 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmaller and Faster 3DGS via Post-Training Dictionary Learning
May 28, 20263D Gaussian Splatting (3DGS) is a promising neural scene representation for real-time rendering, but trained models often suffer from large memory footprints, limiting deployment on less powerful devices. Existing compression techniques often lead to architectures with several additional trainable parameters. While achieving outstanding compression ratios, they introduce noticeable drops in image quality. In this work, we introduce the first dictionary-learning-based compression framework for 3DGS. The proposed post-training compression pipeline can be deployed in virtually any 3DGS model without the need for re-training or modifications to existing 3DGS models. Our compression framework is straightforward to implement, yet provides significant compression capabilities, preserves image quality, and improves real-time rendering performance. Across 13 benchmark scenes, our approach achieves an average compression ratio of 3.95x, 3.10x, and 4.55x when applied to 3DGS, 3DGS-MCMC, and PixelGS, respectively. This yields consistent rendering speedups of 23.3%, 24.3%, and 25.3%, while maintaining image quality.
Towards Controllable Image Generation through Representation-Conditioned Diffusion Models
May 26, 2026Diffusion models have emerged as powerful tools for high-quality image generation and editing, but guiding these models to produce specific outputs remains a challenge. Conventional approaches rely on conditioning mechanisms, such as text prompts or semantic maps, which require extensively annotated datasets. In this preliminary work, we explore diffusion models conditioned on representations from a pre-trained self-supervised model. The self-conditioning mechanism not only improves the quality of unconditional image generation, but also provides a representation space that can be used to control the generation. We explore this conditioning space by identifying directions of variations, and demonstrate promising properties in terms of smoothness and disentanglement.
Representation-Conditioned Diffusion Models for Guided Training Data Generation
May 26, 2026Data availability remains a critical bottleneck in many deep learning applications. Large-scale datasets are often expensive to collect, curate and annotate, which can limit the scalability and applicability of supervised learning methods. In this work, we evaluate the classification performance of models trained on synthetic image datasets produced by generative deep learning. In particular, we use latent diffusion models conditioned on learned representations from DINOv2, DINOv3, and CLIP. Our results demonstrates that this representation-conditioned formulation significantly outperforms class-conditioned generation by a large margin (+10.76 p.p. top-1 accuracy on ImageNet100), by improving sample quality and mode coverage. Furthermore, by scaling the size of the synthetic dataset, we are able to outperform a classifier trained on the real data (+2.0 p.p top-1 accuracy). We also demonstrate how generated images can be used for augmentation purposes, outperforming classical augmentation methods, and how the conditioning space can be used for sample filtering to further improve training value. Collectively, these findings highlight that representation-conditioned diffusion models provide a promising approach for augmenting, complementing, or potentially replacing real-world datasets in large-scale visual learning tasks.
Revisiting Likelihood-Based Out-of-Distribution Detection by Modeling Representations
Apr 10, 2025Out-of-distribution (OOD) detection is critical for ensuring the reliability of deep learning systems, particularly in safety-critical applications. Likelihood-based deep generative models have historically faced criticism for their unsatisfactory performance in OOD detection, often assigning higher likelihood to OOD data than in-distribution samples when applied to image data. In this work, we demonstrate that likelihood is not inherently flawed. Rather, several properties in the images space prohibit likelihood as a valid detection score. Given a sufficiently good likelihood estimator, specifically using the probability flow formulation of a diffusion model, we show that likelihood-based methods can still perform on par with state-of-the-art methods when applied in the representation space of pre-trained encoders. The code of our work can be found at $\href{https://github.com/limchaos/Likelihood-OOD.git}{\texttt{https://github.com/limchaos/Likelihood-OOD.git}}$.
