 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Summarising and Comparing Agent Dynamics with Contrastive Spatiotemporal Abstraction
Jan 17, 2022
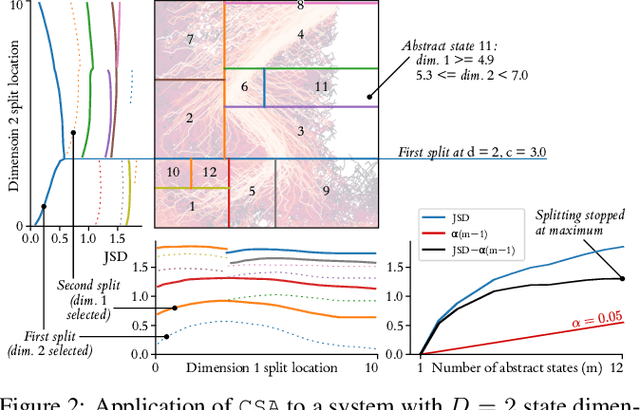
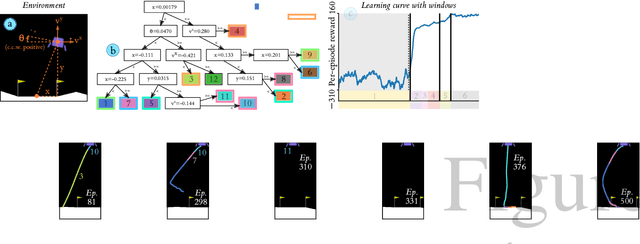
We introduce a data-driven, model-agnostic technique for generating a human-interpretable summary of the salient points of contrast within an evolving dynamical system, such as the learning process of a control agent. It involves the aggregation of transition data along both spatial and temporal dimensions according to an information-theoretic divergence measure. A practical algorithm is outlined for continuous state spaces, and deployed to summarise the learning histories of deep reinforcement learning agents with the aid of graphical and textual communication methods. We expect our method to be complementary to existing techniques in the realm of agent interpretability.
Gravitational Wave Detection and Information Extraction via Neural Networks
Mar 22, 2020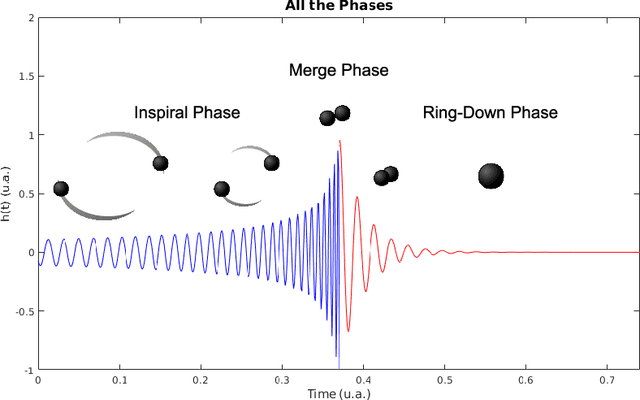
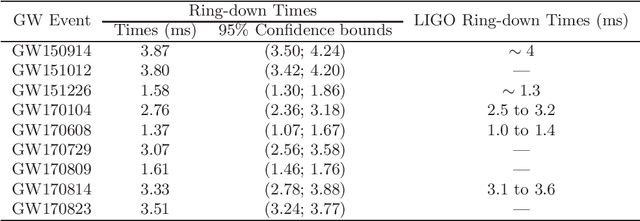
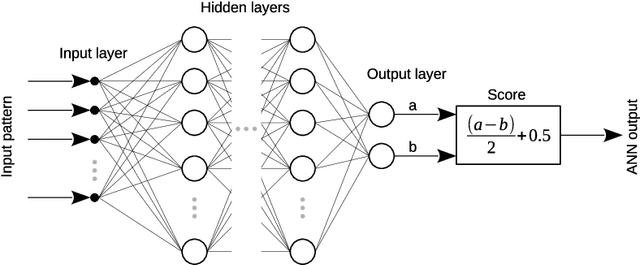
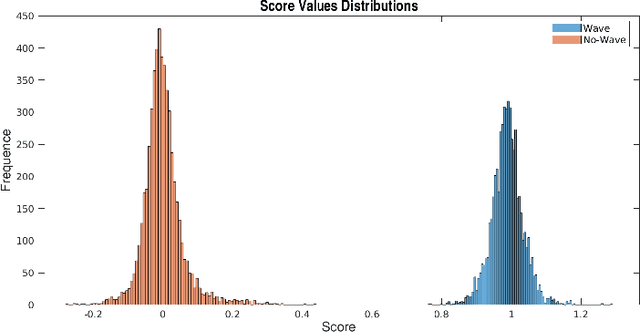
Laser Interferometer Gravitational-Wave Observatory (LIGO) was the first laboratory to measure the gravitational waves. It was needed an exceptional experimental design to measure distance changes much less than a radius of a proton. In the same way, the data analyses to confirm and extract information is a tremendously hard task. Here, it is shown a computational procedure base on artificial neural networks to detect a gravitation wave event and extract the knowledge of its ring-down time from the LIGO data. With this proposal, it is possible to make a probabilistic thermometer for gravitational wave detection and obtain physical information about the astronomical body system that created the phenomenon. Here, the ring-down time is determined with a direct data measure, without the need to use numerical relativity techniques and high computational power.
