 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reprogrammable Surfaces Through Star Graph Metamaterials
Dec 16, 2021
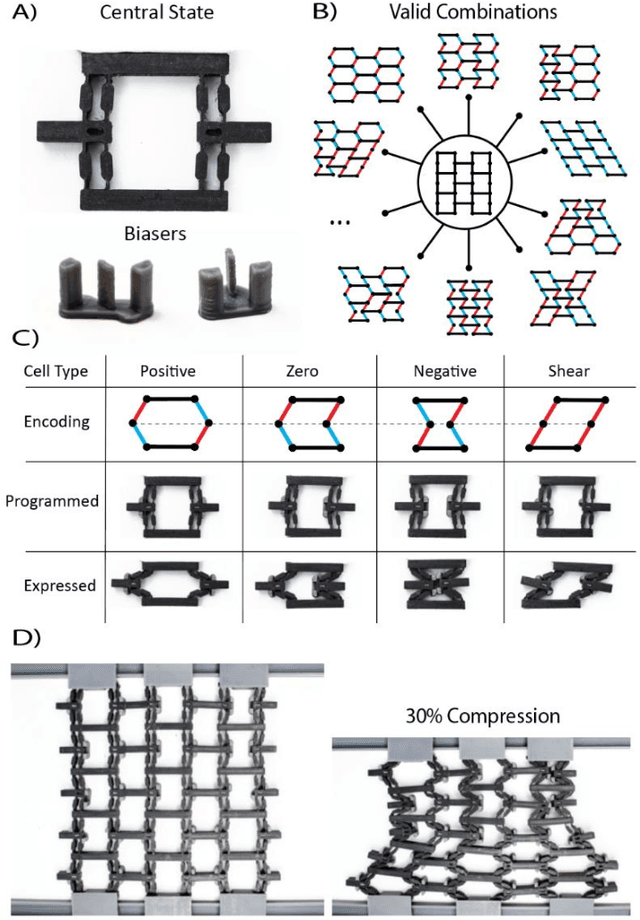
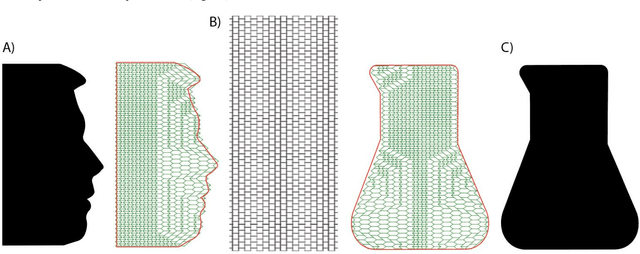

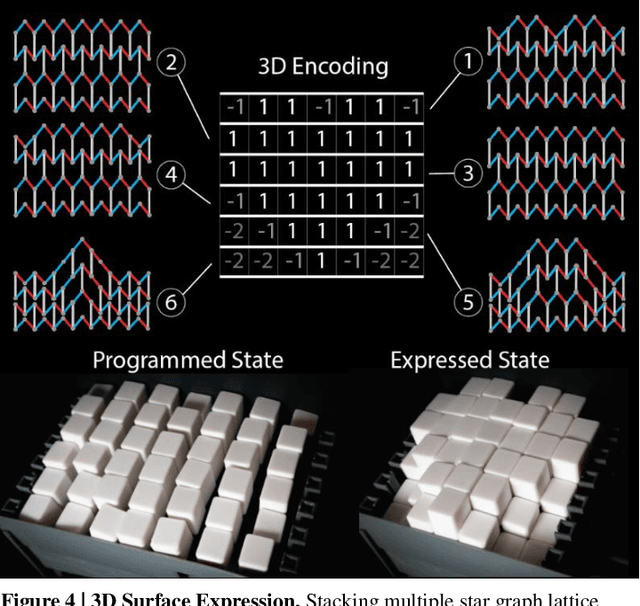
The ability to change a surface's profile allows biological systems to effectively manipulate and blend into their surroundings. Current surface morphing techniques rely either on having a small number of fixed states or on directly driving the entire system. We discovered a subset of scale-independent auxetic metamaterials have a state trajectory with a star-graph structure. At the central node, small nudges can move the material between trajectories, allowing us to locally shift Poisson's ratio, causing the material to take on different shapes under loading. While the number of possible shapes grows exponentially with the size of the material, the probability of finding one at random is vanishingly small. By actively guiding the material through the node points, we produce a reprogrammable surface that does not require inputs to maintain shape and can display arbitrary 2D information and take on complex 3D shapes. Our work opens new opportunities in micro devices, tactile displays, manufacturing, and robotic systems.
