 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Co-learning: Learning from Noisy Labels with Self-supervision
Aug 30, 2021
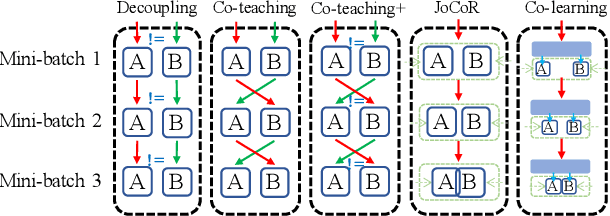

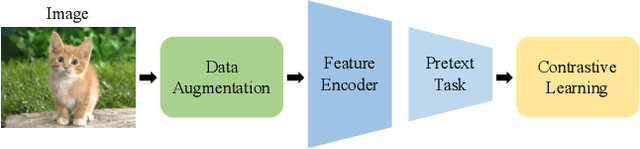

Noisy labels, resulting from mistakes in manual labeling or webly data collecting for supervised learning, can cause neural networks to overfit the misleading information and degrade the generalization performance. Self-supervised learning works in the absence of labels and thus eliminates the negative impact of noisy labels. Motivated by co-training with both supervised learning view and self-supervised learning view, we propose a simple yet effective method called Co-learning for learning with noisy labels. Co-learning performs supervised learning and self-supervised learning in a cooperative way. The constraints of intrinsic similarity with the self-supervised module and the structural similarity with the noisily-supervised module are imposed on a shared common feature encoder to regularize the network to maximize the agreement between the two constraints. Co-learning is compared with peer methods on corrupted data from benchmark datasets fairly, and extensive results are provided which demonstrate that Co-learning is superior to many state-of-the-art approaches.
Sketches for Time-Dependent Machine Learning
Aug 26, 2021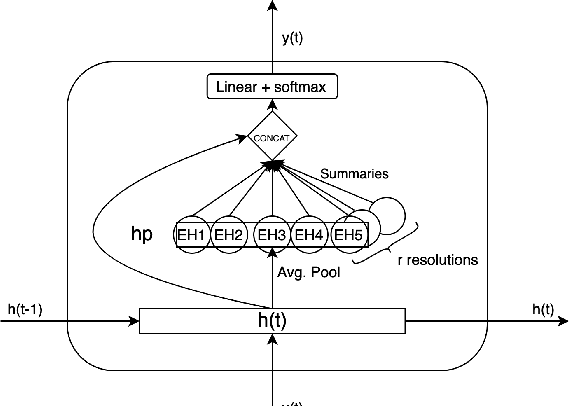
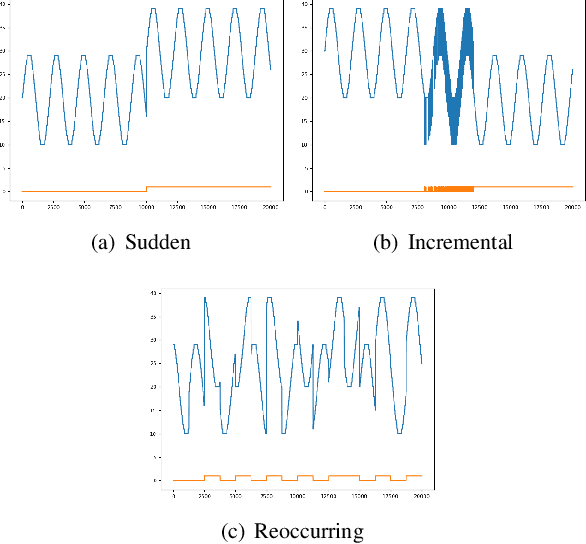
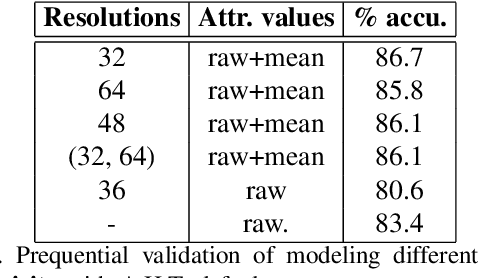
Time series data can be subject to changes in the underlying process that generates them and, because of these changes, models built on old samples can become obsolete or perform poorly. In this work, we present a way to incorporate information about the current data distribution and its evolution across time into machine learning algorithms. Our solution is based on efficiently maintaining statistics, particularly the mean and the variance, of data features at different time resolutions. These data summarisations can be performed over the input attributes, in which case they can then be fed into the model as additional input features, or over latent representations learned by models, such as those of Recurrent Neural Networks. In classification tasks, the proposed techniques can significantly outperform the prediction capabilities of equivalent architectures with no feature / latent summarisations. Furthermore, these modifications do not introduce notable computational and memory overhead when properly adjusted.
