 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparQ Attention: Bandwidth-Efficient LLM Inference
Dec 08, 2023Generative large language models (LLMs) have opened up numerous novel possibilities, but due to their significant computational requirements their ubiquitous use remains challenging. Some of the most useful applications require processing large numbers of samples at a time and using long contexts, both significantly increasing the memory communication load of the models. We introduce SparQ Attention, a technique for increasing the inference throughput of LLMs by reducing the memory bandwidth requirements within the attention blocks through selective fetching of the cached history. Our proposed technique can be applied directly to off-the-shelf LLMs during inference, without requiring any modification to the pre-training setup or additional fine-tuning. We show how SparQ Attention can decrease the attention memory bandwidth requirements up to eight times without any loss in accuracy by evaluating Llama 2 and Pythia models on a wide range of downstream tasks.
Towards Structured Dynamic Sparse Pre-Training of BERT
Aug 13, 2021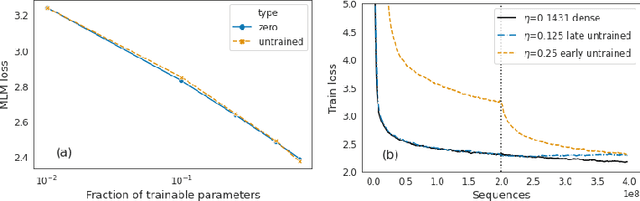
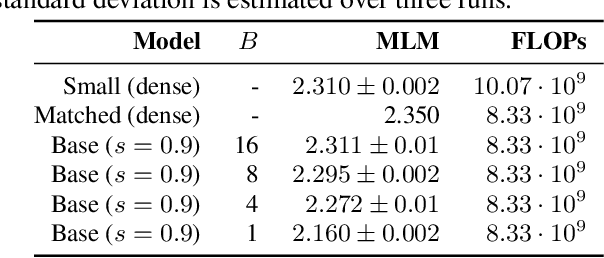
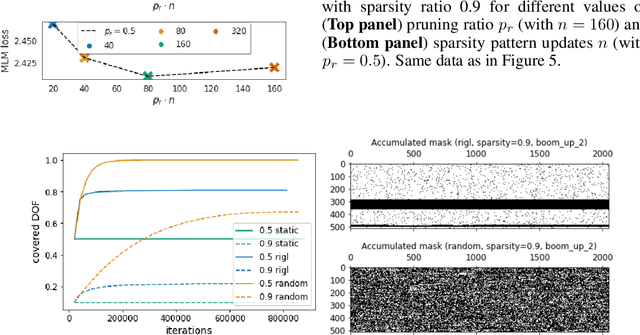
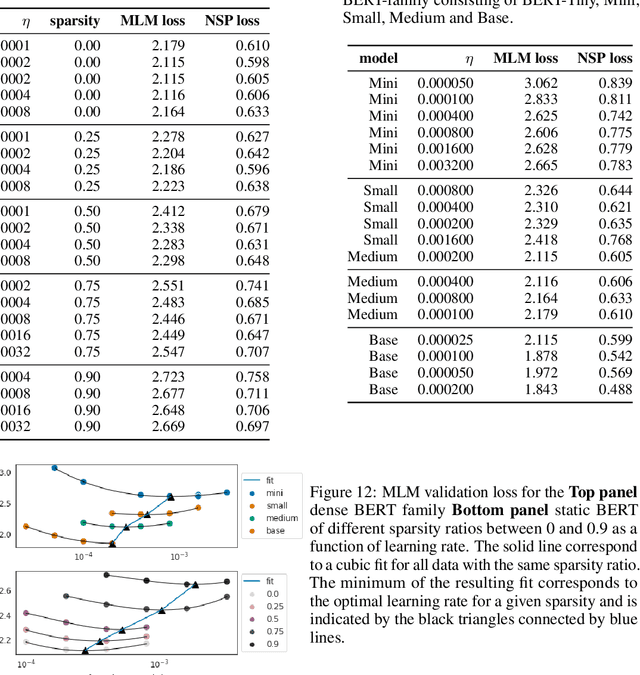
Identifying algorithms for computational efficient unsupervised training of large language models is an important and active area of research. In this work, we develop and study a straightforward, dynamic always-sparse pre-training approach for BERT language modeling task, which leverages periodic compression steps based on magnitude pruning followed by random parameter re-allocation. This approach enables us to achieve Pareto improvements in terms of the number of floating-point operations (FLOPs) over statically sparse and dense models across a broad spectrum of network sizes. Furthermore, we demonstrate that training remains FLOP-efficient when using coarse-grained block sparsity, making it particularly promising for efficient execution on modern hardware accelerators.
