 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Shape-Biased Domain Generalization via Shock Graph Embeddings
Sep 13, 2021

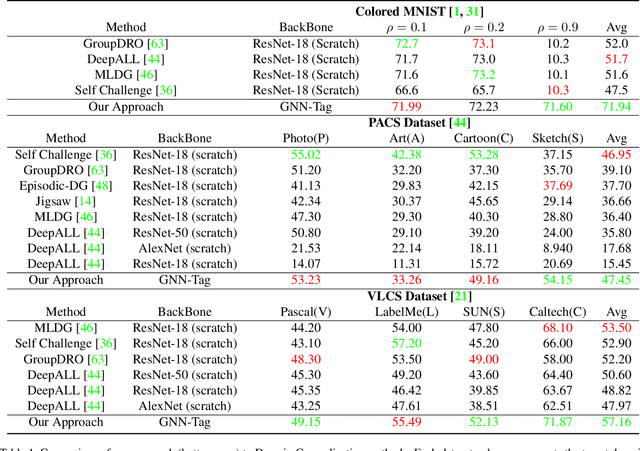

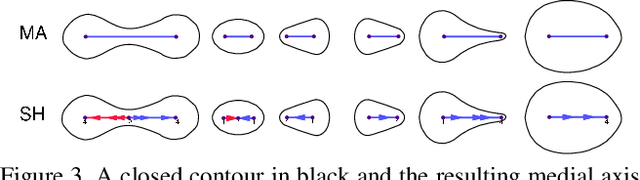
There is an emerging sense that the vulnerability of Image Convolutional Neural Networks (CNN), i.e., sensitivity to image corruptions, perturbations, and adversarial attacks, is connected with Texture Bias. This relative lack of Shape Bias is also responsible for poor performance in Domain Generalization (DG). The inclusion of a role of shape alleviates these vulnerabilities and some approaches have achieved this by training on negative images, images endowed with edge maps, or images with conflicting shape and texture information. This paper advocates an explicit and complete representation of shape using a classical computer vision approach, namely, representing the shape content of an image with the shock graph of its contour map. The resulting graph and its descriptor is a complete representation of contour content and is classified using recent Graph Neural Network (GNN) methods. The experimental results on three domain shift datasets, Colored MNIST, PACS, and VLCS demonstrate that even without using appearance the shape-based approach exceeds classical Image CNN based methods in domain generalization.
LegoFormer: Transformers for Block-by-Block Multi-view 3D Reconstruction
Jun 23, 2021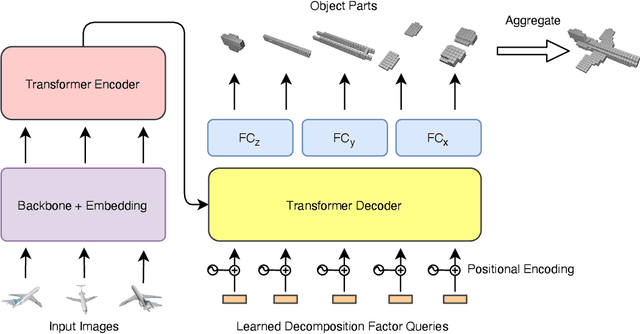
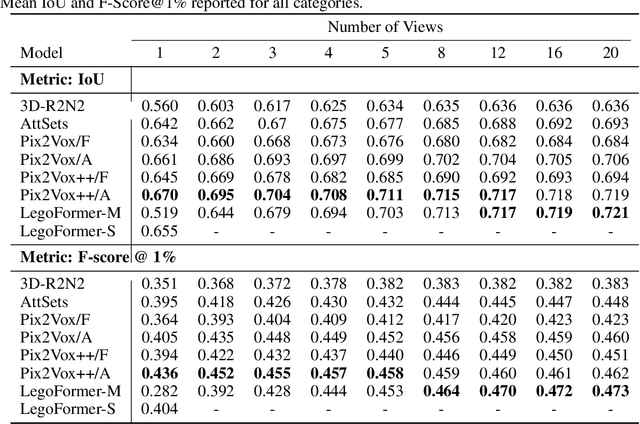
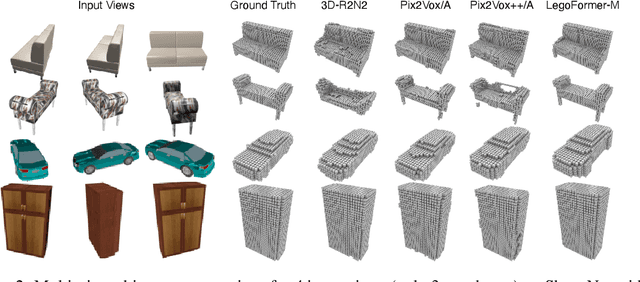
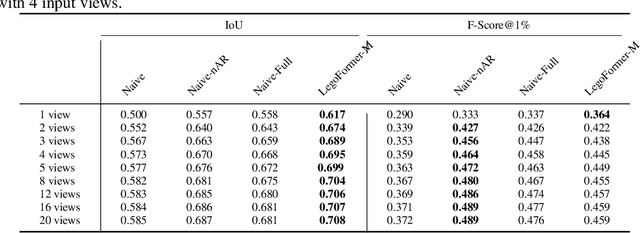
Most modern deep learning-based multi-view 3D reconstruction techniques use RNNs or fusion modules to combine information from multiple images after encoding them. These two separate steps have loose connections and do not consider all available information while encoding each view. We propose LegoFormer, a transformer-based model that unifies object reconstruction under a single framework and parametrizes the reconstructed occupancy grid by its decomposition factors. This reformulation allows the prediction of an object as a set of independent structures then aggregated to obtain the final reconstruction. Experiments conducted on ShapeNet display the competitive performance of our network with respect to the state-of-the-art methods. We also demonstrate how the use of self-attention leads to increased interpretability of the model output.
Generalized Translation and Scale Invariant Online Algorithm for Adversarial Multi-Armed Bandits
