 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Rate of Prefix-free Codes in LQG Control Systems with Side Information
Jan 22, 2021
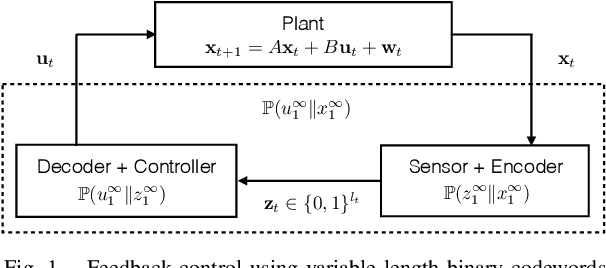
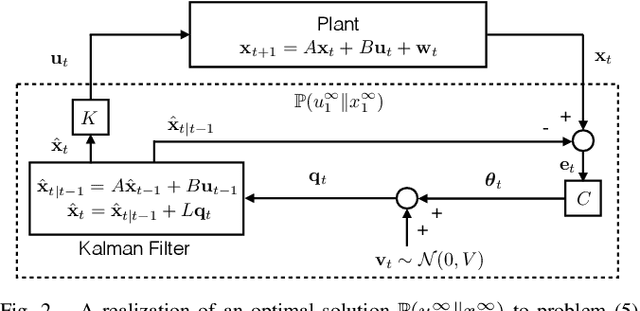
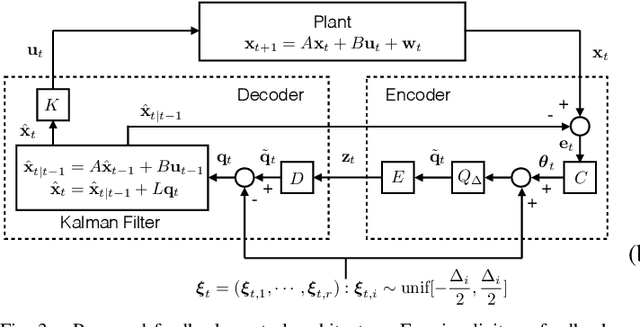
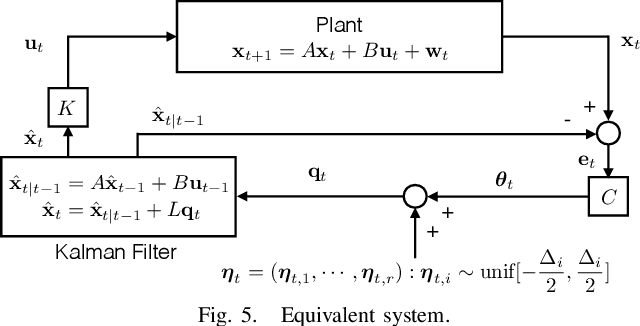
In this work, we study LQG control systems where one of two feedback channels is discrete and incurs a communication cost, measured as time-averaged expected length of prefix-free codeword. This formulation to motivates a rate distortion problem, which we restrict to a particular policy space and express as a convex optimization. The optimization leads to a quantizer design and a subseqent achievability result.
Time in a Box: Advancing Knowledge Graph Completion with Temporal Scopes
Nov 12, 2021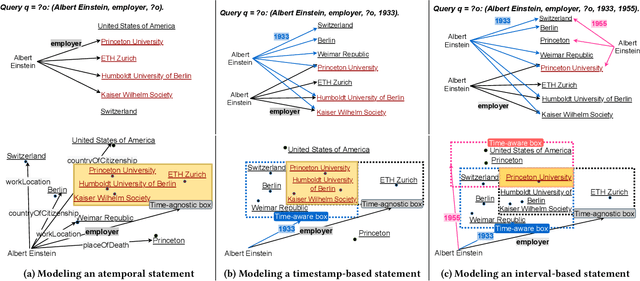
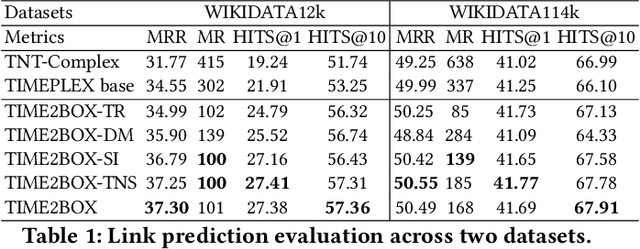
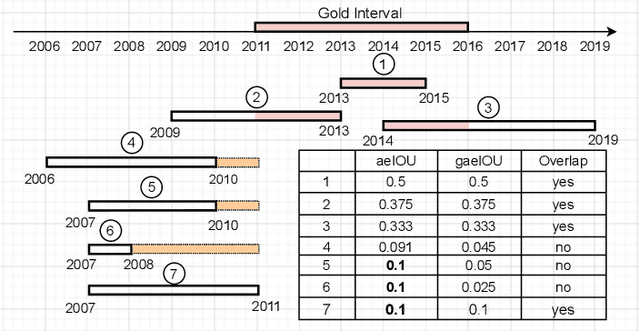
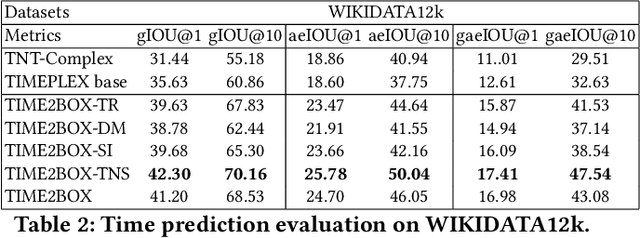
Almost all statements in knowledge bases have a temporal scope during which they are valid. Hence, knowledge base completion (KBC) on temporal knowledge bases (TKB), where each statement \textit{may} be associated with a temporal scope, has attracted growing attention. Prior works assume that each statement in a TKB \textit{must} be associated with a temporal scope. This ignores the fact that the scoping information is commonly missing in a KB. Thus prior work is typically incapable of handling generic use cases where a TKB is composed of temporal statements with/without a known temporal scope. In order to address this issue, we establish a new knowledge base embedding framework, called TIME2BOX, that can deal with atemporal and temporal statements of different types simultaneously. Our main insight is that answers to a