 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Intelligibility-Oriented Audio-Visual Speech Enhancement
Nov 18, 2021
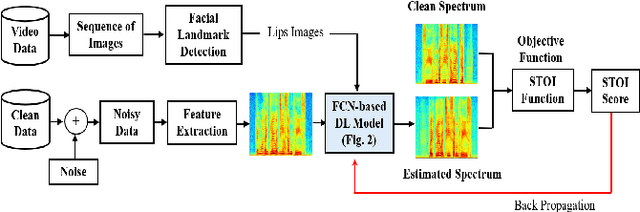
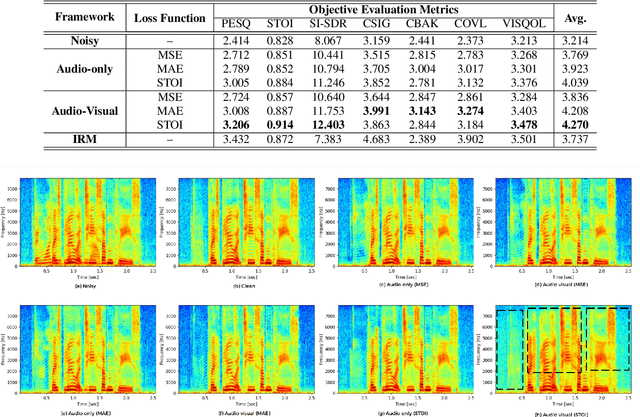
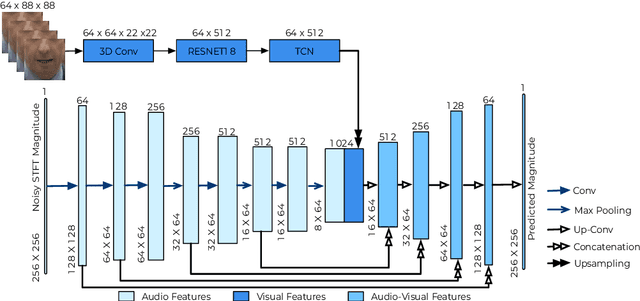
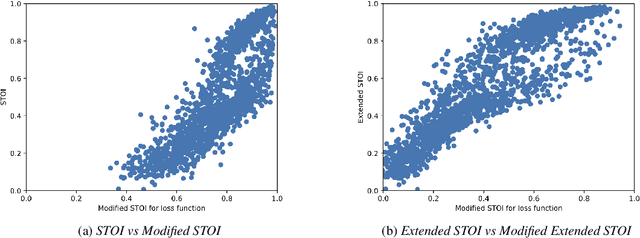
Existing deep learning (DL) based speech enhancement approaches are generally optimised to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in real noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions and integration of audio-visual (AV) information for more robust speech enhancement (SE). In this paper, we introduce DL based I-O SE algorithms exploiting AV information, which is a novel and previously unexplored research direction. Specifically, we present a fully convolutional AV SE model that uses a modified short-time objective intelligibility (STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of AV modalities with an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed I-O AV SE framework outperforms audio-only (AO) and AV models trained with conventional distance-based loss functions, in terms of standard objective evaluation measures when dealing with unseen speakers and noises.