Sep 19, 2021We study the adversarial multi-armed bandit problem and create a completely online algorithmic framework that is invariant under arbitrary translations and scales of the arm losses. We study the expected performance of our algorithm against a generic competition class, which makes it applicable for a wide variety of problem scenarios. Our algorithm works from a universal prediction perspective and the performance measure used is the expected regret against arbitrary arm selection sequences, which is the difference between our losses and a competing loss sequence. The competition class can be designed to include fixed arm selections, switching bandits, contextual bandits, or any other competition of interest. The sequences in the competition class are generally determined by the specific application at hand and should be designed accordingly. Our algorithm neither uses nor needs any preliminary information about the loss sequences and is completely online. Its performance bounds are the second order bounds in terms of sum of the squared losses, where any affine transform of the losses has no effect on the normalized regret.
Multi-stage Pre-training over Simplified Multimodal Pre-training Models
Jul 22, 2021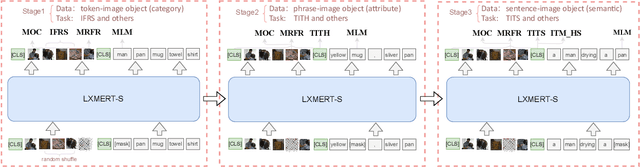
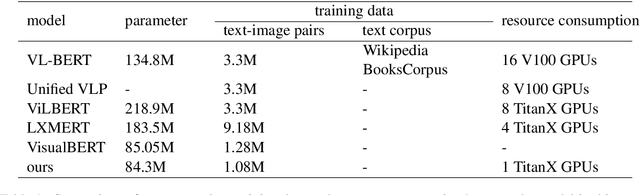
Multimodal pre-training models, such as LXMERT, have achieved excellent results in downstream tasks. However, current pre-trained models require large amounts of training data and have huge model sizes, which make them difficult to apply in low-resource situations. How to obtain similar or even better performance than a larger model under the premise of less pre-training data and smaller model size has become an important problem. In this paper, we propose a new Multi-stage Pre-training (MSP) method, which uses information at different granularities from word, phrase to sentence in both texts and images to pre-train the model in stages. We also design several different pre-training tasks suitable for the information granularity in different stage in order to efficiently capture the diverse knowledge from a limited corpus. We take a Simplified LXMERT (LXMERT- S), which has only 45.9% parameters of the original LXMERT model and 11.76% of the original pre-training data as the testbed of our MSP method. Experimental results show that our method achieves comparable performance to the original LXMERT model in all downstream tasks, and even outperforms the original model in Image-Text Retrieval task.
