 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Robust PCA Unrolling Network for Super-resolution Vessel Extraction in X-ray Coronary Angiography
Apr 16, 2022
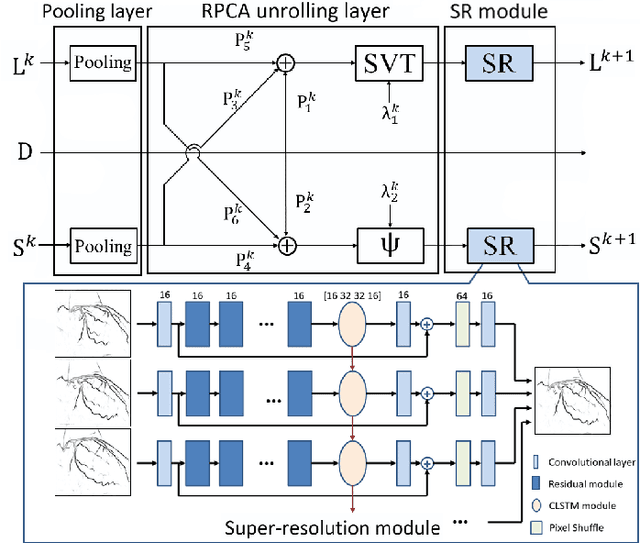
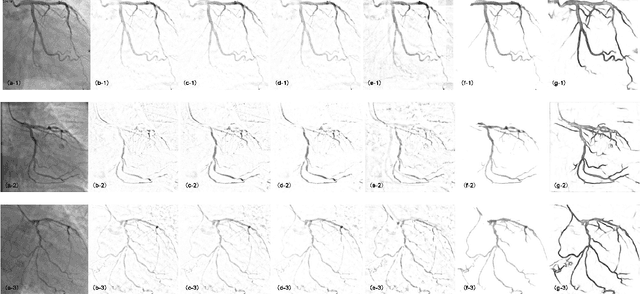

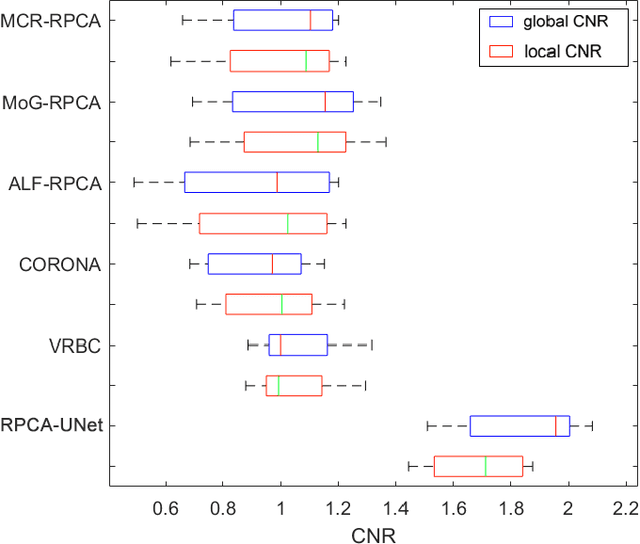
Although robust PCA has been increasingly adopted to extract vessels from X-ray coronary angiography (XCA) images, challenging problems such as inefficient vessel-sparsity modelling, noisy and dynamic background artefacts, and high computational cost still remain unsolved. Therefore, we propose a novel robust PCA unrolling network with sparse feature selection for super-resolution XCA vessel imaging. Being embedded within a patch-wise spatiotemporal super-resolution framework that is built upon a pooling layer and a convolutional long short-term memory network, the proposed network can not only gradually prune complex vessel-like artefacts and noisy backgrounds in XCA during network training but also iteratively learn and select the high-level spatiotemporal semantic information of moving contrast agents flowing in the XCA-imaged vessels. The experimental results show that the proposed method significantly outperforms state-of-the-art methods, especially in the imaging of the vessel network and its distal vessels, by restoring the intensity and geometry profiles of heterogeneous vessels against complex and dynamic backgrounds.
