 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
2D Multi-Class Model for Gray and White Matter Segmentation of the Cervical Spinal Cord at 7T
Oct 13, 2021
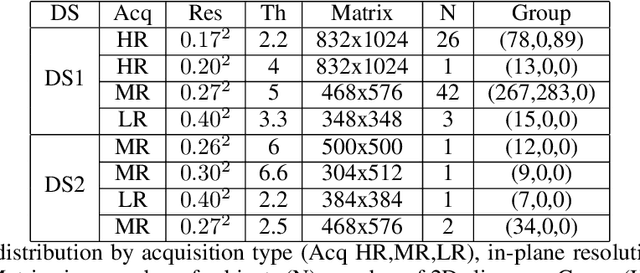
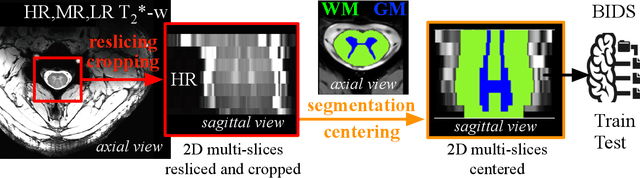
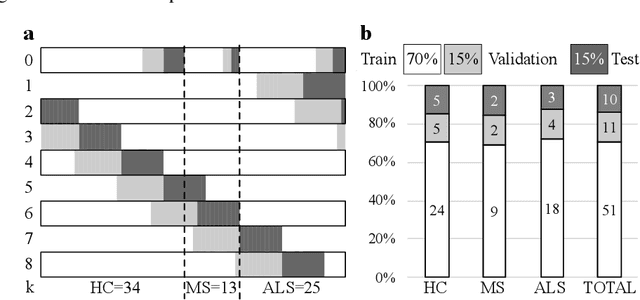
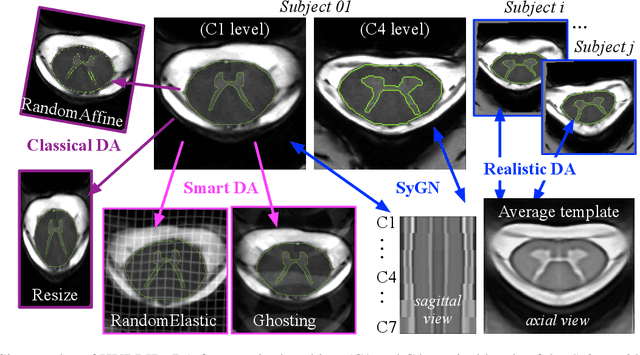
The spinal cord (SC), which conveys information between the brain and the peripheral nervous system, plays a key role in various neurological disorders such as multiple sclerosis (MS) and amyotrophic lateral sclerosis (ALS), in which both gray matter (GM) and white matter (WM) may be impaired. While automated methods for WM/GM segmentation are now largely available, these techniques, developed for conventional systems (3T or lower) do not necessarily perform well on 7T MRI data, which feature finer details, contrasts, but also different artifacts or signal dropout. The primary goal of this study is thus to propose a new deep learning model that allows robust SC/GM multi-class segmentation based on ultra-high resolution 7T T2*-w MR images. The second objective is to highlight the relevance of implementing a specific data augmentation (DA) strategy, in particular to generate a generic model that could be used for multi-center studies at 7T.