Separation of scales and a thermodynamic description of feature learning in some CNNs
Dec 31, 2021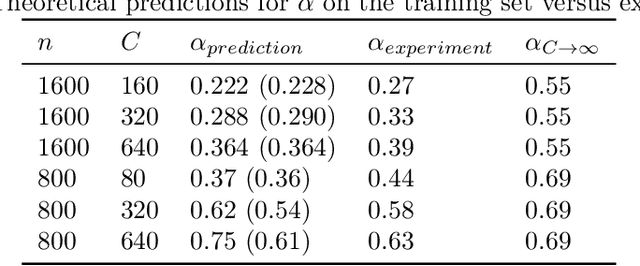
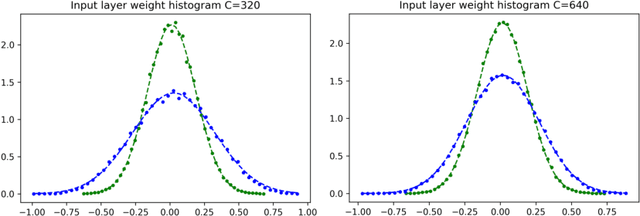
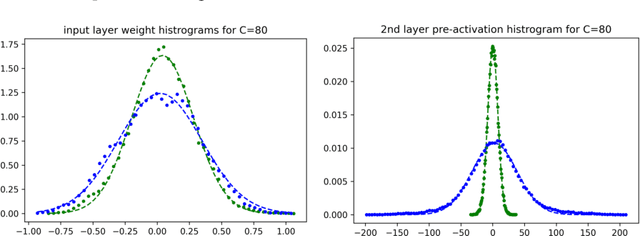
Deep neural networks (DNNs) are powerful tools for compressing and distilling information. Due to their scale and complexity, often involving billions of inter-dependent internal degrees of freedom, exact analysis approaches often fall short. A common strategy in such cases is to identify slow degrees of freedom that average out the erratic behavior of the underlying fast microscopic variables. Here, we identify such a separation of scales occurring in over-parameterized deep convolutional neural networks (CNNs) at the end of training. It implies that neuron pre-activations fluctuate in a nearly Gaussian manner with a deterministic latent kernel. While for CNNs with infinitely many channels these kernels are inert, for finite CNNs they adapt and learn from data in an analytically tractable manner. The resulting thermodynamic theory of deep learning yields accurate predictions on several deep non-linear CNN toy models. In addition, it provides new ways of analyzing and understanding CNNs.
Dense anomaly detection by robust learning on synthetic negative data
Dec 31, 2021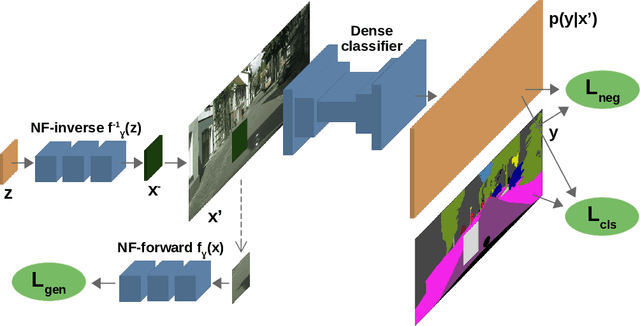

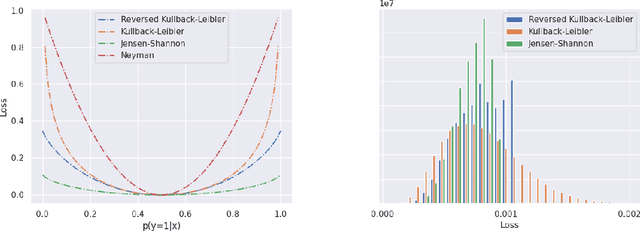
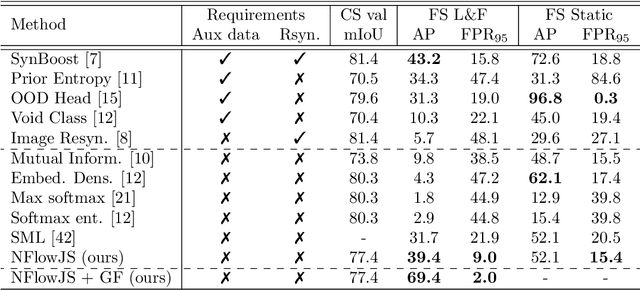
Standard machine learning is unable to accommodate inputs which do not belong to the training distribution. The resulting models often give rise to confident incorrect predictions which may lead to devastating consequences. This problem is especially demanding in the context of dense prediction since input images may be partially anomalous. Previous work has addressed dense anomaly detection by discriminative training on mixed-content images. We extend this approach with synthetic negative patches which simultaneously achieve high inlier likelihood and uniform discriminative prediction. We generate synthetic negatives with normalizing flows due to their outstanding distribution coverage and capability to generate samples at different resolutions. We also propose to detect anomalies according to a principled information-theoretic criterion which can be consistently applied through training and inference. The resulting models set the new state of the art on standard benchmarks and datasets in spite of minimal computational overhead and refraining from auxiliary negative data.