PerFED-GAN: Personalized Federated Learning via Generative Adversarial Networks
Feb 18, 2022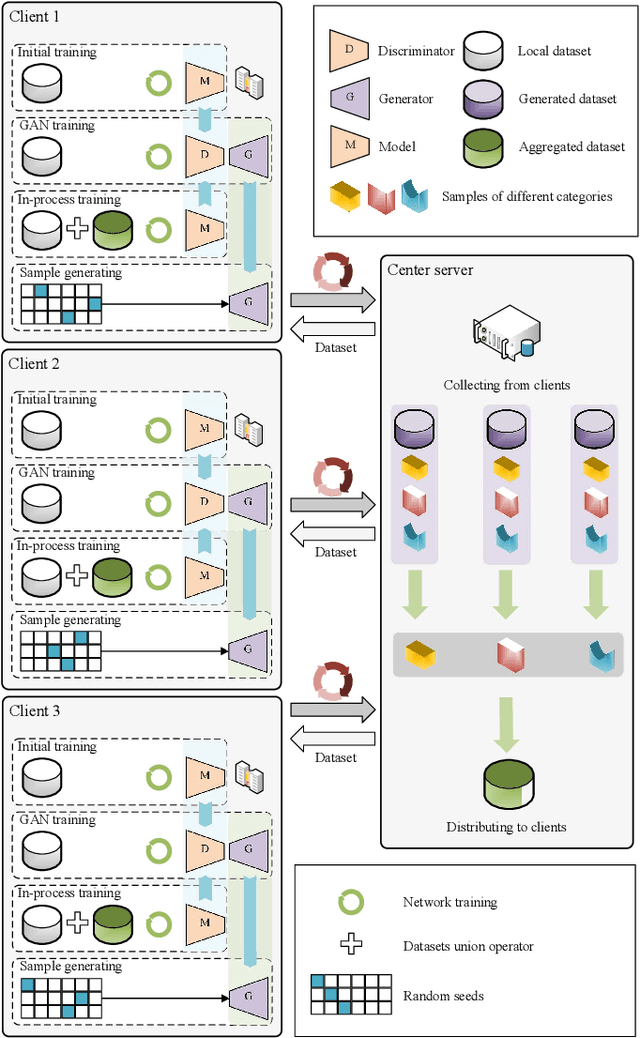
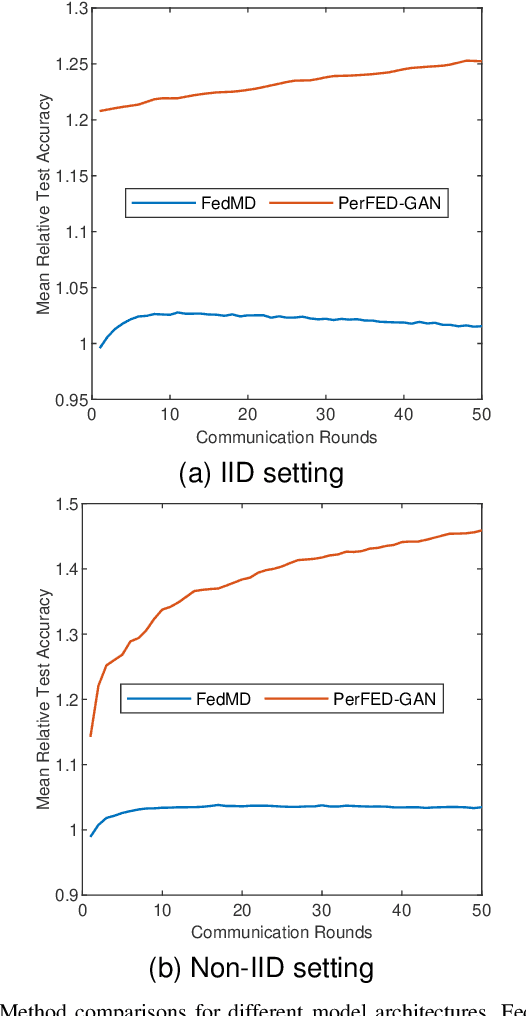
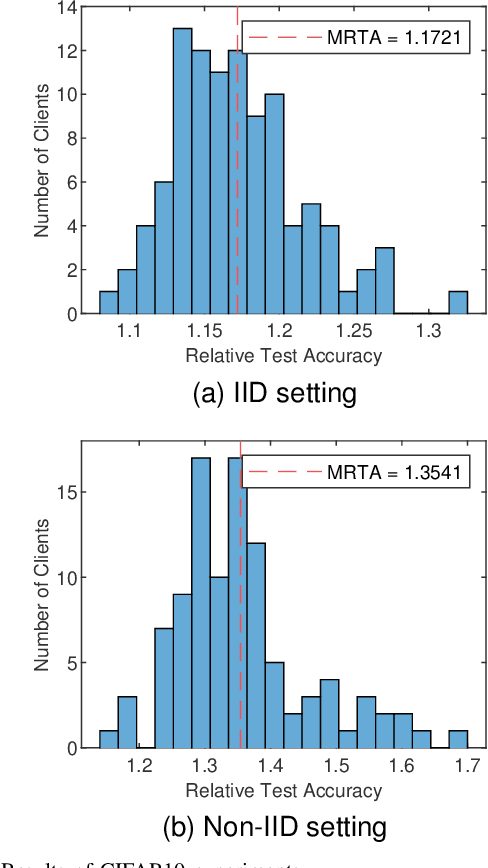
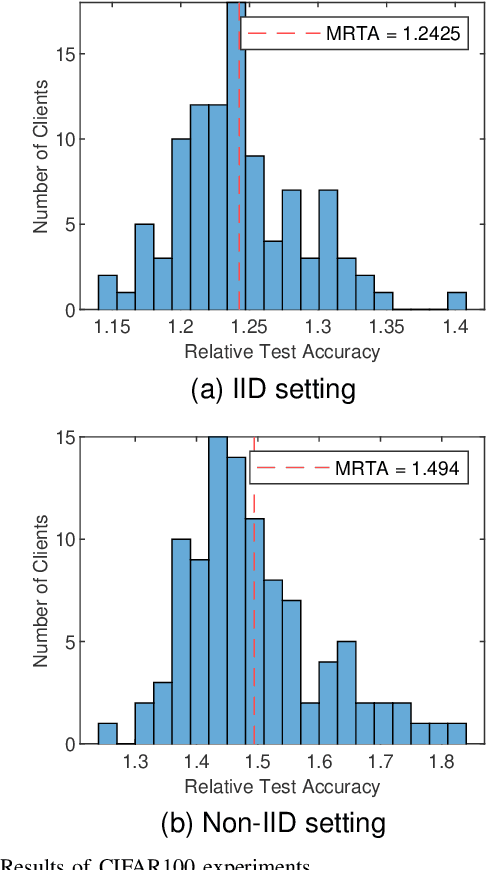
Federated learning is gaining popularity as a distributed machine learning method that can be used to deploy AI-dependent IoT applications while protecting client data privacy and security. Due to the differences of clients, a single global model may not perform well on all clients, so the personalized federated learning method, which trains a personalized model for each client that better suits its individual needs, becomes a research hotspot. Most personalized federated learning research, however, focuses on data heterogeneity while ignoring the need for model architecture heterogeneity. Most existing federated learning methods uniformly set the model architecture of all clients participating in federated learning, which is inconvenient for each client's individual model and local data distribution requirements, and also increases the risk of client model leakage. This paper proposes a federated learning method based on co-training and generative adversarial networks(GANs) that allows each client to design its own model to participate in federated learning training independently without sharing any model architecture or parameter information with other clients or a center. In our experiments, the proposed method outperforms the existing methods in mean test accuracy by 42% when the client's model architecture and data distribution vary significantly.