Approaching the Limit of Image Rescaling via Flow Guidance
Nov 09, 2021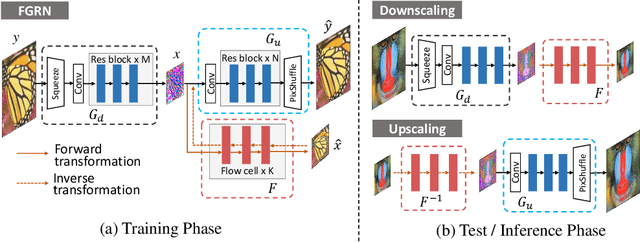
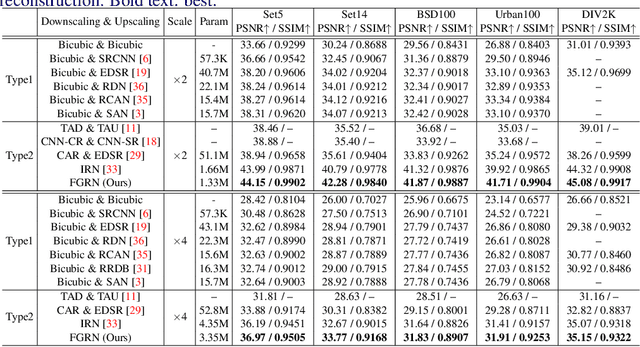
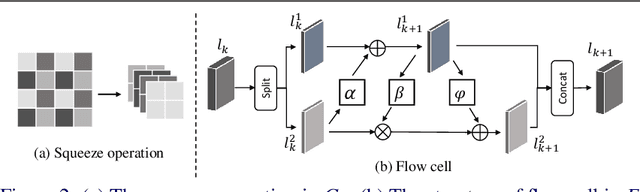
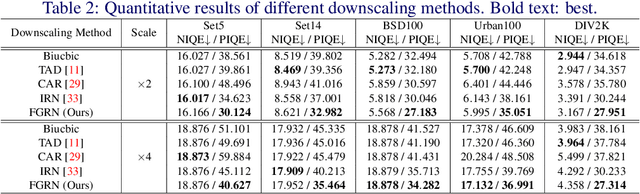
Image downscaling and upscaling are two basic rescaling operations. Once the image is downscaled, it is difficult to be reconstructed via upscaling due to the loss of information. To make these two processes more compatible and improve the reconstruction performance, some efforts model them as a joint encoding-decoding task, with the constraint that the downscaled (i.e. encoded) low-resolution (LR) image must preserve the original visual appearance. To implement this constraint, most methods guide the downscaling module by supervising it with the bicubically downscaled LR version of the original high-resolution (HR) image. However, this bicubic LR guidance may be suboptimal for the subsequent upscaling (i.e. decoding) and restrict the final reconstruction performance. In this paper, instead of directly applying the LR guidance, we propose an additional invertible flow guidance module (FGM), which can transform the downscaled representation to the visually plausible image during downscaling and transform it back during upscaling. Benefiting from the invertibility of FGM, the downscaled representation could get rid of the LR guidance and would not disturb the downscaling-upscaling process. It allows us to remove the restrictions on the downscaling module and optimize the downscaling and upscaling modules in an end-to-end manner. In this way, these two modules could cooperate to maximize the HR reconstruction performance. Extensive experiments demonstrate that the proposed method can achieve state-of-the-art (SotA) performance on both downscaled and reconstructed images.
Idiomatic Expression Identification using Semantic Compatibility
Oct 19, 2021
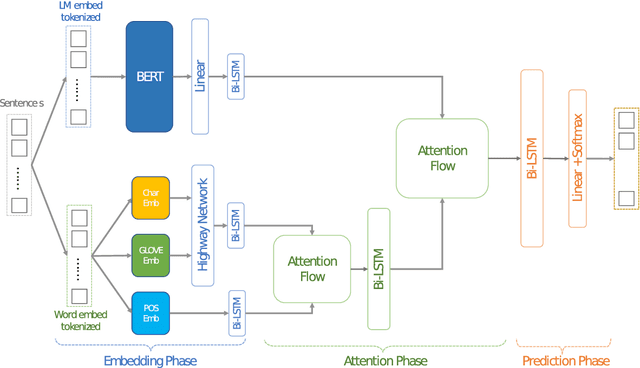
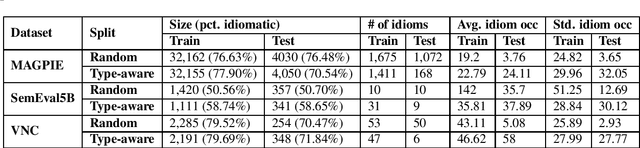
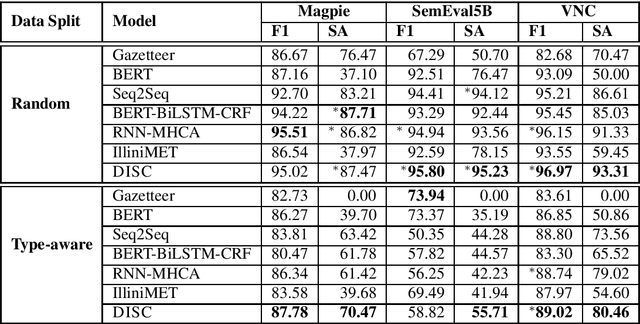
Idiomatic expressions are an integral part of natural language and constantly being added to a language. Owing to their non-compositionality and their ability to take on a figurative or literal meaning depending on the sentential context, they have been a classical challenge for NLP systems. To address this challenge, we study the task of detecting whether a sentence has an idiomatic expression and localizing it. Prior art for this task had studied specific classes of idiomatic expressions offering limited views of their generalizability to new idioms. We propose a multi-stage neural architecture with the attention flow mechanism for identifying these expressions. The network effectively fuses contextual and lexical information at different levels using word and sub-word representations. Empirical evaluations on three of the largest benchmark datasets with idiomatic expressions of varied syntactic patterns and degrees of non-compositionality show that our proposed model achieves new state-of-the-art results. A salient feature of the model is its ability to identify idioms unseen during training with gains from 1.4% to 30.8% over competitive baselines on the largest dataset.