Exploiting Motion Information from Unlabeled Videos for Static Image Action Recognition
Dec 01, 2019
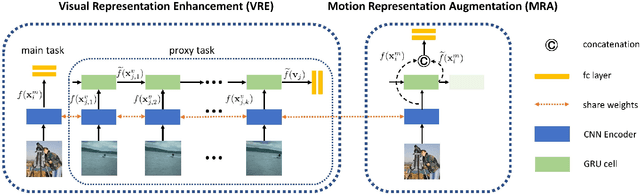
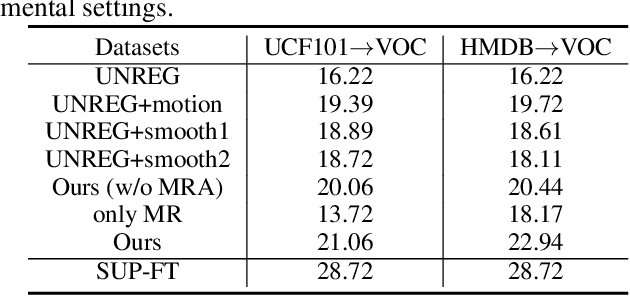
Static image action recognition, which aims to recognize action based on a single image, usually relies on expensive human labeling effort such as adequate labeled action images and large-scale labeled image dataset. In contrast, abundant unlabeled videos can be economically obtained. Therefore, several works have explored using unlabeled videos to facilitate image action recognition, which can be categorized into the following two groups: (a) enhance visual representations of action images with a designed proxy task on unlabeled videos, which falls into the scope of self-supervised learning; (b) generate auxiliary representations for action images with the generator learned from unlabeled videos. In this paper, we integrate the above two strategies in a unified framework, which consists of Visual Representation Enhancement (VRE) module and Motion Representation Augmentation (MRA) module. Specifically, the VRE module includes a proxy task which imposes pseudo motion label constraint and temporal coherence constraint on unlabeled videos, while the MRA module could predict the motion information of a static action image by exploiting unlabeled videos. We demonstrate the superiority of our framework based on four benchmark human action datasets with limited labeled data.
