 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FourierNet: Shape-Preserving Network for Henle's Fiber Layer Segmentation in Optical Coherence Tomography Images
Jan 17, 2022
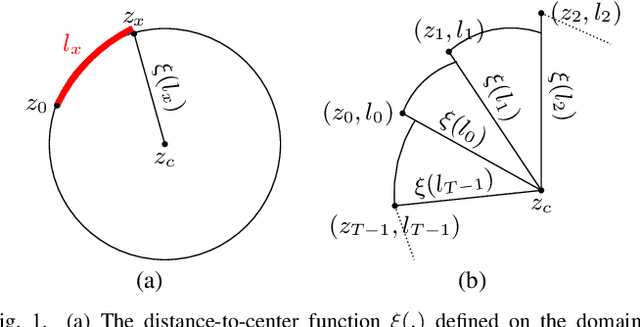
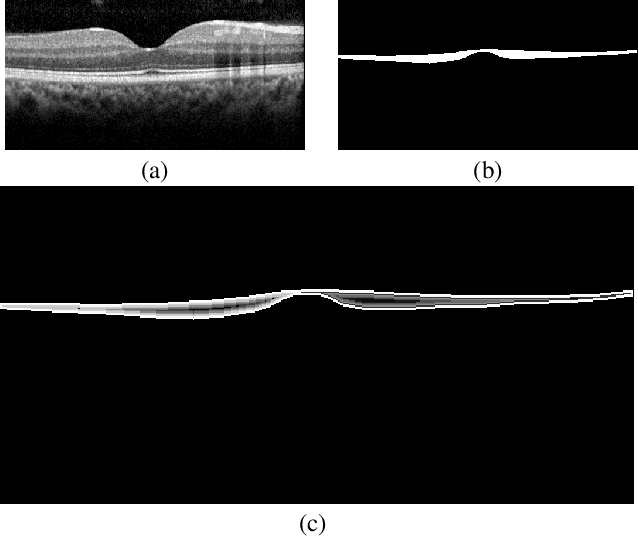
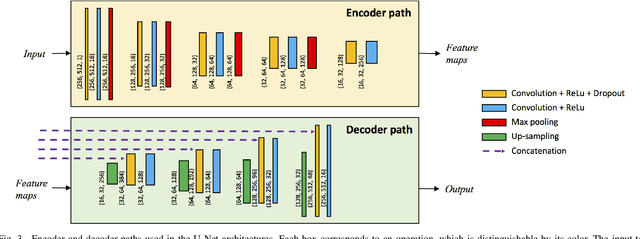
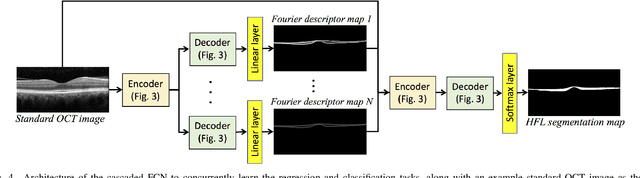
The Henle's fiber layer (HFL) in the retina carries valuable information on the macular condition of an eye. However, in the common practice, this layer is not separately segmented but rather included in the outer nuclear layer since it is difficult to perceive HFL contours on standard optical coherence tomography (OCT) imaging. Due to its variable reflectivity under an imaging beam, delineating the HFL contours necessitates directional OCT, which requires additional imaging. This paper addresses this issue by introducing a shape-preserving network, FourierNet, that achieves HFL segmentation in standard OCT scans with the target performance obtained when directional OCT scans are used. FourierNet is a new cascaded network design that puts forward the idea of benefiting the shape prior of HFL in the network training. This design proposes to represent the shape prior by extracting Fourier descriptors on the HFL contours and defining an additional regression task of learning these descriptors. It then formulates HFL segmentation as concurrent learning of regression and classification tasks, in which Fourier descriptors are estimated from an input image to encode the shape prior and used together with the input image to construct the HFL segmentation map. Our experiments on 1470 images of 30 OCT scans reveal that quantifying the HFL shape with Fourier descriptors and concurrently learning them with the main task of HFL segmentation lead to better results. This indicates the effectiveness of designing a shape-preserving network to improve HFL segmentation by reducing the need to perform directional OCT imaging.
