 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Cold-Start Gap: LLM-Powered Synthetic Data Generation for Natural Language Search at Airbnb
May 20, 2026Deploying natural language search systems presents a critical cold-start challenge: no real user queries to learn linguistic patterns, and no relevance labels to train ranking models. We present a framework for generating synthetic queries and labels using large language models (LLMs), powering model training and evaluation for Airbnb's natural language search. For query generation, we combine contrastive listing pairs from booking sessions with seed queries from user research to balance realism and diversity, enabling a cold-to-warm start transition as real user data becomes available. For label generation, we introduce contrastive generation that produces topicality labels by construction, and Virtual Judge (VJ) labeling for broader coverage. We compare our approach against a no-seed contrastive baseline and an InPars-style baseline. For query length, the InPars baseline produces verbose queries with KL divergence of 12.03 vs. real users; our seed-guided approach achieves 0.66, a 7.5x improvement. For attribute type distributions, our approach achieves the lowest KL divergence (0.04), outperforming even seed queries (0.09). Experiments show our approach produces harder evaluation examples than the no-seed baseline (79% vs. 97% pairwise accuracy), providing discriminative signal for model improvement. We deploy production pipelines generating synthetic examples daily for embedding-based retrieval and ranking evaluation.
Recommending Search Filters To Improve Conversions At Airbnb
Feb 27, 2026Airbnb, a two-sided online marketplace connecting guests and hosts, offers a diverse and unique inventory of accommodations, experiences, and services. Search filters play an important role in helping guests navigate this variety by refining search results to align with their needs. Yet, while search filters are designed to facilitate conversions in online marketplaces, their direct impact on driving conversions remains underexplored in the existing literature. This paper bridges this gap by presenting a novel application of machine learning techniques to recommend search filters aimed at improving booking conversions. We introduce a modeling framework that directly targets lower-funnel conversions (bookings) by recommending intermediate tools, i.e. search filters. Leveraging the framework, we designed and built the filter recommendation system at Airbnb from the ground up, addressing challenges like cold start and stringent serving requirements. The filter recommendation system we developed has been successfully deployed at Airbnb, powering multiple user interfaces and driving incremental booking conversion lifts, as validated through online A/B testing. An ablation study further validates the effectiveness of our approach and key design choices. By focusing on conversion-oriented filter recommendations, our work ensures that search filters serve their ultimate purpose at Airbnb - helping guests find and book their ideal accommodations.
High Precision Audience Expansion via Extreme Classification in a Two-Sided Marketplace
Feb 16, 2026Airbnb search must balance a worldwide, highly varied supply of homes with guests whose location, amenity, style, and price expectations differ widely. Meeting those expectations hinges on an efficient retrieval stage that surfaces only the listings a guest might realistically book, before resource intensive ranking models are applied to determine the best results. Unlike many recommendation engines, our system faces a distinctive challenge, location retrieval, that sits upstream of ranking and determines which geographic areas are queried in order to filter inventory to a candidate set. The preexisting approach employs a deep bayesian bandit based system to predict a rectangular retrieval bounds area that can be used for filtering. The purpose of this paper is to demonstrate the methodology, challenges, and impact of rearchitecting search to retrieve from the subset of most bookable high precision rectangular map cells defined by dividing the world into 25M uniform cells.
Learning to Rank for Maps at Airbnb
Jun 25, 2024