Differential Music: Automated Music Generation Using LSTM Networks with Representation Based on Melodic and Harmonic Intervals
Aug 23, 2021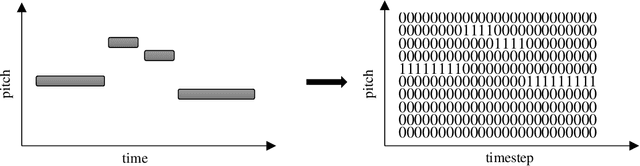

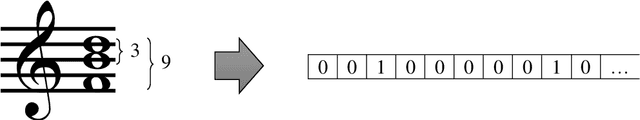
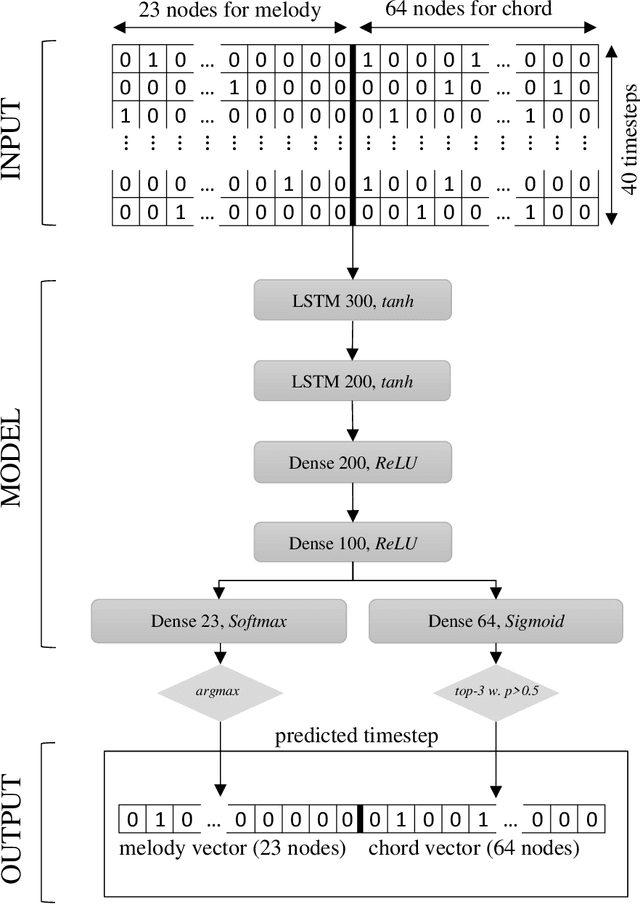
This paper presents a generative AI model for automated music composition with LSTM networks that takes a novel approach at encoding musical information which is based on movement in music rather than absolute pitch. Melodies are encoded as a series of intervals rather than a series of pitches, and chords are encoded as the set of intervals that each chord note makes with the melody at each timestep. Experimental results show promise as they sound musical and tonal. There are also weaknesses to this method, mainly excessive modulations in the compositions, but that is expected from the nature of the encoding. This issue is discussed later in the paper and is a potential topic for future work.
TENGraD: Time-Efficient Natural Gradient Descent with Exact Fisher-Block Inversion
Jun 07, 2021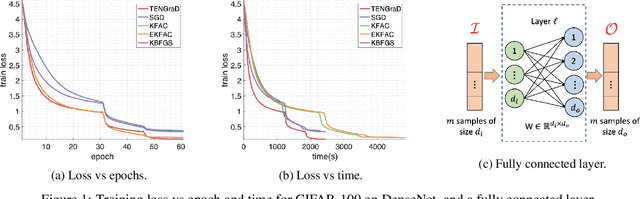

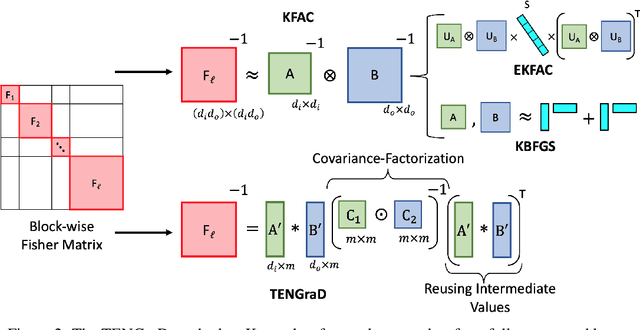
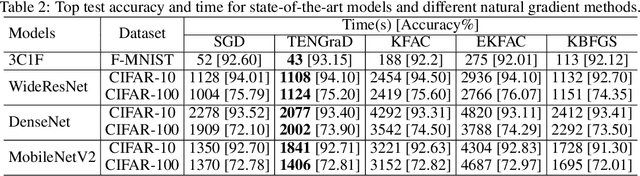
This work proposes a time-efficient Natural Gradient Descent method, called TENGraD, with linear convergence guarantees. Computing the inverse of the neural network's Fisher information matrix is expensive in NGD because the Fisher matrix is large. Approximate NGD methods such as KFAC attempt to improve NGD's running time and practical application by reducing the Fisher matrix inversion cost with approximation. However, the approximations do not reduce the overall time significantly and lead to less accurate parameter updates and loss of curvature information. TENGraD improves the time efficiency of NGD by computing Fisher block inverses with a computationally efficient covariance factorization and reuse method. It computes the inverse of each block exactly using the Woodbury matrix identity to preserve curvature information while admitting (linear) fast convergence rates. Our experiments on image classification tasks for state-of-the-art deep neural architecture on CIFAR-10, CIFAR-100, and Fashion-MNIST show that TENGraD significantly outperforms state-of-the-art NGD methods and often stochastic gradient descent in wall-clock time.
