 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Iteratively Selecting an Easy Reference Frame Makes Unsupervised Video Object Segmentation Easier
Dec 23, 2021
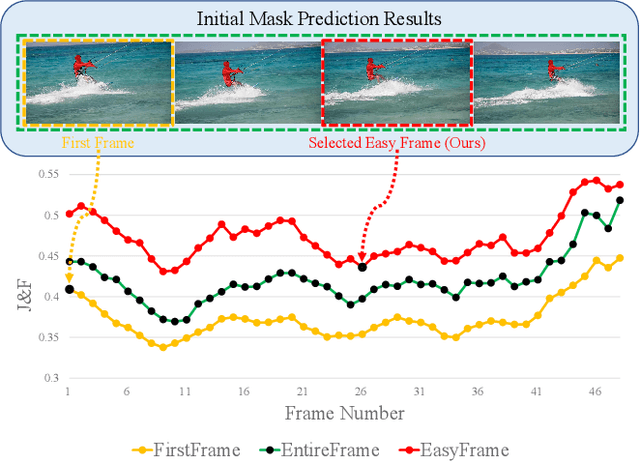
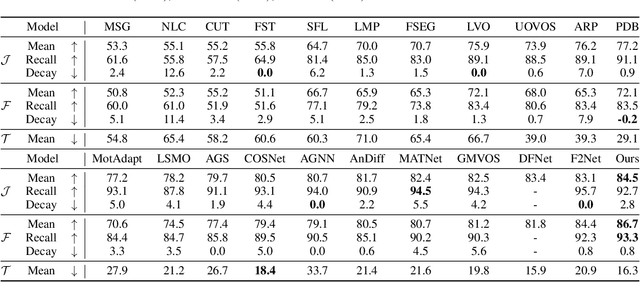


Unsupervised video object segmentation (UVOS) is a per-pixel binary labeling problem which aims at separating the foreground object from the background in the video without using the ground truth (GT) mask of the foreground object. Most of the previous UVOS models use the first frame or the entire video as a reference frame to specify the mask of the foreground object. Our question is why the first frame should be selected as a reference frame or why the entire video should be used to specify the mask. We believe that we can select a better reference frame to achieve the better UVOS performance than using only the first frame or the entire video as a reference frame. In our paper, we propose Easy Frame Selector (EFS). The EFS enables us to select an 'easy' reference frame that makes the subsequent VOS become easy, thereby improving the VOS performance. Furthermore, we propose a new framework named as Iterative Mask Prediction (IMP). In the framework, we repeat applying EFS to the given video and selecting an 'easier' reference frame from the video than the previous iteration, increasing the VOS performance incrementally. The IMP consists of EFS, Bi-directional Mask Prediction (BMP), and Temporal Information Updating (TIU). From the proposed framework, we achieve state-of-the-art performance in three UVOS benchmark sets: DAVIS16, FBMS, and SegTrack-V2.
A novel multi-view deep learning approach for BI-RADS and density assessment of mammograms
Dec 08, 2021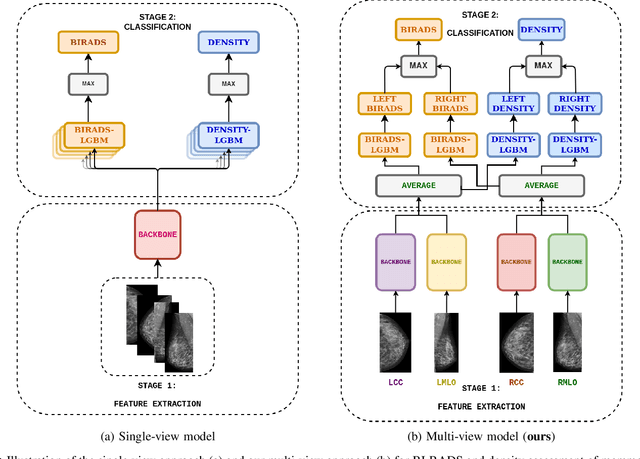

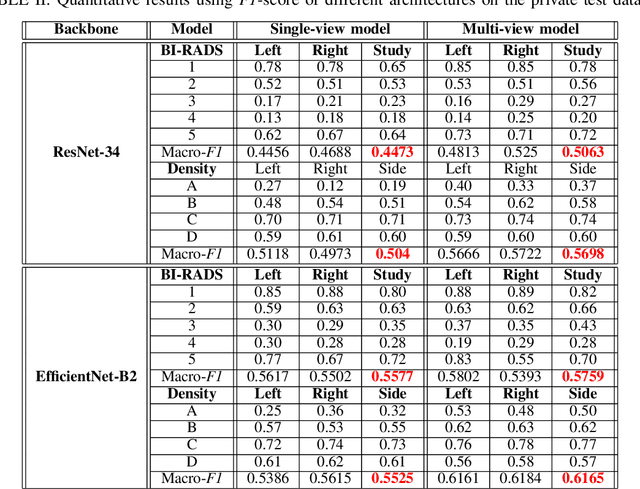
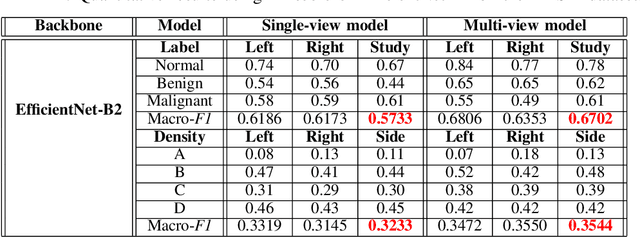