Combining Scale-Invariance and Uncertainty for Self-Supervised Domain Adaptation of Foggy Scenes Segmentation
Jan 17, 2022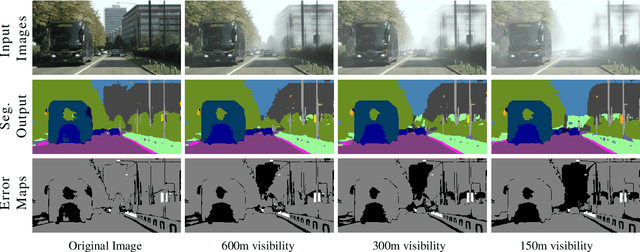

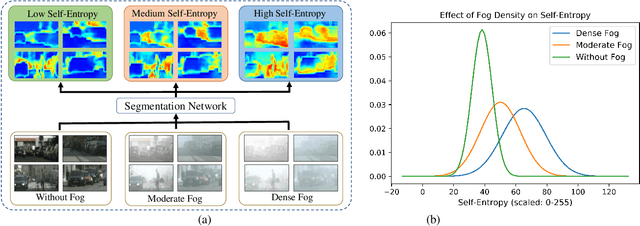
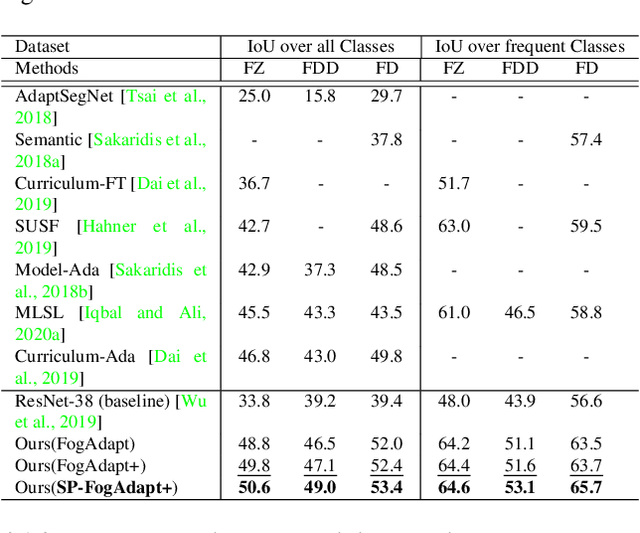
This paper presents FogAdapt, a novel approach for domain adaptation of semantic segmentation for dense foggy scenes. Although significant research has been directed to reduce the domain shift in semantic segmentation, adaptation to scenes with adverse weather conditions remains an open question. Large variations in the visibility of the scene due to weather conditions, such as fog, smog, and haze, exacerbate the domain shift, thus making unsupervised adaptation in such scenarios challenging. We propose a self-entropy and multi-scale information augmented self-supervised domain adaptation method (FogAdapt) to minimize the domain shift in foggy scenes segmentation. Supported by the empirical evidence that an increase in fog density results in high self-entropy for segmentation probabilities, we introduce a self-entropy based loss function to guide the adaptation method. Furthermore, inferences obtained at different image scales are combined and weighted by the uncertainty to generate scale-invariant pseudo-labels for the target domain. These scale-invariant pseudo-labels are robust to visibility and scale variations. We evaluate the proposed model on real clear-weather scenes to real foggy scenes adaptation and synthetic non-foggy images to real foggy scenes adaptation scenarios. Our experiments demonstrate that FogAdapt significantly outperforms the current state-of-the-art in semantic segmentation of foggy images. Specifically, by considering the standard settings compared to state-of-the-art (SOTA) methods, FogAdapt gains 3.8% on Foggy Zurich, 6.0% on Foggy Driving-dense, and 3.6% on Foggy Driving in mIoU when adapted from Cityscapes to Foggy Zurich.
Natural Scene Text Editing Based on AI
Nov 26, 2021


In a recorded situation, textual information is crucial for scene interpretation and decision making. The ability to edit text directly on images has a number of advantages, including error correction, text restoration, and image reusability. This research shows how to change image text at the letter and digits level. I devised a two-part letters-digits network (LDN) to encode and decode digital images, as well as learn and transfer the font style of the source characters to the target characters. This method allows you to update the uppercase letters, lowercase letters and digits in the picture.
