 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Learning in Information Security
Sep 12, 2018
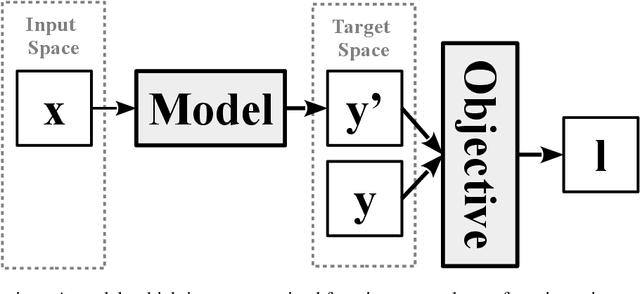
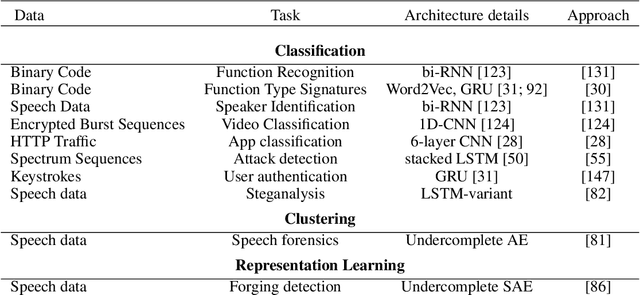
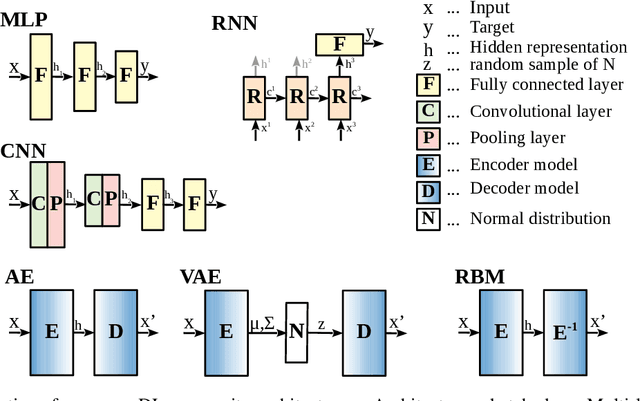

Machine learning has a long tradition of helping to solve complex information security problems that are difficult to solve manually. Machine learning techniques learn models from data representations to solve a task. These data representations are hand-crafted by domain experts. Deep Learning is a sub-field of machine learning, which uses models that are composed of multiple layers. Consequently, representations that are used to solve a task are learned from the data instead of being manually designed. In this survey, we study the use of DL techniques within the domain of information security. We systematically reviewed 77 papers and presented them from a data-centric perspective. This data-centric perspective reflects one of the most crucial advantages of DL techniques -- domain independence. If DL-methods succeed to solve problems on a data type in one domain, they most likely will also succeed on similar data from another domain. Other advantages of DL methods are unrivaled scalability and efficiency, both regarding the number of examples that can be analyzed as well as with respect of dimensionality of the input data. DL methods generally are capable of achieving high-performance and generalize well. However, information security is a domain with unique requirements and challenges. Based on an analysis of our reviewed papers, we point out shortcomings of DL-methods to those requirements and discuss further research opportunities.
Approximate Inference via Clustering
Nov 28, 2021
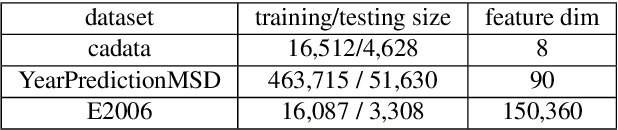
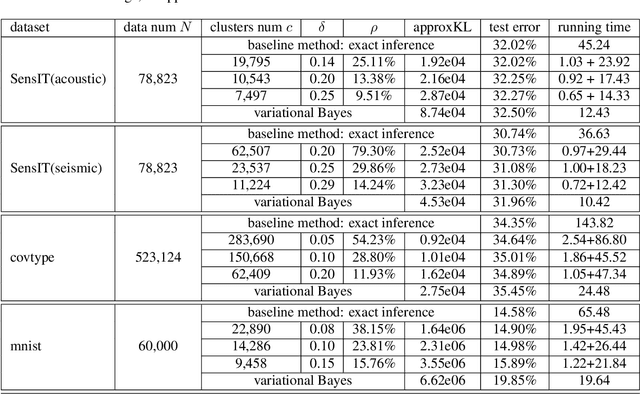
In recent years, large-scale Bayesian learning draws a great deal of attention. However, in big-data era, the amount of data we face is growing much faster than our ability to deal with it. Fortunately, it is observed that large-scale datasets usually own rich internal structure and is somewhat redundant. In this paper, we attempt to simplify the Bayesian posterior via exploiting this structure. Specifically, we restrict our interest to the so-called well-clustered datasets and construct an \emph{approximate posterior} according to the clustering information. Fortunately, the clustering structure can be efficiently obtained via a particular clustering algorithm. When constructing the approximate posterior, the data points in the same cluster are all replaced by the centroid of the cluster. As a result, the posterior can be significantly simplified. Theoretically, we show that under certain conditions the approximate posterior we construct is close (measured by KL divergence) to the exact posterior. Furthermore, thorough experiments are conducted to validate the fact that the constructed posterior is a good approximation to the true posterior and much easier to sample from.