Second Order Regret Bounds Against Generalized Expert Sequences under Partial Bandit Feedback
Apr 13, 2022We study the problem of expert advice under partial bandit feedback setting and create a sequential minimax optimal algorithm. Our algorithm works with a more general partial monitoring setting, where, in contrast to the classical bandit feedback, the losses can be revealed in an adversarial manner. Our algorithm adopts a universal prediction perspective, whose performance is analyzed with regret against a general expert selection sequence. The regret we study is against a general competition class that covers many settings (such as the switching or contextual experts settings) and the expert selection sequences in the competition class are determined by the application at hand. Our regret bounds are second order bounds in terms of the sum of squared losses and the normalized regret of our algorithm is invariant under arbitrary affine transforms of the loss sequence. Our algorithm is truly online and does not use any preliminary information about the loss sequences.
A Tech Hybrid-Recommendation Engine and Personalized Notification: An integrated tool to assist users through Recommendations (Project ATHENA)
Feb 13, 2022
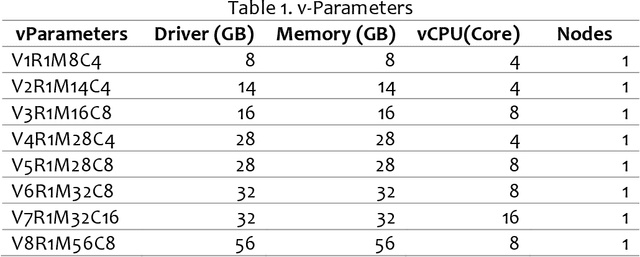
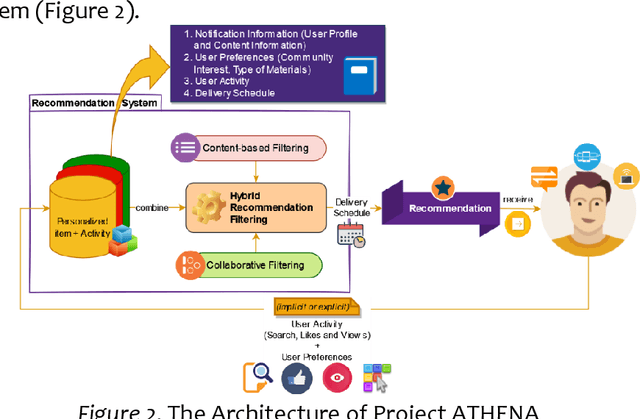
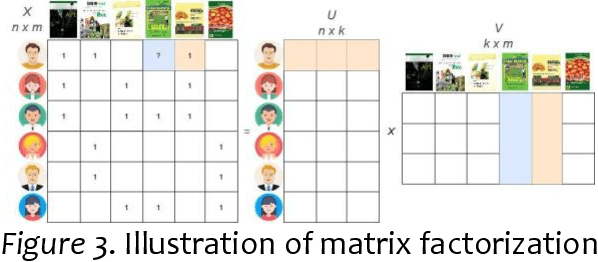
Project ATHENA aims to develop an application to address information overload, primarily focused on Recommendation Systems (RSs) with the personalization and user experience design of a modern system. Two machine learning (ML) algorithms were used: (1) TF-IDF for Content-based filtering (CBF); (2) Classification with Matrix Factorization- Singular Value Decomposition(SVD) applied with Collaborative filtering (CF) and mean (normalization) for prediction accuracy of the CF. Data sampling in academic Research and Development of Philippine Council for Agriculture, Aquatic, and Natural Resources Research and Development (PCAARRD) e-Library and Project SARAI publications plus simulated data used as training sets to generate a recommendation of items that uses the three RS filtering (CF, CBF, and personalized version of item recommendations). Series of Testing and TAM performed and discussed. Findings allow users to engage in online information and quickly evaluate retrieved items produced by the application. Compatibility-testing (CoT) shows the application is compatible with all major browsers and mobile-friendly. Performance-testing (PT) recommended v-parameter specs and TAM evaluations results indicate strongly associated with overall positive feedback, thoroughly enough to address the information-overload problem as the core of the paper. A modular architecture presented addressing the information overload, primarily focused on RSs with the personalization and design of modern systems. Developers utilized Two ML algorithms and prototyped a simplified version of the architecture. Series of testing (CoT and PT) and evaluations with TAM were performed and discussed. Project ATHENA added a UX feature design of a modern system.