Data and knowledge-driven approaches for multilingual training to improve the performance of speech recognition systems of Indian languages
Jan 24, 2022
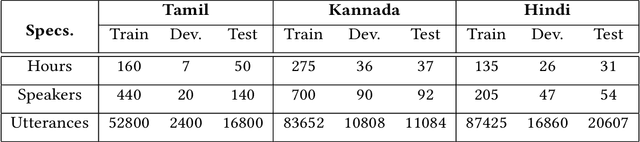
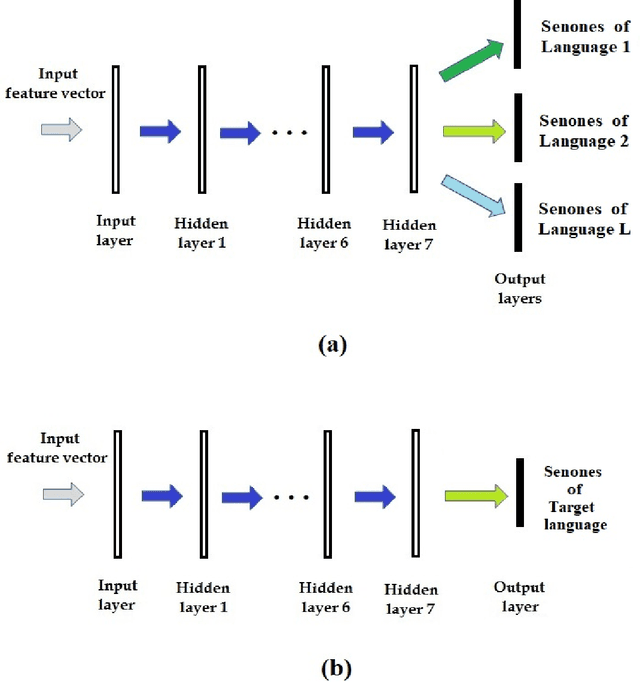
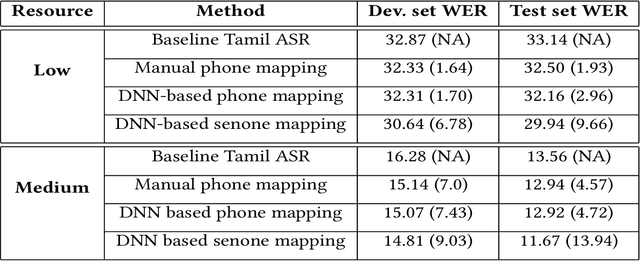
We propose data and knowledge-driven approaches for multilingual training of the automated speech recognition (ASR) system for a target language by pooling speech data from multiple source languages. Exploiting the acoustic similarities between Indian languages, we implement two approaches. In phone/senone mapping, deep neural network (DNN) learns to map senones or phones from one language to the others, and the transcriptions of the source languages are modified such that they can be used along with the target language data to train and fine-tune the target language ASR system. In the other approach, we model the acoustic information for all the languages simultaneously by training a multitask DNN (MTDNN) to predict the senones of each language in different output layers. The cross-entropy loss and the weight update procedure are modified such that only the shared layers and the output layer responsible for predicting the senone classes of a language are updated during training, if the feature vector belongs to that particular language. In the low-resource setting (LRS), 40 hours of transcribed data each for Tamil, Telugu and Gujarati languages are used for training. The DNN based senone mapping technique gives relative improvements in word error rates (WER) of 9.66%, 7.2% and 15.21% over the baseline system for Tamil, Gujarati and Telugu languages, respectively. In medium-resourced setting (MRS), 160, 275 and 135 hours of data for Tamil, Kannada and Hindi languages are used, where, the same technique gives better relative improvements of 13.94%, 10.28% and 27.24% for Tamil, Kannada and Hindi, respectively. The MTDNN with senone mapping based training in LRS, gives higher relative WER improvements of 15.0%, 17.54% and 16.06%, respectively for Tamil, Gujarati and Telugu, whereas in MRS, we see improvements of 21.24% 21.05% and 30.17% for Tamil, Kannada and Hindi languages, respectively.
