Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-modal and Multi-task Learning Method for Action Unit and Expression Recognition
Paper and Code
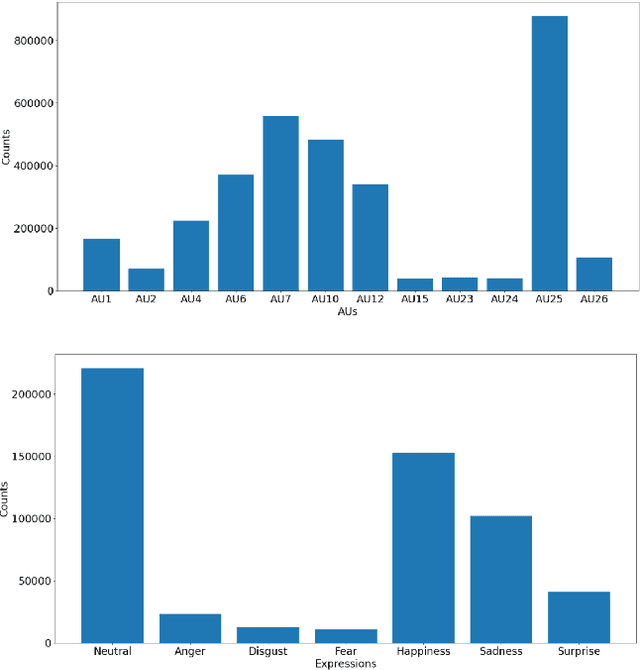

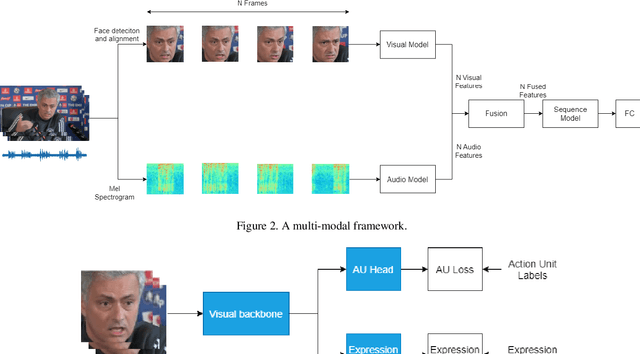
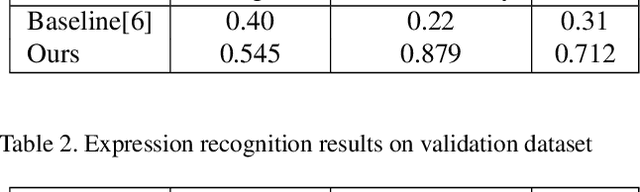
Analyzing human affect is vital for human-computer interaction systems. Most methods are developed in restricted scenarios which are not practical for in-the-wild settings. The Affective Behavior Analysis in-the-wild (ABAW) 2021 Contest provides a benchmark for this in-the-wild problem. In this paper, we introduce a multi-modal and multi-task learning method by using both visual and audio information. We use both AU and expression annotations to train the model and apply a sequence model to further extract associations between video frames. We achieve an AU score of 0.712 and an expression score of 0.477 on the validation set. These results demonstrate the effectiveness of our approach in improving model performance.
* 5 pages, 3 figures, 2 tables
View paper on