Leveraging Multiple Online Sources for Accurate Income Verification
Jun 19, 2021
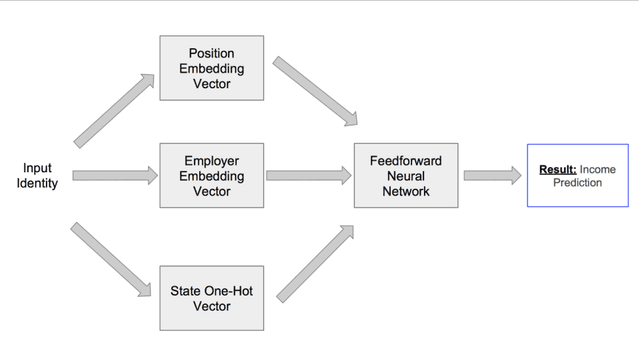
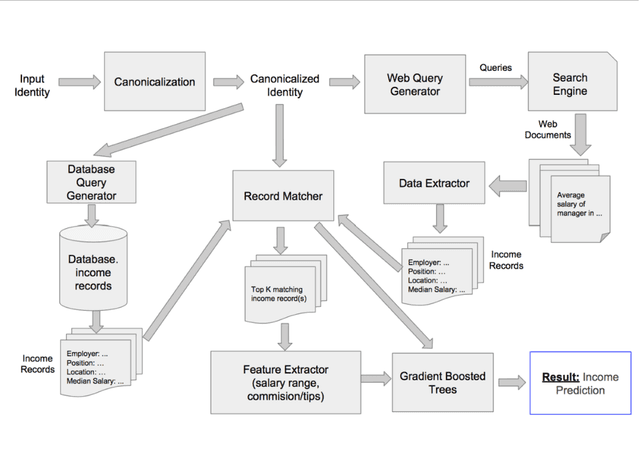
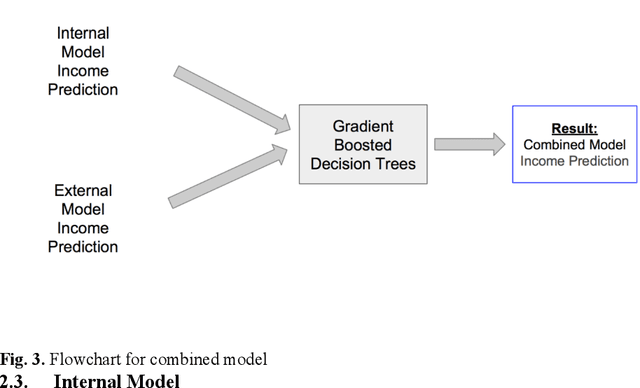
Income verification is the problem of validating a person's stated income given basic identity information such as name, location, job title and employer. It is widely used in the context of mortgage lending, rental applications and other financial risk models. However, the current processes surrounding verification involve significant human effort and document gathering which can be both time-consuming and expensive. In this paper, we propose a novel model for verifying an individual's income given very limited identity information typically available in loan applications. Our model is a combination of a deep neural network and hand-engineered features. The hand engineered features are based upon matching the input information against income records extracted automatically from various publicly available online sources (e.g. payscale.com, H-1B filings, government employee salaries). We conduct experiments on two data sets, one simulated from H-1B records and the other from a real-world data set of peer-to-peer (P2P) loan applications obtained from one of the world's largest P2P lending platform. Our results show a significant reduction in error of 3-6% relative to several strong baselines. We also perform ablation studies to demonstrate that a combined model is indeed necessary to achieve state-of-the-art performance on this task.