Weakly Supervised Change Detection Using Guided Anisotropic Difusion
Dec 31, 2021
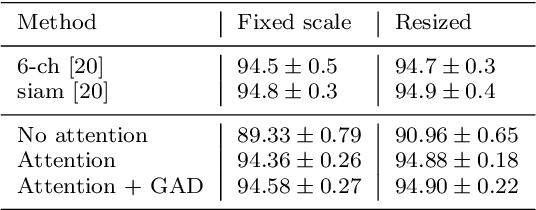

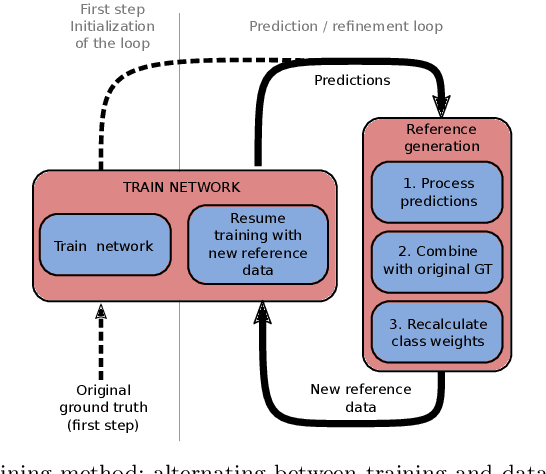
Large scale datasets created from crowdsourced labels or openly available data have become crucial to provide training data for large scale learning algorithms. While these datasets are easier to acquire, the data are frequently noisy and unreliable, which is motivating research on weakly supervised learning techniques. In this paper we propose original ideas that help us to leverage such datasets in the context of change detection. First, we propose the guided anisotropic diffusion (GAD) algorithm, which improves semantic segmentation results using the input images as guides to perform edge preserving filtering. We then show its potential in two weakly-supervised learning strategies tailored for change detection. The first strategy is an iterative learning method that combines model optimisation and data cleansing using GAD to extract the useful information from a large scale change detection dataset generated from open vector data. The second one incorporates GAD within a novel spatial attention layer that increases the accuracy of weakly supervised networks trained to perform pixel-level predictions from image-level labels. Improvements with respect to state-of-the-art are demonstrated on 4 different public datasets.
Explainable Point-Based Document Visualizations
Sep 28, 2021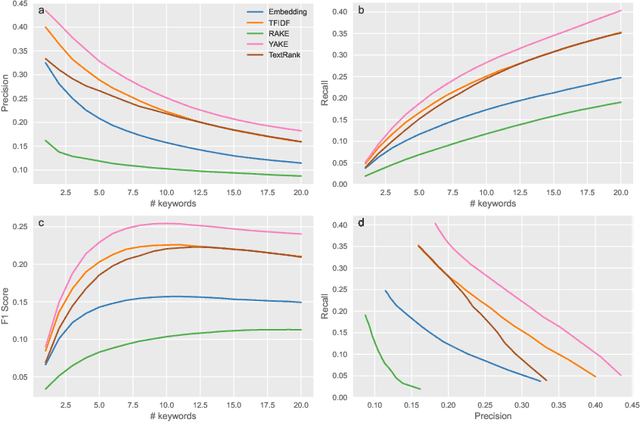
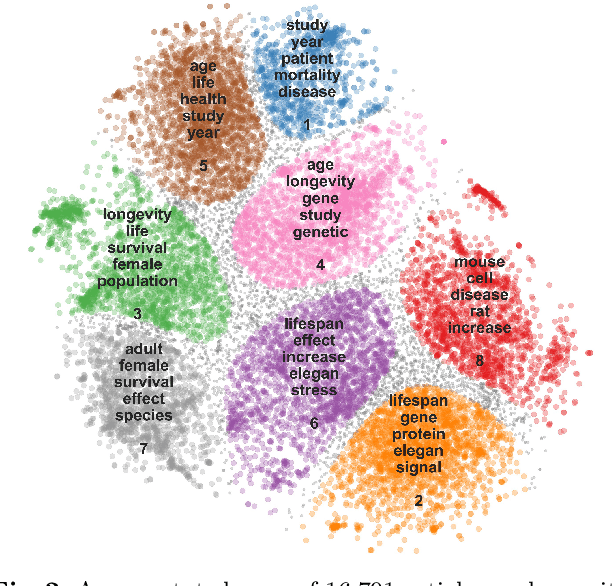
Two-dimensional data maps can visually reveal information about the relations between data instances. Popular techniques to construct data maps are t-SNE and UMAP. The resulting point-based visualizations, though, provide information only through their interpretation. We here consider a set of abstracts from the articles on longevity to argue for using keyword extraction methods to label clusters of documents in the map. Among the considered approaches, the best results were obtained by recently proposed YAKE!. Surprisingly, a classical TF-IDF term ranking outperformed graph and embedding-based techniques.