REGINA - Reasoning Graph Convolutional Networks in Human Action Recognition
May 14, 2021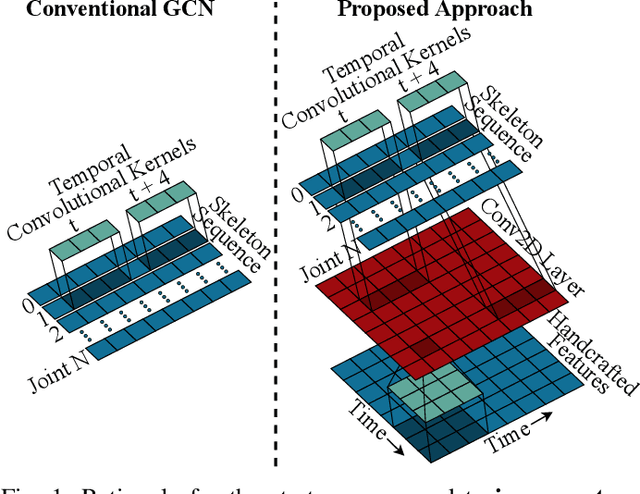
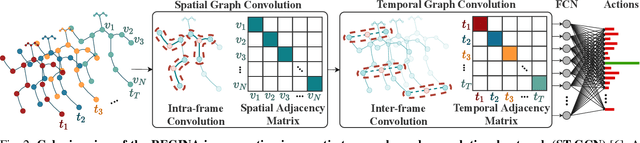
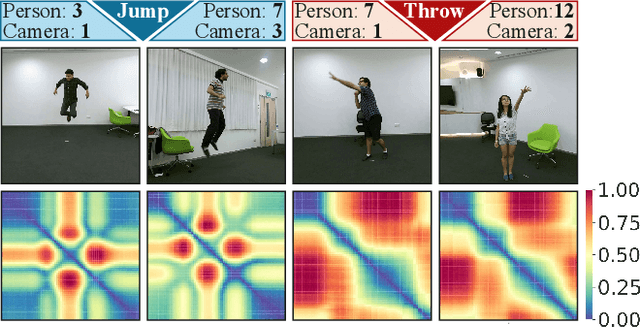
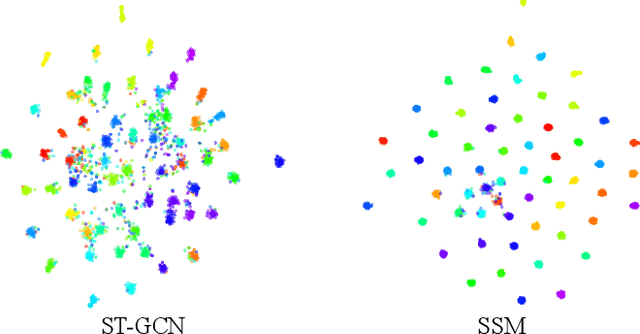
It is known that the kinematics of the human body skeleton reveals valuable information in action recognition. Recently, modeling skeletons as spatio-temporal graphs with Graph Convolutional Networks (GCNs) has been reported to solidly advance the state-of-the-art performance. However, GCN-based approaches exclusively learn from raw skeleton data, and are expected to extract the inherent structural information on their own. This paper describes REGINA, introducing a novel way to REasoning Graph convolutional networks IN Human Action recognition. The rationale is to provide to the GCNs additional knowledge about the skeleton data, obtained by handcrafted features, in order to facilitate the learning process, while guaranteeing that it remains fully trainable in an end-to-end manner. The challenge is to capture complementary information over the dynamics between consecutive frames, which is the key information extracted by state-of-the-art GCN techniques. Moreover, the proposed strategy can be easily integrated in the existing GCN-based methods, which we also regard positively. Our experiments were carried out in well known action recognition datasets and enabled to conclude that REGINA contributes for solid improvements in performance when incorporated to other GCN-based approaches, without any other adjustment regarding the original method. For reproducibility, the REGINA code and all the experiments carried out will be publicly available at https://github.com/DegardinBruno.