GroupBERT: Enhanced Transformer Architecture with Efficient Grouped Structures
Jun 10, 2021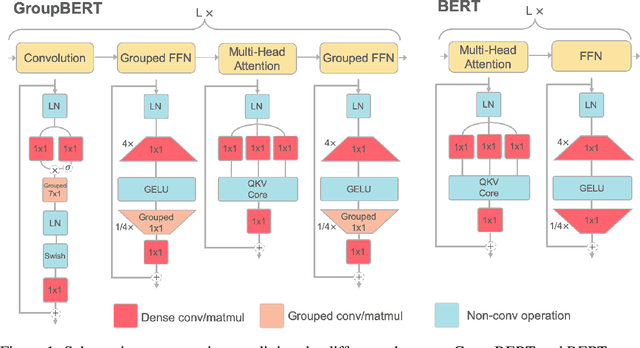
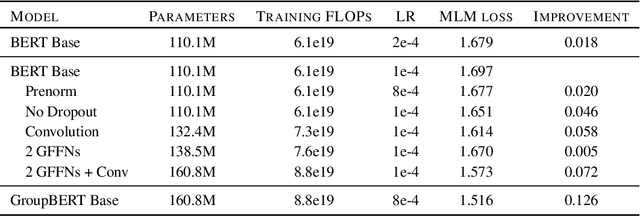

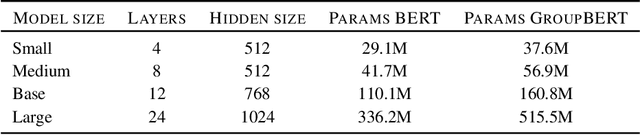
Attention based language models have become a critical component in state-of-the-art natural language processing systems. However, these models have significant computational requirements, due to long training times, dense operations and large parameter count. In this work we demonstrate a set of modifications to the structure of a Transformer layer, producing a more efficient architecture. First, we add a convolutional module to complement the self-attention module, decoupling the learning of local and global interactions. Secondly, we rely on grouped transformations to reduce the computational cost of dense feed-forward layers and convolutions, while preserving the expressivity of the model. We apply the resulting architecture to language representation learning and demonstrate its superior performance compared to BERT models of different scales. We further highlight its improved efficiency, both in terms of floating-point operations (FLOPs) and time-to-train.
Adaptive Estimators Show Information Compression in Deep Neural Networks
Feb 24, 2019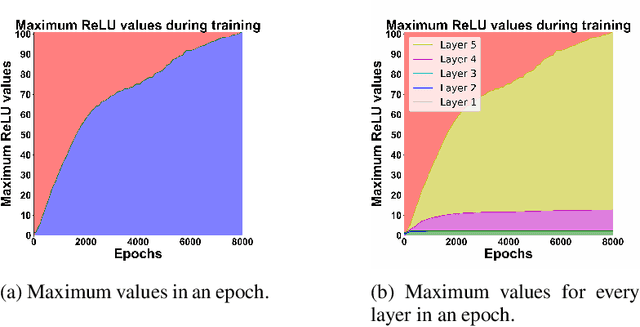
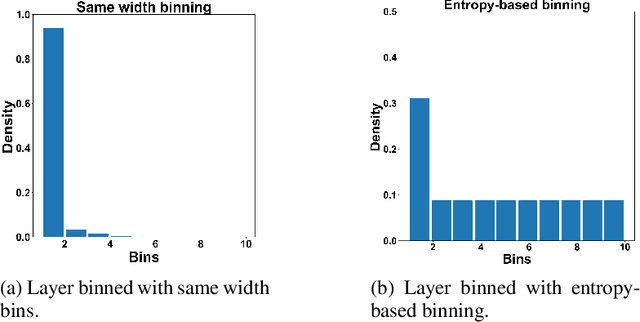
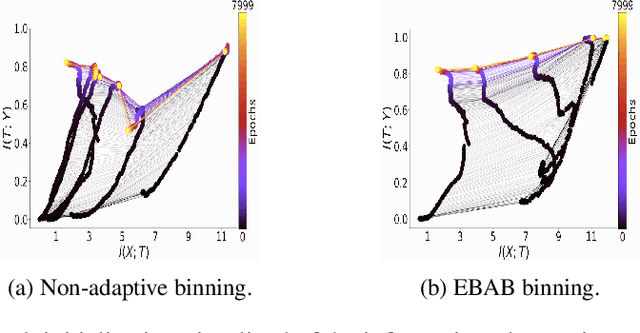
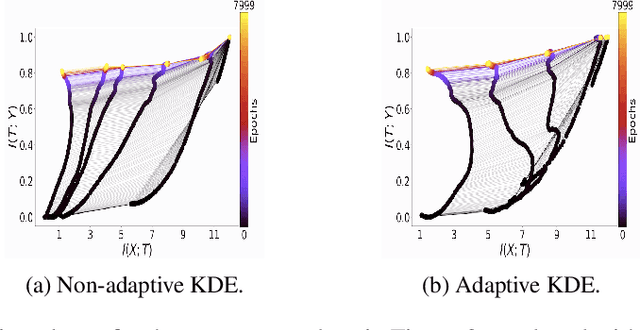
To improve how neural networks function it is crucial to understand their learning process. The information bottleneck theory of deep learning proposes that neural networks achieve good generalization by compressing their representations to disregard information that is not relevant to the task. However, empirical evidence for this theory is conflicting, as compression was only observed when networks used saturating activation functions. In contrast, networks with non-saturating activation functions achieved comparable levels of task performance but did not show compression. In this paper we developed more robust mutual information estimation techniques, that adapt to hidden activity of neural networks and produce more sensitive measurements of activations from all functions, especially unbounded functions. Using these adaptive estimation techniques, we explored compression in networks with a range of different activation functions. With two improved methods of estimation, firstly, we show that saturation of the activation function is not required for compression, and the amount of compression varies between different activation functions. We also find that there is a large amount of variation in compression between different network initializations. Secondary, we see that L2 regularization leads to significantly increased compression, while preventing overfitting. Finally, we show that only compression of the last layer is positively correlated with generalization.