Exploiting Domain-Specific Features to Enhance Domain Generalization
Oct 18, 2021
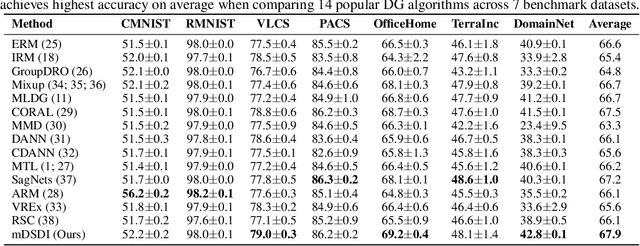

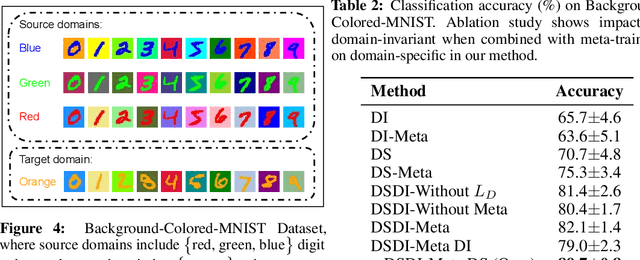
Domain Generalization (DG) aims to train a model, from multiple observed source domains, in order to perform well on unseen target domains. To obtain the generalization capability, prior DG approaches have focused on extracting domain-invariant information across sources to generalize on target domains, while useful domain-specific information which strongly correlates with labels in individual domains and the generalization to target domains is usually ignored. In this paper, we propose meta-Domain Specific-Domain Invariant (mDSDI) - a novel theoretically sound framework that extends beyond the invariance view to further capture the usefulness of domain-specific information. Our key insight is to disentangle features in the latent space while jointly learning both domain-invariant and domain-specific features in a unified framework. The domain-specific representation is optimized through the meta-learning framework to adapt from source domains, targeting a robust generalization on unseen domains. We empirically show that mDSDI provides competitive results with state-of-the-art techniques in DG. A further ablation study with our generated dataset, Background-Colored-MNIST, confirms the hypothesis that domain-specific is essential, leading to better results when compared with only using domain-invariant.
Joint Learning of Linear Time-Invariant Dynamical Systems
Dec 22, 2021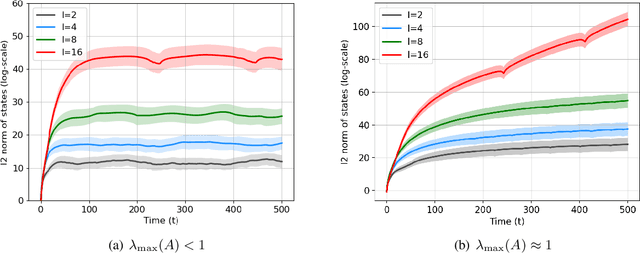
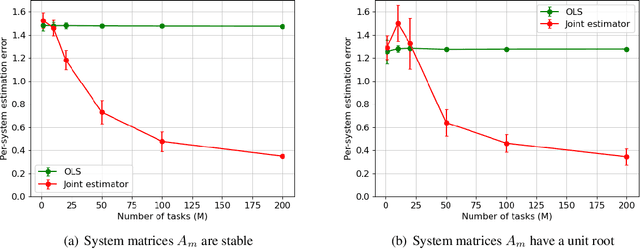
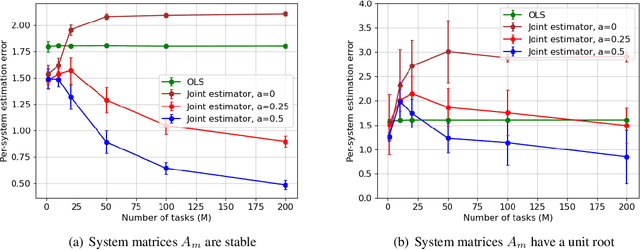
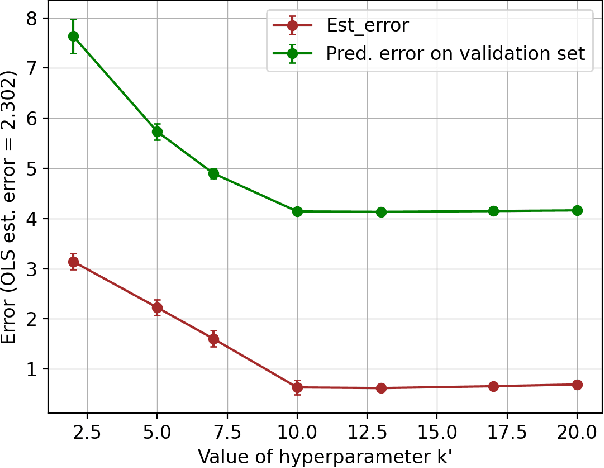
Learning the parameters of a linear time-invariant dynamical system (LTIDS) is a problem of current interest. In many applications, one is interested in jointly learning the parameters of multiple related LTIDS, which remains unexplored to date. To that end, we develop a joint estimator for learning the transition matrices of LTIDS that share common basis matrices. Further, we establish finite-time error bounds that depend on the underlying sample size, dimension, number of tasks, and spectral properties of the transition matrices. The results are obtained under mild regularity assumptions and showcase the gains from pooling information across LTIDS, in comparison to learning each system separately. We also study the impact of misspecifying the joint structure of the transition matrices and show that the established results are robust in the presence of moderate misspecifications.