Unified Simultaneous Wireless Information and Power Transfer for IoT: Signaling and Architecture with Deep Learning Adaptive Control
Jun 26, 2021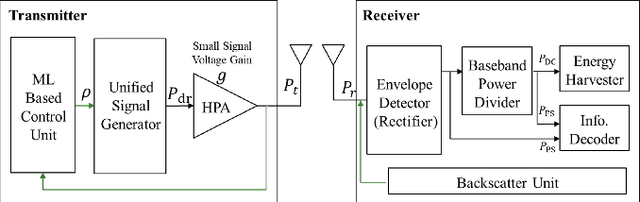
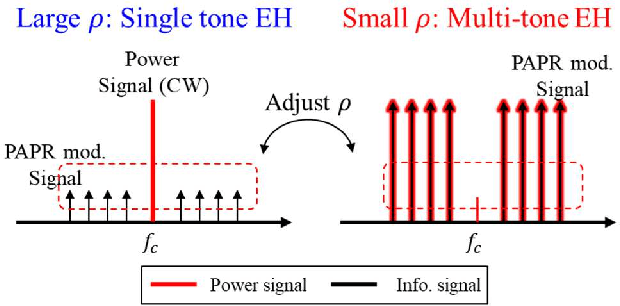
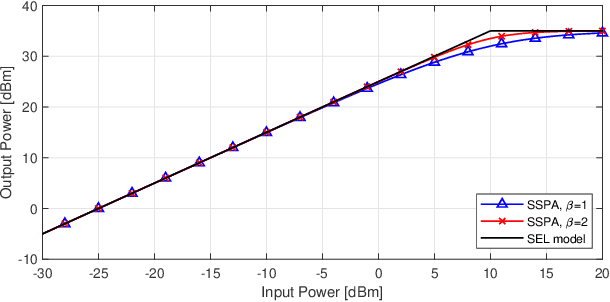
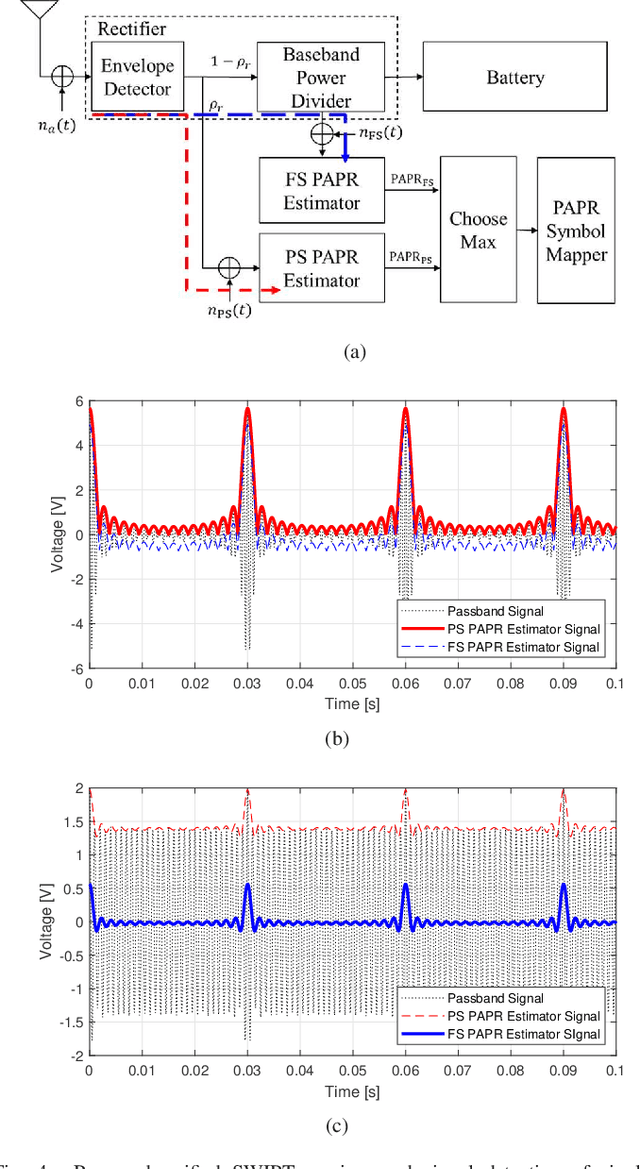
In this paper, we propose a unified SWIPT signal and its architecture design in order to take advantage of both single tone and multi-tone signaling by adjusting only the power allocation ratio of a unified signal. For this, we design a novel unified and integrated receiver architecture for the proposed unified SWIPT signaling, which consumes low power with an envelope detection. To relieve the computational complexity of the receiver, we propose an adaptive control algorithm by which the transmitter adjusts the communication mode through temporal convolutional network (TCN) based asymmetric processing. To this end, the transmitter optimizes the modulation index and power allocation ratio in short-term scale while updating the mode switching threshold in long-term scale. We demonstrate that the proposed unified SWIPT system improves the achievable rate under the self-powering condition of low-power IoT devices. Consequently it is foreseen to effectively deploy low-power IoT networks that concurrently supply both information and energy wirelessly to the devices by using the proposed unified SWIPT and adaptive control algorithm in place at the transmitter side.