Graph Attention Networks with Positional Embeddings
May 29, 2021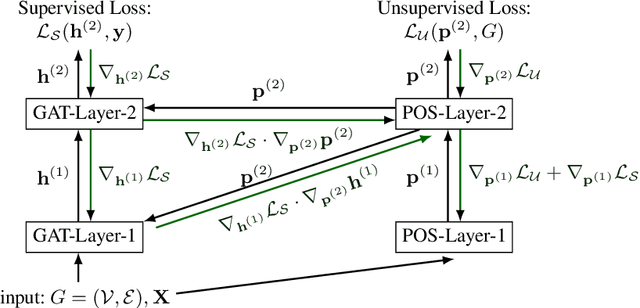
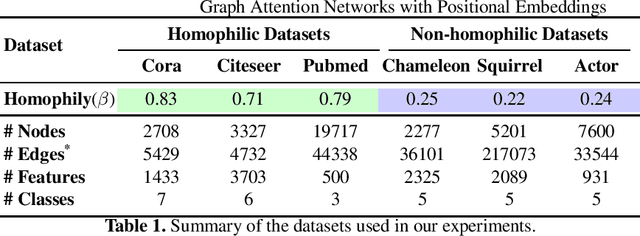
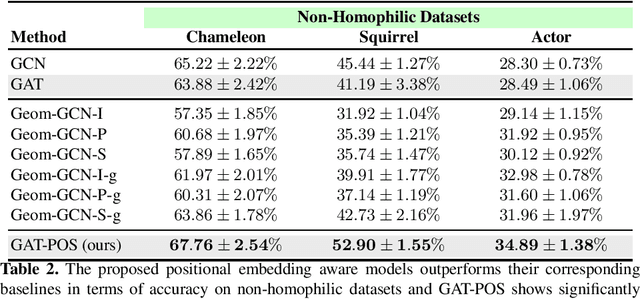
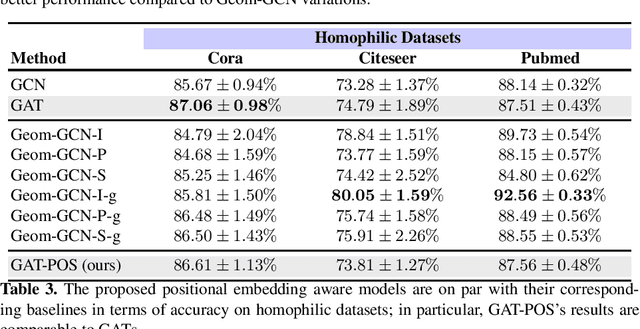
Graph Neural Networks (GNNs) are deep learning methods which provide the current state of the art performance in node classification tasks. GNNs often assume homophily -- neighboring nodes having similar features and labels--, and therefore may not be at their full potential when dealing with non-homophilic graphs. In this work, we focus on addressing this limitation and enable Graph Attention Networks (GAT), a commonly used variant of GNNs, to explore the structural information within each graph locality. Inspired by the positional encoding in the Transformers, we propose a framework, termed Graph Attentional Networks with Positional Embeddings (GAT-POS), to enhance GATs with positional embeddings which capture structural and positional information of the nodes in the graph. In this framework, the positional embeddings are learned by a model predictive of the graph context, plugged into an enhanced GAT architecture, which is able to leverage both the positional and content information of each node. The model is trained jointly to optimize for the task of node classification as well as the task of predicting graph context. Experimental results show that GAT-POS reaches remarkable improvement compared to strong GNN baselines and recent structural embedding enhanced GNNs on non-homophilic graphs.