Privacy-Aware Communication Over the Wiretap Channel with Generative Networks
Oct 08, 2021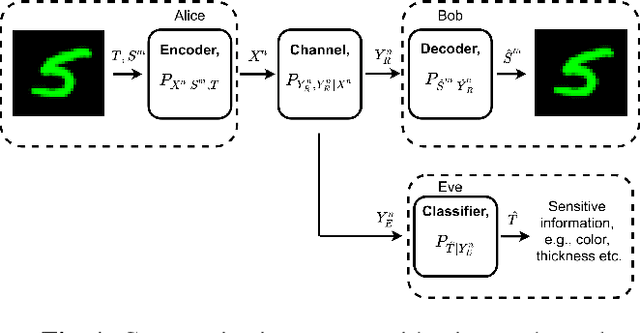
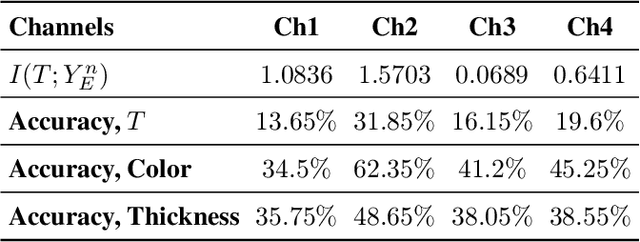
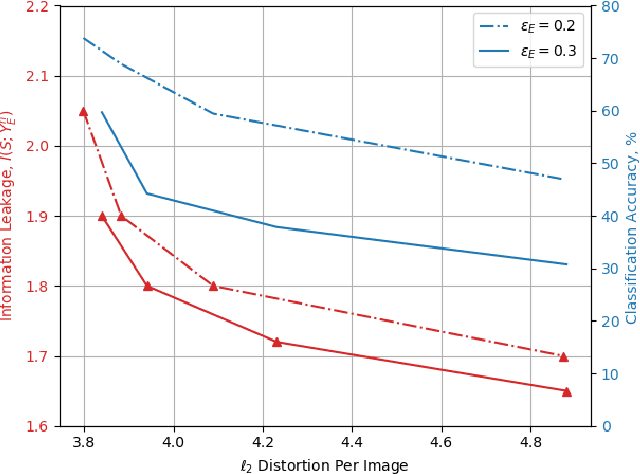

We study privacy-aware communication over a wiretap channel using end-to-end learning. Alice wants to transmit a source signal to Bob over a binary symmetric channel, while passive eavesdropper Eve tries to infer some sensitive attribute of Alice's source based on its overheard signal. Since we usually do not have access to true distributions, we propose a data-driven approach using variational autoencoder (VAE)-based joint source channel coding (JSCC). We show through simulations with the colored MNIST dataset that our approach provides high reconstruction quality at the receiver while confusing the eavesdropper about the latent sensitive attribute, which consists of the color and thickness of the digits. Finally, we consider a parallel-channel scenario, and show that our approach arranges the information transmission such that the channels with higher noise levels at the eavesdropper carry the sensitive information, while the non-sensitive information is transmitted over more vulnerable channels.
