 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DORA: Distributed Online Risk-Aware Explorer
Sep 29, 2021
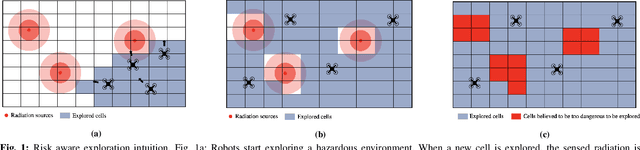
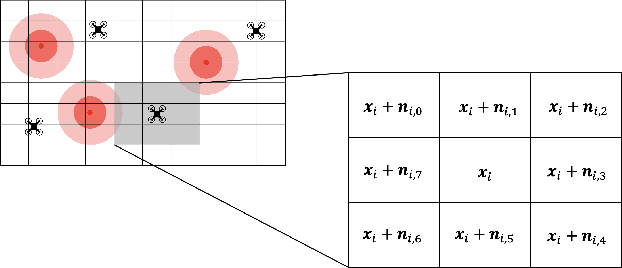

Exploration of unknown environments is an important challenge in the field of robotics. While a single robot can achieve this task alone, evidence suggests it could be accomplished more efficiently by groups of robots, with advantages in terms of terrain coverage as well as robustness to failures. Exploration can be guided through belief maps, which provide probabilistic information about which part of the terrain is interesting to explore (either based on risk management or reward). This process can be centrally coordinated by building a collective belief map on a common server. However, relying on a central processing station creates a communication bottleneck and single point of failure for the system. In this paper, we present Distributed Online Risk-Aware (DORA) Explorer, an exploration system that leverages decentralized information sharing to update a common risk belief map. DORA Explorer allows a group of robots to explore an unknown environment discretized as a 2D grid with obstacles, with high coverage while minimizing exposure to risk, effectively reducing robot failures
Joint speaker diarisation and tracking in switching state-space model
Sep 23, 2021

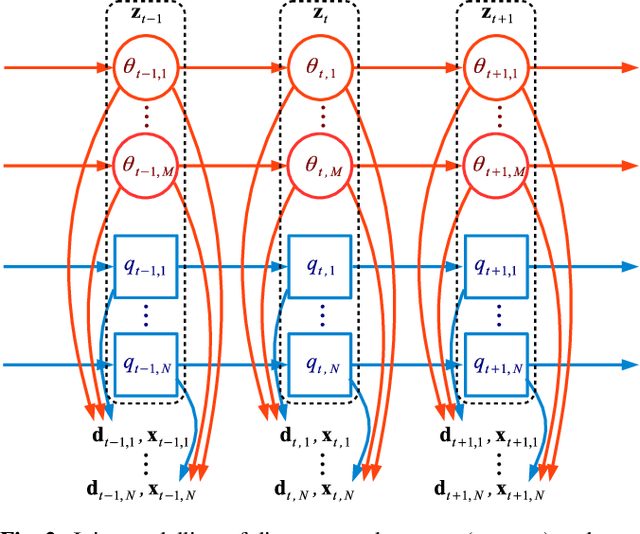
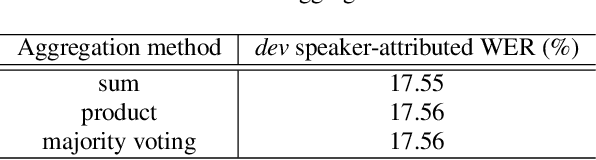
Speakers may move around while diarisation is being performed. When a microphone array is used, the instantaneous locations of where the sounds originated from can be estimated, and previous investigations have shown that such information can be complementary to speaker embeddings in the diarisation task. However, these approaches often assume that speakers are fairly stationary throughout a meeting. This paper relaxes this assumption, by proposing to explicitly track the movements of speakers while jointly performing diarisation within a unified model. A state-space model is proposed, where the hidden state expresses the identity of the current active speaker and the predicted locations of all speakers. The model is implemented as a particle filter. Experiments on a Microsoft rich meeting transcription task show that the proposed joint location tracking and diarisation approach is able to perform comparably with other methods that use location information.