Exact Learning of Qualitative Constraint Networks from Membership Queries
Sep 23, 2021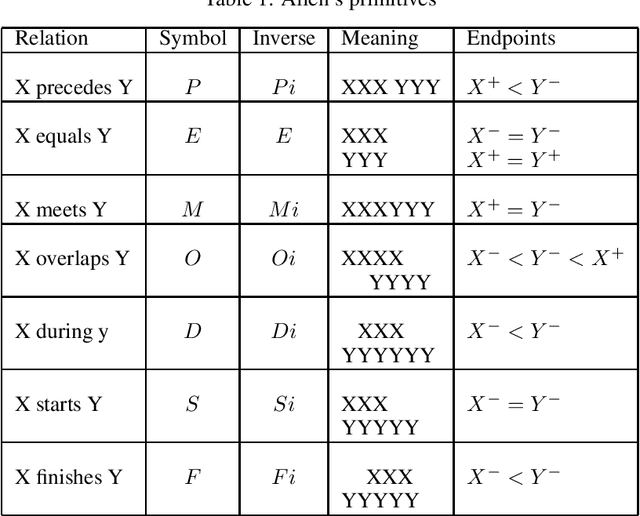
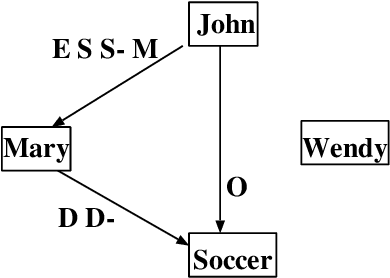
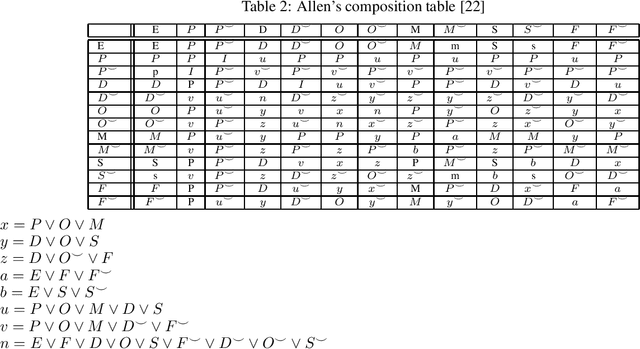
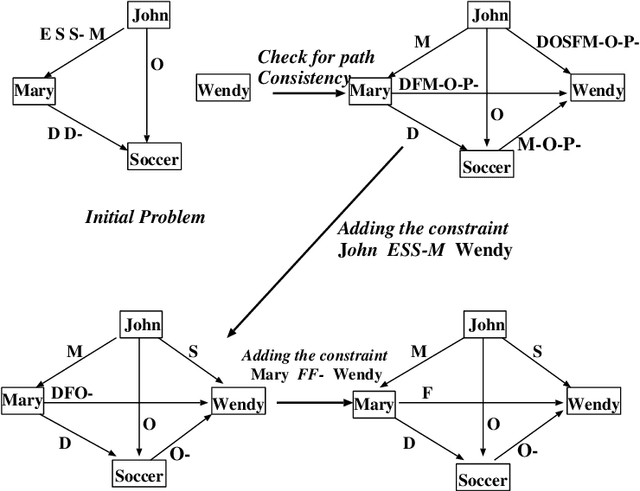
A Qualitative Constraint Network (QCN) is a constraint graph for representing problems under qualitative temporal and spatial relations, among others. More formally, a QCN includes a set of entities, and a list of qualitative constraints defining the possible scenarios between these entities. These latter constraints are expressed as disjunctions of binary relations capturing the (incomplete) knowledge between the involved entities. QCNs are very effective in representing a wide variety of real-world applications, including scheduling and planning, configuration and Geographic Information Systems (GIS). It is however challenging to elicit, from the user, the QCN representing a given problem. To overcome this difficulty in practice, we propose a new algorithm for learning, through membership queries, a QCN from a non expert. In this paper, membership queries are asked in order to elicit temporal or spatial relationships between pairs of temporal or spatial entities. In order to improve the time performance of our learning algorithm in practice, constraint propagation, through transitive closure, as well as ordering heuristics, are enforced. The goal here is to reduce the number of membership queries needed to reach the target QCN. In order to assess the practical effect of constraint propagation and ordering heuristics, we conducted several experiments on randomly generated temporal and spatial constraint network instances. The results of the experiments are very encouraging and promising.