FROST-BRDF: A Fast and Robust Optimal Sampling Technique for BRDF Acquisition
Jan 14, 2024



Efficient and accurate BRDF acquisition of real world materials is a challenging research problem that requires sampling millions of incident light and viewing directions. To accelerate the acquisition process, one needs to find a minimal set of sampling directions such that the recovery of the full BRDF is accurate and robust given such samples. In this paper, we formulate BRDF acquisition as a compressed sensing problem, where the sensing operator is one that performs sub-sampling of the BRDF signal according to a set of optimal sample directions. To solve this problem, we propose the Fast and Robust Optimal Sampling Technique (FROST) for designing a provably optimal sub-sampling operator that places light-view samples such that the recovery error is minimized. FROST casts the problem of designing an optimal sub-sampling operator for compressed sensing into a sparse representation formulation under the Multiple Measurement Vector (MMV) signal model. The proposed reformulation is exact, i.e. without any approximations, hence it converts an intractable combinatorial problem into one that can be solved with standard optimization techniques. As a result, FROST is accompanied by strong theoretical guarantees from the field of compressed sensing. We perform a thorough analysis of FROST-BRDF using a 10-fold cross-validation with publicly available BRDF datasets and show significant advantages compared to the state-of-the-art with respect to reconstruction quality. Finally, FROST is simple, both conceptually and in terms of implementation, it produces consistent results at each run, and it is at least two orders of magnitude faster than the prior art.
Standalone Neural ODEs with Sensitivity Analysis
Jun 08, 2022

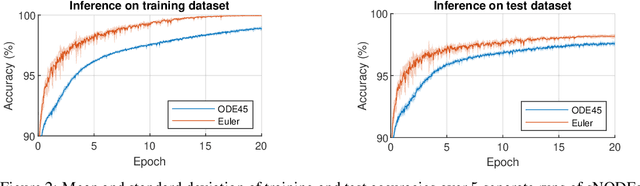
This paper presents the Standalone Neural ODE (sNODE), a continuous-depth neural ODE model capable of describing a full deep neural network. This uses a novel nonlinear conjugate gradient (NCG) descent optimization scheme for training, where the Sobolev gradient can be incorporated to improve smoothness of model weights. We also