A Novel Approach for Optimum-Path Forest Classification Using Fuzzy Logic
Apr 13, 2022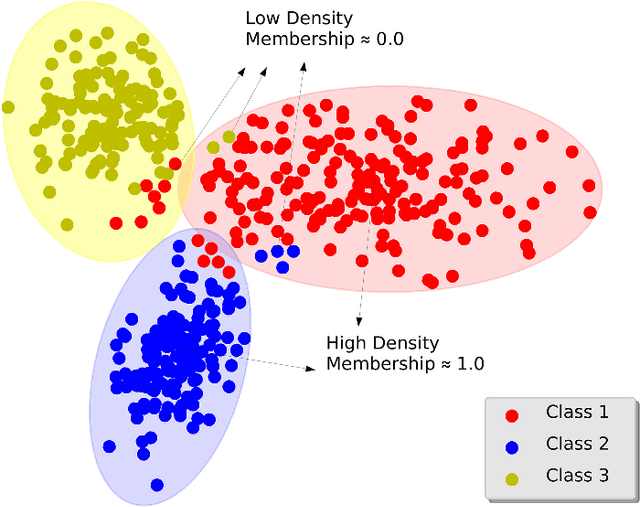
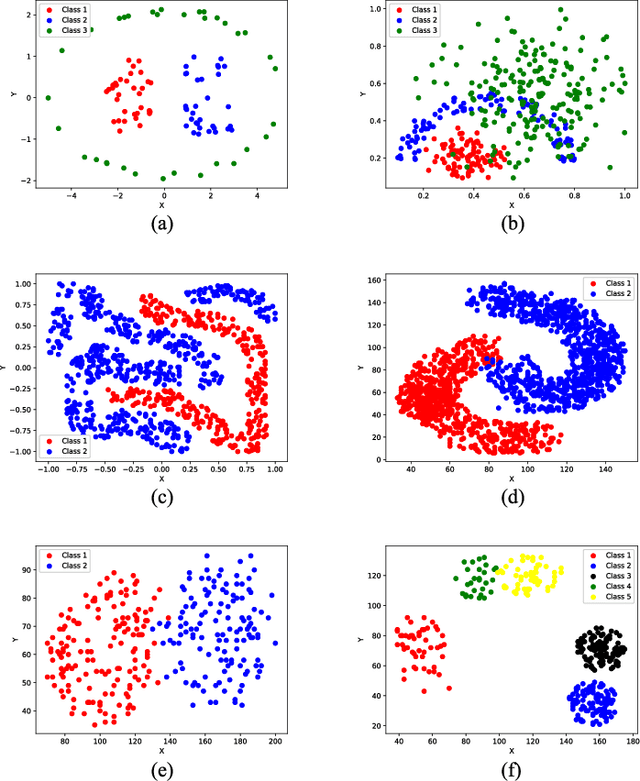

In the past decades, fuzzy logic has played an essential role in many research areas. Alongside, graph-based pattern recognition has shown to be of great importance due to its flexibility in partitioning the feature space using the background from graph theory. Some years ago, a new framework for both supervised, semi-supervised, and unsupervised learning named Optimum-Path Forest (OPF) was proposed with competitive results in several applications, besides comprising a low computational burden. In this paper, we propose the Fuzzy Optimum-Path Forest, an improved version of the standard OPF classifier that learns the samples' membership in an unsupervised fashion, which are further incorporated during supervised training. Such information is used to identify the most relevant training samples, thus improving the classification step. Experiments conducted over twelve public datasets highlight the robustness of the proposed approach, which behaves similarly to standard OPF in worst-case scenarios.