temporal query always belong to a subset of answers to a time-agnostic counterpart. Put differently, time is a filter that helps pick out answers to be correct during certain periods. We introduce boxes to represent a set of answer entities to a time-agnostic query. The filtering functionality of time is modeled by intersections over these boxes. In addition, we generalize current evaluation protocols on time interval prediction. We describe experiments on two datasets and show that the proposed method outperforms state-of-the-art (SOTA) methods on both link prediction and time prediction.
CO-Search: COVID-19 Information Retrieval with Semantic Search, Question Answering, and Abstractive Summarization
Jun 17, 2020
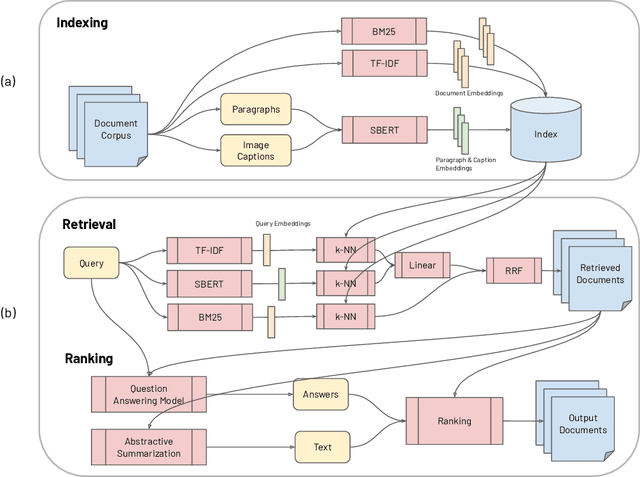
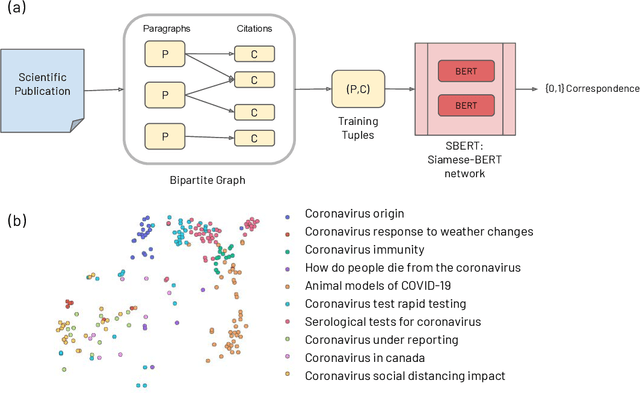
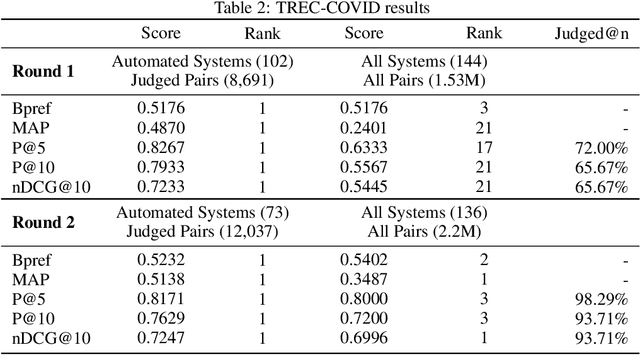
The COVID-19 global pandemic has resulted in international efforts to understand, track, and mitigate the disease, yielding a significant corpus of COVID-19 and SARS-CoV-2-related publications across scientific disciplines. As of May 2020, 128,000 coronavirus-related publications have been collected through the COVID-19 Open Research Dataset Challenge. Here we present CO-Search, a retriever-ranker semantic search engine designed to handle complex queries over the COVID-19 literature, potentially aiding overburdened health workers in finding scientific answers during a time of crisis. The retriever is built from a Siamese-BERT encoder that is linearly composed with a TF-IDF vectorizer, and reciprocal-rank fused with a BM25 vectorizer. The ranker is composed of a multi-hop question-answering module, that together with a multi-paragraph abstractive summarizer adjust retriever scores. To account for the domain-specific and relatively limited