present a general formulation of the neural sensitivity problem and show how it is used in the NCG training. The sensitivity analysis provides a reliable measure of uncertainty propagation throughout a network, and can be used to study model robustness and to generate adversarial attacks. Our evaluations demonstrate that our novel formulations lead to increased robustness and performance as compared to ResNet models, and that it opens up for new opportunities for designing and developing machine learning with improved explainability.
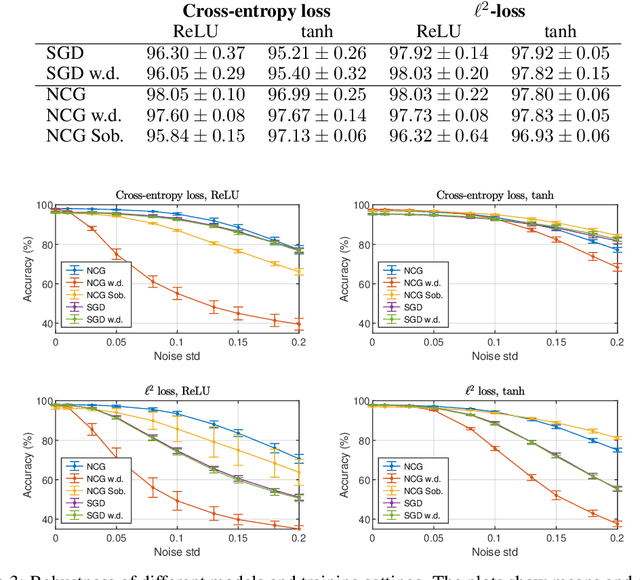
Learning via nonlinear conjugate gradients and depth-varying neural ODEs
Feb 11, 2022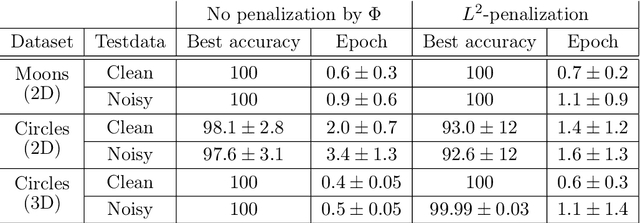
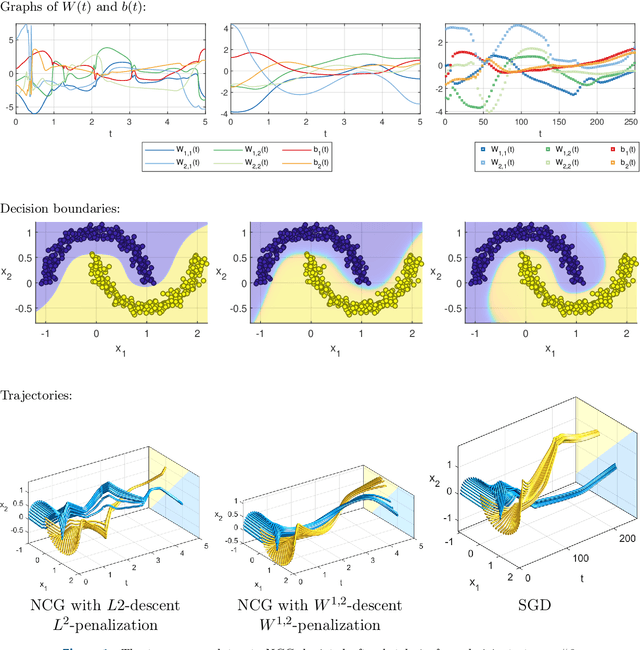
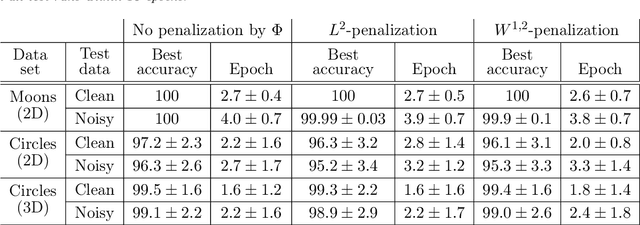
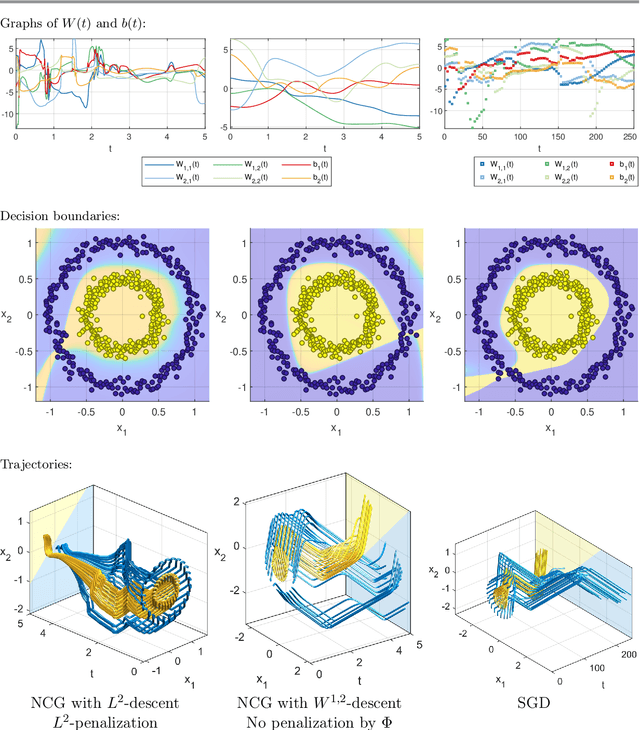
The inverse problem of supervised reconstruction of depth-variable (time-dependent) parameters in a neural ordinary differential equation (NODE) is considered, that means finding the weights of a residual network with time continuous layers. The NODE is treated as an isolated entity describing the full network as opposed to earlier research, which embedded it between pre- and post-appended layers trained by conventional methods. The proposed parameter reconstruction is done for a general first order differential equation by minimizing a cost functional covering a variety of loss functions and penalty terms. A nonlinear conjugate gradient method (NCG) is derived for the minimization. Mathematical properties are stated for the differential equation and the cost functional. The adjoint problem needed is derived together with a sensitivity problem. The sensitivity problem can estimate changes in the network output under perturbation of the trained parameters. To preserve smoothness during the iterations the Sobolev gradient is calculated and incorporated. As a proof-of-concept, numerical results are included for a NODE and two synthetic datasets, and compared with standard gradient approaches (not based on NODEs). The results show that the proposed method works well for deep learning with infinite numbers of layers, and has built-in stability and smoothness.