Event-guided Deblurring of Unknown Exposure Time Videos
Dec 17, 2021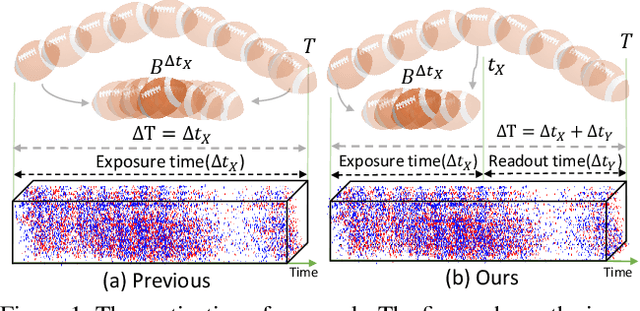

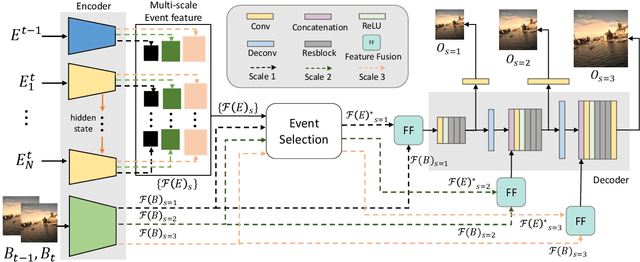
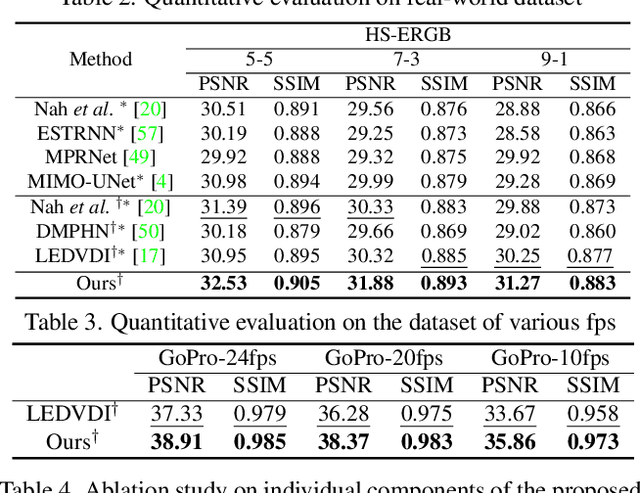
Video deblurring is a highly ill-posed problem due to the loss of motion information in the blur degradation process. Since event cameras can capture apparent motion with a high temporal resolution, several attempts have explored the potential of events for guiding video deblurring. These methods generally assume that the exposure time is the same as the reciprocal of the video frame rate. However,this is not true in real situations, and the exposure time might be unknown and dynamically varies depending on the video shooting environment(e.g., illumination condition). In this paper, we address the event-guided video deblurring assuming dynamically variable unknown exposure time of the frame-based camera. To this end, we first derive a new formulation for event-guided video deblurring by considering the exposure and readout time in the video frame acquisition process. We then propose a novel end-toend learning framework for event-guided video deblurring. In particular, we design a novel Exposure Time-based Event Selection(ETES) module to selectively use event features by estimating the cross-modal correlation between the features from blurred frames and the events. Moreover, we propose a feature fusion module to effectively fuse the selected features from events and blur frames. We conduct extensive experiments on various datasets and demonstrate that our method achieves state-of-the-art performance. Our project code and pretrained models will be available.
Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition
Nov 16, 2021Due to the recent advances of natural language processing, several works have applied the pre-trained masked language model (MLM) of BERT to the post-correction of speech recognition. However, existing pre-trained models only consider the semantic correction while the phonetic features of words is neglected. The semantic-only post-correction will consequently decrease the performance since homophonic errors are fairly common in Chinese ASR. In this paper, we proposed a novel approach to collectively exploit the contextualized representation and the phonetic information between the error and its replacing candidates to alleviate the error rate of Chinese ASR. Our experiment results on real world speech recognition datasets showed that our proposed method has evidently lower CER than the baseline model, which utilized a pre-trained BERT MLM as the corrector.