Neural KEM: A Kernel Method with Deep Coefficient Prior for PET Image Reconstruction
Jan 05, 2022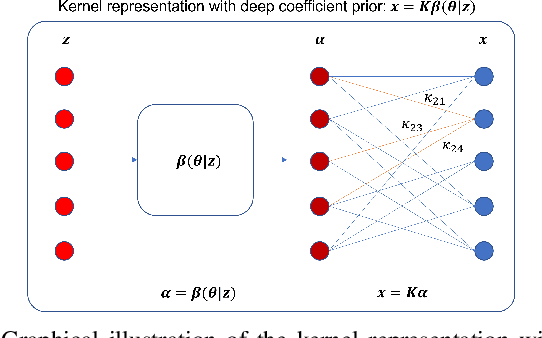
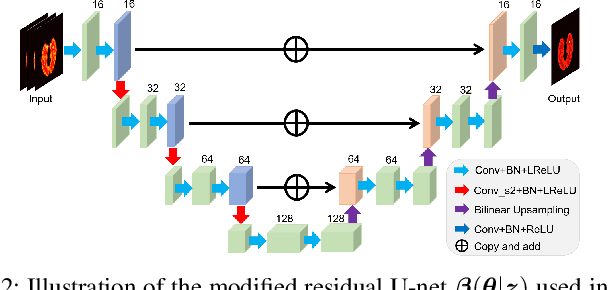
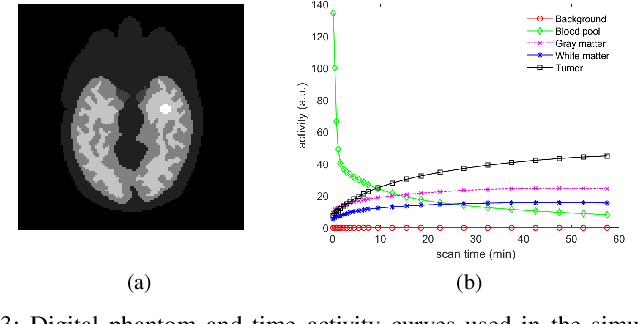
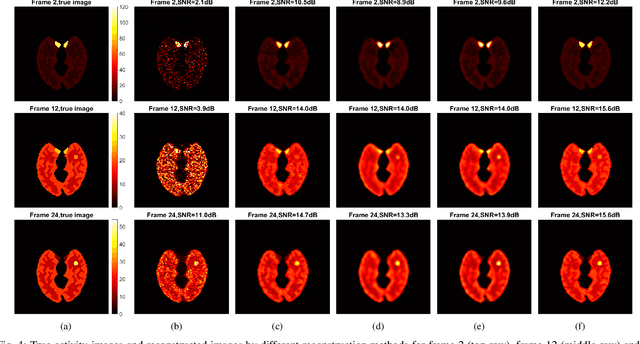
Image reconstruction of low-count positron emission tomography (PET) data is challenging. Kernel methods address the challenge by incorporating image prior information in the forward model of iterative PET image reconstruction. The kernelized expectation-maximization (KEM) algorithm has been developed and demonstrated to be effective and easy to implement. A common approach for a further improvement of the kernel method would be adding an explicit regularization, which however leads to a complex optimization problem. In this paper, we propose an implicit regularization for the kernel method by using a deep coefficient prior, which represents the kernel coefficient image in the PET forward model using a convolutional neural-network. To solve the maximum-likelihood neural network-based reconstruction problem, we apply the principle of optimization transfer to derive a neural KEM algorithm. Each iteration of the algorithm consists of two separate steps: a KEM step for image update from the projection data and a deep-learning step in the image domain for updating the kernel coefficient image using the neural network. This optimization algorithm is guaranteed to monotonically increase the data likelihood. The results from computer simulations and real patient data have demonstrated that the neural KEM can outperform existing KEM and deep image prior methods.
