 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperRAG: Reasoning N-ary Facts over Hypergraphs for Retrieval Augmented Generation
Feb 16, 2026Graph-based retrieval-augmented generation (RAG) methods, typically built on knowledge graphs (KGs) with binary relational facts, have shown promise in multi-hop open-domain QA. However, their rigid retrieval schemes and dense similarity search often introduce irrelevant context, increase computational overhead, and limit relational expressiveness. In contrast, n-ary hypergraphs encode higher-order relational facts that capture richer inter-entity dependencies and enable shallower, more efficient reasoning paths. To address this limitation, we propose HyperRAG, a RAG framework tailored for n-ary hypergraphs with two complementary retrieval variants: (i) HyperRetriever learns structural-semantic reasoning over n-ary facts to construct query-conditioned relational chains. It enables accurate factual tracking, adaptive high-order traversal, and interpretable multi-hop reasoning under context constraints. (ii) HyperMemory leverages the LLM's parametric memory to guide beam search, dynamically scoring n-ary facts and entities for query-aware path expansion. Extensive evaluations on WikiTopics (11 closed-domain datasets) and three open-domain QA benchmarks (HotpotQA, MuSiQue, and 2WikiMultiHopQA) validate HyperRAG's effectiveness. HyperRetriever achieves the highest answer accuracy overall, with average gains of 2.95% in MRR and 1.23% in Hits@10 over the strongest baseline. Qualitative analysis further shows that HyperRetriever bridges reasoning gaps through adaptive and interpretable n-ary chain construction, benefiting both open and closed-domain QA.
Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition
Nov 16, 2021Due to the recent advances of natural language processing, several works have applied the pre-trained masked language model (MLM) of BERT to the post-correction of speech recognition. However, existing pre-trained models only consider the semantic correction while the phonetic features of words is neglected. The semantic-only post-correction will consequently decrease the performance since homophonic errors are fairly common in Chinese ASR. In this paper, we proposed a novel approach to collectively exploit the contextualized representation and the phonetic information between the error and its replacing candidates to alleviate the error rate of Chinese ASR. Our experiment results on real world speech recognition datasets showed that our proposed method has evidently lower CER than the baseline model, which utilized a pre-trained BERT MLM as the corrector.
Human Activity Recognition using Smartphone
Jan 30, 2014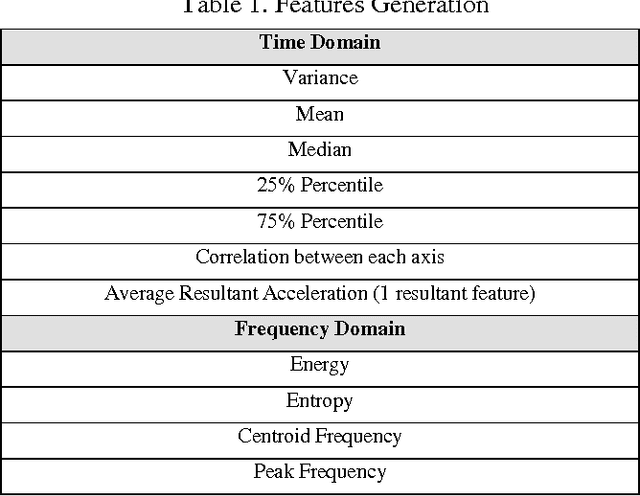
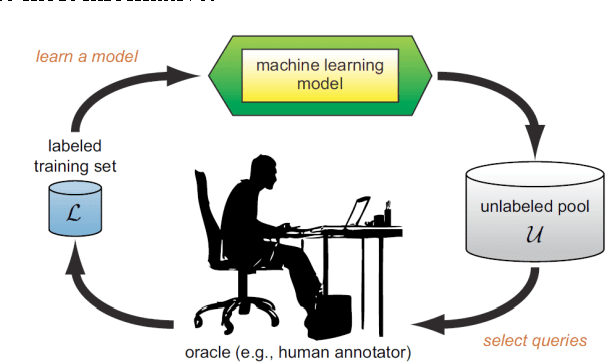
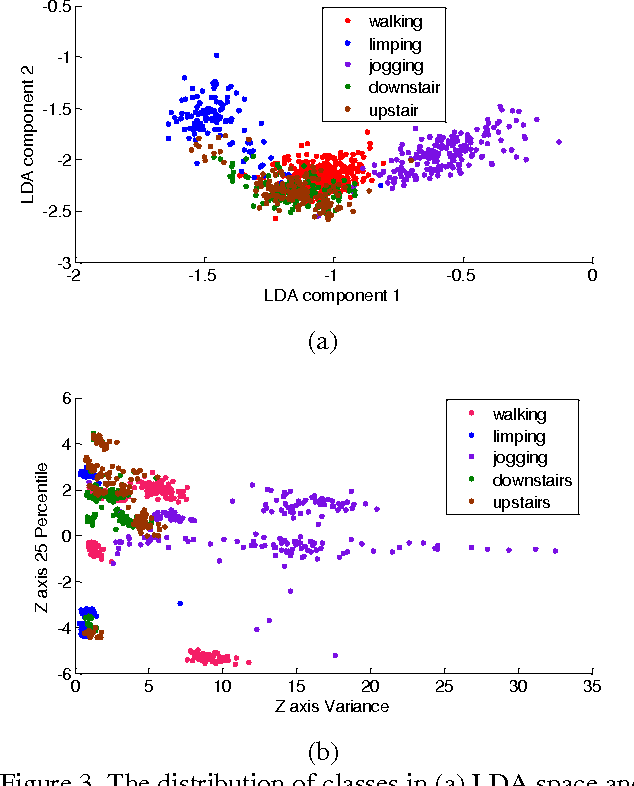
Human activity recognition has wide applications in medical research and human survey system. In this project, we design a robust activity recognition system based on a smartphone. The system uses a 3-dimentional smartphone accelerometer as the only sensor to collect time series signals, from which 31 features are generated in both time and frequency domain. Activities are classified using 4 different passive learning methods, i.e., quadratic classifier, k-nearest neighbor algorithm, support vector machine, and artificial neural networks. Dimensionality reduction is performed through both feature extraction and subset selection. Besides passive learning, we also apply active learning algorithms to reduce data labeling expense. Experiment results show that the classification rate of passive learning reaches 84.4% and it is robust to common positions and poses of cellphone. The results of active learning on real data demonstrate a reduction of labeling labor to achieve comparable performance with passive learning.