Tell me what you see: A zero-shot action recognition method based on natural language descriptions
Dec 18, 2021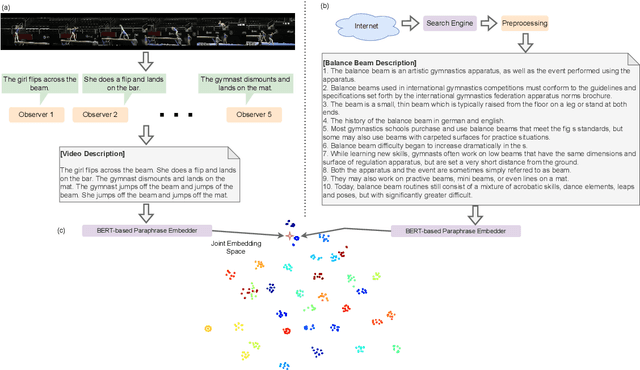
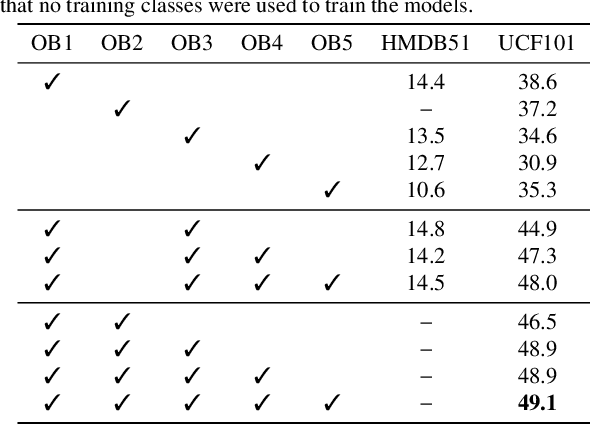

Recently, several approaches have explored the detection and classification of objects in videos to perform Zero-Shot Action Recognition with remarkable results. In these methods, class-object relationships are used to associate visual patterns with the semantic side information because these relationships also tend to appear in texts. Therefore, word vector methods would reflect them in their latent representations. Inspired by these methods and by video captioning's ability to describe events not only with a set of objects but with contextual information, we propose a method in which video captioning models, called observers, provide different and complementary descriptive sentences. We demonstrate that representing videos with descriptive sentences instead of deep features, in ZSAR, is viable and naturally alleviates the domain adaptation problem, as we reached state-of-the-art (SOTA) performance on the UCF101 dataset and competitive performance on HMDB51 without their training sets. We also demonstrate that word vectors are unsuitable for building the semantic embedding space of our descriptions. Thus, we propose to represent the classes with sentences extracted from documents acquired with search engines on the Internet, without any human evaluation on the quality of descriptions. Lastly, we build a shared semantic space employing BERT-based embedders pre-trained in the paraphrasing task on multiple text datasets. We show that this pre-training is essential for bridging the semantic gap. The projection onto this space is straightforward for both types of information, visual and semantic, because they are sentences, enabling the classification with nearest neighbour rule in this shared space. Our code is available at https://github.com/valterlej/zsarcap.
TempoQR: Temporal Question Reasoning over Knowledge Graphs
Dec 10, 2021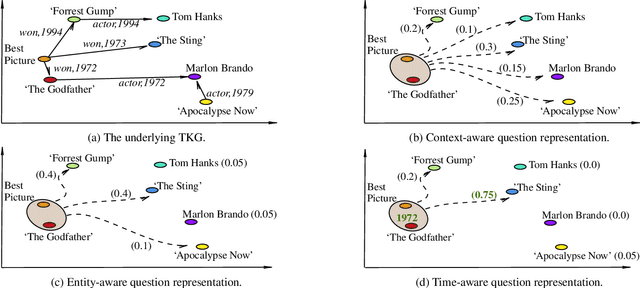

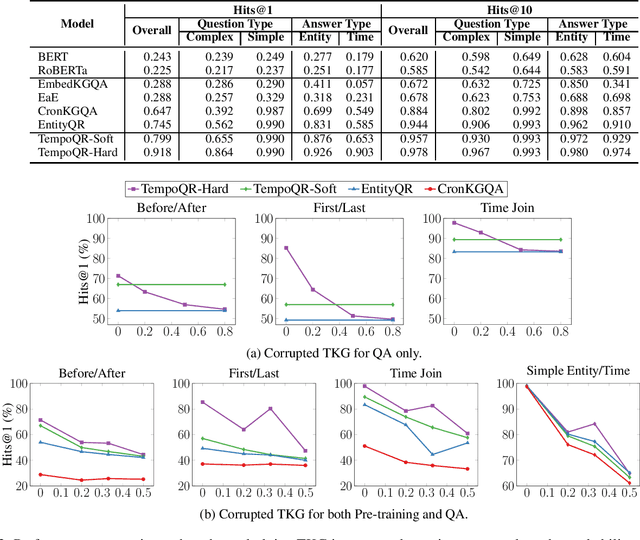