Cooperative multi-agent reinforcement learning for high-dimensional nonequilibrium control
Nov 12, 2021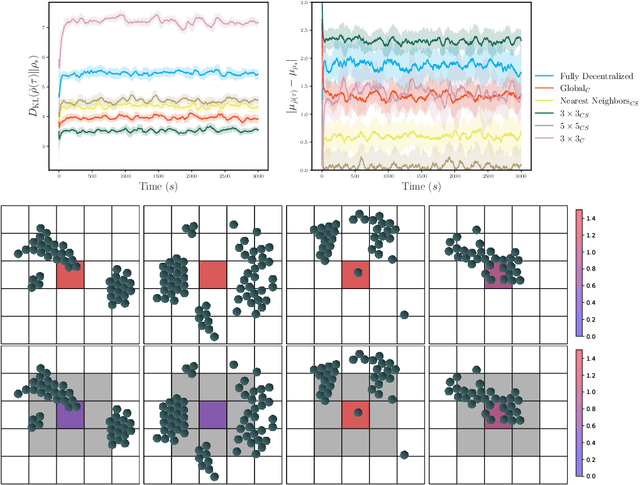
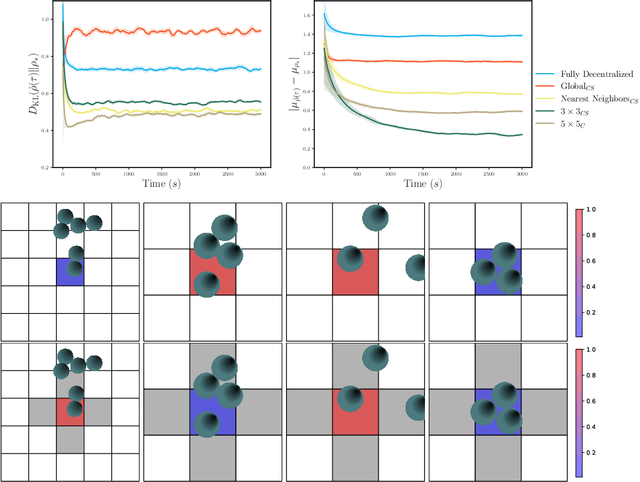
Experimental advances enabling high-resolution external control create new opportunities to produce materials with exotic properties. In this work, we investigate how a multi-agent reinforcement learning approach can be used to design external control protocols for self-assembly. We find that a fully decentralized approach performs remarkably well even with a "coarse" level of external control. More importantly, we see that a partially decentralized approach, where we include information about the local environment allows us to better control our system towards some target distribution. We explain this by analyzing our approach as a partially-observed Markov decision process. With a partially decentralized approach, the agent is able to act more presciently, both by preventing the formation of undesirable structures and by better stabilizing target structures as compared to a fully decentralized approach.