Learning Representations with Contrastive Self-Supervised Learning for Histopathology Applications
Dec 10, 2021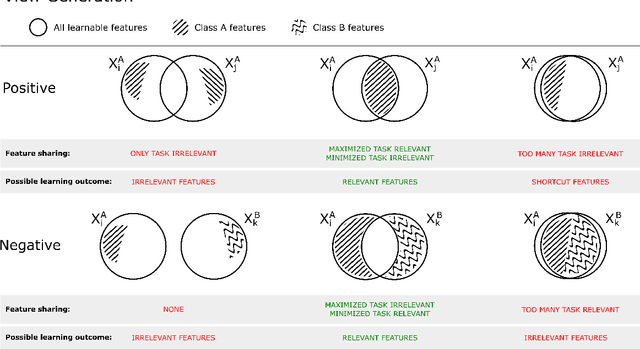
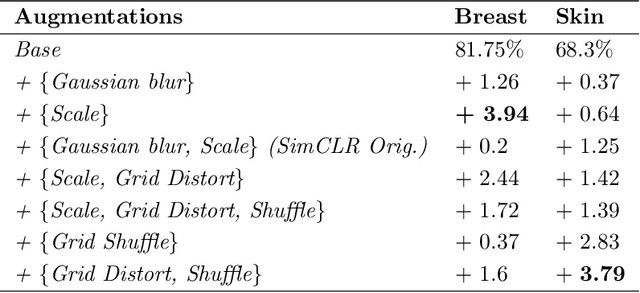
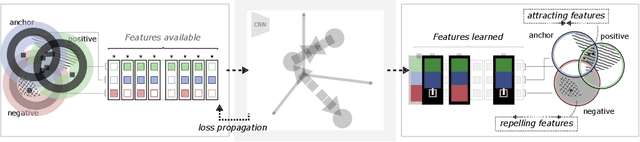
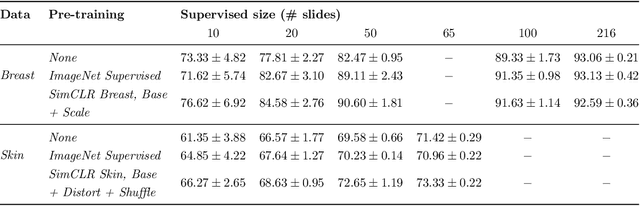
Unsupervised learning has made substantial progress over the last few years, especially by means of contrastive self-supervised learning. The dominating dataset for benchmarking self-supervised learning has been ImageNet, for which recent methods are approaching the performance achieved by fully supervised training. The ImageNet dataset is however largely object-centric, and it is not clear yet what potential those methods have on widely different datasets and tasks that are not object-centric, such as in digital pathology. While self-supervised learning has started to be explored within this area with encouraging results, there is reason to look closer at how this setting differs from natural images and ImageNet. In this paper we make an in-depth analysis of contrastive learning for histopathology, pin-pointing how the contrastive objective will behave differently due to the characteristics of histopathology data. We bring forward a number of considerations, such as view generation for the contrastive objective and hyper-parameter tuning. In a large battery of experiments, we analyze how the downstream performance in tissue classification will be affected by these considerations. The results point to how contrastive learning can reduce the annotation effort within