A First-Occupancy Representation for Reinforcement Learning
Oct 06, 2021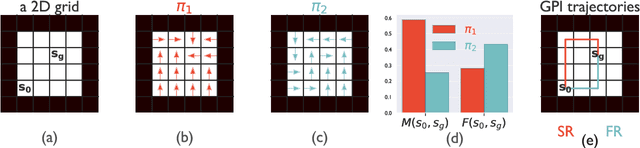
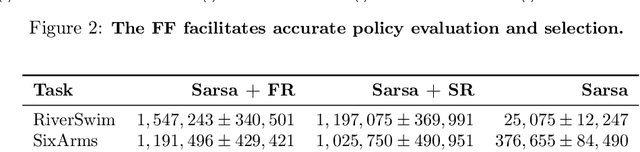
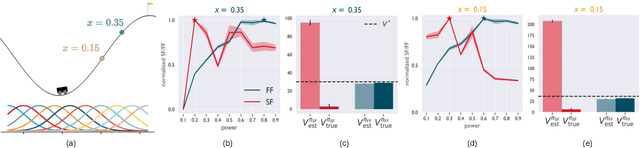
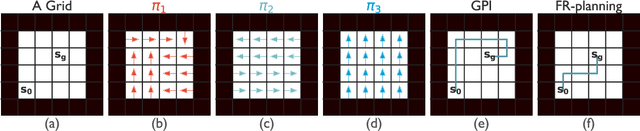
Both animals and artificial agents benefit from state representations that support rapid transfer of learning across tasks and which enable them to efficiently traverse their environments to reach rewarding states. The successor representation (SR), which measures the expected cumulative, discounted state occupancy under a fixed policy, enables efficient transfer to different reward structures in an otherwise constant Markovian environment and has been hypothesized to underlie aspects of biological behavior and neural activity. However, in the real world, rewards may move or only be available for consumption once, may shift location, or agents may simply aim to reach goal states as rapidly as possible without the constraint of artificially imposed task horizons. In such cases, the most behaviorally-relevant representation would carry information about when the agent was likely to first reach states of interest, rather than how often it should expect to visit them over a potentially infinite time span. To reflect such demands, we introduce the first-occupancy representation (FR), which measures the expected temporal discount to the first time a state is accessed. We demonstrate that the FR facilitates exploration, the selection of efficient paths to desired states, allows the agent, under certain conditions, to plan provably optimal trajectories defined by a sequence of subgoals, and induces similar behavior to animals avoiding threatening stimuli.