neuro2vec: Masked Fourier Spectrum Prediction for Neurophysiological Representation Learning
Apr 20, 2022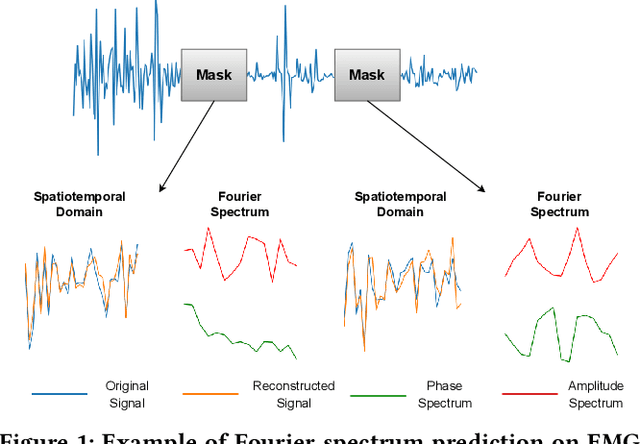
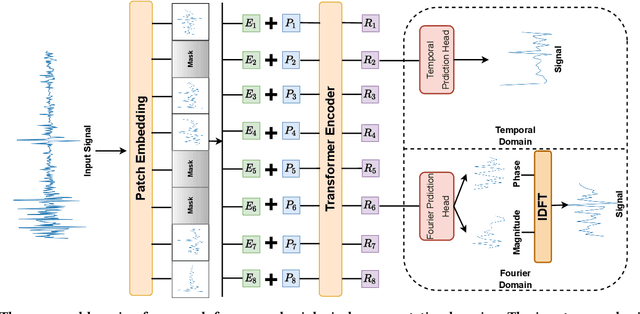
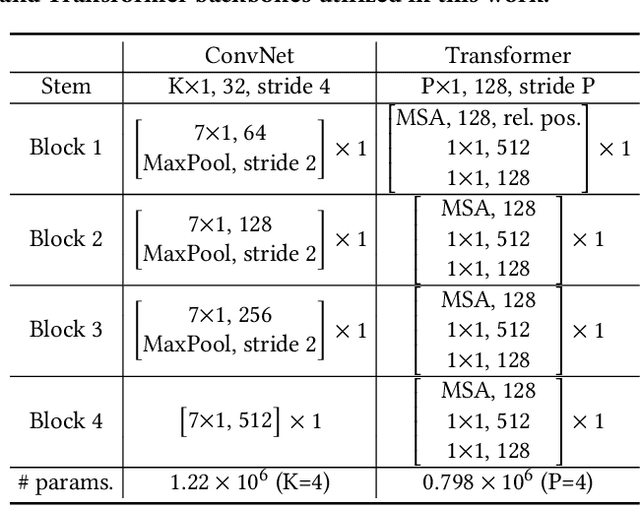
Extensive data labeling on neurophysiological signals is often prohibitively expensive or impractical, as it may require particular infrastructure or domain expertise. To address the appetite for data of deep learning methods, we present for the first time a Fourier-based modeling framework for self-supervised pre-training of neurophysiology signals. The intuition behind our approach is simple: frequency and phase distribution of neurophysiology signals reveal the underlying neurophysiological activities of the brain and muscle. Our approach first randomly masks out a portion of the input signal and then predicts the missing information from either spatiotemporal or the Fourier domain. Pre-trained models can be potentially used for downstream tasks such as sleep stage classification using electroencephalogram (EEG) signals and gesture recognition using electromyography (EMG) signals. Unlike contrastive-based methods, which strongly rely on carefully hand-crafted augmentations and siamese structure, our approach works reasonably well with a simple transformer encoder with no augmentation requirements. By evaluating our method on several benchmark datasets, including both EEG and EMG, we show that our modeling approach improves downstream neurophysiological related tasks by a large margin.