Advanced deep learning (DL) algorithms may predict the patient's risk of developing breast cancer based on the Breast Imaging Reporting and Data System (BI-RADS) and density standards. Recent studies have suggested that the combination of multi-view analysis improved the overall breast exam classification. In this paper, we propose a novel multi-view DL approach for BI-RADS and density assessment of mammograms. The proposed approach first deploys deep convolutional networks for feature extraction on each view separately. The extracted features are then stacked and fed into a Light Gradient Boosting Machine (LightGBM) classifier to predict BI-RADS and density scores. We conduct extensive experiments on both the internal mammography dataset and the public dataset Digital Database for Screening Mammography (DDSM). The experimental results demonstrate that the proposed approach outperforms the single-view classification approach on two benchmark datasets by huge margins (5% on the internal dataset and 10% on the DDSM dataset). These results highlight the vital role of combining multi-view information to improve the performance of breast cancer risk prediction.
BuildFormer: Automatic building extraction with vision transformer
Nov 29, 2021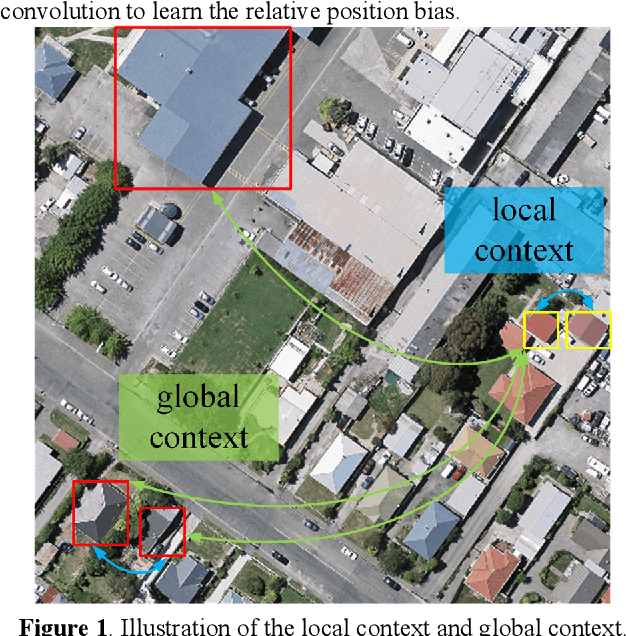
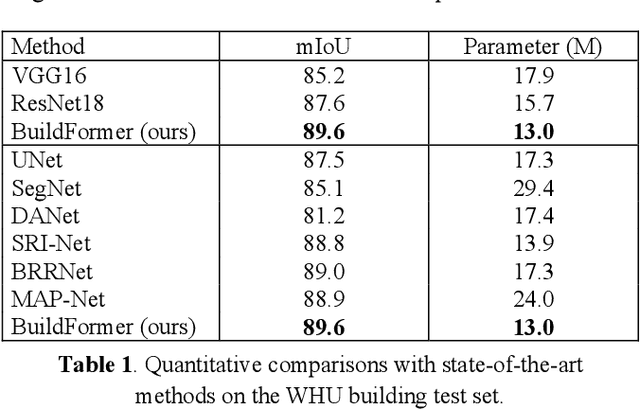
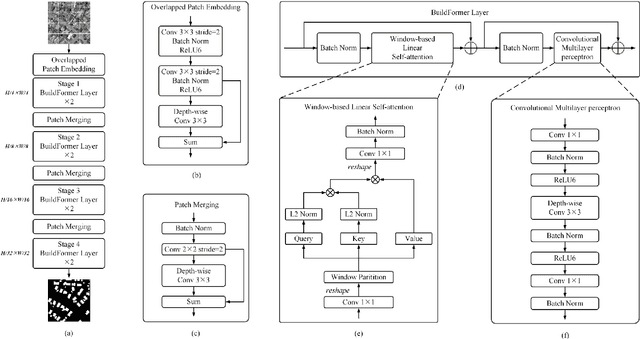
Building extraction from fine-resolution remote sensing images plays a vital role in numerous geospatial applications, such as urban planning, population statistic, economic assessment and disaster management. With the advancement of deep learning technology, deep convolutional neural networks (DCNNs) have dominated the automatic building extraction task for many years. However, the local property of DCNNs limits the extraction of global information, weakening the ability of the network for recognizing the building instance. Recently, the Transformer comprises a hot topic in the computer vision domain and achieves state-of-the-art performance in fundamental vision tasks, such as image classification, semantic segmentation and object detection. Inspired by this, in this paper, we propose a novel transformer-based network for extracting buildings from fine-resolution remote sensing images, namely BuildFormer. In Comparision with the ResNet, the proposed method achieves an improvement of 2% in mIoU on the WHU building dataset.
