 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepair-R1: Better Test Before Repair
Jul 30, 2025APR (Automated Program Repair) aims to automatically locate program defects, generate patches and validate the repairs. Existing techniques for APR are often combined with LLMs (Large Language Models), which leverages the code-related knowledge of LLMs to improve repair effectiveness. Current LLM-based APR methods typically utilize test cases only during the inference stage, adopting an iterative approach that performs repair first and validates it through test execution afterward. This conventional paradigm neglects two important aspects: the potential contribution of test cases in the training phase, and the possibility of leveraging testing prior to repair. To address this, we propose Repair-R1, which introduces test cases into the model's training phase and shifts test generation to precede repair. The model is required to first generate discriminative test cases that can distinguish defective behaviors, and then perform repair based on these tests. This enables the model to better locate defects and understand the underlying causes of defects, thereby improving repair effectiveness. We implement Repair-R1 with three different backbone models, using RL (reinforcement learning) to co-optimize test generation and bug repair. Experimental results on four widely adopted benchmarks demonstrate the superiority of Repair-R1. Specially, compared to vanilla models, Repair-R1 improves repair success rate by 2.68\% to 48.29\%, test generation success rate by 16.38\% to 53.28\%, and test coverage by 0.78\% to 53.96\%. We publish the code and weights at https://github.com/Tomsawyerhu/APR-RL and https://huggingface.co/tomhu/Qwen3-4B-RL-5000-step.
Semi-supervised Domain Adaptation on Graphs with Contrastive Learning and Minimax Entropy
Sep 14, 2023



Label scarcity in a graph is frequently encountered in real-world applications due to the high cost of data labeling. To this end, semi-supervised domain adaptation (SSDA) on graphs aims to leverage the knowledge of a labeled source graph to aid in node classification on a target graph with limited labels. SSDA tasks need to overcome the domain gap between the source and target graphs. However, to date, this challenging research problem has yet to be formally considered by the existing approaches designed for cross-graph node classification. To tackle the SSDA problem on graphs, a novel method called SemiGCL is proposed, which benefits from graph contrastive learning and minimax entropy training. SemiGCL generates informative node representations by contrasting the representations learned from a graph's local and global views. Additionally, SemiGCL is adversarially optimized with the entropy loss of unlabeled target nodes to reduce domain divergence. Experimental results on benchmark datasets demonstrate that SemiGCL outperforms the state-of-the-art baselines on the SSDA tasks.
Adversarially Regularized Graph Attention Networks for Inductive Learning on Partially Labeled Graphs
Jun 07, 2021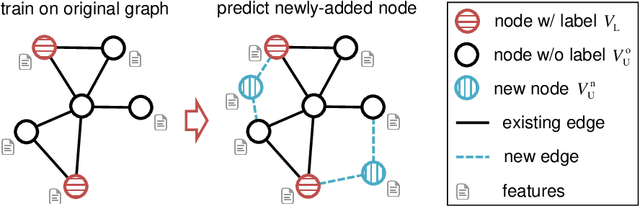
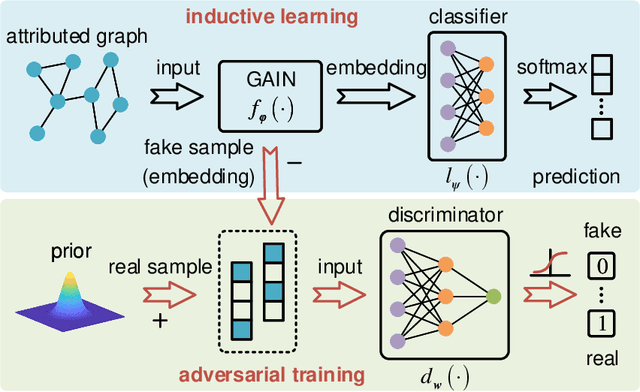
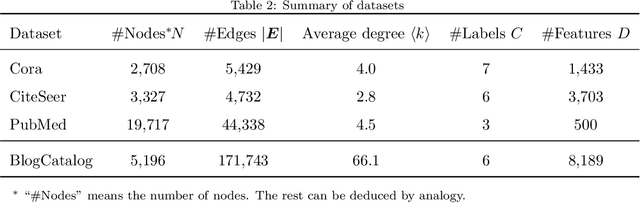
Graph embedding is a general approach to tackling graph-analytic problems by encoding nodes into low-dimensional representations. Most existing embedding methods are transductive since the information of all nodes is required in training, including those to be predicted. In this paper, we propose a novel inductive embedding method for semi-supervised learning on graphs. This method generates node representations by learning a parametric function to aggregate information from the neighborhood using an attention mechanism, and hence naturally generalizes to previously unseen nodes. Furthermore, adversarial training serves as an external regularization enforcing the learned representations to match a prior distribution for improving robustness and generalization ability. Experiments on real-world clean or noisy graphs are used to demonstrate the effectiveness of this approach.