Adaptive Estimators Show Information Compression in Deep Neural Networks
Feb 24, 2019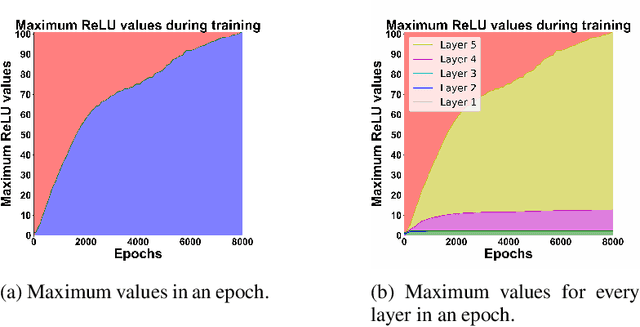
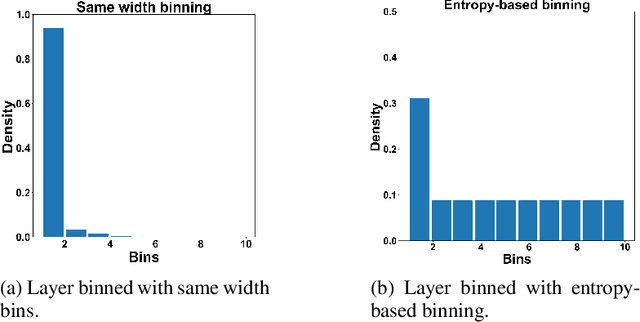
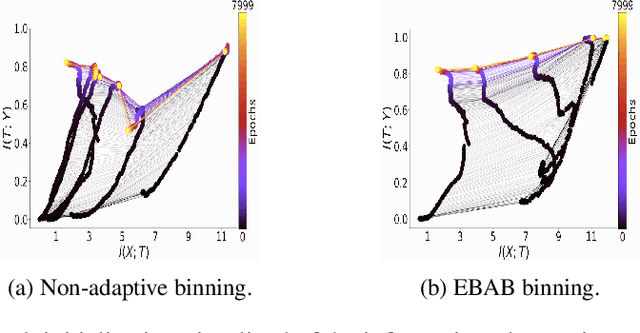
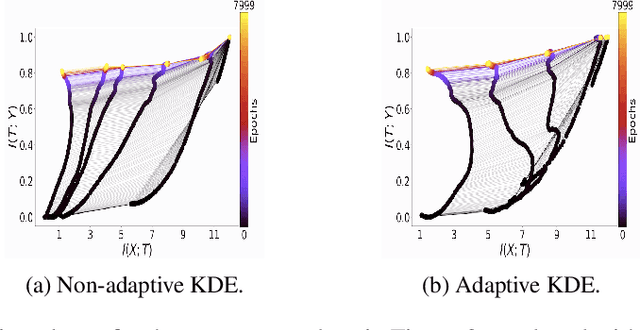
To improve how neural networks function it is crucial to understand their learning process. The information bottleneck theory of deep learning proposes that neural networks achieve good generalization by compressing their representations to disregard information that is not relevant to the task. However, empirical evidence for this theory is conflicting, as compression was only observed when networks used saturating activation functions. In contrast, networks with non-saturating activation functions achieved comparable levels of task performance but did not show compression. In this paper we developed more robust mutual information estimation techniques, that adapt to hidden activity of neural networks and produce more sensitive measurements of activations from all functions, especially unbounded functions. Using these adaptive estimation techniques, we explored compression in networks with a range of different activation functions. With two improved methods of estimation, firstly, we show that saturation of the activation function is not required for compression, and the amount of compression varies between different activation functions. We also find that there is a large amount of variation in compression between different network initializations. Secondary, we see that L2 regularization leads to significantly increased compression, while preventing overfitting. Finally, we show that only compression of the last layer is positively correlated with generalization.