Sign Language Recognition System using TensorFlow Object Detection API
Jan 05, 2022
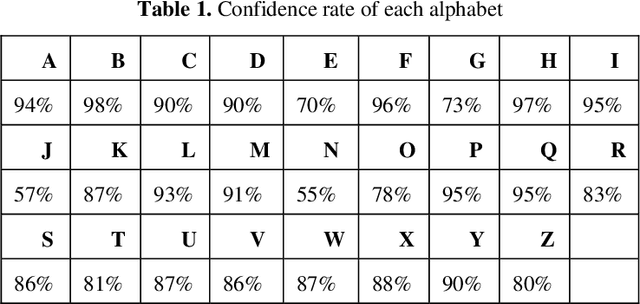


Communication is defined as the act of sharing or exchanging information, ideas or feelings. To establish communication between two people, both of them are required to have knowledge and understanding of a common language. But in the case of deaf and dumb people, the means of communication are different. Deaf is the inability to hear and dumb is the inability to speak. They communicate using sign language among themselves and with normal people but normal people do not take seriously the importance of sign language. Not everyone possesses the knowledge and understanding of sign language which makes communication difficult between a normal person and a deaf and dumb person. To overcome this barrier, one can build a model based on machine learning. A model can be trained to recognize different gestures of sign language and translate them into English. This will help a lot of people in communicating and conversing with deaf and dumb people. The existing Indian Sing Language Recognition systems are designed using machine learning algorithms with single and double-handed gestures but they are not real-time. In this paper, we propose a method to create an Indian Sign Language dataset using a webcam and then using transfer learning, train a TensorFlow model to create a real-time Sign Language Recognition system. The system achieves a good level of accuracy even with a limited size dataset.
Evaluating Deep Music Generation Methods Using Data Augmentation
Dec 31, 2021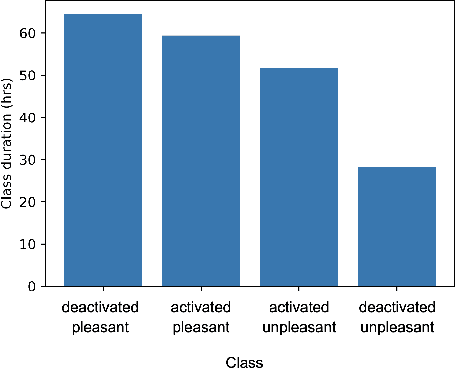
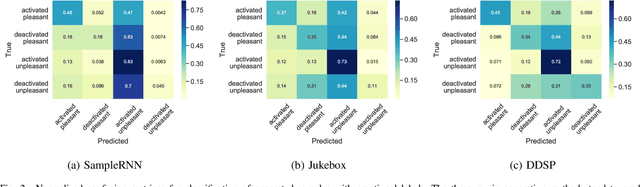
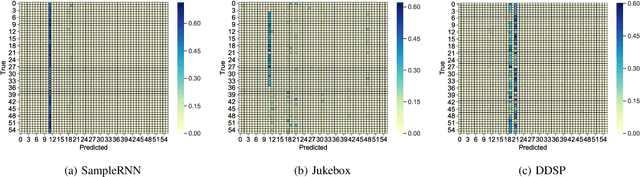
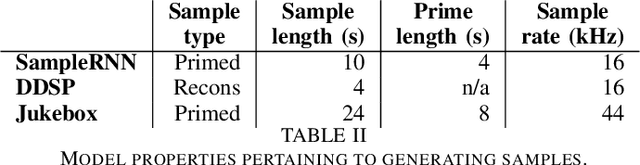
Despite advances in deep algorithmic music generation, evaluation of generated samples often relies on human evaluation, which is subjective and costly. We focus on designing a homogeneous, objective framework for evaluating samples of algorithmically generated music. Any engineered measures to evaluate generated music typically attempt to define the samples' musicality, but do not capture qualities of music such as theme or mood. We do not seek to assess the musical merit of generated music, but instead explore whether generated samples contain meaningful information pertaining to emotion or mood/theme. We achieve this by measuring the change in predictive performance of a music mood/theme classifier after augmenting its training data with generated samples. We analyse music samples generated by three models -- SampleRNN, Jukebox, and DDSP -- and employ a homogeneous framework across all methods to allow for objective comparison. This is the first attempt at augmenting a music genre classification dataset with conditionally generated music. We investigate the classification performance improvement using deep music generation and the ability of the generators to make emotional music by using an additional, emotion annotation of the dataset. Finally, we use a classifier trained on real data to evaluate the label validity of class-conditionally generated samples.