digital pathology, but that the specific dataset characteristics need to be considered. To take full advantage of the contrastive learning objective, different calibrations of view generation and hyper-parameters are required. Our results pave the way for realizing the full potential of self-supervised learning for histopathology applications.
Primary Tumor and Inter-Organ Augmentations for Supervised Lymph Node Colon Adenocarcinoma Metastasis Detection
Sep 17, 2021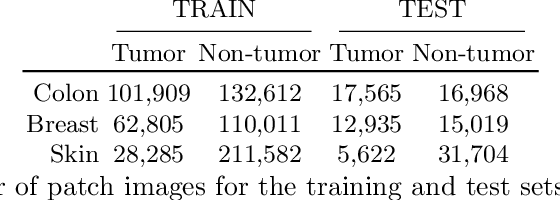
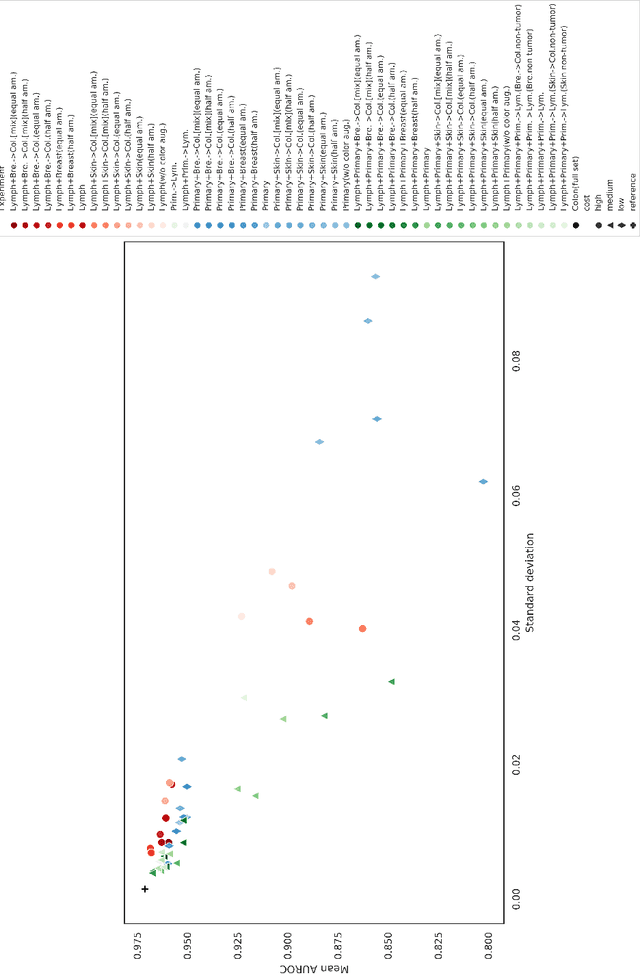
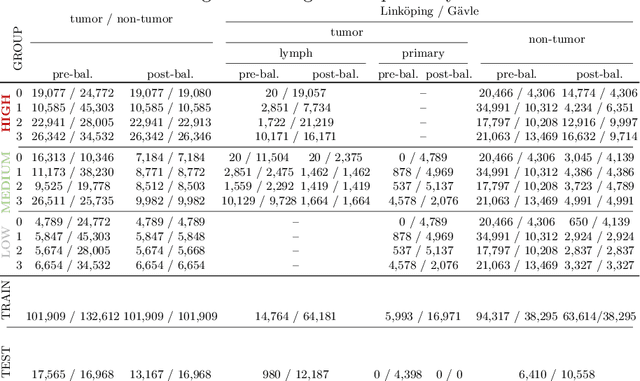
The scarcity of labeled data is a major bottleneck for developing accurate and robust deep learning-based models for histopathology applications. The problem is notably prominent for the task of metastasis detection in lymph nodes, due to the tissue's low tumor-to-non-tumor ratio, resulting in labor- and time-intensive annotation processes for the pathologists. This work explores alternatives on how to augment the training data for colon carcinoma metastasis detection when there is limited or no representation of the target domain. Through an exhaustive study of cross-validated experiments with limited training data availability, we evaluate both an inter-organ approach utilizing already available data for other tissues, and an intra-organ approach, utilizing the primary tumor. Both these approaches result in little to no extra annotation effort. Our results show that these data augmentation strategies can be an efficient way of increasing accuracy on metastasis detection, but fore-most increase robustness.