Timestamping Documents and Beliefs
Jun 09, 2021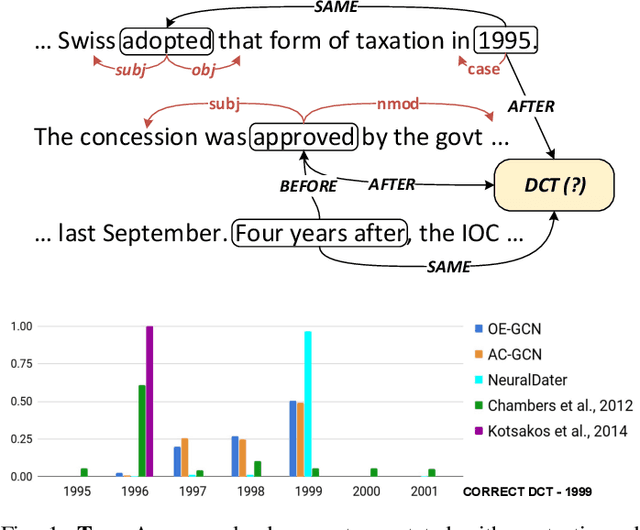
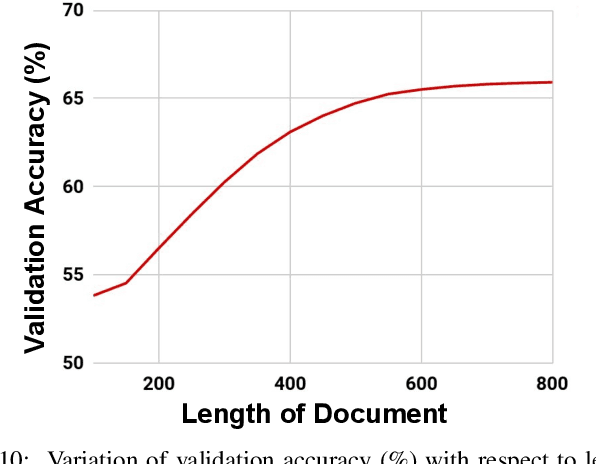
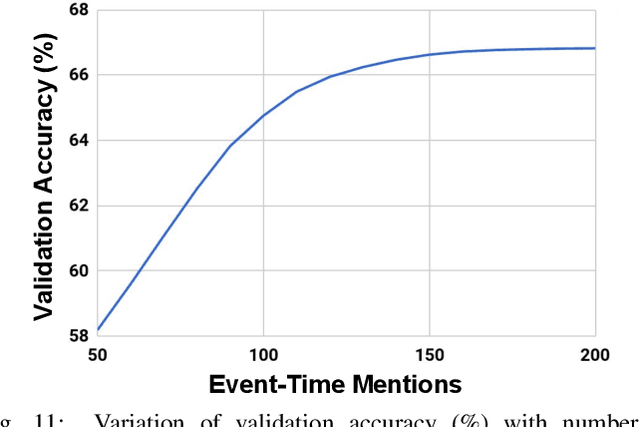
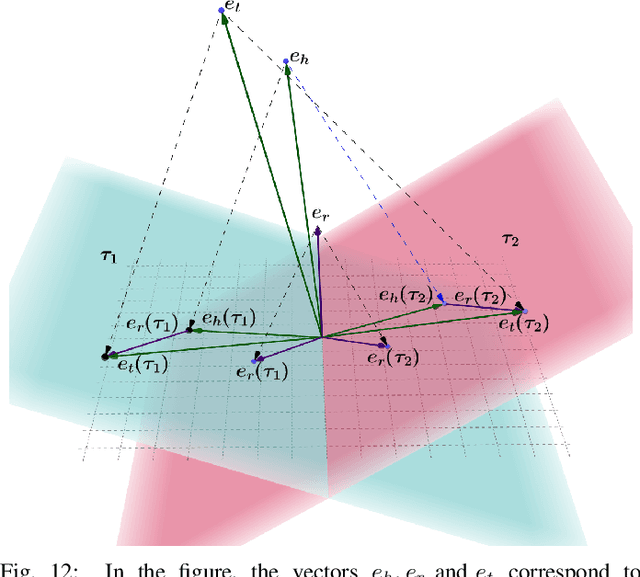
Most of the textual information available to us are temporally variable. In a world where information is dynamic, time-stamping them is a very important task. Documents are a good source of information and are used for many tasks like, sentiment analysis, classification of reviews etc. The knowledge of creation date of documents facilitates several tasks like summarization, event extraction, temporally focused information extraction etc. Unfortunately, for most of the documents on the web, the time-stamp meta-data is either erroneous or missing. Thus document dating is a challenging problem which requires inference over the temporal structure of the document alongside the contextual information of the document. Prior document dating systems have largely relied on handcrafted features while ignoring such document-internal structures. In this paper we propose NeuralDater, a Graph Convolutional Network (GCN) based document dating approach which jointly exploits syntactic and temporal graph structures of document in a principled way. We also pointed out some limitations of NeuralDater and tried to utilize both context and temporal information in documents in a more flexible and intuitive manner proposing AD3: Attentive Deep Document Dater, an attention-based document dating system. To the best of our knowledge these are the first application of deep learning methods for the task. Through extensive experiments on real-world datasets, we find that our models significantly outperforms state-of-the-art baselines by a significant margin.
ERQA: Edge-Restoration Quality Assessment for Video Super-Resolution
Oct 19, 2021

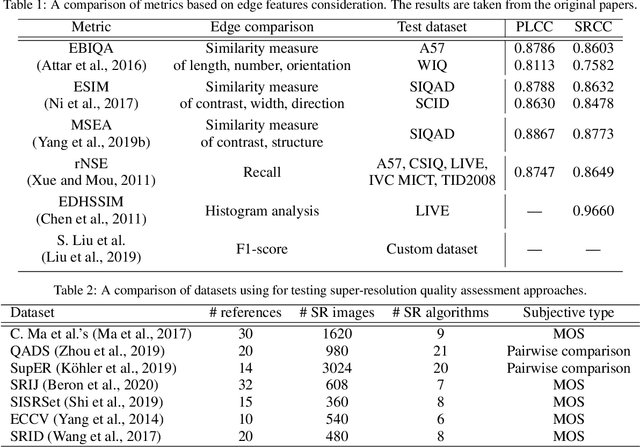

Despite the growing popularity of video super-resolution (VSR), there is still no good way to assess the quality of the restored details in upscaled frames. Some SR methods may produce the wrong digit or an entirely different face. Whether a method's results are trustworthy depends on how well it restores truthful details. Image super-resolution can use natural distributions to produce a high-resolution image that is only somewhat similar to the real one. VSR enables exploration of additional information in neighboring frames to restore details from the original scene. The ERQA metric, which we propose