Gradient-based Bit Encoding Optimization for Noise-Robust Binary Memristive Crossbar
Jan 05, 2022
Binary memristive crossbars have gained huge attention as an energy-efficient deep learning hardware accelerator. Nonetheless, they suffer from various noises due to the analog nature of the crossbars. To overcome such limitations, most previous works train weight parameters with noise data obtained from a crossbar. These methods are, however, ineffective because it is difficult to collect noise data in large-volume manufacturing environment where each crossbar has a large device/circuit level variation. Moreover, we argue that there is still room for improvement even though these methods somewhat improve accuracy. This paper explores a new perspective on mitigating crossbar noise in a more generalized way by manipulating input binary bit encoding rather than training the weight of networks with respect to noise data. We first mathematically show that the noise decreases as the number of binary bit encoding pulses increases when representing the same amount of information. In addition, we propose Gradient-based Bit Encoding Optimization (GBO) which optimizes a different number of pulses at each layer, based on our in-depth analysis that each layer has a different level of noise sensitivity. The proposed heterogeneous layer-wise bit encoding scheme achieves high noise robustness with low computational cost. Our experimental results on public benchmark datasets show that GBO improves the classification accuracy by ~5-40% in severe noise scenarios.
Mutual Information Scaling and Expressive Power of Sequence Models
May 10, 2019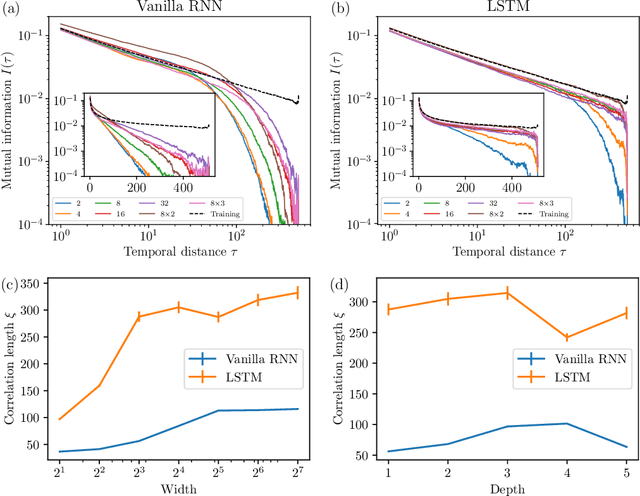
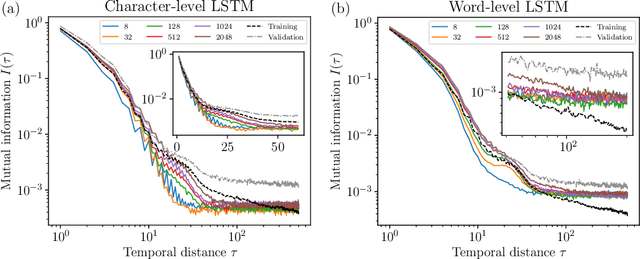
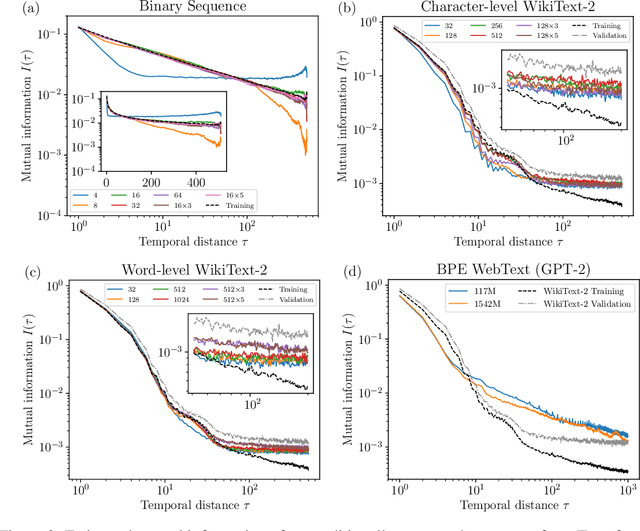
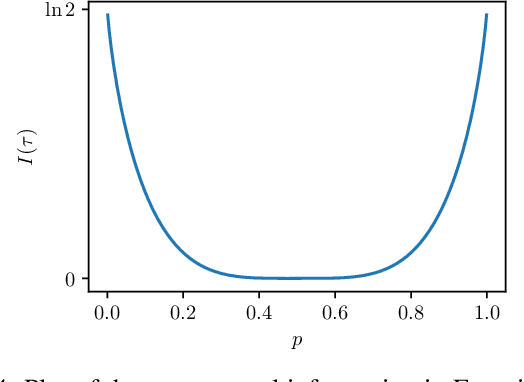
Sequence models assign probabilities to variable-length sequences such as natural language texts. The ability of sequence models to capture temporal dependence can be characterized by the temporal scaling of correlation and mutual information. In this paper, we study the mutual information of recurrent neural networks (RNNs) including long short-term memories and self-attention networks such as Transformers. Through