How to cheat with metrics in single-image HDR reconstruction
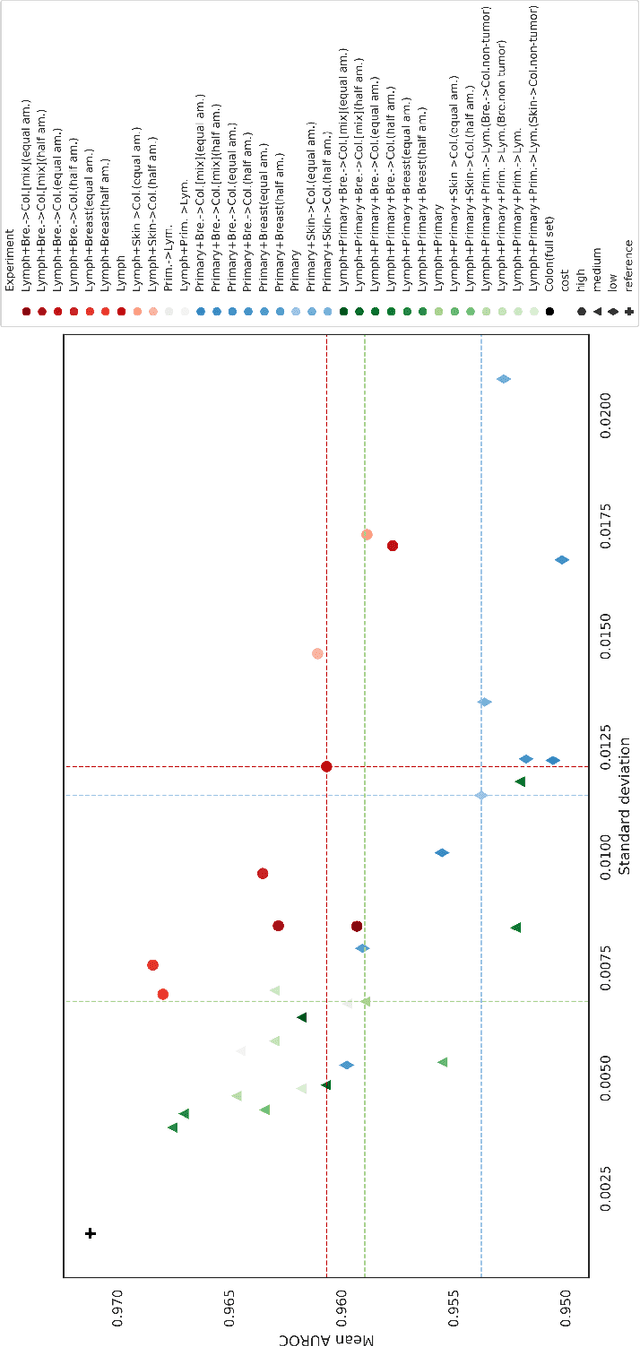
Aug 19, 2021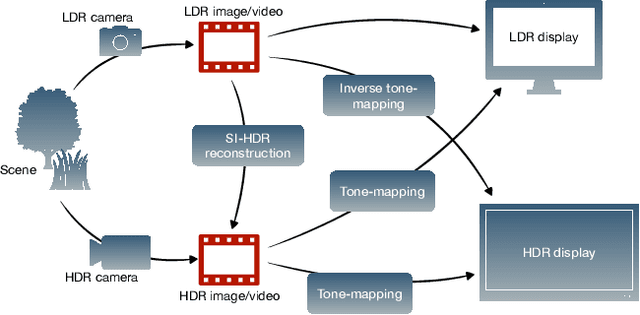
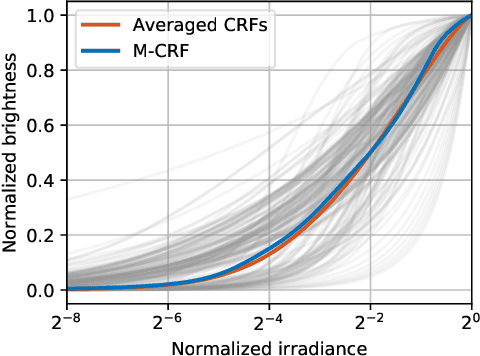
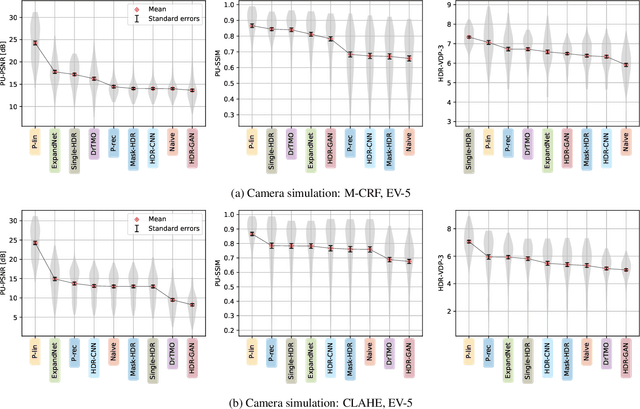
Single-image high dynamic range (SI-HDR) reconstruction has recently emerged as a problem well-suited for deep learning methods. Each successive technique demonstrates an improvement over existing methods by reporting higher image quality scores. This paper, however, highlights that such improvements in objective metrics do not necessarily translate to visually superior images. The first problem is the use of disparate evaluation conditions in terms of data and metric parameters, calling for a standardized protocol to make it possible to compare between papers. The second problem, which forms the main focus of this paper, is the inherent difficulty in evaluating SI-HDR reconstructions since certain aspects of the reconstruction problem dominate objective differences, thereby introducing a bias. Here, we reproduce a typical evaluation using existing as well as simulated SI-HDR methods to demonstrate how different aspects of the problem affect objective quality metrics. Surprisingly, we found that methods that do not even reconstruct HDR information can compete with state-of-the-art deep learning methods. We show how such results are not representative of the perceived quality and that SI-HDR reconstruction needs better evaluation protocols.