INSIDE: Steering Spatial Attention with Non-Imaging Information in CNNs
Aug 21, 2020We consider the problem of integrating non-imaging information into segmentation networks to improve performance. Conditioning layers such as FiLM provide the means to selectively amplify or suppress the contribution of different feature maps in a linear fashion. However, spatial dependency is difficult to learn within a convolutional paradigm. In this paper, we propose a mechanism to allow for spatial localisation conditioned on non-imaging information, using a feature-wise attention mechanism comprising a differentiable parametrised function (e.g. Gaussian), prior to applying the feature-wise modulation. We name our method INstance modulation with SpatIal DEpendency (INSIDE). The conditioning information might comprise any factors that relate to spatial or spatio-temporal information such as lesion location, size, and cardiac cycle phase. Our method can be trained end-to-end and does not require additional supervision. We evaluate the method on two datasets: a new CLEVR-Seg dataset where we segment objects based on location, and the ACDC dataset conditioned on cardiac phase and slice location within the volume. Code and the CLEVR-Seg dataset are available at https://github.com/jacenkow/inside.
Clifford Circuits can be Properly PAC Learned if and only if $\textsf{RP}=\textsf{NP}$
Apr 20, 2022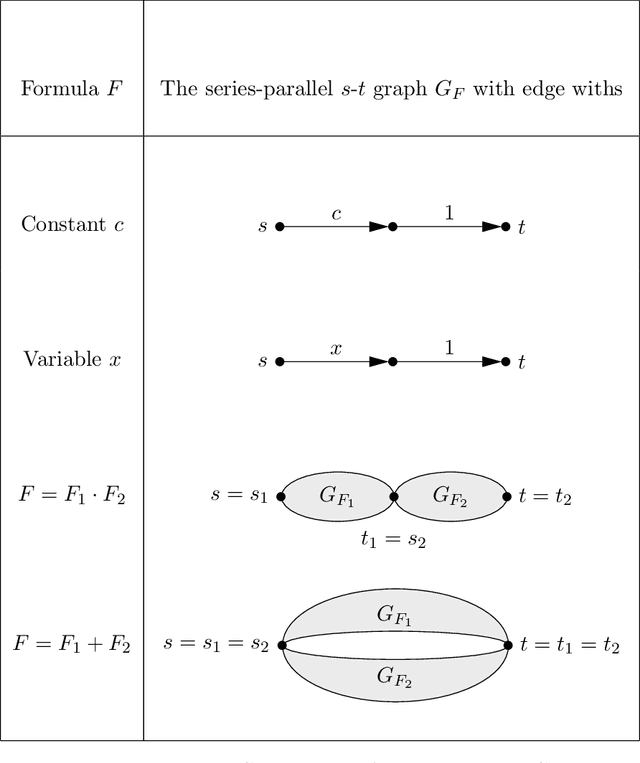
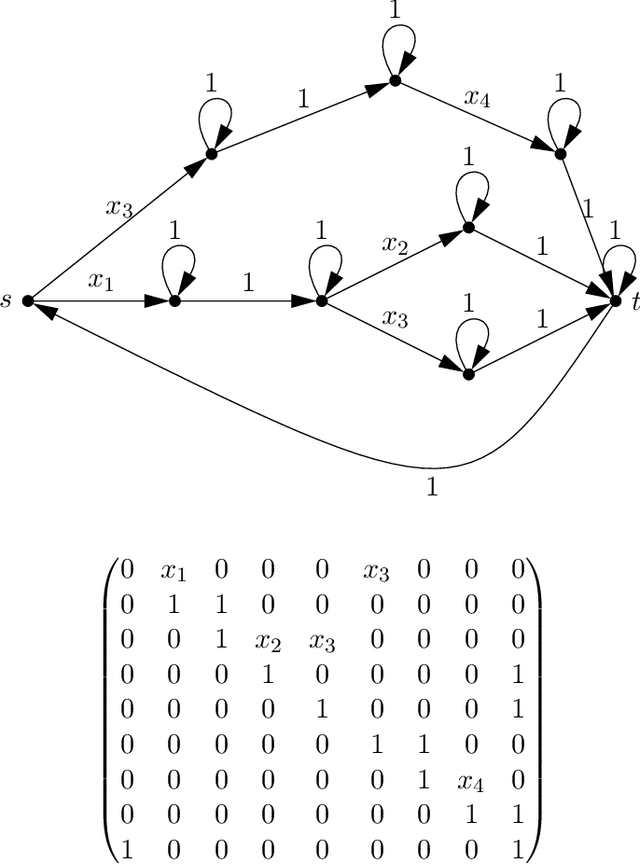
Given a dataset of input states, measurements, and probabilities, is it possible to efficiently predict the measurement probabilities associated with a quantum circuit? Recent work of Caro and Datta (2020) studied the problem of PAC learning quantum circuits in an information theoretic sense, leaving open questions of computational efficiency. In particular, one candidate class of circuits for which an efficient learner might have been possible was that of Clifford circuits, since the corresponding set of states generated by such