 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX-Agents
Jan 20, 2026We introduce the AI Productivity Index for Agents (APEX-Agents), a benchmark for assessing whether AI agents can execute long-horizon, cross-application tasks created by investment banking analysts, management consultants, and corporate lawyers. APEX-Agents requires agents to navigate realistic work environments with files and tools. We test eight agents for the leaderboard using Pass@1. Gemini 3 Flash (Thinking=High) achieves the highest score of 24.0%, followed by GPT-5.2 (Thinking=High), Claude Opus 4.5 (Thinking=High), and Gemini 3 Pro (Thinking=High). We open source the APEX-Agents benchmark (n=480) with all prompts, rubrics, gold outputs, files, and metadata. We also open-source Archipelago, our infrastructure for agent execution and evaluation.
APEX-SWE
Jan 13, 2026We introduce the AI Productivity Index for Software Engineering (APEX-SWE), a benchmark for assessing whether frontier AI models can execute economically valuable software engineering work. Unlike existing evaluations that focus on narrow, well-defined tasks, APEX-SWE assesses two novel task types that reflect real-world software engineering work: (1) Integration tasks (n=100), which require constructing end-to-end systems across heterogeneous cloud primitives, business applications, and infrastructure-as-code services, and (2) Observability tasks (n=100), which require debugging production failures using telemetry signals such as logs and dashboards, as well as unstructured context. We evaluated eight frontier models on APEX-SWE. Gemini 3 Pro (Thinking = High) performs best, with a Pass@1 score of 25\%. Our analysis shows that strong performance is primarily driven by epistemic reasoning, defined as the ability to distinguish between assumptions and verified facts, combined with agency to resolve uncertainty prior to acting. We open-source the APEX-SWE evaluation harness and a dev set (n=50).
Leveraging Multiple Online Sources for Accurate Income Verification
Jun 19, 2021
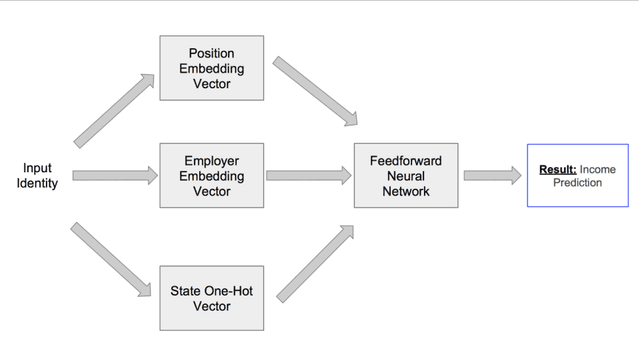
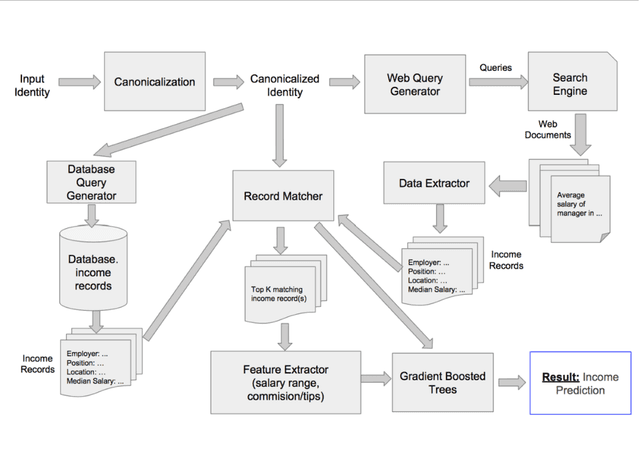
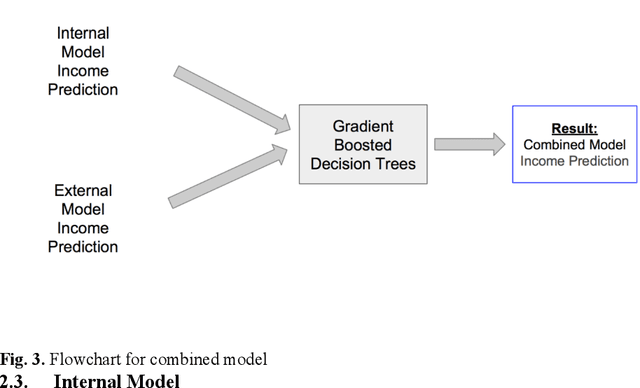
Income verification is the problem of validating a person's stated income given basic identity information such as name, location, job title and employer. It is widely used in the context of mortgage lending, rental applications and other financial risk models. However, the current processes surrounding verification involve significant human effort and document gathering which can be both time-consuming and expensive. In this paper, we propose a novel model for verifying an individual's income given very limited identity information typically available in loan applications. Our model is a combination of a deep neural network and hand-engineered features. The hand engineered features are based upon matching the input information against income records extracted automatically from various publicly available online sources (e.g. payscale.com, H-1B filings, government employee salaries). We conduct experiments on two data sets, one simulated from H-1B records and the other from a real-world data set of peer-to-peer (P2P) loan applications obtained from one of the world's largest P2P lending platform. Our results show a significant reduction in error of 3-6% relative to several strong baselines. We also perform ablation studies to demonstrate that a combined model is indeed necessary to achieve state-of-the-art performance on this task.