dataset, we generate a bipartite graph of document paragraphs and citations, creating 1.3 million (citation title, paragraph) tuples for training the encoder. We evaluate our system on the data of the TREC-COVID information retrieval challenge. CO-Search obtains top performance on the datasets of the first and second rounds, across several key metrics: normalized discounted cumulative gain, precision, mean average precision, and binary preference.
Developing Products Update-Alert System for e-Commerce Websites Users Using HTML Data and Web Scraping Technique
Sep 02, 2021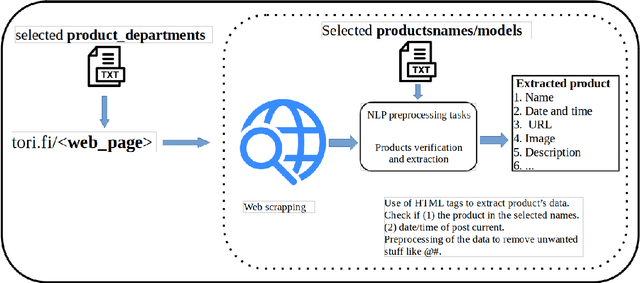

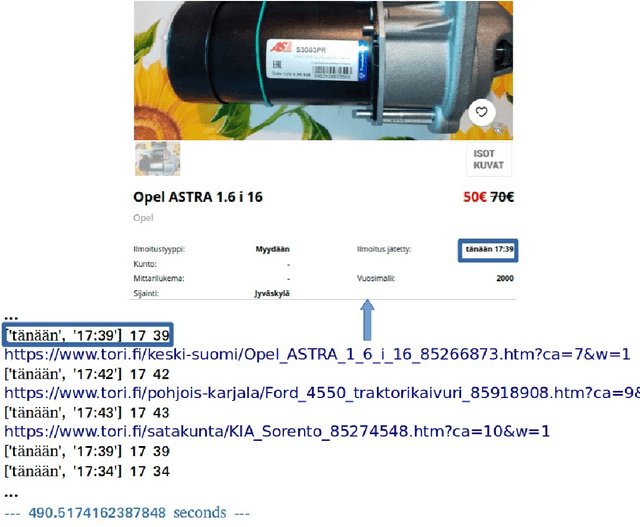
Websites are regarded as domains of limitless information which anyone and everyone can access. The new trend of technology put us to change the way we are doing our business. The Internet now is fastly becoming a new place for business and the advancement in this technology gave rise to the number of e-commerce websites. This made the lifestyle of marketers/vendors, retailers and consumers (collectively regarded as users in this paper) easy, because it provides easy platforms to sale/order items through the internet. This also requires that the users will have to spend a lot of time and effort to search for the best product deals, products updates and offers on e-commerce websites. They have to filter and compare search results by themselves which takes a lot of time and there are chances of ambiguous results. In this paper, we applied web crawling and scraping methods on an e-commerce website to get HTML data for identifying products updates based on the current time. The HTML data is preprocessed to extract details of the products such as name, price, post date and time, etc. to serve as useful information for users.