Xp-GAN: Unsupervised Multi-object Controllable Video Generation
Nov 19, 2021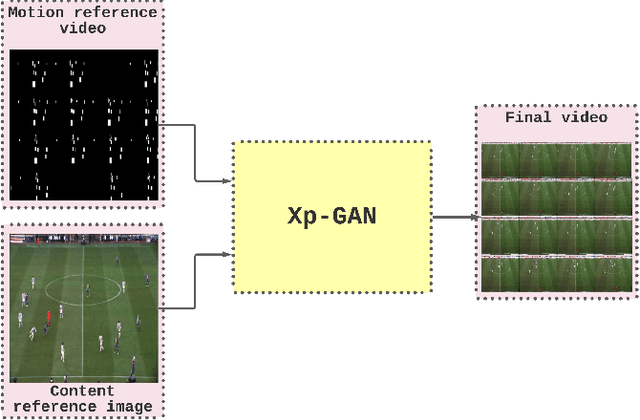

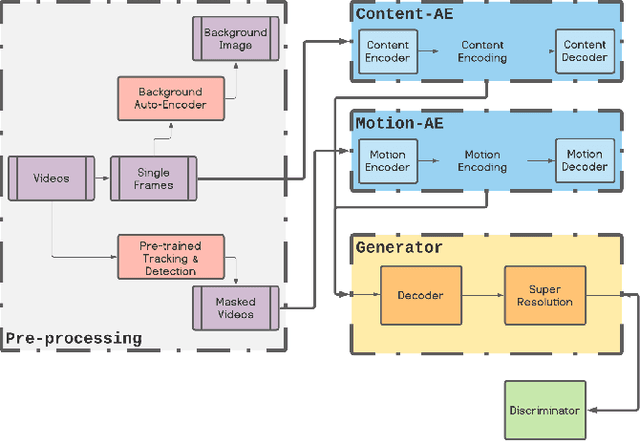
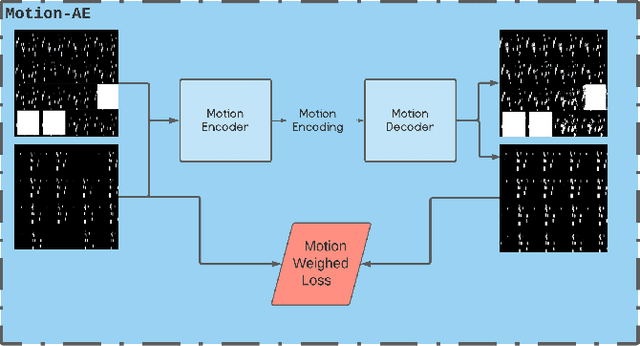
Video Generation is a relatively new and yet popular subject in machine learning due to its vast variety of potential applications and its numerous challenges. Current methods in Video Generation provide the user with little or no control over the exact specification of how the objects in the generate video are to be moved and located at each frame, that is, the user can't explicitly control how each object in the video should move. In this paper we propose a novel method that allows the user to move any number of objects of a single initial frame just by drawing bounding boxes over those objects and then moving those boxes in the desired path. Our model utilizes two Autoencoders to fully decompose the motion and content information in a video and achieves results comparable to well-known baseline and state of the art methods.
Molecular Graph Generation via Geometric Scattering
Oct 12, 2021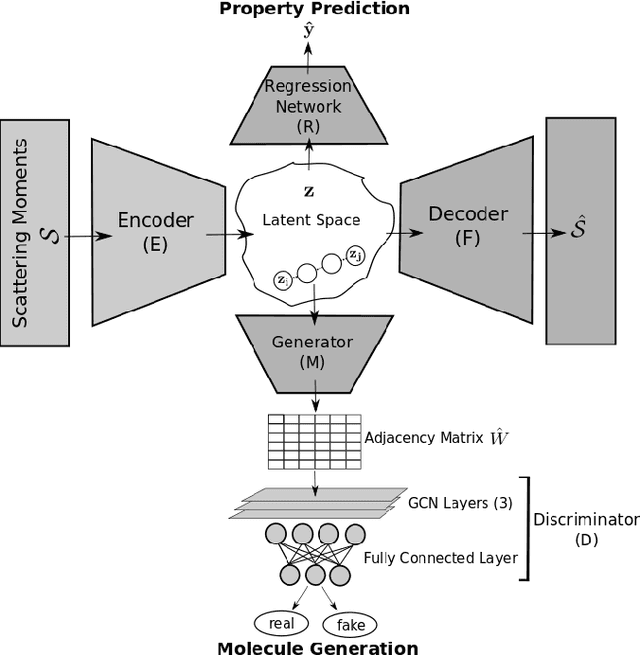
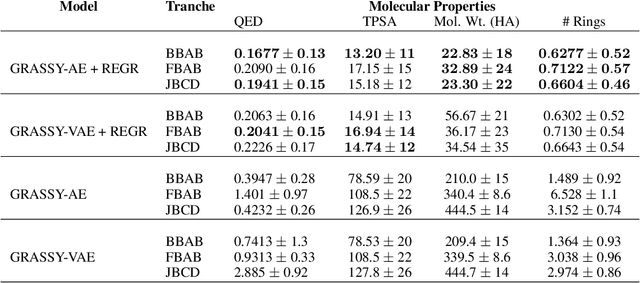
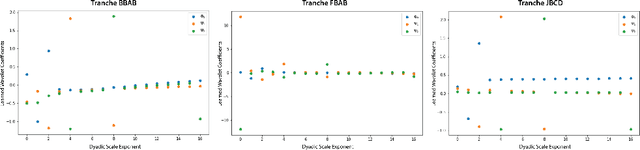
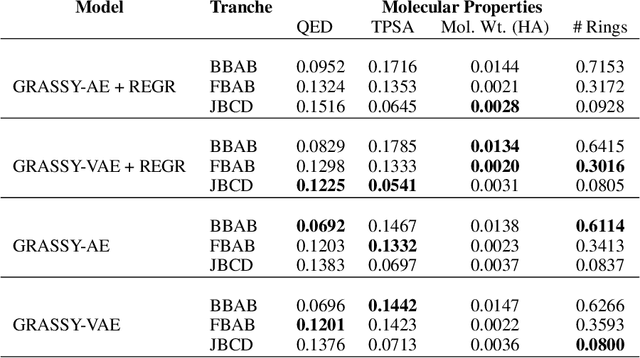
Graph neural networks (GNNs) have been used extensively for addressing problems in drug design and discovery. Both ligand and target molecules are represented as graphs with node and edge features encoding information about atomic elements and bonds respectively. Although existing deep learning models perform remarkably well at predicting physicochemical properties and binding affinities, the generation of new molecules with optimized properties remains challenging. Inherently, most GNNs perform poorly in whole-graph representation due to the limitations of the message-passing paradigm. Furthermore, step-by-step graph generation frameworks that use reinforcement learning or other sequential processing can be slow and result in a high proportion of invalid molecules with substantial post-processing needed in order to satisfy the principles of stoichiometry. To address these issues, we propose a representation-first approach to molecular graph generation. We guide the latent