Improving Compound Activity Classification via Deep Transfer and Representation Learning
Nov 14, 2021
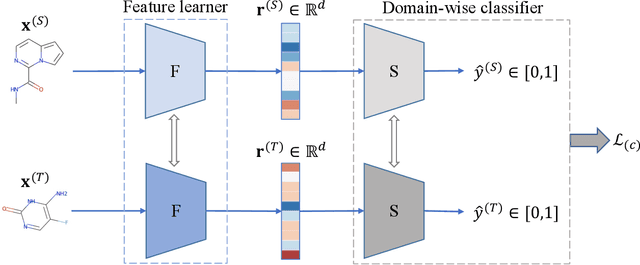
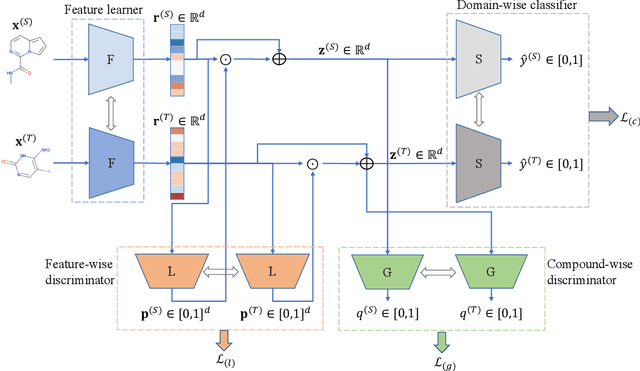
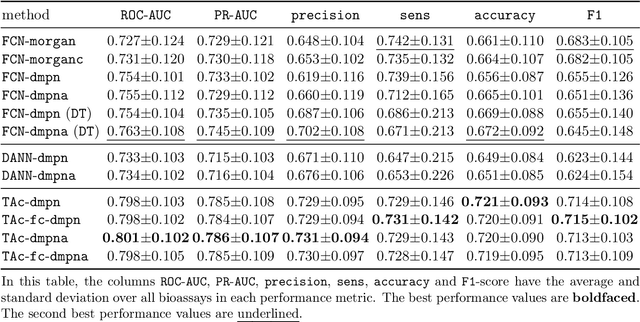
Recent advances in molecular machine learning, especially deep neural networks such as Graph Neural Networks (GNNs) for predicting structure activity relationships (SAR) have shown tremendous potential in computer-aided drug discovery. However, the applicability of such deep neural networks are limited by the requirement of large amounts of training data. In order to cope with limited training data for a target task, transfer learning for SAR modeling has been recently adopted to leverage information from data of related tasks. In this work, in contrast to the popular parameter-based transfer learning such as pretraining, we develop novel deep transfer learning methods TAc and TAc-fc to leverage source domain data and transfer useful information to the target domain. TAc learns to generate effective molecular features that can generalize well from one domain to another, and increase the classification performance in the target domain. Additionally, TAc-fc extends TAc by incorporating novel components to selectively learn feature-wise and compound-wise transferability. We used the bioassay screening data from PubChem, and identified 120 pairs of bioassays such that the active compounds in each pair are more similar to each other compared to its inactive compounds. Overall, TAc achieves the best performance with average ROC-AUC of 0.801; it significantly improves ROC-AUC of 83% target tasks with average task-wise performance improvement of 7.102%, compared to the best baseline FCN-dmpna (DT). Our experiments clearly demonstrate that TAc achieves significant improvement over all baselines across a large number of target tasks. Furthermore, although TAc-fc achieves slightly worse ROC-AUC on average compared to TAc (0.798 vs 0.801), TAc-fc still achieves the best performance on more tasks in terms of PR-AUC and F1 compared to other methods.