a combination of theoretical study of linear RNNs and empirical study of nonlinear RNNs, we find their mutual information decays exponentially in temporal distance. On the other hand, Transformers can capture long-range mutual information more efficiently, making them preferable in modeling sequences with slow power-law mutual information, such as natural languages and stock prices. We discuss the connection of these results with statistical mechanics. We also point out the non-uniformity problem in many natural language datasets. We hope this work provides a new perspective in understanding the expressive power of sequence models and shed new light on improving the architecture of them.
Kalman Filtering with Adversarial Corruptions
Nov 11, 2021Here we revisit the classic problem of linear quadratic estimation, i.e. estimating the trajectory of a linear dynamical system from noisy measurements. The celebrated Kalman filter gives an optimal estimator when the measurement noise is Gaussian, but is widely known to break down when one deviates from this assumption, e.g. when the noise is heavy-tailed. Many ad hoc heuristics have been employed in practice for dealing with outliers. In a pioneering work, Schick and Mitter gave provable guarantees when the measurement noise is a known infinitesimal perturbation of a Gaussian and raised the important question of whether one can get similar guarantees for large and unknown perturbations. In this work we give a truly robust filter: we give the first strong provable guarantees for linear quadratic estimation when even a constant fraction of measurements have been adversarially corrupted. This framework can model heavy-tailed and even non-stationary noise processes. Our algorithm robustifies the Kalman filter in the sense that it competes with the optimal algorithm that knows the locations of the corruptions. Our work is in a challenging Bayesian setting where the number of measurements scales with the complexity of what we need to estimate. Moreover, in linear dynamical systems past information decays over time. We develop a suite of new techniques to robustly extract information across different time steps and over varying time scales.