Energy and Age Pareto Optimal Trajectories in UAV-assisted Wireless Data Collection
Jun 07, 2021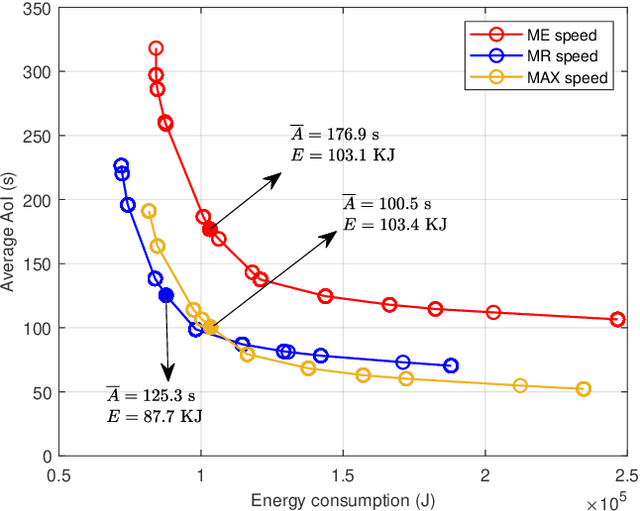
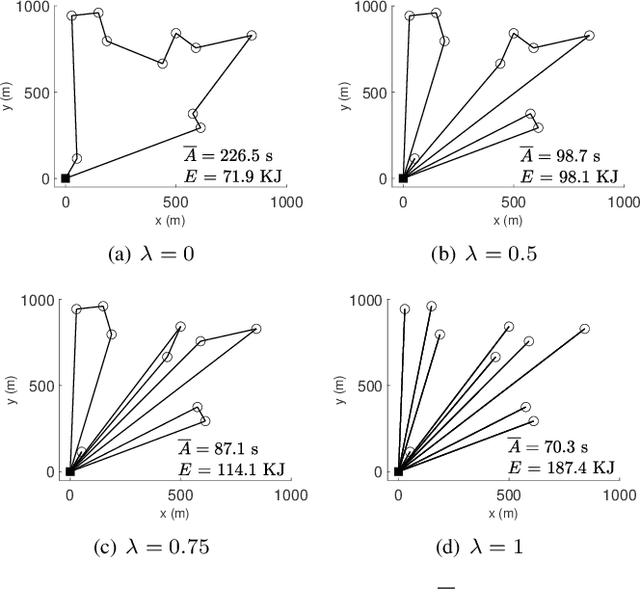
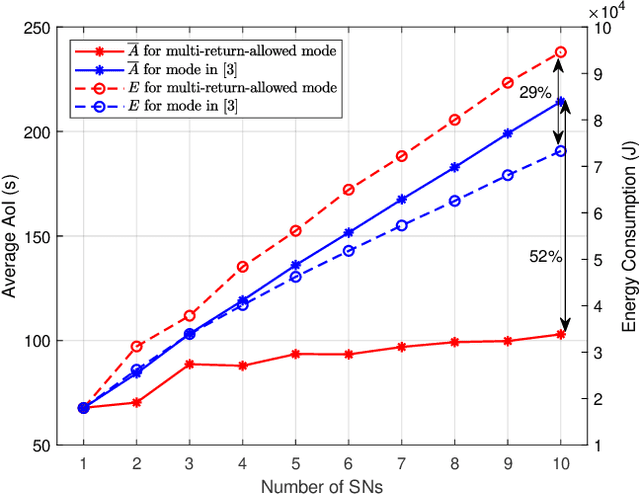

This paper studies an unmanned aerial vehicle (UAV)-assisted wireless network, where a UAV is dispatched to gather information from ground sensor nodes (SN) and transfer the collected data to the depot. The information freshness is captured by the age of information (AoI) metric, whilst the energy consumption of the UAV is seen as another performance criterion. Most importantly, the AoI and energy efficiency are inherently competing metrics, since decreasing the AoI requires the UAV returning to the depot more frequently, leading to a higher energy consumption. To this end, we design UAV paths that optimize these two competing metrics and reveal the Pareto frontier. To formulate this problem, a multi-objective mixed integer linear programming (MILP) is proposed with a flow-based constraint set and we apply Bender's decomposition on the proposed formulation. The overall outcome shows that the proposed method allows deriving non-dominated solutions for decision making for UAV based wireless data collection. Numerical results are provided to corroborate our study by presenting the Pareto front of the two objectives and the effect on the UAV trajectory.