Adversarially Regularized Graph Attention Networks for Inductive Learning on Partially Labeled Graphs
Jun 07, 2021
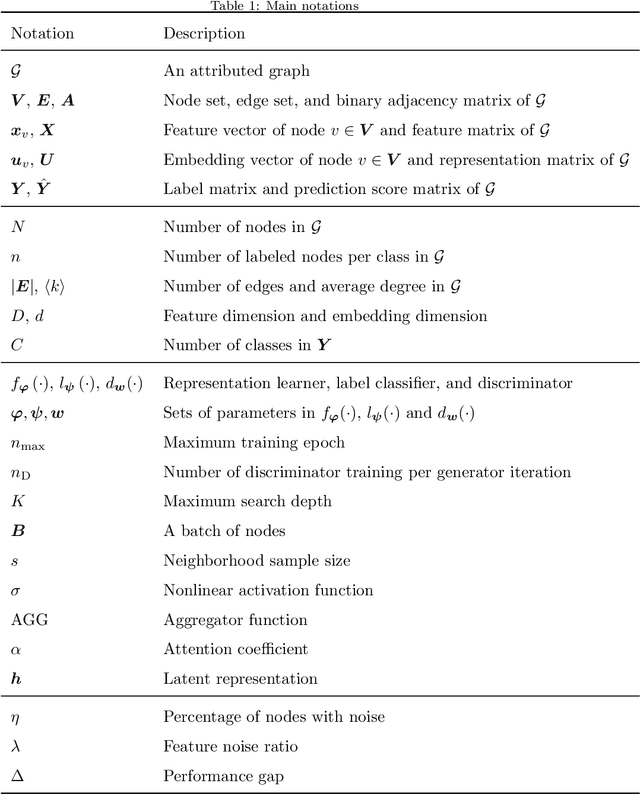
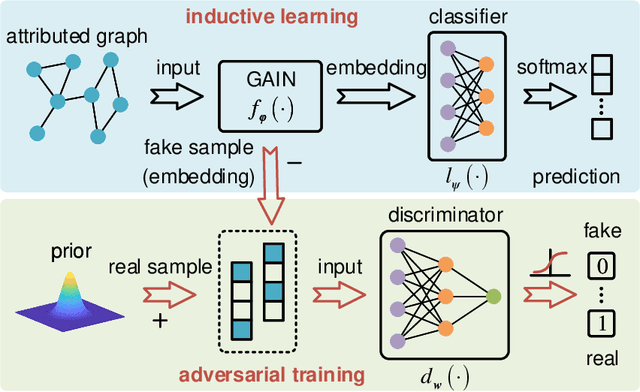
Graph embedding is a general approach to tackling graph-analytic problems by encoding nodes into low-dimensional representations. Most existing embedding methods are transductive since the information of all nodes is required in training, including those to be predicted. In this paper, we propose a novel inductive embedding method for semi-supervised learning on graphs. This method generates node representations by learning a parametric function to aggregate information from the neighborhood using an attention mechanism, and hence naturally generalizes to previously unseen nodes. Furthermore, adversarial training serves as an external regularization enforcing the learned representations to match a prior distribution for improving robustness and generalization ability. Experiments on real-world clean or noisy graphs are used to demonstrate the effectiveness of this approach.