Outage Analysis over Correlated Fisher-Snedecor F Fading Multi-User Channels
Nov 12, 2021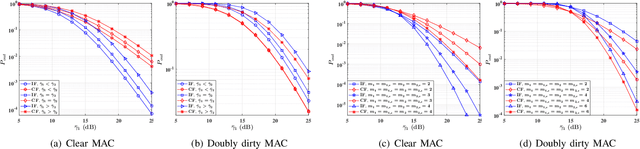

In this paper, we investigate the impact of correlated fading on the performance of wireless multiple access channels (MAC) in the presence and absence of side information (SI) at transmitters, where the fading coefficients are modeled according to the Fisher-Snedecor F distribution. Specifically, we represent two scenarios: (i) clear MAC (i.e, without SI at transmitters), (ii) doubly dirty MAC (i.e., with the non-causally known SI at transmitters). For both system models, we derive the closed-form expressions for the outage probability in independent fading conditions. Besides, exploiting copula theory, we obtain exact analytical expressions for the outage probability under the positive dependence fading conditions in both considered models. Finally, the efficiency of the analytical results is illustrated numerically.
Gradient and Projection Free Distributed Online Min-Max Resource Optimization
Dec 07, 2021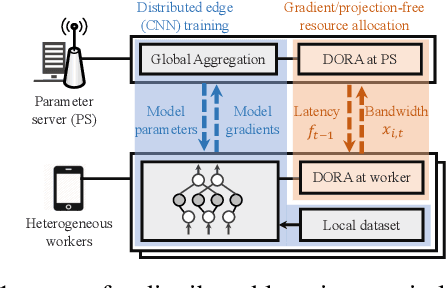
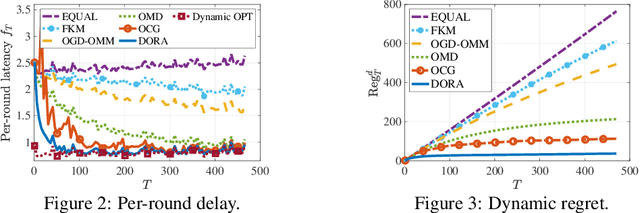
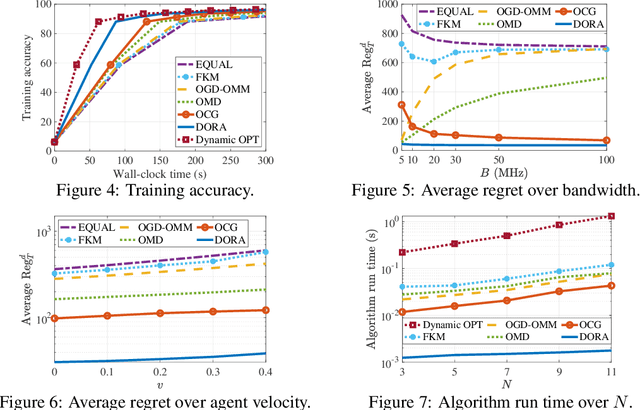
We consider distributed online min-max resource allocation with a set of parallel agents and a parameter server. Our goal is to minimize the pointwise maximum over a set of time-varying convex and decreasing cost functions, without a priori information about these functions. We propose a novel online algorithm, termed Distributed Online resource Re-Allocation (DORA), where non-stragglers learn to relinquish resource and share resource with stragglers. A notable feature of DORA is that it does not require gradient calculation or projection operation, unlike most existing online optimization strategies. This allows it to substantially reduce the computation overhead in large-scale and distributed networks. We show that the dynamic regret of the proposed algorithm is upper bounded by $O\left(T^{\frac{3}{4}}(1+P_T)^{\frac{1}{4}}\right)$, where $T$ is the total number of rounds and $P_T$ is the path-length of the instantaneous minimizers. We further consider an application to the bandwidth allocation problem in distributed online machine learning. Our numerical study demonstrates the efficacy of the proposed solution and its performance advantage over gradient- and/or projection-based resource allocation algorithms in reducing wall-clock time.