in this paper, aims to estimate a model's ability to restore real details using VSR. On the assumption that edges are significant for detail and character recognition, we chose edge fidelity as the foundation for this metric. Experimental validation of our work is based on the MSU Video Super-Resolution Benchmark, which includes the most difficult patterns for detail restoration and verifies the fidelity of details from the original frame. Code for the proposed metric is publicly available at https://github.com/msu-video-group/ERQA.
Network representation learning systematic review: ancestors and current development state
Sep 14, 2021


Real-world information networks are increasingly occurring across various disciplines including online social networks and citation networks. These network data are generally characterized by sparseness, nonlinearity and heterogeneity bringing different challenges to the network analytics task to capture inherent properties from network data. Artificial intelligence and machine learning have been recently leveraged as powerful systems to learn insights from network data and deal with presented challenges. As part of machine learning techniques, graph embedding approaches are originally conceived for graphs constructed from feature represented datasets, like image dataset, in which links between nodes are explicitly defined. These traditional approaches cannot cope with network data challenges. As a new learning paradigm, network representation learning has been proposed to map a real-world information network into a low-dimensional space while preserving inherent properties of the network. In this paper, we present a systematic comprehensive survey of network representation learning, known also as network embedding, from birth to the current development state. Through the undertaken survey, we provide a comprehensive view of reasons behind the emergence of network embedding and, types of settings and models used in the network embedding pipeline. Thus, we introduce a brief history of representation learning and word representation learning ancestor of network embedding. We provide also formal definitions of basic concepts required to understand network representation learning followed by a description of network embedding pipeline. Most commonly used downstream tasks to evaluate embeddings, their evaluation metrics and popular datasets are highlighted. Finally, we present the open-source libraries for network embedding.