* 6 pages, 3 figures, 1 table, IJNLC Journal
Generalizing electrocardiogram delineation: training convolutional neural networks with synthetic data augmentation
Nov 25, 2021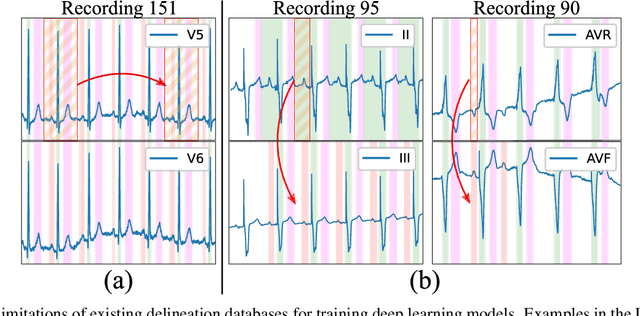
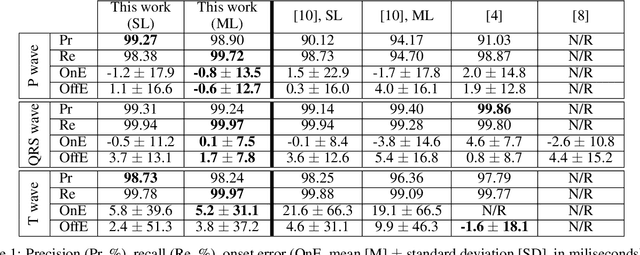
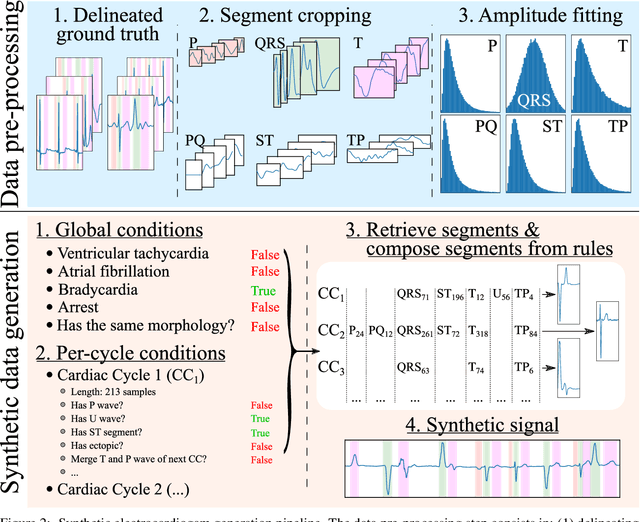

Obtaining per-beat information is a key task in the analysis of cardiac electrocardiograms (ECG), as many downstream diagnosis tasks are dependent on ECG-based measurements. Those measurements, however, are costly to produce, especially in recordings that change throughout long periods of time. However, existing annotated databases for ECG delineation are small, being insufficient in size and in the array of pathological conditions they represent. This article delves has two main contributions. First, a pseudo-synthetic data generation algorithm was developed, based in probabilistically composing ECG traces given "pools" of fundamental segments, as cropped from the original databases, and a set of rules for their arrangement into coherent synthetic traces. The generation of conditions is controlled by imposing expert knowledge on the generated trace, which increases the input variability for training the model. Second, two novel segmentation-based loss functions have been developed, which attempt at enforcing the prediction of an exact number of independent structures and at producing closer segmentation boundaries by focusing on a reduced number of samples. The best performing model obtained an $F_1$-score of 99.38\% and a delineation error of $2.19 \pm 17.73$ ms and $4.45 \pm 18.32$ ms for all wave's fiducials (onsets and offsets, respectively), as averaged across the P, QRS and T waves for three distinct freely available databases. The excellent results were obtained despite the heterogeneous characteristics of the tested databases, in terms of lead configurations (Holter, 12-lead), sampling frequencies ($250$, $500$ and $2,000$ Hz) and represented pathophysiologies (e.g., different types of arrhythmias, sinus rhythm with structural heart disease), hinting at its generalization capabilities, while outperforming current state-of-the-art delineation approaches.