Deep covariate-learning: optimising information extraction from terrain texture for geostatistical modelling applications
May 22, 2020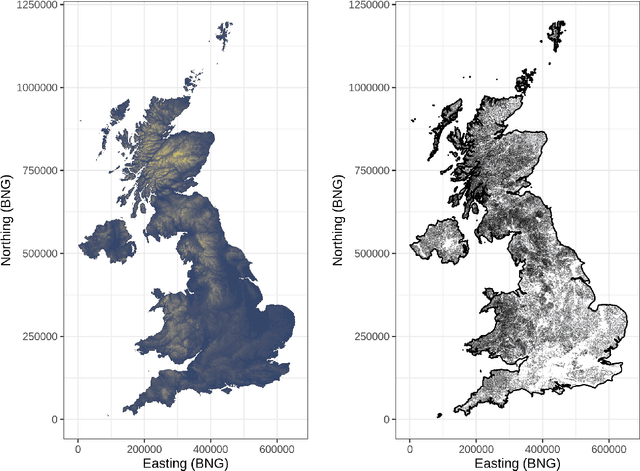
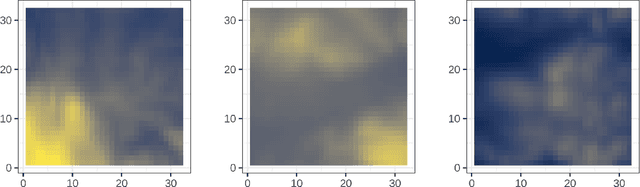
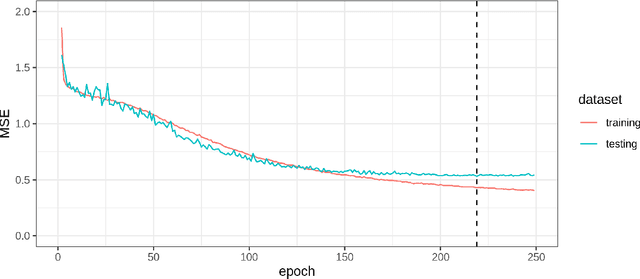
Where data is available, it is desirable in geostatistical modelling to make use of additional covariates, for example terrain data, in order to improve prediction accuracy in the modelling task. While elevation itself may be important, additional explanatory power for any given problem can be sought (but not necessarily found) by filtering digital elevation models to extact higher-order derivatives such as slope angles, curvatures, and roughness. In essence, it would be beneficial to extract as much task-relevant information as possible from the elevation grid. However, given the complexities of the natural world, chance dictates that the use of 'off-the-shelf' filters is unlikely to derive covariates that provide strong explanatory power to the target variable at hand, and any attempt to manually design informative covariates is likely to be a trial-and-error process -- not optimal. In this paper we present a solution to this problem in the form of a deep learning approach to automatically deriving optimal task-specific terrain texture covariates from a standard SRTM 90m gridded digital elevation model (DEM). For our target variables we use point-sampled geochemical data from the British Geological Survey: concentrations of potassium, calcium and arsenic in stream sediments. We find that our deep learning approach produces covariates for geostatistical modelling that have surprisingly strong explanatory power on their own, with R-squared values around 0.6 for all three elements (with arsenic on the log scale). These results are achieved without the neural network being provided with easting, northing, or absolute elevation as inputs, and purely reflect the capacity of our deep neural network to extract task-specific information from terrain texture. We hope that these results will inspire further investigation into the capabilities of deep learning within geostatistical applications.
Deep Learning for automated phase segmentation in EBSD maps. A case study in Dual Phase steel microstructures
Nov 26, 2021
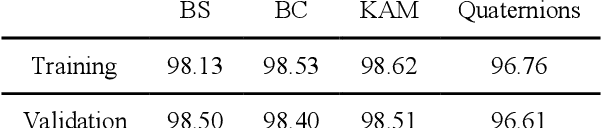
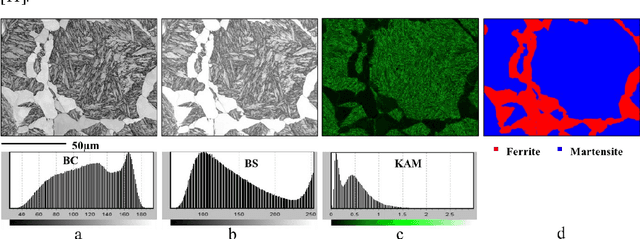
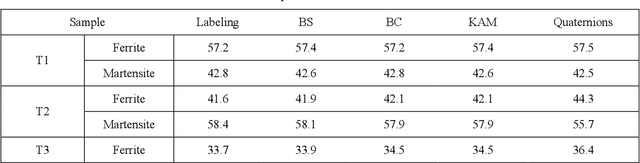
Electron Backscattering Diffraction (EBSD) provides important information to discriminate phase transformation products in steels. This task is conventionally performed by an expert, who carries a high degree of subjectivity and requires time and effort. In this paper, we question if Convolutional Neural Networks (CNNs) are able to extract meaningful features from EBSD-based data in order to automatically classify the present phases within a steel microstructure. The selected case of study is ferrite-martensite discrimination and U-Net has been selected as the network architecture to work with. Pixel-wise accuracies around ~95% have been obtained when inputting raw orientation data, while ~98% has been reached with orientation-derived parameters such as Kernel Average Misorientation (KAM) or pattern quality. Compared to other available approaches in the literature for phase discrimination, the models presented here provided higher accuracies in shorter times. These promising results open a possibility to work on more complex steel microstructures.