Improving traffic sign recognition by active search
Nov 29, 2021



We describe an iterative active-learning algorithm to recognise rare traffic signs. A standard ResNet is trained on a training set containing only a single sample of the rare class. We demonstrate that by sorting the samples of a large, unlabeled set by the estimated probability of belonging to the rare class, we can efficiently identify samples from the rare class. This works despite the fact that this estimated probability is usually quite low. A reliable active-learning loop is obtained by labeling these candidate samples, including them in the training set, and iterating the procedure. Further, we show that we get similar results starting from a single synthetic sample. Our results are important as they indicate a straightforward way of improving traffic-sign recognition for automated driving systems. In addition, they show that we can make use of the information hidden in low confidence outputs, which is usually ignored.
Computing Class Hierarchies from Classifiers
Dec 02, 2021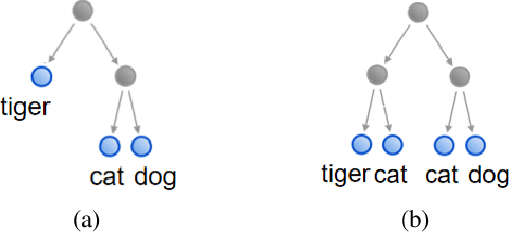
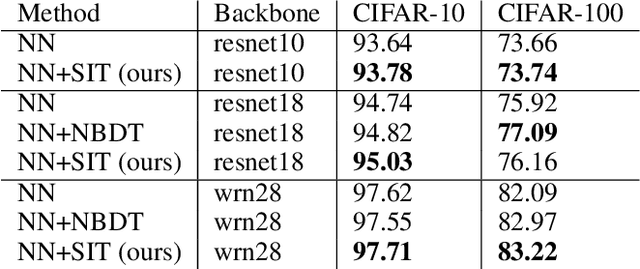
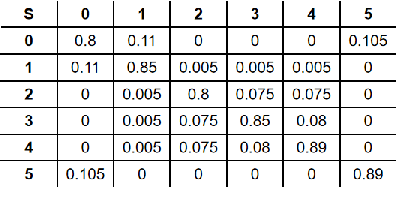

A class or taxonomic hierarchy is often manually constructed, and part of our knowledge about the world. In this paper, we propose a novel algorithm for automatically acquiring a class hierarchy from a classifier which is often a large neural network these days. The information that we need from a classifier is its confusion matrix which contains, for each pair of base classes, the number of errors the classifier makes by mistaking one for another. Our algorithm produces surprisingly good hierarchies for some well-known deep neural network models trained on the CIFAR-10 dataset, a neural network model for predicting the native language of a non-native English speaker, a neural network model for detecting the language of a written text, and a classifier for identifying music genre. In the literature, such class hierarchies have been used to provide interpretability to the neural networks. We also discuss some other potential uses of the acquired hierarchies.