Convolutional Shapelet Transform: A new approach for time series shapelets
Sep 28, 2021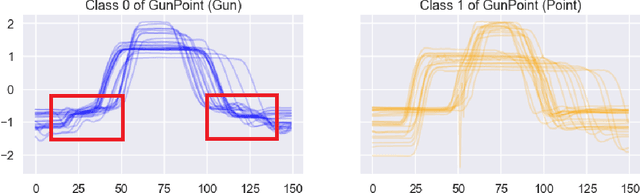
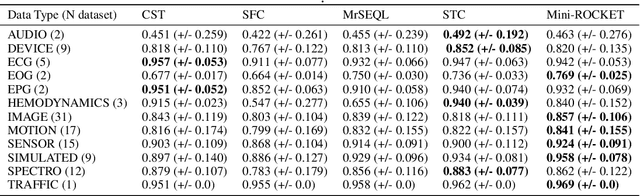
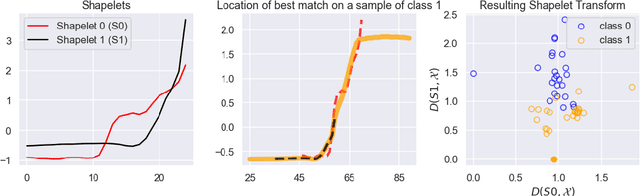
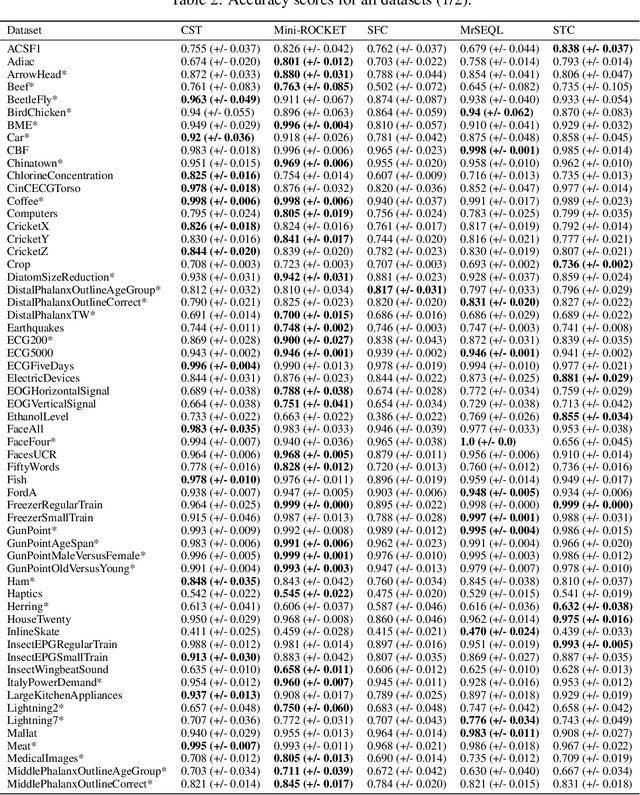
Shapelet-based algorithms are widely used for time series classification because of their ease of interpretation, but they are currently outperformed, notably by methods using convolutional kernels, capable of reaching state-of-the-art performance while being highly scalable. We present a new formulation of time series shapelets including the notion of dilation, and a shapelet extraction method based on convolutional kernels, which is able to target the discriminant information identified by convolutional kernels. Experiments performed on 108 datasets show that our method improves on the state-of-the-art for shapelet algorithms, and we show that it can be used to interpret results from convolutional kernels.