A generalization gap estimation for overparameterized models via Langevin functional variance
Dec 07, 2021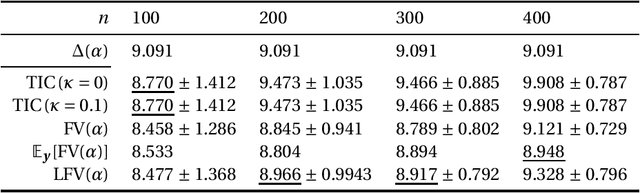
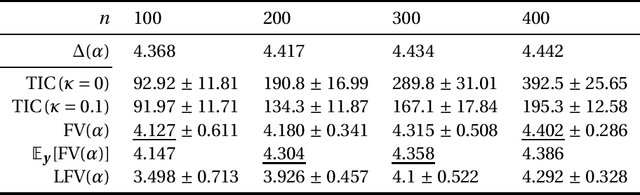
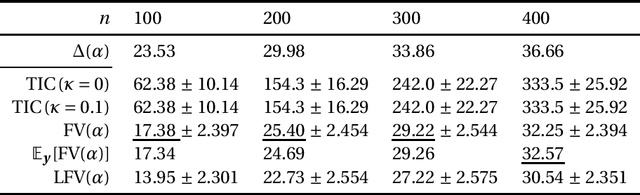

This paper discusses estimating the generalization gap, a difference between a generalization gap and an empirical error, for overparameterized models (e.g., neural networks). We first show that a functional variance, a key concept in defining a widely-applicable information criterion, characterizes the generalization gap even in overparameterized settings, where a conventional theory cannot be applied. We next propose a computationally efficient approximation of the function variance, a Langevin approximation of the functional variance~(Langevin FV). This method leverages the 1st-order but not the 2nd-order gradient of the squared loss function; so, it can be computed efficiently and implemented consistently with gradient-based optimization algorithms. We demonstrate the Langevin FV numerically in estimating generalization gaps of overparameterized linear regression and non-linear neural network models.
Generating Diverse and Consistent QA pairs from Contexts with Information-Maximizing Hierarchical Conditional VAEs
Jun 02, 2020
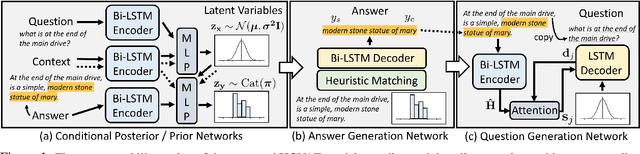
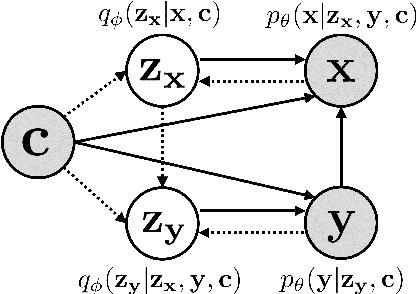
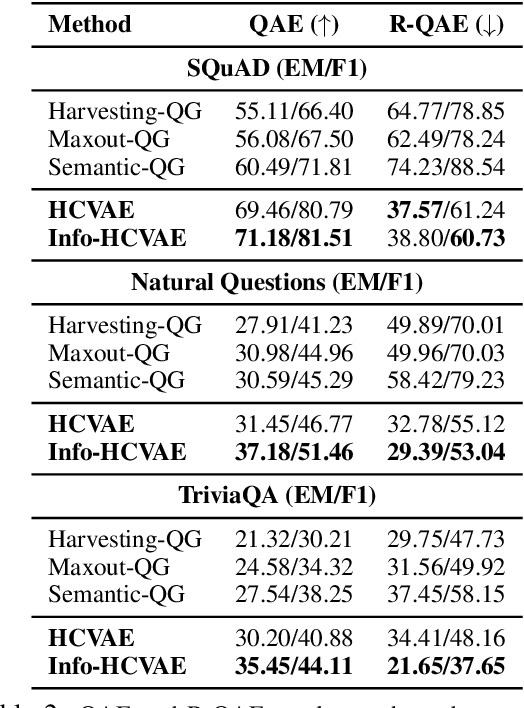
One of the most crucial challenges in question answering (QA) is the scarcity of labeled data, since it is costly to obtain question-answer (QA) pairs for a target text domain with human annotation. An alternative approach to tackle the problem is to use automatically generated QA pairs from either the problem context or from large amount of unstructured texts (e.g. Wikipedia). In this work, we propose a hierarchical conditional variational autoencoder (HCVAE) for generating QA pairs given unstructured texts as contexts, while maximizing the mutual information between generated QA pairs to ensure their consistency. We validate our Information Maximizing Hierarchical Conditional Variational AutoEncoder (Info-HCVAE) on several benchmark datasets by evaluating the performance of the QA model (BERT-base) using only the generated QA pairs (QA-based evaluation) or by using both the generated and human-labeled pairs (semi-supervised learning) for training, against state-of-the-art baseline models. The results show that our model obtains impressive performance gains over all baselines on both tasks, using only a fraction of data for training.