Applying Surface Normal Information in Drivable Area and Road Anomaly Detection for Ground Mobile Robots
Aug 26, 2020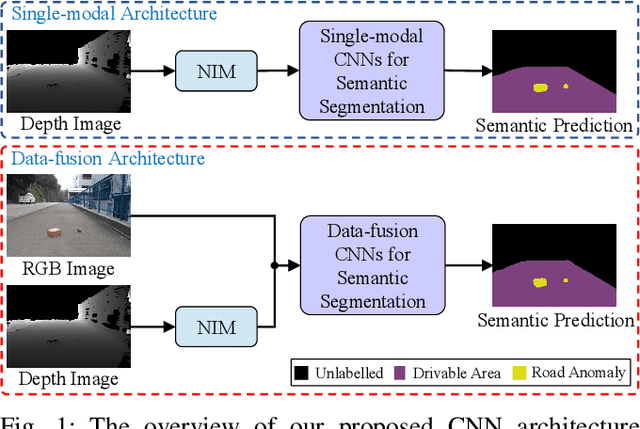
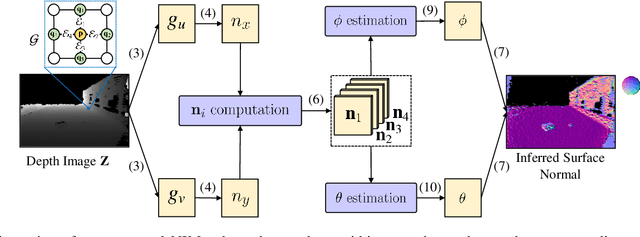
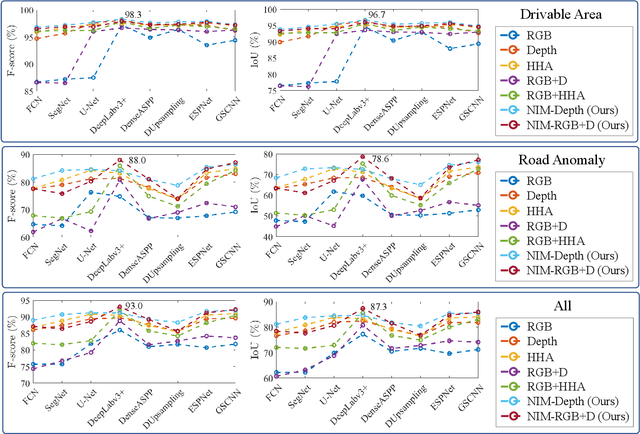
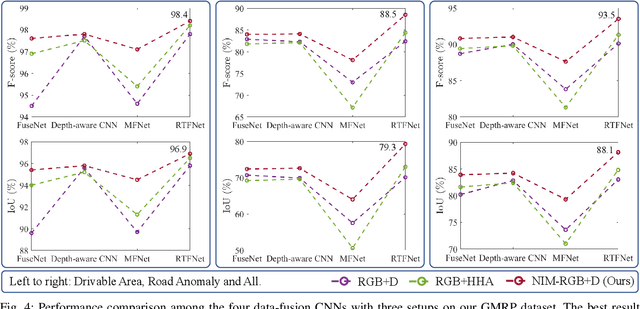
The joint detection of drivable areas and road anomalies is a crucial task for ground mobile robots. In recent years, many impressive semantic segmentation networks, which can be used for pixel-level drivable area and road anomaly detection, have been developed. However, the detection accuracy still needs improvement. Therefore, we develop a novel module named the Normal Inference Module (NIM), which can generate surface normal information from dense depth images with high accuracy and efficiency. Our NIM can be deployed in existing convolutional neural networks (CNNs) to refine the segmentation performance. To evaluate the effectiveness and robustness of our NIM, we embed it in twelve state-of-the-art CNNs. The experimental results illustrate that our NIM can greatly improve the performance of the CNNs for drivable area and road anomaly detection. Furthermore, our proposed NIM-RTFNet ranks 8th on the KITTI road benchmark and exhibits a real-time inference speed.