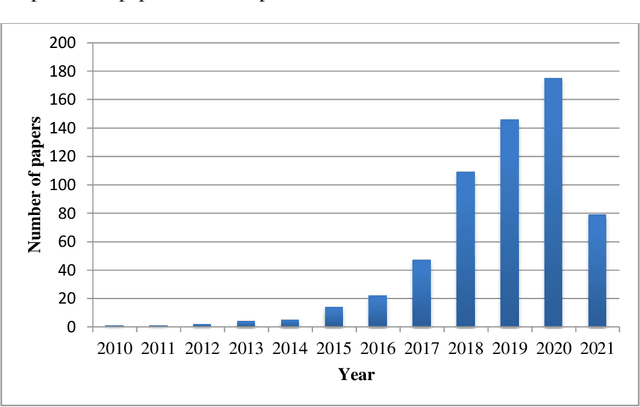
* 65 pages 11 Figures 6 Tables
Passive Phased Array Acoustic Emission Localisation via Recursive Signal-Averaged Lamb Waves with an Applied Warped Frequency Transformation
Oct 13, 2021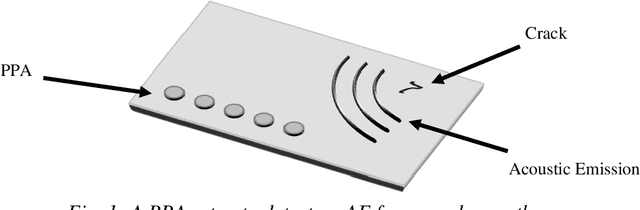

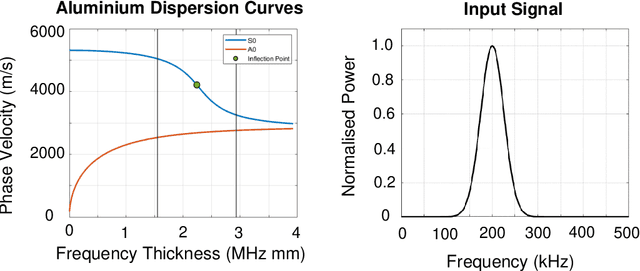

This work presents a concept for the localisation of Lamb waves using a Passive Phased Array (PPA). A Warped Frequency Transformation (WFT) is applied to the acquired signals using numerically determined phase velocity information to compensate for signal dispersion. Whilst powerful, uncertainty between material properties cannot completely remove dispersion and hence the close intra-element spacing of the array is leveraged to allow for the assumption that each acquired signal is a scaled, translated, and noised copy of its adjacent counterparts. Following this, a recursive signal-averaging method using artificial time-locking to denoise the acquired signals by assuming the presence of non-correlated, zero mean noise is applied. Unlike the application of bandpass filters, the signal-averaging method does not remove potentially useful frequency components. The proposed methodology is compared against a bandpass filtered approach through a parametric study. A further discussion is made regarding applications and future developments of this technique.
Multi-Semantic Image Recognition Model and Evaluating Index for explaining the deep learning models
Sep 28, 2021
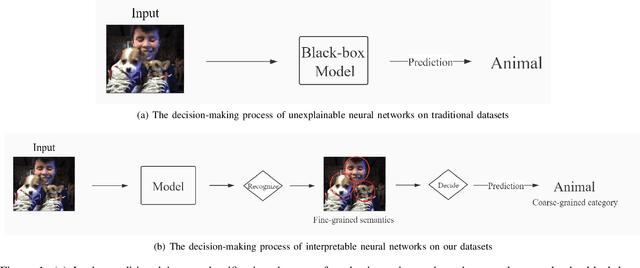
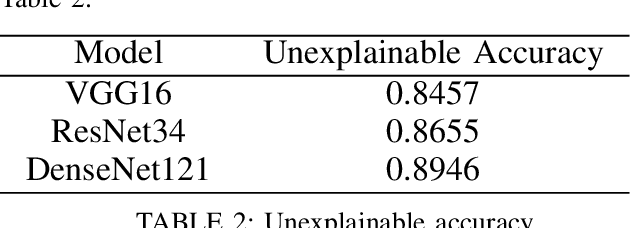
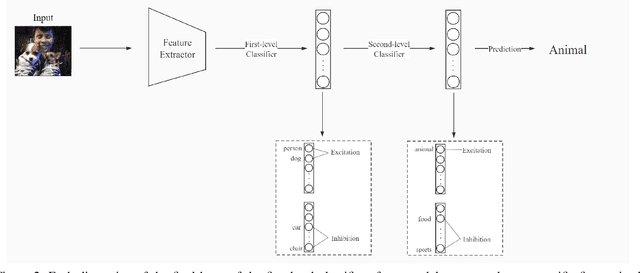
Although deep learning models are powerful among various applications, most deep learning models are still a black box, lacking verifiability and interpretability, which means the decision-making process that human beings cannot understand. Therefore, how to evaluate deep neural networks with explanations is still an urgent task. In this paper, we first propose a multi-semantic image recognition model, which enables human beings to understand the decision-making process of the neural network. Then, we presents a new evaluation index, which can quantitatively assess the model interpretability. We also comprehensively summarize the semantic information that affects the image classification results in the judgment process of neural networks. Finally, this paper also exhibits the relevant baseline performance with current state-of-the-art deep learning models.