NOTMAD: Estimating Bayesian Networks with Sample-Specific Structures and Parameters
Nov 01, 2021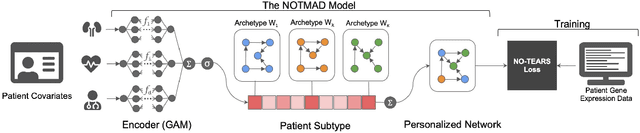


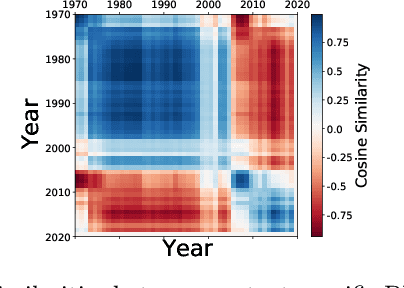
Context-specific Bayesian networks (i.e. directed acyclic graphs, DAGs) identify context-dependent relationships between variables, but the non-convexity induced by the acyclicity requirement makes it difficult to share information between context-specific estimators (e.g. with graph generator functions). For this reason, existing methods for inferring context-specific Bayesian networks have favored breaking datasets into subsamples, limiting statistical power and resolution, and preventing the use of multidimensional and latent contexts. To overcome this challenge, we propose NOTEARS-optimized Mixtures of Archetypal DAGs (NOTMAD). NOTMAD models context-specific Bayesian networks as the output of a function which learns to mix archetypal networks according to sample context. The archetypal networks are estimated jointly with the context-specific networks and do not require any prior knowledge. We encode the acyclicity constraint as a smooth regularization loss which is back-propagated to the mixing function; in this way, NOTMAD shares information between context-specific acyclic graphs, enabling the estimation of Bayesian network structures and parameters at even single-sample resolution. We demonstrate the utility of NOTMAD and sample-specific network inference through analysis and experiments, including patient-specific gene expression networks which correspond to morphological variation in cancer.
Watch It Move: Unsupervised Discovery of 3D Joints for Re-Posing of Articulated Objects
Dec 21, 2021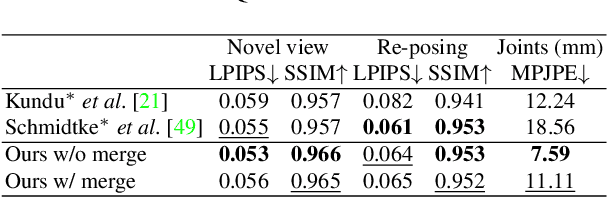
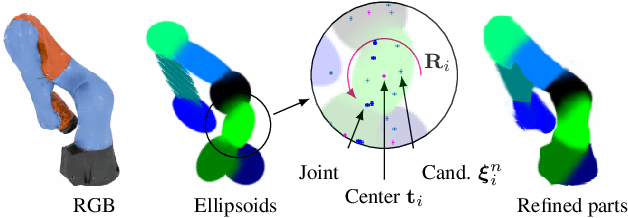
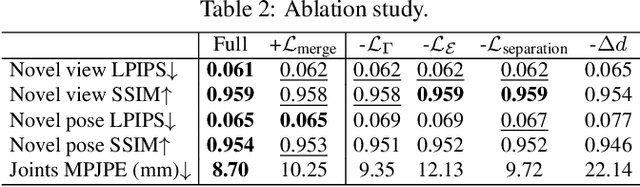
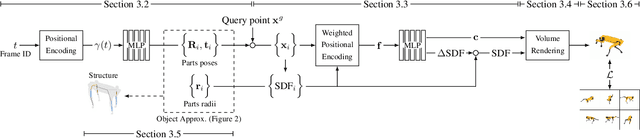
Rendering articulated objects while controlling their poses is critical to applications such as virtual reality or animation for movies. Manipulating the pose of an object, however, requires the understanding of its underlying structure, that is, its joints and how they interact with each other. Unfortunately, assuming the structure to be known, as existing methods do, precludes the ability to work on new object categories. We propose to learn both the appearance and the structure of previously unseen articulated objects by observing them move from multiple views, with no additional supervision, such as joints annotations, or information about the structure. Our insight is that adjacent parts that move relative to each other must be connected by a joint. To leverage this observation, we model the object parts in 3D as ellipsoids, which allows us to identify joints. We combine this explicit representation with an implicit one that compensates for the approximation introduced. We show that our method works for different structures, from quadrupeds, to single-arm robots, to humans.