representation of an autoencoder by capturing graph structure information with the geometric scattering transform and apply penalties that structure the representation also by molecular properties. We show that this highly structured latent space can be directly used for molecular graph generation by the use of a GAN. We demonstrate that our architecture learns meaningful representations of drug datasets and provides a platform for goal-directed drug synthesis.
Learning to Bid in Contextual First Price Auctions
Sep 07, 2021In this paper, we investigate the problem about how to bid in repeated contextual first price auctions. We consider a single bidder (learner) who repeatedly bids in the first price auctions: at each time $t$, the learner observes a context $x_t\in \mathbb{R}^d$ and decides the bid based on historical information and $x_t$. We assume a structured linear model of the maximum bid of all the others $m_t = \alpha_0\cdot x_t + z_t$, where $\alpha_0\in \mathbb{R}^d$ is unknown to the learner and $z_t$ is randomly sampled from a noise distribution $\mathcal{F}$ with log-concave density function $f$. We consider both \emph{binary feedback} (the learner can only observe whether she wins or not) and \emph{full information feedback} (the learner can observe $m_t$) at the end of each time $t$. For binary feedback, when the noise distribution $\mathcal{F}$ is known, we propose a bidding algorithm, by using maximum likelihood estimation (MLE) method to achieve at most $\widetilde{O}(\sqrt{\log(d) T})$ regret. Moreover, we generalize this algorithm to the setting with binary feedback and the noise distribution is unknown but belongs to a parametrized family of distributions. For the full information feedback with \emph{unknown} noise distribution, we provide an algorithm that achieves regret at most $\widetilde{O}(\sqrt{dT})$. Our approach combines an estimator for log-concave density functions and then MLE method to learn the noise distribution $\mathcal{F}$ and linear weight $\alpha_0$ simultaneously. We also provide a lower bound result such that any bidding policy in a broad class must achieve regret at least $\Omega(\sqrt{T})$, even when the learner receives the full information feedback and $\mathcal{F}$ is known.