Learning Generative Deception Strategies in Combinatorial Masking Games
Sep 23, 2021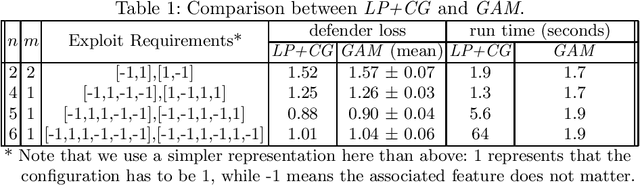
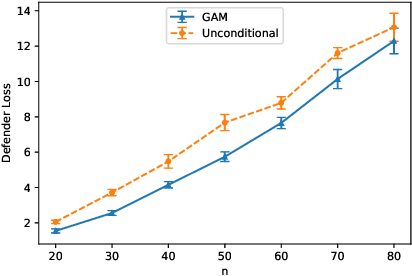
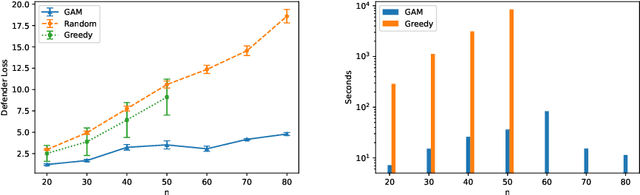
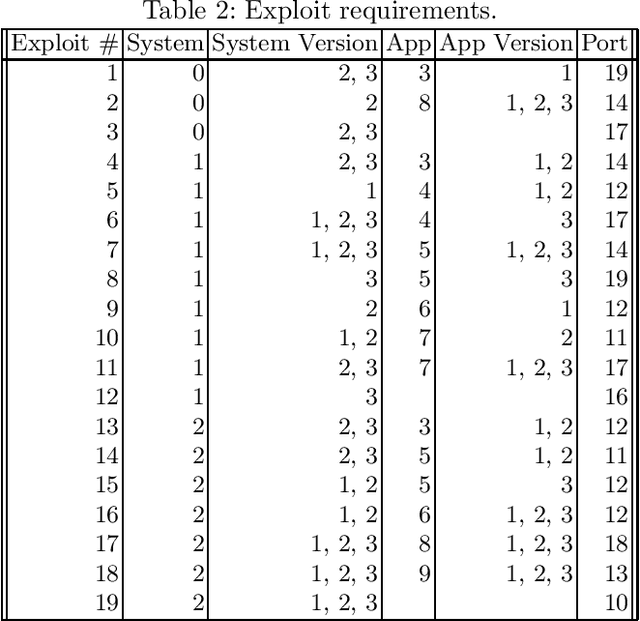
Deception is a crucial tool in the cyberdefence repertoire, enabling defenders to leverage their informational advantage to reduce the likelihood of successful attacks. One way deception can be employed is through obscuring, or masking, some of the information about how systems are configured, increasing attacker's uncertainty about their targets. We present a novel game-theoretic model of the resulting defender-attacker interaction, where the defender chooses a subset of attributes to mask, while the attacker responds by choosing an exploit to execute. The strategies of both players have combinatorial structure with complex informational dependencies, and therefore even representing these strategies is not trivial. First, we show that the problem of computing an equilibrium of the resulting zero-sum defender-attacker game can be represented as a linear program with a combinatorial number of system configuration variables and constraints, and develop a constraint generation approach for solving this problem. Next, we present a novel highly scalable approach for approximately solving such games by representing the strategies of both players as neural networks. The key idea is to represent the defender's mixed strategy using a deep neural network generator, and then using alternating gradient-descent-ascent algorithm, analogous to the training of Generative Adversarial Networks. Our experiments, as well as a case study, demonstrate the efficacy of the proposed approach.
Shatter: An Efficient Transformer Encoder with Single-Headed Self-Attention and Relative Sequence Partitioning
Aug 30, 2021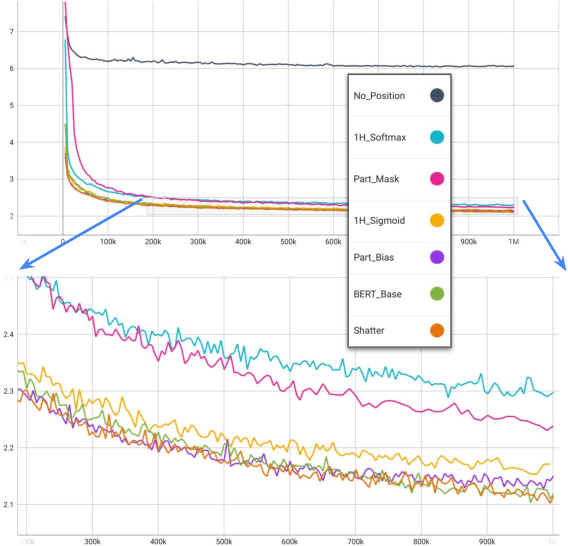
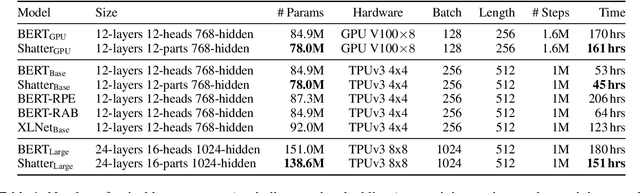

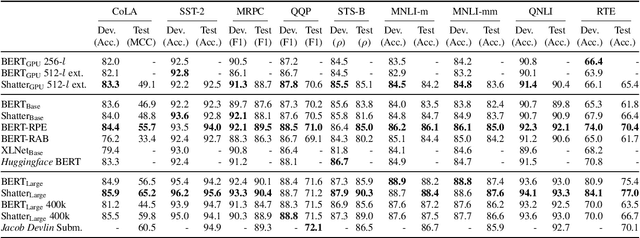