POCO: Point Convolution for Surface Reconstruction
Jan 05, 2022
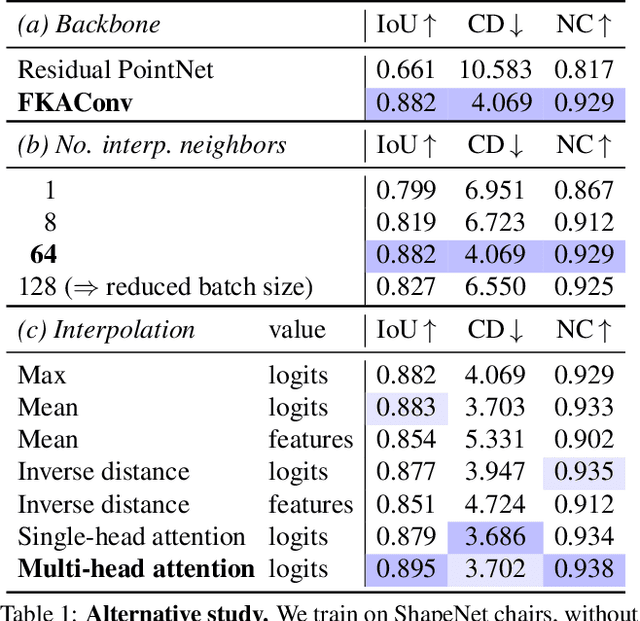
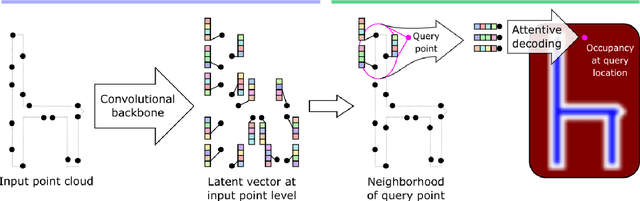
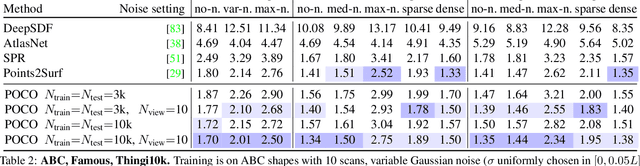
Implicit neural networks have been successfully used for surface reconstruction from point clouds. However, many of them face scalability issues as they encode the isosurface function of a whole object or scene into a single latent vector. To overcome this limitation, a few approaches infer latent vectors on a coarse regular 3D grid or on 3D patches, and interpolate them to answer occupancy queries. In doing so, they loose the direct connection with the input points sampled on the surface of objects, and they attach information uniformly in space rather than where it matters the most, i.e., near the surface. Besides, relying on fixed patch sizes may require discretization tuning. To address these issues, we propose to use point cloud convolutions and compute latent vectors at each input point. We then perform a learning-based interpolation on nearest neighbors using inferred weights. Experiments on both object and scene datasets show that our approach significantly outperforms other methods on most classical metrics, producing finer details and better reconstructing thinner volumes. The code is available at https://github.com/valeoai/POCO.
Iterative Joint Parameters Estimation and Decoding in a Distributed Receiver for Satellite Applications and Relevant Cramer-Rao Bounds
Jan 23, 2022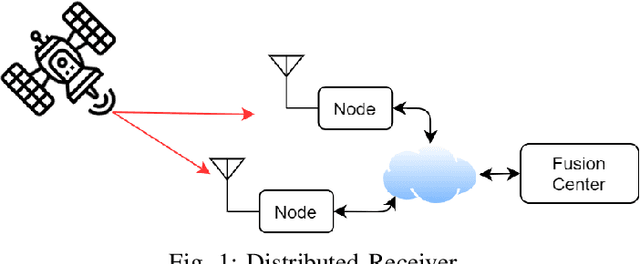
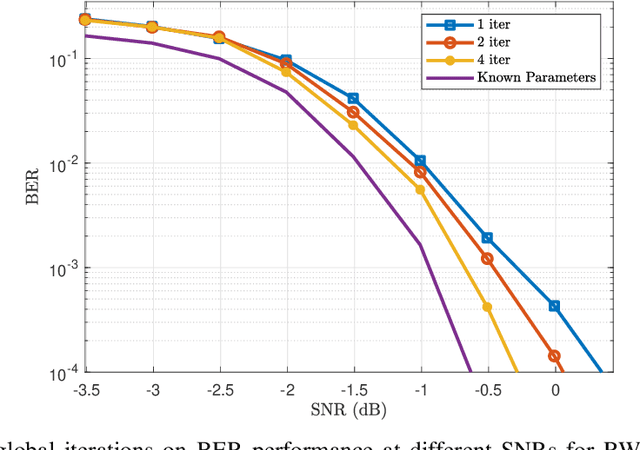
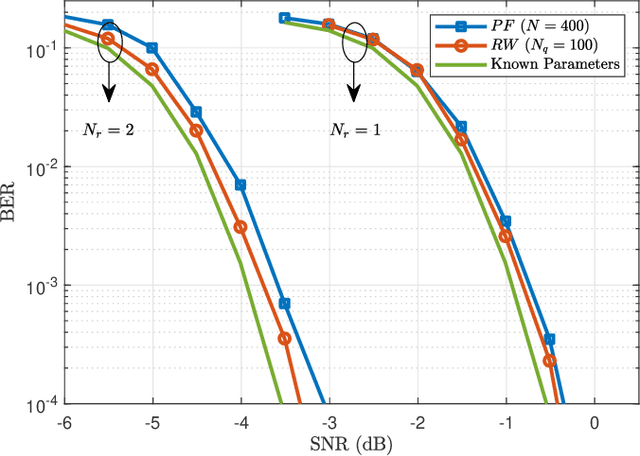