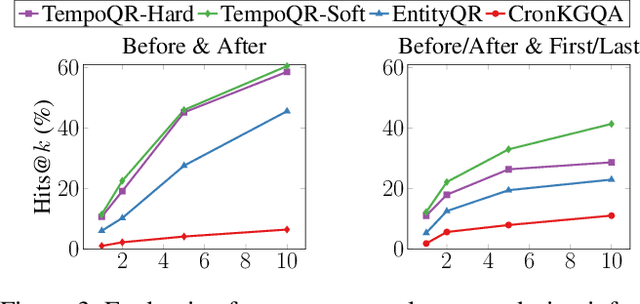
Knowledge Graph Question Answering (KGQA) involves retrieving facts from a Knowledge Graph (KG) using natural language queries. A KG is a curated set of facts consisting of entities linked by relations. Certain facts include also temporal information forming a Temporal KG (TKG). Although many natural questions involve explicit or implicit time constraints, question answering (QA) over TKGs has been a relatively unexplored area. Existing solutions are mainly designed for simple temporal questions that can be answered directly by a single TKG fact. This paper puts forth a comprehensive embedding-based framework for answering complex questions over TKGs. Our method termed temporal question reasoning (TempoQR) exploits TKG embeddings to ground the question to the specific entities and time scope it refers to. It does so by augmenting the question embeddings with context, entity and time-aware information by employing three specialized modules. The first computes a textual representation of a given question, the second combines it with the entity embeddings for entities involved in the question, and the third generates question-specific time embeddings. Finally, a transformer-based encoder learns to fuse the generated temporal information with the question representation, which is used for answer predictions. Extensive experiments show that TempoQR improves accuracy by 25--45 percentage points on complex temporal questions over state-of-the-art approaches and it generalizes better to unseen question types.
Energy Efficient Dual-Functional Radar-Communication: Rate-Splitting Multiple Access, Low-Resolution DACs, and RF Chain Selection
Feb 18, 2022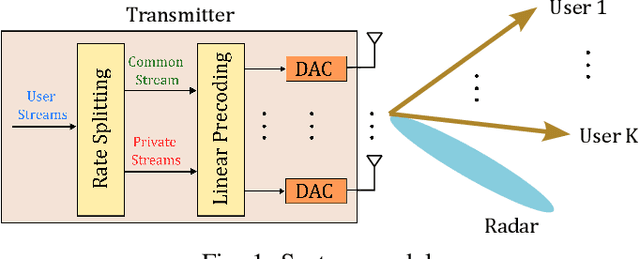
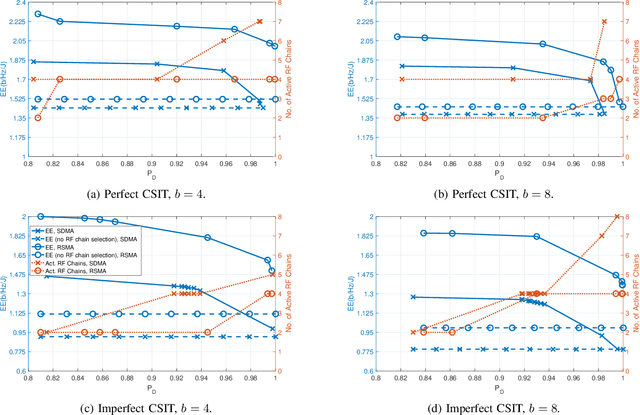
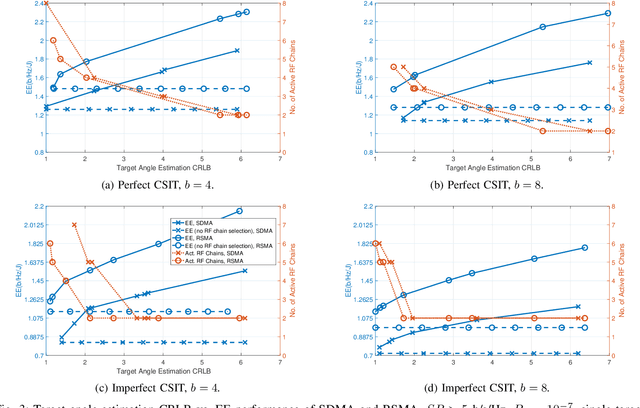
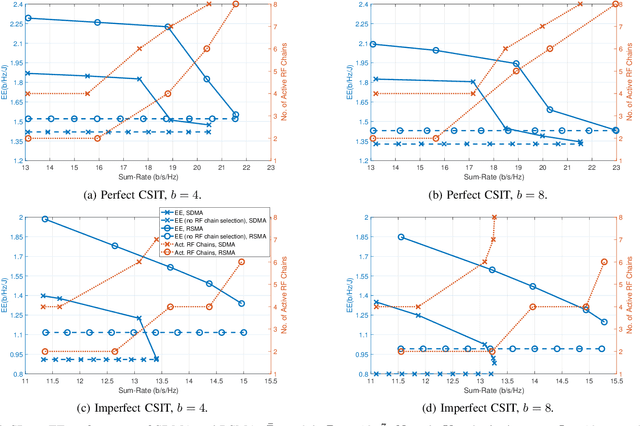