Detection of extragalactic Ultra-Compact Dwarfs and Globular Clusters using Explainable AI techniques
Jan 07, 2022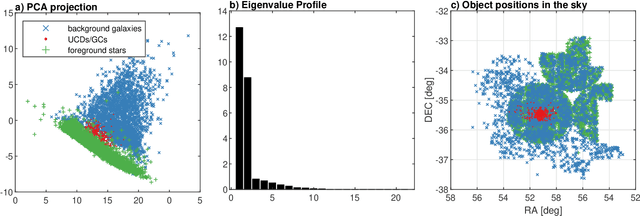
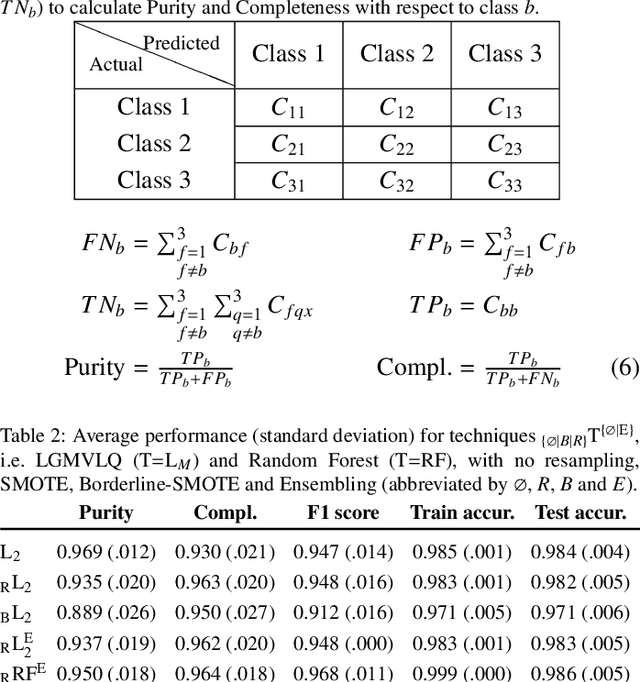
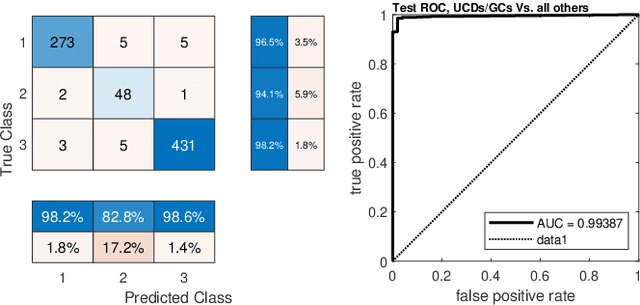
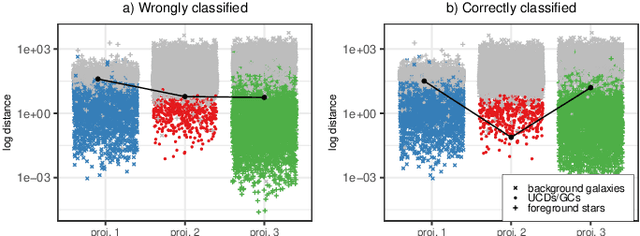
Compact stellar systems such as Ultra-compact dwarfs (UCDs) and Globular Clusters (GCs) around galaxies are known to be the tracers of the merger events that have been forming these galaxies. Therefore, identifying such systems allows to study galaxies mass assembly, formation and evolution. However, in the lack of spectroscopic information detecting UCDs/GCs using imaging data is very uncertain. Here, we aim to train a machine learning model to separate these objects from the foreground stars and background galaxies using the multi-wavelength imaging data of the Fornax galaxy cluster in 6 filters, namely u, g, r, i, J and Ks. The classes of objects are highly imbalanced which is problematic for many automatic classification techniques. Hence, we employ Synthetic Minority Over-sampling to handle the imbalance of the training data. Then, we compare two classifiers, namely Localized Generalized Matrix Learning Vector Quantization (LGMLVQ) and Random Forest (RF). Both methods are able to identify UCDs/GCs with a precision and a recall of >93 percent and provide relevances that reflect the importance of each feature dimension %(colors and angular sizes) for the classification. Both methods detect angular sizes as important markers for this classification problem. While it is astronomical expectation that color indices of u-i and i-Ks are the most important colors, our analysis shows that colors such as g-r are more informative, potentially because of higher signal-to-noise ratio. Besides the excellent performance the LGMLVQ method allows further interpretability by providing the feature importance for each individual class, class-wise representative samples and the possibility for non-linear visualization of the data as demonstrated in this contribution. We conclude that employing machine learning techniques to identify UCDs/GCs can lead to promising results.
Learners that Use Little Information
Feb 28, 2018We study learning algorithms that are restricted to using a small amount of information from their input sample. We introduce a category of learning algorithms we term $d$-bit information learners, which are algorithms whose output conveys at most $d$ bits of information of their input. A central theme in this work is that such algorithms generalize. We focus on the learning capacity of these algorithms, and prove sample complexity bounds with tight dependencies on the confidence and error parameters. We also observe connections with well studied notions such as sample compression schemes, Occam's razor, PAC-Bayes and differential privacy. We discuss an approach that allows us to prove upper bounds on the amount of information that algorithms reveal about their inputs, and also provide a lower bound by showing a simple concept class for which every (possibly randomized) empirical risk minimizer must reveal a lot of information. On the other hand, we show that in the distribution-dependent setting every VC class has empirical risk minimizers that do not reveal a lot of information.