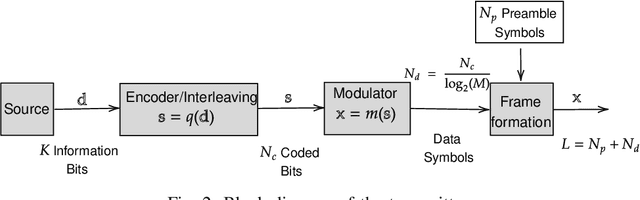
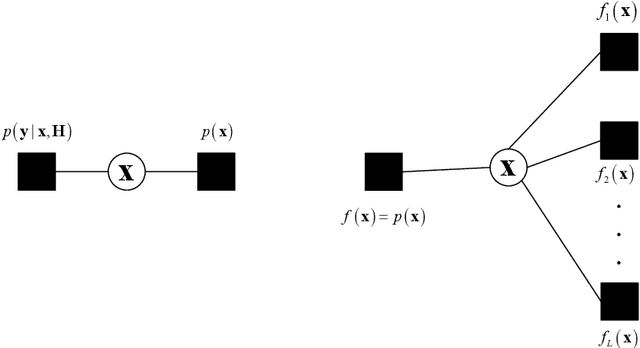
This paper presents an algorithm for iterative joint channel parameter (carrier phase, Doppler shift and Doppler rate) estimation and decoding of transmission over channels affected by Doppler shift and Doppler rate using a distributed receiver. This algorithm is derived by applying the sum-product algorithm (SPA) to a factor graph representing the joint a posteriori distribution of the information symbols and channel parameters given the channel output. In this paper, we present two methods for dealing with intractable messages of the sum-product algorithm. In the first approach, we use particle filtering with sequential importance sampling (SIS) for the estimation of the unknown parameters. We also propose a method for fine-tuning of particles for improved convergence. In the second approach, we approximate our model with a random walk phase model, followed by a phase tracking algorithm and polynomial regression algorithm to estimate the unknown parameters. We derive the Weighted Bayesian Cramer-Rao Bounds (WBCRBs) for joint carrier phase, Doppler shift and Doppler rate estimation, which take into account the prior distribution of the estimation parameters and are accurate lower bounds for all considered Signal to Noise Ratio (SNR) values. Numerical results (of bit error rate (BER) and the mean-square error (MSE) of parameter estimation) suggest that phase tracking with the random walk model slightly outperforms particle filtering. However, particle filtering has a lower computational cost than the random walk model based method.