Dual-Functional Radar-Communication systems enhance the benefits of communications and radar sensing by jointly implementing these on the same hardware platform and using the common RF resources. An important and latest concern to be addressed in designing such Dual-Functional Radar-Communication systems is maximizing the energy-efficiency. In this paper, we consider a Dual-Functional Radar-Communication system performing simultaneous multi-user communications and radar sensing, and investigate the energy-efficiency behaviour with respect to active transmission elements. Specifically, we formulate a problem to find the optimal precoders and the number of active RF chains for maximum energy-efficiency by taking into consideration the power consumption of low-resolution Digital-to-Analog Converters on each RF chain under communications and radar performance constraints. We consider Rate-Splitting Multiple Access to perform multi-user communications with perfect and imperfect Channel State Information at Transmitter. The formulated non-convex optimization problem is solved by means of a novel algorithm. We demonstrate by numerical results that Rate Splitting Multiple Access achieves an improved energy-efficiency by employing a smaller number of RF chains compared to Space Division Multiple Access, owing to its generalized structure and improved interference management capabilities.
Classification on Sentence Embeddings for Legal Assistance
Feb 05, 2022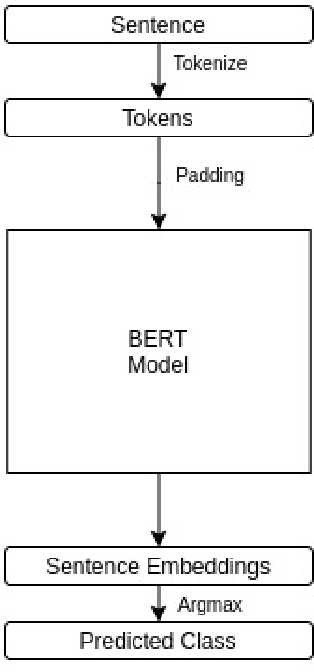
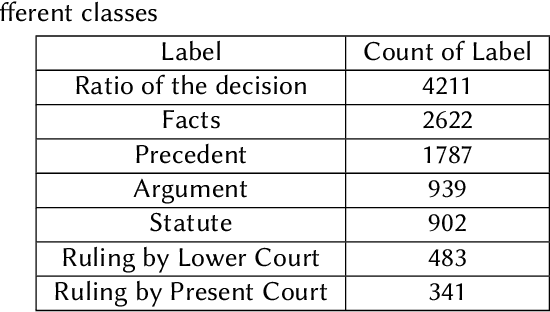
Legal proceedings take plenty of time and also cost a lot. The lawyers have to do a lot of work in order to identify the different sections of prior cases and statutes. The paper tries to solve the first tasks in AILA2021 (Artificial Intelligence for Legal Assistance) that will be held in FIRE2021 (Forum for Information Retrieval Evaluation). The task is to semantically segment the document into different assigned one of the 7 predefined labels or "rhetorical roles." The paper uses BERT to obtain the sentence embeddings from a sentence, and then a linear classifier is used to output the final prediction. The experiments show that when more weightage is assigned to the class with the highest frequency, the results are better than those when more weightage is given to the class with a lower frequency. In task 1, the team legalNLP obtained a F1 score of 0.22.