Fuzzy-Depth Objects Grasping Based on FSG Algorithm and a Soft Robotic Hand
Oct 21, 2021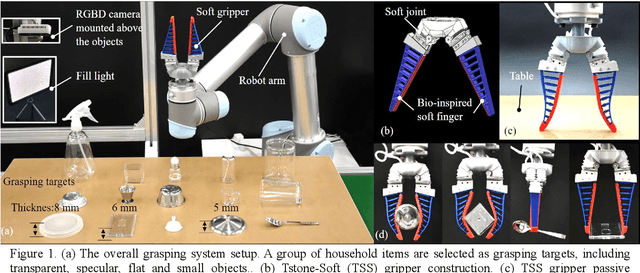
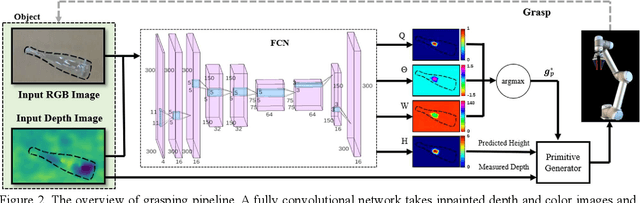
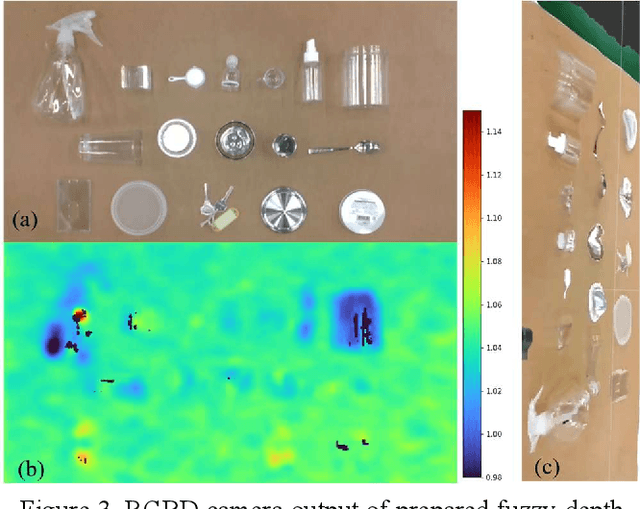

Autonomous grasping is an important factor for robots physically interacting with the environment and executing versatile tasks. However, a universally applicable, cost-effective, and rapidly deployable autonomous grasping approach is still limited by those target objects with fuzzy-depth information. Examples are transparent, specular, flat, and small objects whose depth is difficult to be accurately sensed. In this work, we present a solution to those fuzzy-depth objects. The framework of our approach includes two major components: one is a soft robotic hand and the other one is a Fuzzy-depth Soft Grasping (FSG) algorithm. The soft hand is replaceable for most existing soft hands/grippers with body compliance. FSG algorithm exploits both RGB and depth images to predict grasps while not trying to reconstruct the whole scene. Two grasping primitives are designed to further increase robustness. The proposed method outperforms reference baselines in unseen fuzzy-depth objects grasping experiments (84% success rate).
Towards Practical Deployment-Stage Backdoor Attack on Deep Neural Networks
Nov 25, 2021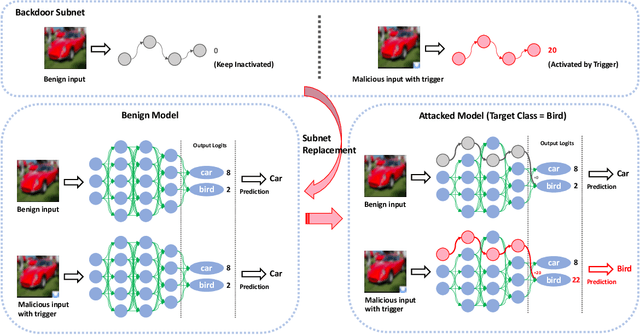
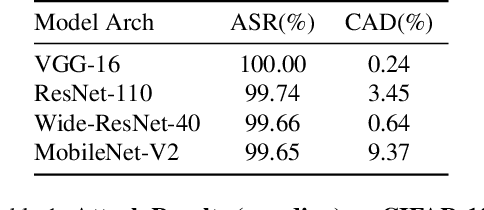
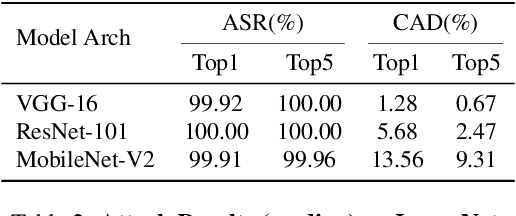
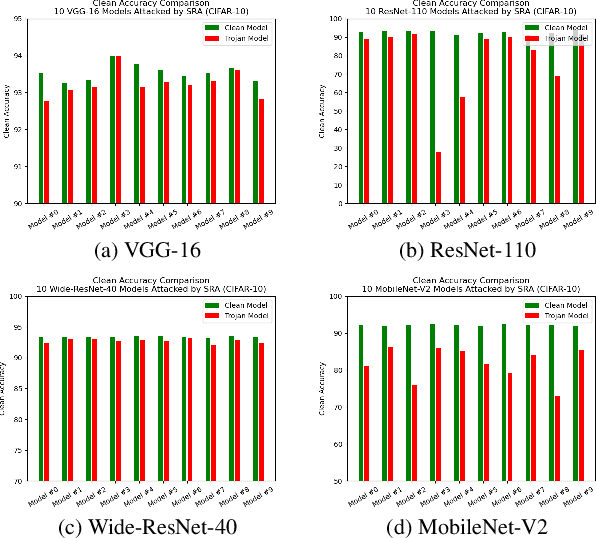
One major goal of the AI security community is to securely and reliably produce and deploy deep learning models for real-world applications. To this end, data poisoning based backdoor attacks on deep neural networks (DNNs) in the production stage (or training stage) and corresponding defenses are extensively explored in recent years. Ironically, backdoor attacks in the deployment stage, which can often happen in unprofessional users' devices and are thus arguably far more threatening in