Boosting Contrastive Learning with Relation Knowledge Distillation
Dec 08, 2021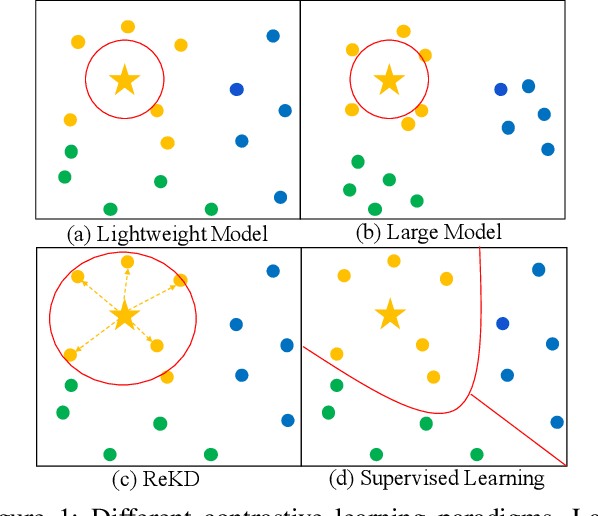
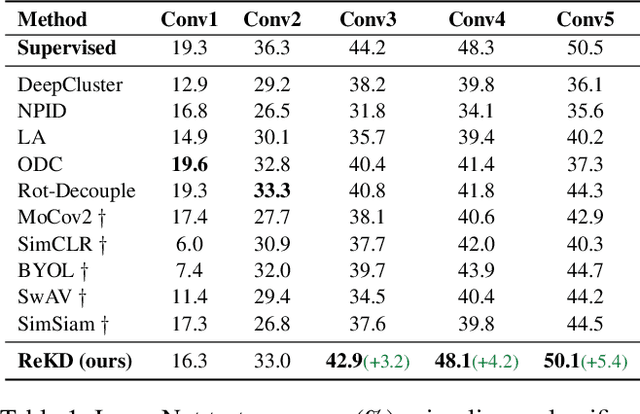
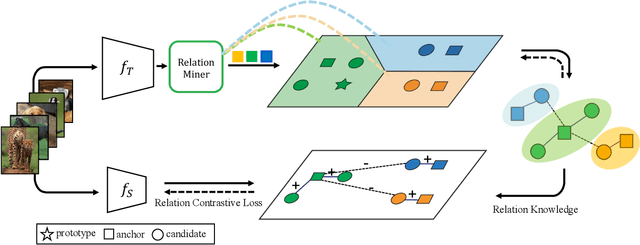
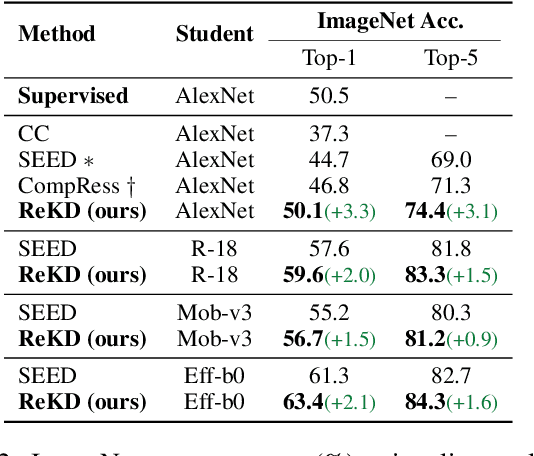
While self-supervised representation learning (SSL) has proved to be effective in the large model, there is still a huge gap between the SSL and supervised method in the lightweight model when following the same solution. We delve into this problem and find that the lightweight model is prone to collapse in semantic space when simply performing instance-wise contrast. To address this issue, we propose a relation-wise contrastive paradigm with Relation Knowledge Distillation (ReKD). We introduce a heterogeneous teacher to explicitly mine the semantic information and transferring a novel relation knowledge to the student (lightweight model). The theoretical analysis supports our main concern about instance-wise contrast and verify the effectiveness of our relation-wise contrastive learning. Extensive experimental results also demonstrate that our method achieves significant improvements on multiple lightweight models. Particularly, the linear evaluation on AlexNet obviously improves the current state-of-art from 44.7% to 50.1%, which is the first work to get close to the supervised 50.5%. Code will be made available.