Framework for Network-Constrained Target Tracking
Mar 02, 2022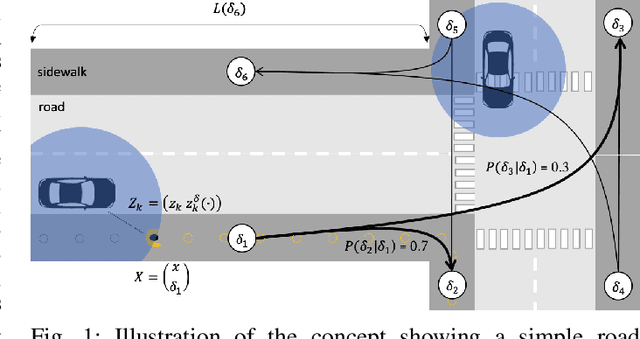
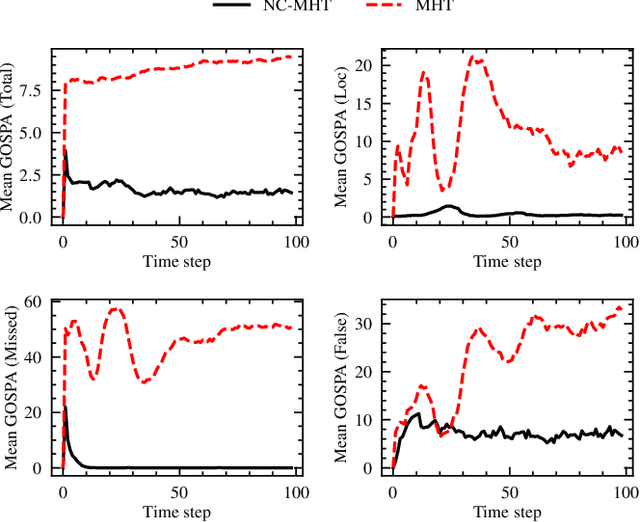
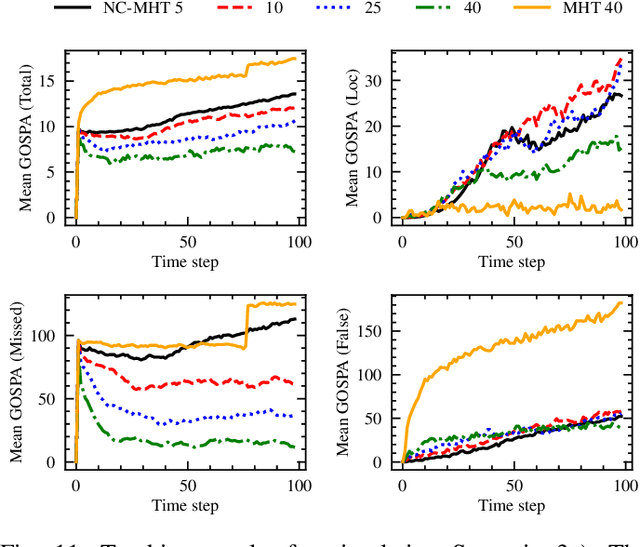
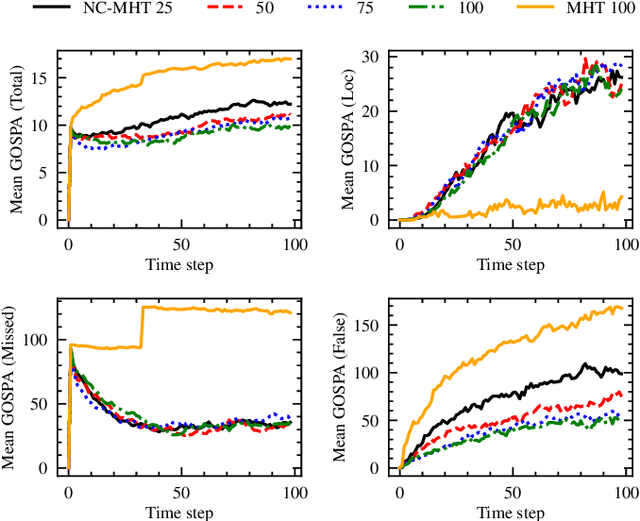
The increase in perception capabilities of connected mobile sensor platforms (e.g., self-driving vehicles, drones, and robots) leads to an extensive surge of sensed features at various temporal and spatial scales. Beyond their traditional use for safe operation, available observations could enable to see how and where people move on sidewalks and cycle paths, to eventually obtain a complete microscopic and macroscopic picture of the traffic flows in a larger area. This paper proposes a new method for advanced traffic applications, tracking an unknown and varying number of moving targets (e.g., pedestrians or cyclists) constrained by a road network, using mobile (e.g., vehicles) spatially distributed sensor platforms. The key contribution in this paper is to introduce the concept of network bound targets into the multi-target tracking problem, and hence to derive a network-constrained multi-hypotheses tracker (NC-MHT) to fully utilize the available road information. This is done by introducing a target representation, comprising a traditional target tracking representation and a discrete component placing the target on a given segment in the network. A simulation study shows that the method performs well in comparison to the standard MHT filter in free space. Results particularly highlight network-constraint effects for more efficient target predictions over extended periods of time, and in the simplification of the measurement association process, as compared to not utilizing a network structure. This theoretical work also directs attention to latent privacy concerns for potential applications.