AMMASurv: Asymmetrical Multi-Modal Attention for Accurate Survival Analysis with Whole Slide Images and Gene Expression Data
Aug 28, 2021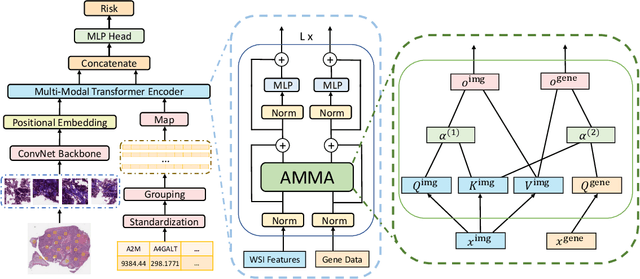
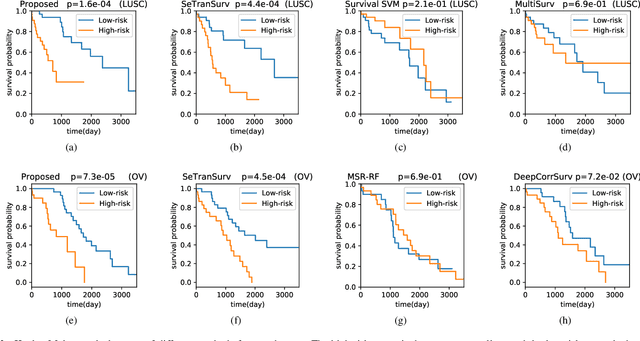
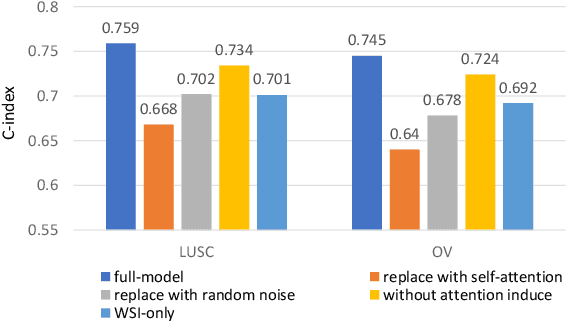
The use of multi-modal data such as the combination of whole slide images (WSIs) and gene expression data for survival analysis can lead to more accurate survival predictions. Previous multi-modal survival models are not able to efficiently excavate the intrinsic information within each modality. Moreover, despite experimental results show that WSIs provide more effective information than gene expression data, previous methods regard the information from different modalities as similarly important so they cannot flexibly utilize the potential connection between the modalities. To address the above problems, we propose a new asymmetrical multi-modal method, termed as AMMASurv. Specifically, we design an asymmetrical multi-modal attention mechanism (AMMA) in Transformer encoder for multi-modal data to enable a more flexible multi-modal information fusion for survival prediction. Different from previous works, AMMASurv can effectively utilize the intrinsic information within every modality and flexibly adapts to the modalities of different importance. Extensive experiments are conducted to validate the effectiveness of the proposed model. Encouraging results demonstrate the superiority of our method over other state-of-the-art methods.