real-world scenarios, draw much less attention of the community. We attribute this imbalance of vigilance to the weak practicality of existing deployment-stage backdoor attack algorithms and the insufficiency of real-world attack demonstrations. To fill the blank, in this work, we study the realistic threat of deployment-stage backdoor attacks on DNNs. We base our study on a commonly used deployment-stage attack paradigm -- adversarial weight attack, where adversaries selectively modify model weights to embed backdoor into deployed DNNs. To approach realistic practicality, we propose the first gray-box and physically realizable weights attack algorithm for backdoor injection, namely subnet replacement attack (SRA), which only requires architecture information of the victim model and can support physical triggers in the real world. Extensive experimental simulations and system-level real-world attack demonstrations are conducted. Our results not only suggest the effectiveness and practicality of the proposed attack algorithm, but also reveal the practical risk of a novel type of computer virus that may widely spread and stealthily inject backdoor into DNN models in user devices. By our study, we call for more attention to the vulnerability of DNNs in the deployment stage.
GAM: Explainable Visual Similarity and Classification via Gradient Activation Maps
Sep 02, 2021
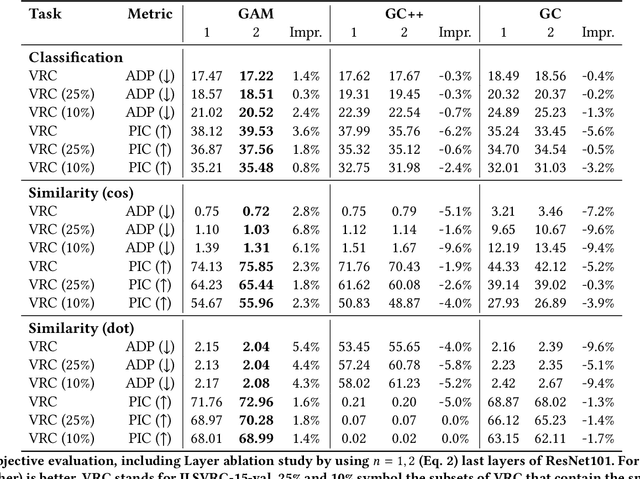
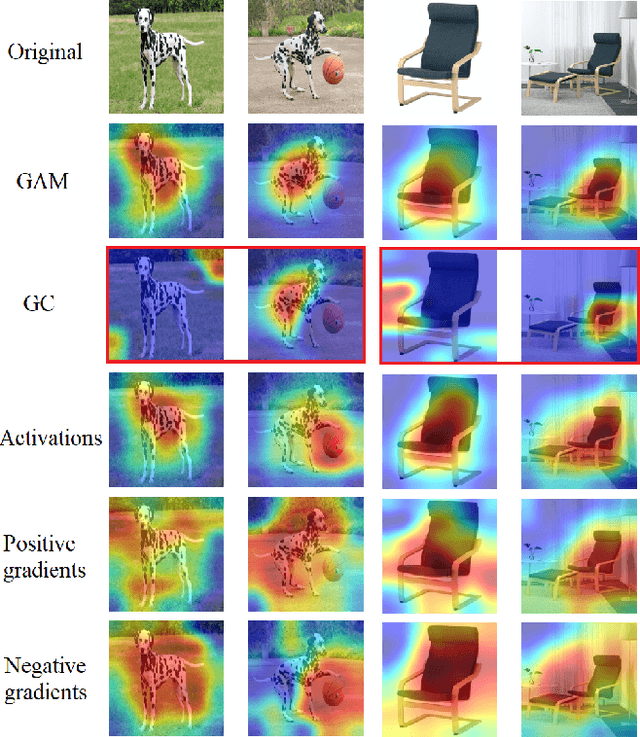
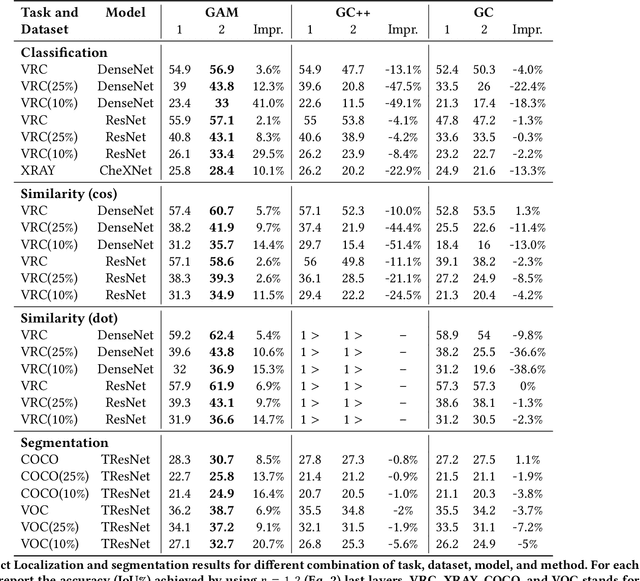
We present Gradient Activation Maps (GAM) - a machinery for explaining predictions made by visual similarity and classification models. By gleaning localized gradient and activation information from multiple network layers, GAM offers improved visual explanations, when compared to existing alternatives. The algorithmic advantages of GAM are explained in detail, and validated empirically, where it is shown that GAM outperforms its alternatives across various tasks and datasets.