Visual Sensation and Perception Computational Models for Deep Learning: State of the art, Challenges and Prospects
Sep 08, 2021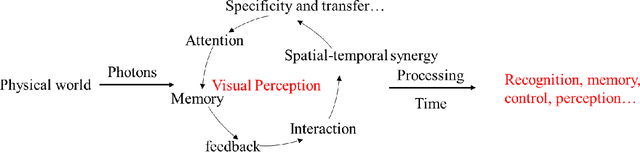
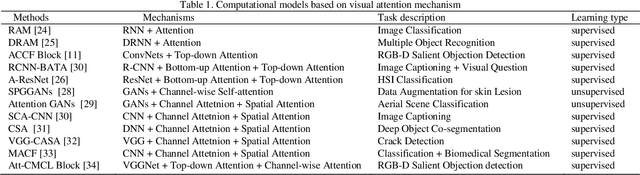
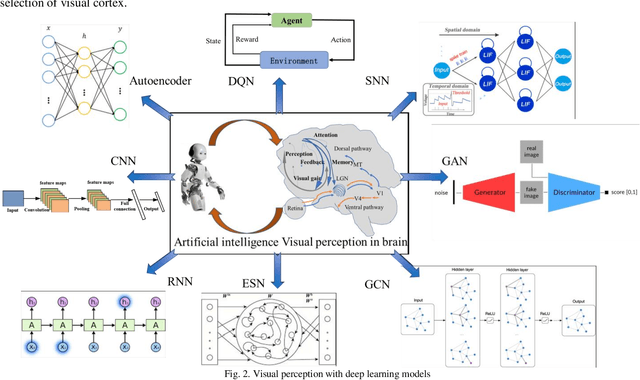

Visual sensation and perception refers to the process of sensing, organizing, identifying, and interpreting visual information in environmental awareness and understanding. Computational models inspired by visual perception have the characteristics of complexity and diversity, as they come from many subjects such as cognition science, information science, and artificial intelligence. In this paper, visual perception computational models oriented deep learning are investigated from the biological visual mechanism and computational vision theory systematically. Then, some points of view about the prospects of the visual perception computational models are presented. Finally, this paper also summarizes the current challenges of visual perception and predicts its future development trends. Through this survey, it will provide a comprehensive reference for research in this direction.
Event-guided Deblurring of Unknown Exposure Time Videos
Dec 13, 2021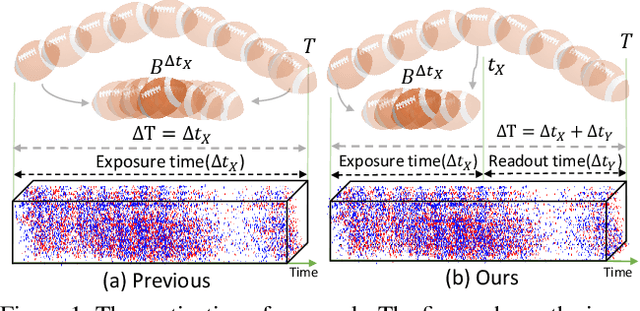

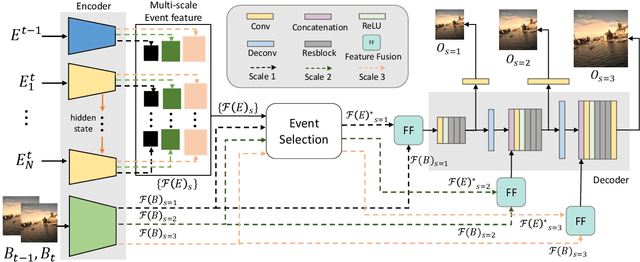
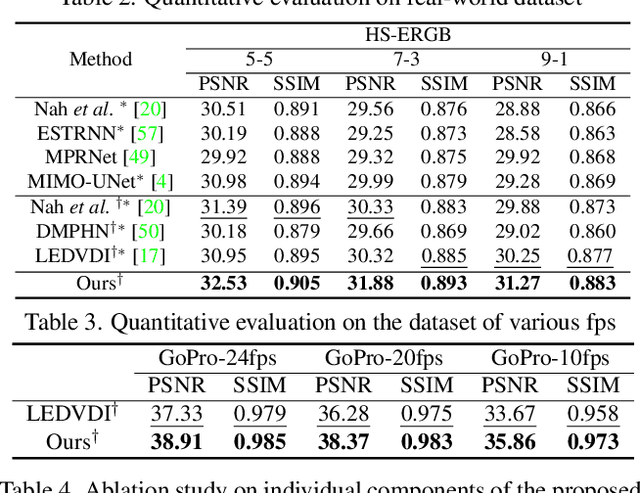
Video deblurring is a highly ill-posed problem due to the loss of motion information in the blur degradation process. Since event cameras can capture apparent motion with a high temporal resolution, several attempts have explored the potential of events for guiding video deblurring. These methods generally assume that the exposure time is the same as the reciprocal of the video frame rate. However,this is not true in real situations, and the exposure time might be unknown and dynamically varies depending on the video shooting environment(e.g., illumination condition). In this paper, we address the event-guided video deblurring assuming dynamically variable unknown exposure time of the frame-based camera. To this end, we first derive a new formulation for event-guided video deblurring by considering the exposure and readout time in the video frame acquisition process. We then propose a novel end-toend learning framework for event-guided video deblurring. In particular, we design a novel Exposure Time-based Event Selection(ETES) module to selectively use event features by estimating the cross-modal correlation between the features from blurred frames and the events. Moreover, we propose a feature fusion module to effectively fuse the selected features from events and blur frames. We conduct extensive experiments on various datasets and demonstrate that our method achieves state-of-the-art performance. Our project code and pretrained models will be available.