The highly popular Transformer architecture, based on self-attention, is the foundation of large pretrained models such as BERT, that have become an enduring paradigm in NLP. While powerful, the computational resources and time required to pretrain such models can be prohibitive. In this work, we present an alternative self-attention architecture, Shatter, that more efficiently encodes sequence information by softly partitioning the space of relative positions and applying different value matrices to different parts of the sequence. This mechanism further allows us to simplify the multi-headed attention in Transformer to single-headed. We conduct extensive experiments showing that Shatter achieves better performance than BERT, with pretraining being faster per step (15% on TPU), converging in fewer steps, and offering considerable memory savings (>50%). Put together, Shatter can be pretrained on 8 V100 GPUs in 7 days, and match the performance of BERT_Base -- making the cost of pretraining much more affordable.
Time-Frequency Localization Using Deep Convolutional Maxout Neural Network in Persian Speech Recognition
Aug 09, 2021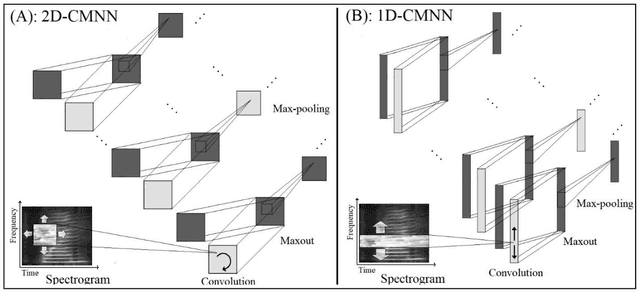
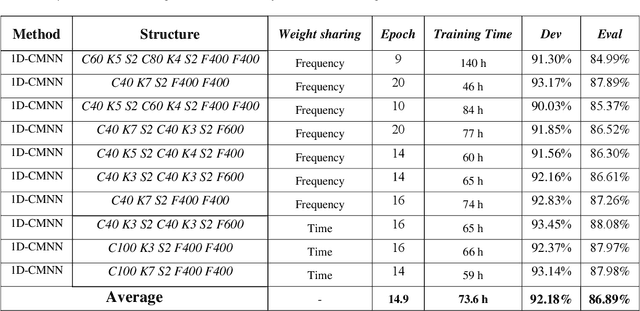
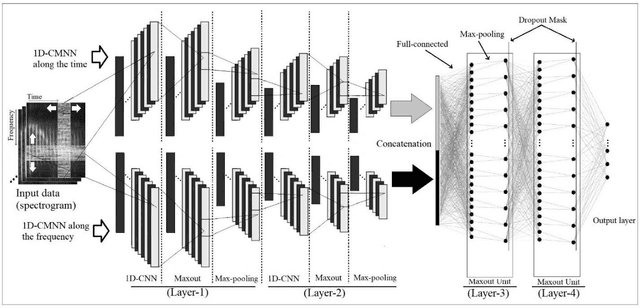
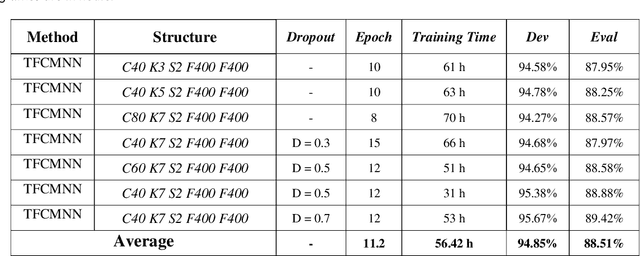
In this paper, a CNN-based structure for time-frequency localization of audio signal information in the ASR acoustic model is proposed for Persian speech recognition. Research has shown that the receptive fields' time-frequency flexibility in some mammals' auditory neurons system improves recognition performance. Biosystems have inspired many artificial systems because of their high efficiency and performance, so time-frequency localization has been used extensively to improve system performance. In the last few years, much work has been done to localize time-frequency information in ASR systems, which has used the spatial immutability properties of methods such as TDNN, CNN and LSTM-RNN. However, most of these models have large parameter volumes and are challenging to train. In the structure we have designed, called Time-Frequency Convolutional Maxout Neural Network (TFCMNN), two parallel blocks consisting of 1D-CMNN each have weight sharing in one dimension, are applied simultaneously but independently to the feature vectors. Then their output is concatenated and applied to a fully connected Maxout network for classification. To improve the