Parallel Composition of Weighted Finite-State Transducers
Oct 06, 2021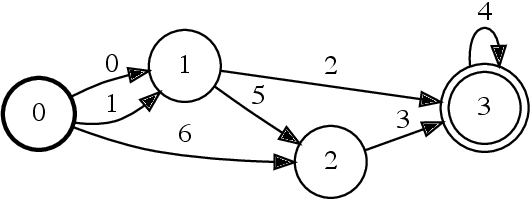
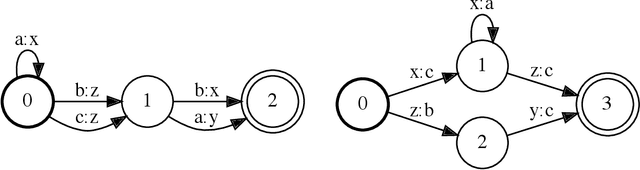
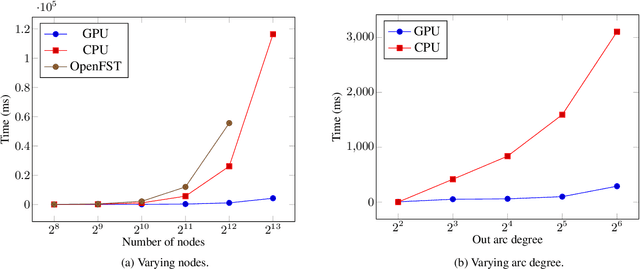
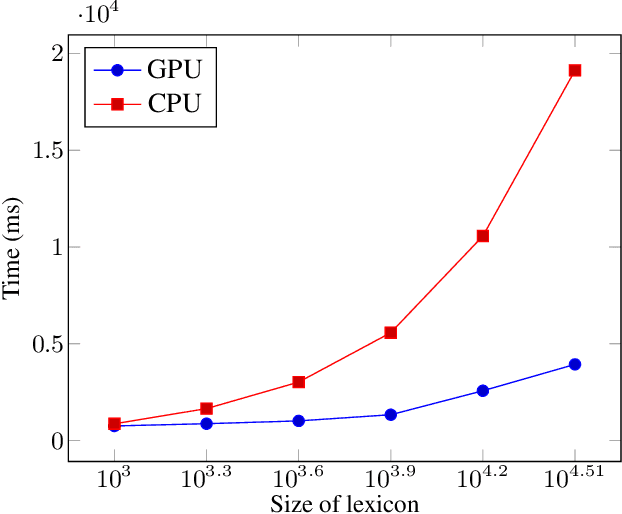
Finite-state transducers (FSTs) are frequently used in speech recognition. Transducer composition is an essential operation for combining different sources of information at different granularities. However, composition is also one of the more computationally expensive operations. Due to the heterogeneous structure of FSTs, parallel algorithms for composition are suboptimal in efficiency, generality, or both. We propose an algorithm for parallel composition and implement it on graphics processing units. We benchmark our parallel algorithm on the composition of random graphs and the composition of graphs commonly used in speech recognition. The parallel composition scales better with the size of the input graphs and for large graphs can be as much as 10 to 30 times faster than a sequential CPU algorithm.