Private and polynomial time algorithms for learning Gaussians and beyond
Nov 22, 2021We present a fairly general framework for reducing $(\varepsilon, \delta)$ differentially private (DP) statistical estimation to its non-private counterpart. As the main application of this framework, we give a polynomial time and $(\varepsilon,\delta)$-DP algorithm for learning (unrestricted) Gaussian distributions in $\mathbb{R}^d$. The sample complexity of our approach for learning the Gaussian up to total variation distance $\alpha$ is $\widetilde{O}\left(\frac{d^2}{\alpha^2}+\frac{d^2 \sqrt{\ln{1/\delta}}}{\alpha\varepsilon} \right)$, matching (up to logarithmic factors) the best known information-theoretic (non-efficient) sample complexity upper bound of Aden-Ali, Ashtiani, Kamath~(ALT'21). In an independent work, Kamath, Mouzakis, Singhal, Steinke, and Ullman~(arXiv:2111.04609) proved a similar result using a different approach and with $O(d^{5/2})$ sample complexity dependence on $d$. As another application of our framework, we provide the first polynomial time $(\varepsilon, \delta)$-DP algorithm for robust learning of (unrestricted) Gaussians.
DenseGAP: Graph-Structured Dense Correspondence Learning with Anchor Points
Dec 13, 2021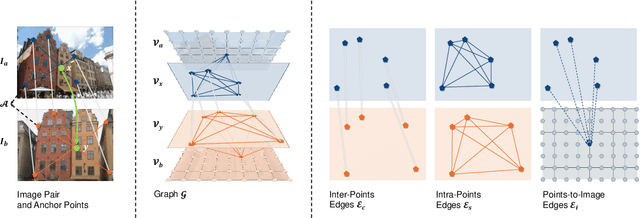
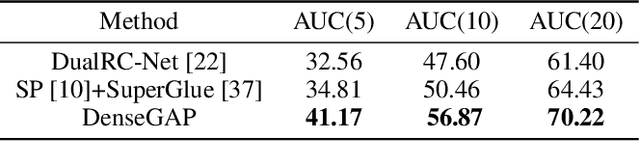

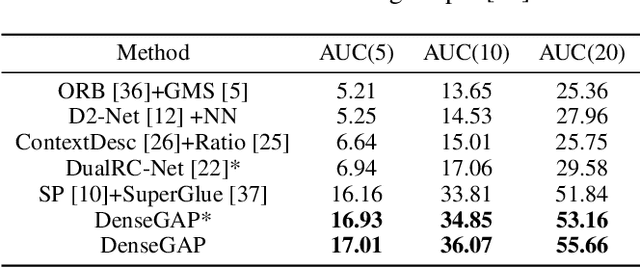
Establishing dense correspondence between two images is a fundamental computer vision problem, which is typically tackled by matching local feature descriptors. However, without global awareness, such local features are often insufficient for disambiguating similar regions. And computing the pairwise feature correlation across images is both computation-expensive and memory-intensive. To make the local features aware of the global context and improve their matching accuracy, we introduce DenseGAP, a new solution for efficient Dense correspondence learning with a Graph-structured neural network conditioned on Anchor Points. Specifically, we first propose a graph structure that utilizes anchor points to provide sparse but reliable prior on inter- and intra-image context and propagates them to all image points via directed edges. We also design a graph-structured network to broadcast multi-level contexts via light-weighted message-passing layers and generate high-resolution feature maps at low memory cost. Finally, based on the predicted feature maps, we introduce a coarse-to-fine framework for accurate correspondence prediction using cycle consistency. Our feature descriptors capture both local and global information, thus enabling a continuous feature field for querying arbitrary points at high resolution. Through comprehensive ablative experiments and evaluations on large-scale indoor and outdoor datasets, we demonstrate that our method advances the state-of-the-art of correspondence learning on most benchmarks.