As a two-sided marketplace, Airbnb brings together hosts who own listings for rent with prospective guests from around the globe. Results from a guest's search for listings are displayed primarily through two interfaces: (1) as a list of rectangular cards that contain on them the listing image, price, rating, and other details, referred to as list-results (2) as oval pins on a map showing the listing price, called map-results. Both these interfaces, since their inception, have used the same ranking algorithm that orders listings by their booking probabilities and selects the top listings for display. But some of the basic assumptions underlying ranking, built for a world where search results are presented as lists, simply break down for maps. This paper describes how we rebuilt ranking for maps by revising the mathematical foundations of how users interact with search results. Our iterative and experiment-driven approach led us through a path full of twists and turns, ending in a unified theory for the two interfaces. Our journey shows how assumptions taken for granted when designing machine learning algorithms may not apply equally across all user interfaces, and how they can be adapted. The net impact was one of the largest improvements in user experience for Airbnb which we discuss as a series of experimental validations.
Leveraging Multiple Online Sources for Accurate Income Verification
Jun 19, 2021
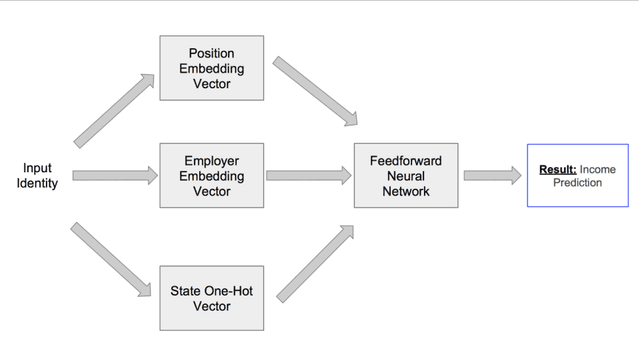
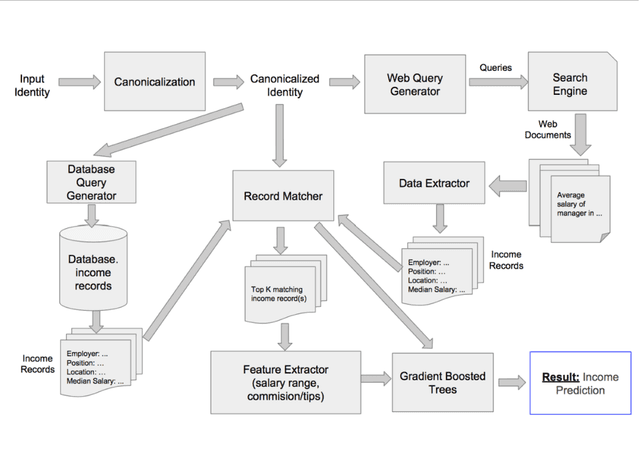
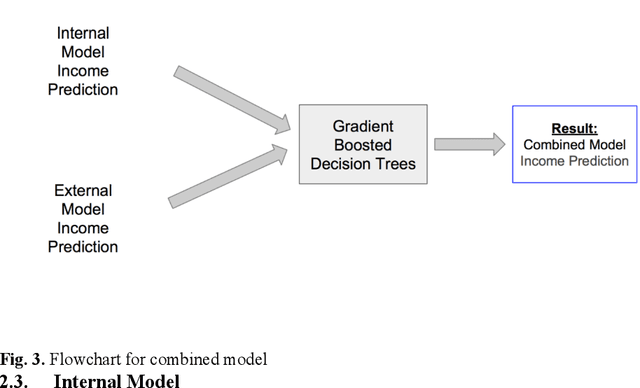
Income verification is the problem of validating a person's stated income given basic identity information such as name, location, job title and employer. It is widely used in the context of mortgage lending, rental applications and other financial risk models. However, the current processes surrounding verification involve significant human effort and document gathering which can be both time-consuming and expensive. In this paper, we propose a novel model for verifying an individual's income given very limited identity information typically available in loan applications. Our model is a combination of a deep neural network and hand-engineered features. The hand engineered features are based upon matching the input information against income records extracted automatically from various publicly available online sources (e.g. payscale.com, H-1B filings, government employee salaries). We conduct experiments on two data sets, one simulated from H-1B records and the other from a real-world data set of peer-to-peer (P2P) loan applications obtained from one of the world's largest P2P lending platform. Our results show a significant reduction in error of 3-6% relative to several strong baselines. We also perform ablation studies to demonstrate that a combined model is indeed necessary to achieve state-of-the-art performance on this task.
A Conditional Random Field for Discriminatively-trained Finite-state String Edit Distance
Jul 04, 2012



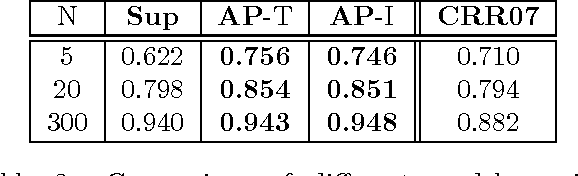
The need to measure sequence similarity arises in information extraction, object identity, data mining, biological sequence analysis, and other domains. This paper presents discriminative string-edit CRFs, a finitestate conditional random field model for edit sequences between strings. Conditional random fields have advantages over generative approaches to this problem, such as pair HMMs or the work of Ristad and Yianilos, because as conditionally-trained methods, they enable the use of complex, arbitrary actions and features of the input strings. As in generative models, the training data does not have to specify the edit sequences between the given string pairs. Unlike generative models, however, our model is trained on both positive and negative instances of string pairs. We present positive experimental results on several data sets.
Alternating Projections for Learning with Expectation Constraints
May 09, 2012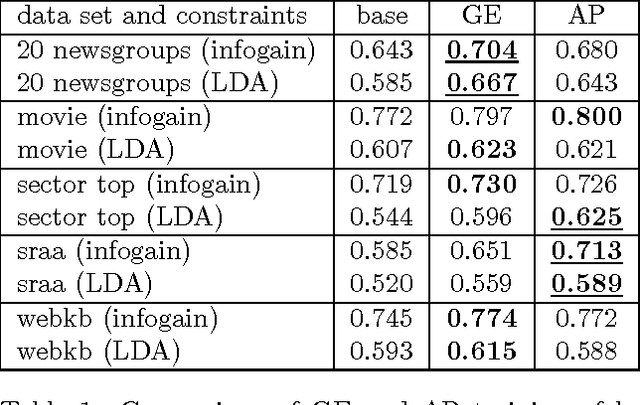

We present an objective function for learning with unlabeled data that utilizes auxiliary expectation constraints. We optimize this objective function using a procedure that alternates between information and moment projections. Our method provides an alternate interpretation of the posterior regularization framework (Graca et al., 2008), maintains uncertainty during optimization unlike constraint-driven learning (Chang et al., 2007), and is more efficient than generalized expectation criteria (Mann & McCallum, 2008). Applications of this framework include minimally supervised learning, semisupervised learning, and learning with constraints that are more expressive than the underlying model. In experiments, we demonstrate comparable accuracy to generalized expectation criteria for minimally supervised learning, and use expressive structural constraints to guide semi-supervised learning, providing a 3%-6% improvement over stateof-the-art constraint-driven learning.