performance of this structure, we have used newly developed methods and models such as the maxout, Dropout, and weight normalization. Two experimental sets were designed and implemented on the Persian FARSDAT speech data set to evaluate the performance of this model compared to conventional 1D-CMNN models. According to the experimental results, the average recognition score of TFCMNN models is about 1.6% higher than the average of conventional models. In addition, the average training time of the TFCMNN models is about 17 hours lower than the average training time of traditional models. As a result, as mentioned in other references, time-frequency localization in ASR systems increases system accuracy and speeds up the model training process.
An Improved Hybrid Recommender System: Integrating Document Context-Based and Behavior-Based Methods
Sep 12, 2021
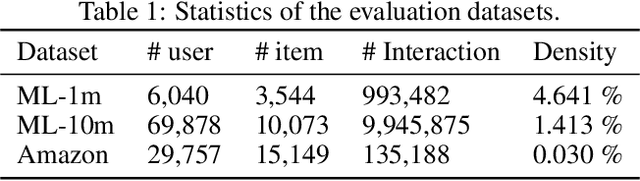
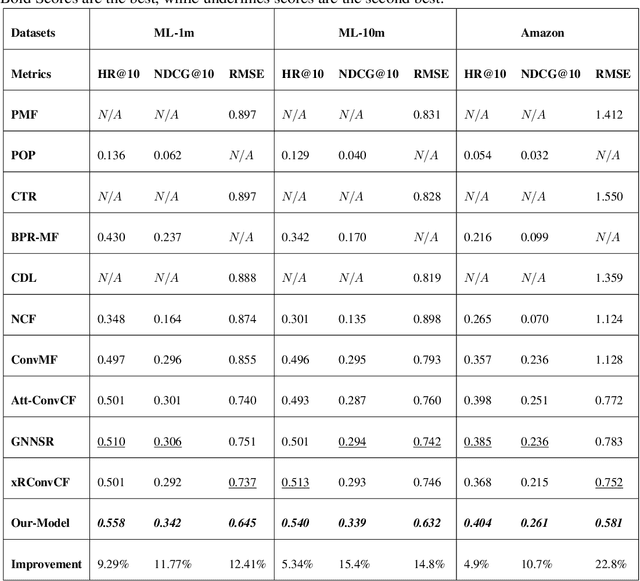
One of the main challenges in recommender systems is data sparsity which leads to high variance. Several attempts have been made to improve the bias-variance trade-off using auxiliary information. In particular, document modeling-based methods have improved the model's accuracy by using textual data such as reviews, abstracts, and storylines when the user-to-item rating matrix is sparse. However, such models are insufficient to learn optimal representation for users and items. User-based and item-based collaborative filtering, owing to their efficiency and interpretability, have been long used for building recommender systems. They create a profile for each user and item respectively as their historically interacted items and the users who interacted with the target item. This work combines these two approaches with document context-aware recommender systems by considering users' opinions on these items. Another advantage of our model is that it supports online personalization. If a user has new interactions, it needs to refresh the user and item history representation vectors instead of updating model parameters. The proposed algorithm is implemented and tested on three real-world datasets that demonstrate our model's effectiveness over the baseline methods.