Cell-Free Massive MIMO Detection: A Distributed Expectation Propagation Approach
Nov 28, 2021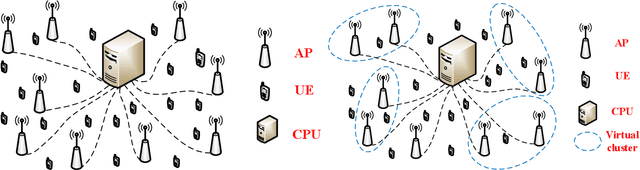
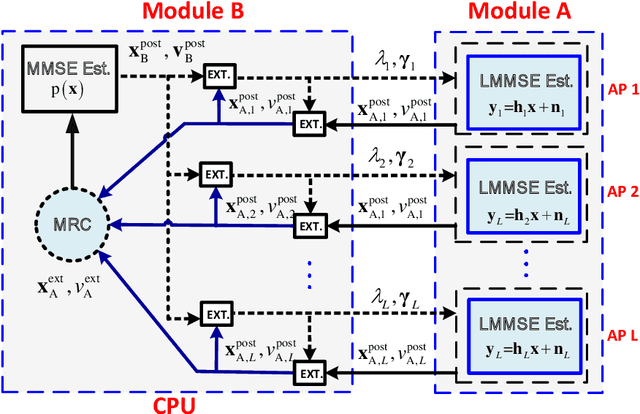
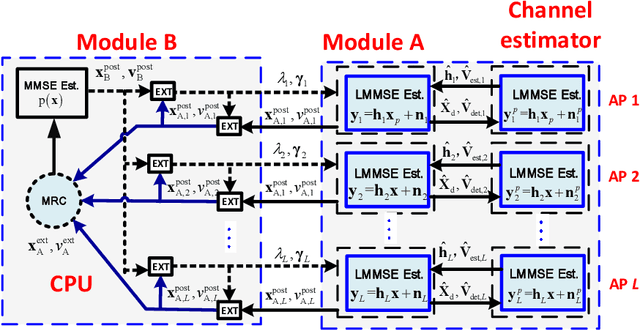
Cell-free massive MIMO is one of the core technologies for future wireless networks. It is expected to bring enormous benefits, including ultra-high reliability, data throughput, energy efficiency, and uniform coverage. As a radically distributed system, the performance of cell-free massive MIMO critically relies on efficient distributed processing algorithms. In this paper, we propose a distributed expectation propagation (EP) detector for cell-free massive MIMO, which consists of two modules: a nonlinear module at the central processing unit (CPU) and a linear module at each access point (AP). The turbo principle in iterative channel decoding is utilized to compute and pass the extrinsic information between the two modules. An analytical framework is provided to characterize the asymptotic performance of the proposed EP detector with a large number of antennas. Furthermore, a distributed joint channel estimation and data detection (JCD) algorithm is developed to handle the practical setting with imperfect channel state information (CSI). Simulation results will show that the proposed method outperforms existing detectors for cell-free massive MIMO systems in terms of the bit-error rate and demonstrate that the developed theoretical analysis accurately predicts system performance. Finally, it is shown that with imperfect CSI, the proposed JCD algorithm improves the system performance significantly and enables non-orthogonal pilots to reduce the pilot overhead.
Computer-aided Recognition and Assessment of a Porous Bioelastomer on Ultrasound Images for Regenerative Medicine Applications
Jan 31, 2022Biodegradable elastic scaffolds have attracted more and more attention in the field of soft tissue repair and tissue engineering. These scaffolds made of porous bioelastomers support tissue ingrowth along with their own degradation. It is necessary to develop a computer-aided analyzing method based on ultrasound images to identify the degradation performance of the scaffold, not only to obviate the need to do destructive testing, but also to monitor the scaffold's degradation and tissue ingrowth over time. It is difficult using a single traditional image processing algorithm to extract continuous and accurate contour of a porous bioelastomer. This paper proposes a joint algorithm for the bioelastomer's contour detection and a texture feature extraction method for monitoring the degradation behavior of the bioelastomer. Mean-shift clustering method is used to obtain the bioelastomer's and native tissue's clustering feature information. Then the OTSU image binarization method automatically selects the optimal threshold value to convert the grayscale ultrasound image into a binary image. The Canny edge detector is used to extract the complete bioelastomer's contour. The first-order and second-order statistical features of texture are extracted. The proposed joint algorithm not only achieves the ideal extraction of the bioelastomer's contours in ultrasound images, but also gives valuable feedback of the degradation behavior of the bioelastomer at the implant site based on the changes of texture characteristics and contour area. The preliminary results of this study suggest that the proposed computer-aided image processing techniques have values and potentials in the non-invasive analysis of tissue scaffolds in vivo based on ultrasound images and may help tissue engineers evaluate the tissue scaffold's degradation and cellular ingrowth progress and improve the scaffold designs.