Natural Language Processing for Information Extraction
Jul 06, 2018With rise of digital age, there is an explosion of information in the form of news, articles, social media, and so on. Much of this data lies in unstructured form and manually managing and effectively making use of it is tedious, boring and labor intensive. This explosion of information and need for more sophisticated and efficient information handling tools gives rise to Information Extraction(IE) and Information Retrieval(IR) technology. Information Extraction systems takes natural language text as input and produces structured information specified by certain criteria, that is relevant to a particular application. Various sub-tasks of IE such as Named Entity Recognition, Coreference Resolution, Named Entity Linking, Relation Extraction, Knowledge Base reasoning forms the building blocks of various high end Natural Language Processing (NLP) tasks such as Machine Translation, Question-Answering System, Natural Language Understanding, Text Summarization and Digital Assistants like Siri, Cortana and Google Now. This paper introduces Information Extraction technology, its various sub-tasks, highlights state-of-the-art research in various IE subtasks, current challenges and future research directions.
Spatiotemporal Information Processing with a Reservoir Decision-making Network
Jul 28, 2019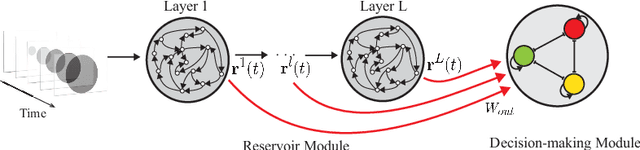
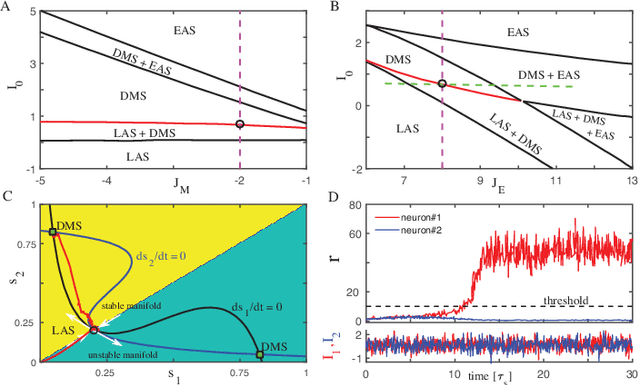
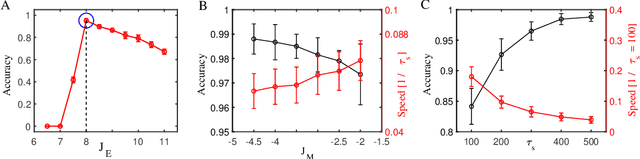
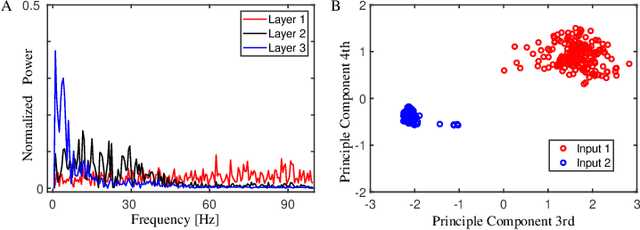
Spatiotemporal information processing is fundamental to brain functions. The present study investigates a canonic neural network model for spatiotemporal pattern recognition. Specifically, the model consists of two modules, a reservoir subnetwork and a decision-making subnetwork. The former projects complex spatiotemporal patterns into spatially separated neural representations, and the latter reads out these neural representations via integrating information over time; the two modules are combined together via supervised-learning using known examples. We elucidate the working mechanism of the model and demonstrate its feasibility for discriminating complex spatiotemporal patterns. Our model reproduces the phenomenon of recognizing looming patterns in the neural system, and can learn to discriminate gait with very few training examples. We hope this study gives us insight into understanding how spatiotemporal information is processed in the brain and helps us to develop brain-inspired application algorithms.