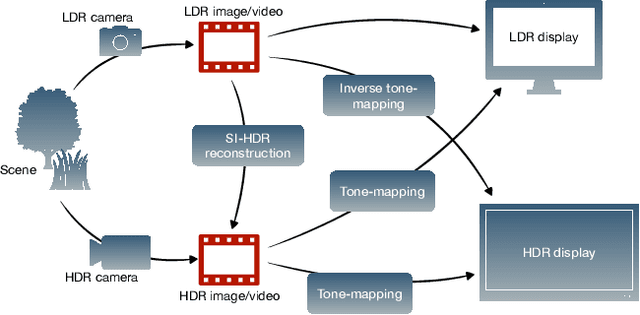
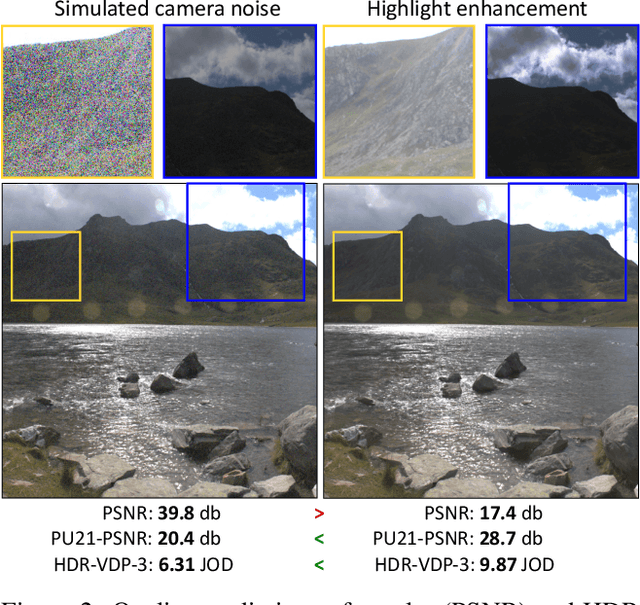
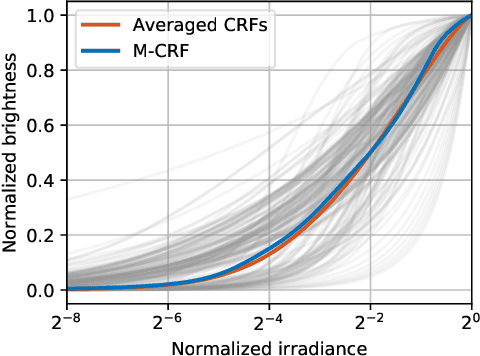
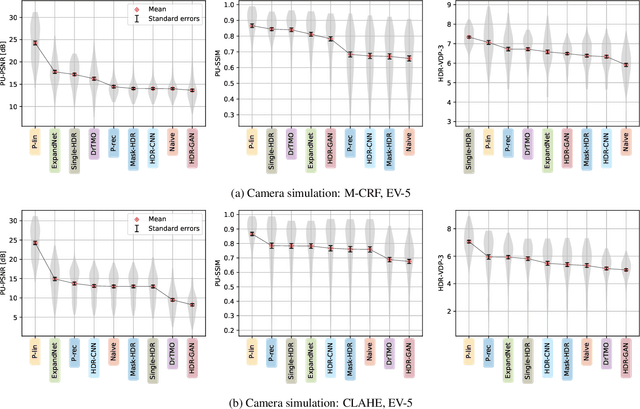
Single-image high dynamic range (SI-HDR) reconstruction has recently emerged as a problem well-suited for deep learning methods. Each successive technique demonstrates an improvement over existing methods by reporting higher image quality scores. This paper, however, highlights that such improvements in objective metrics do not necessarily translate to visually superior images. The first problem is the use of disparate evaluation conditions in terms of data and metric parameters, calling for a standardized protocol to make it possible to compare between papers. The second problem, which forms the main focus of this paper, is the inherent difficulty in evaluating SI-HDR reconstructions since certain aspects of the reconstruction problem dominate objective differences, thereby introducing a bias. Here, we reproduce a typical evaluation using existing as well as simulated SI-HDR methods to demonstrate how different aspects of the problem affect objective quality metrics. Surprisingly, we found that methods that do not even reconstruct HDR information can compete with state-of-the-art deep learning methods. We show how such results are not representative of the perceived quality and that SI-HDR reconstruction needs better evaluation protocols.