Training Differentially Private Models with Secure Multiparty Computation
Feb 05, 2022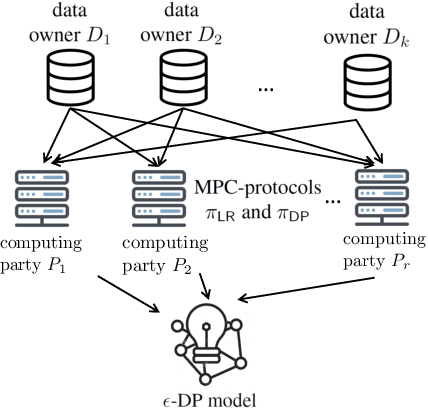

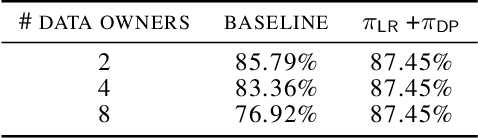

We address the problem of learning a machine learning model from training data that originates at multiple data owners while providing formal privacy guarantees regarding the protection of each owner's data. Existing solutions based on Differential Privacy (DP) achieve this at the cost of a drop in accuracy. Solutions based on Secure Multiparty Computation (MPC) do not incur such accuracy loss but leak information when the trained model is made publicly available. We propose an MPC solution for training DP models. Our solution relies on an MPC protocol for model training, and an MPC protocol for perturbing the trained model coefficients with Laplace noise in a privacy-preserving manner. The resulting MPC+DP approach achieves higher accuracy than a pure DP approach while providing the same formal privacy guarantees. Our work obtained first place in the iDASH2021 Track III competition on confidential computing for secure genome analysis.
Dynamic Hypergraph Convolutional Networks for Skeleton-Based Action Recognition
Dec 20, 2021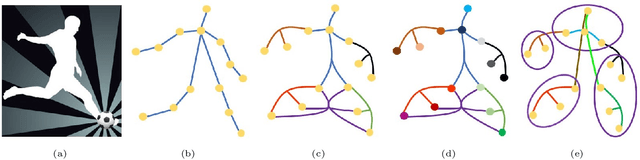
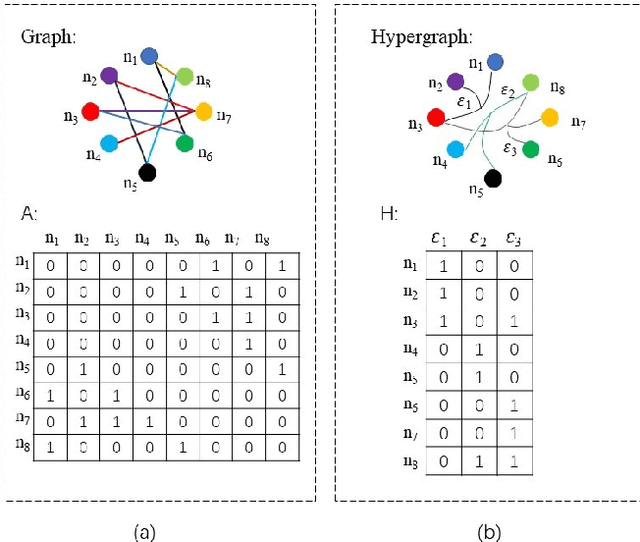

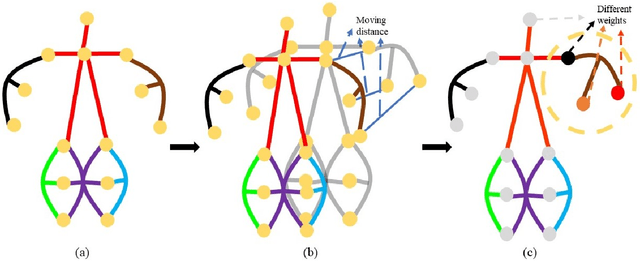
Graph convolutional networks (GCNs) based methods have achieved advanced performance on skeleton-based action recognition task. However, the skeleton graph cannot fully represent the motion information contained in skeleton data. In addition, the topology of the skeleton graph in the GCN-based methods is manually set according to natural connections, and it is fixed for all samples, which cannot well adapt to different situations. In this work, we propose a novel dynamic hypergraph convolutional networks (DHGCN) for skeleton-based action recognition. DHGCN uses hypergraph to represent the skeleton structure to effectively exploit the motion information contained in human joints. Each joint in the skeleton hypergraph is dynamically assigned the corresponding weight according to its moving, and the hypergraph topology in our model can be dynamically adjusted to different samples according to the relationship between the joints. Experimental results demonstrate that the performance of our model achieves competitive performance on three datasets: Kinetics-Skeleton 400, NTU RGB+D 60, and NTU RGB+D 120.