Multi-View Spatial-Temporal Graph Convolutional Networks with Domain Generalization for Sleep Stage Classification
Sep 04, 2021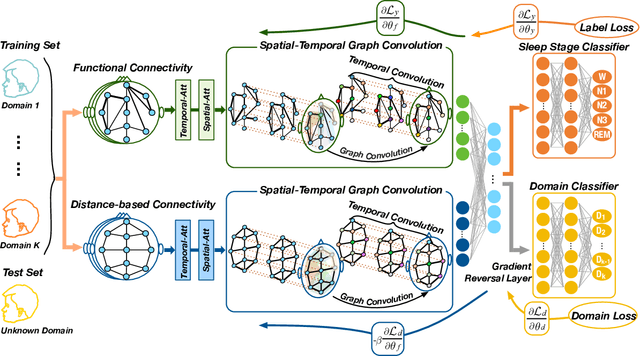
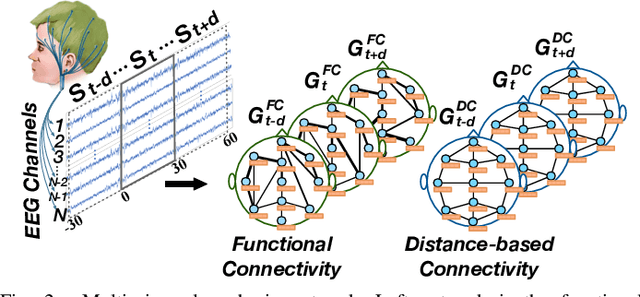
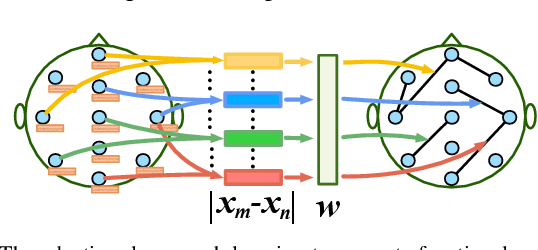
Sleep stage classification is essential for sleep assessment and disease diagnosis. Although previous attempts to classify sleep stages have achieved high classification performance, several challenges remain open: 1) How to effectively utilize time-varying spatial and temporal features from multi-channel brain signals remains challenging. Prior works have not been able to fully utilize the spatial topological information among brain regions. 2) Due to the many differences found in individual biological signals, how to overcome the differences of subjects and improve the generalization of deep neural networks is important. 3) Most deep learning methods ignore the interpretability of the model to the brain. To address the above challenges, we propose a multi-view spatial-temporal graph convolutional networks (MSTGCN) with domain generalization for sleep stage classification. Specifically, we construct two brain view graphs for MSTGCN based on the functional connectivity and physical distance proximity of the brain regions. The MSTGCN consists of graph convolutions for extracting spatial features and temporal convolutions for capturing the transition rules among sleep stages. In addition, attention mechanism is employed for capturing the most relevant spatial-temporal information for sleep stage classification. Finally, domain generalization and MSTGCN are integrated into a unified framework to extract subject-invariant sleep features. Experiments on two public datasets demonstrate that the proposed model outperforms the state-of-the-art baselines.