TransMEF: A Transformer-Based Multi-Exposure Image Fusion Framework using Self-Supervised Multi-Task Learning
Dec 02, 2021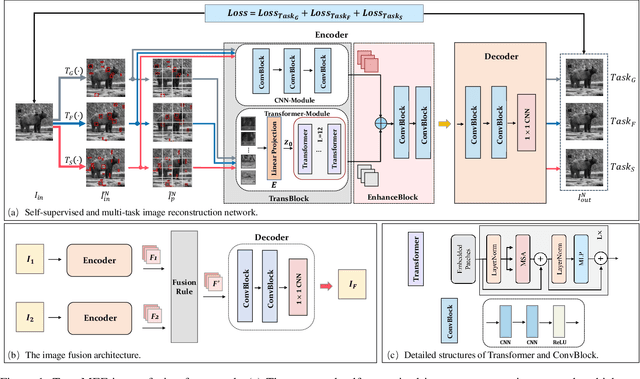
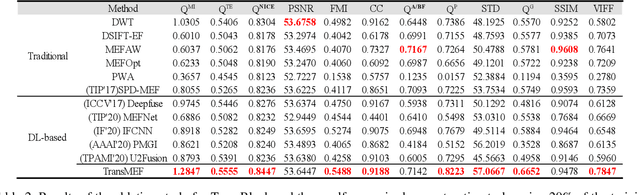


In this paper, we propose TransMEF, a transformer-based multi-exposure image fusion framework that uses self-supervised multi-task learning. The framework is based on an encoder-decoder network, which can be trained on large natural image datasets and does not require ground truth fusion images. We design three self-supervised reconstruction tasks according to the characteristics of multi-exposure images and conduct these tasks simultaneously using multi-task learning; through this process, the network can learn the characteristics of multi-exposure images and extract more generalized features. In addition, to compensate for the defect in establishing long-range dependencies in CNN-based architectures, we design an encoder that combines a CNN module with a transformer module. This combination enables the network to focus on both local and global information. We evaluated our method and compared it to 11 competitive traditional and deep learning-based methods on the latest released multi-exposure image fusion benchmark dataset, and our method achieved the best performance in both subjective and objective evaluations.
Bayesian Persuasion for Algorithmic Recourse
Dec 12, 2021
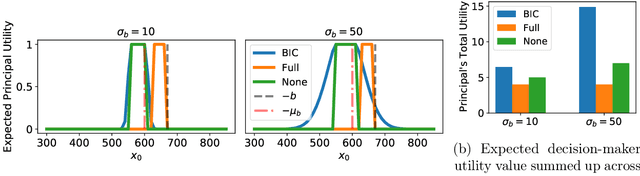
When subjected to automated decision-making, decision-subjects will strategically modify their observable features in ways they believe will maximize their chances of receiving a desirable outcome. In many situations, the underlying predictive model is deliberately kept secret to avoid gaming and maintain competitive advantage. This opacity forces the decision subjects to rely on incomplete information when making strategic feature modifications. We capture such settings as a game of Bayesian persuasion, in which the decision-maker sends a signal, e.g., an action recommendation, to a decision subject to incentivize them to take desirable actions. We formulate the decision-maker's problem of finding the optimal Bayesian incentive-compatible (BIC) action recommendation policy as an optimization problem and characterize the solution via a linear program. Through this characterization, we observe that while the problem of finding the optimal BIC recommendation policy can be simplified dramatically, the computational complexity of solving this linear program is closely tied to (1) the relative size of the decision-subjects' action space, and (2) the number of features utilized by the underlying predictive model. Finally, we provide bounds on the performance of the optimal BIC recommendation policy and show that it can lead to arbitrarily better outcomes compared to standard baselines.