circuits, called stabilizer states, are known to be efficiently PAC learnable (Rocchetto 2018). Here we provide a negative result, showing that proper learning of CNOT circuits is hard for classical learners unless $\textsf{RP} = \textsf{NP}$. As the classical analogue and subset of Clifford circuits, this naturally leads to a hardness result for Clifford circuits as well. Additionally, we show that if $\textsf{RP} = \textsf{NP}$ then there would exist efficient proper learning algorithms for CNOT and Clifford circuits. By similar arguments, we also find that an efficient proper quantum learner for such circuits exists if and only if $\textsf{NP} \subseteq \textsf{RQP}$.
Improving Named Entity Recognition with Attentive Ensemble of Syntactic Information
Oct 29, 2020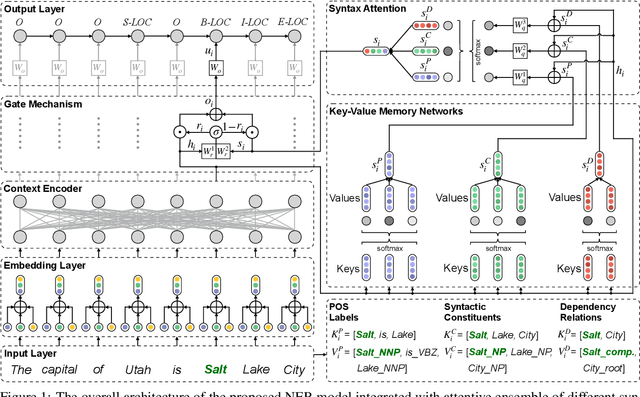
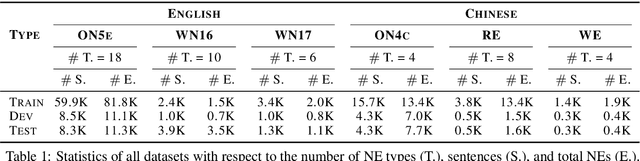
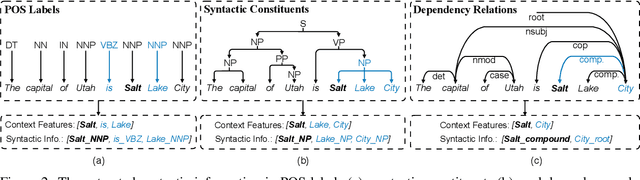
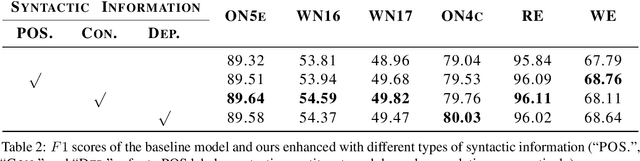
Named entity recognition (NER) is highly sensitive to sentential syntactic and semantic properties where entities may be extracted according to how they are used and placed in the running text. To model such properties, one could rely on existing resources to providing helpful knowledge to the NER task; some existing studies proved the effectiveness of doing so, and yet are limited in appropriately leveraging the knowledge such as distinguishing the important ones for particular context. In this paper, we improve NER by leveraging different types of syntactic information through attentive ensemble, which functionalizes by the proposed key-value memory networks, syntax attention, and the gate mechanism for encoding, weighting and aggregating such syntactic information, respectively. Experimental results on six English and Chinese benchmark datasets suggest the effectiveness of the proposed model and show that it outperforms previous studies on all experiment datasets.
TTAGN: Temporal Transaction Aggregation Graph Network for Ethereum Phishing Scams Detection
Apr 28, 2022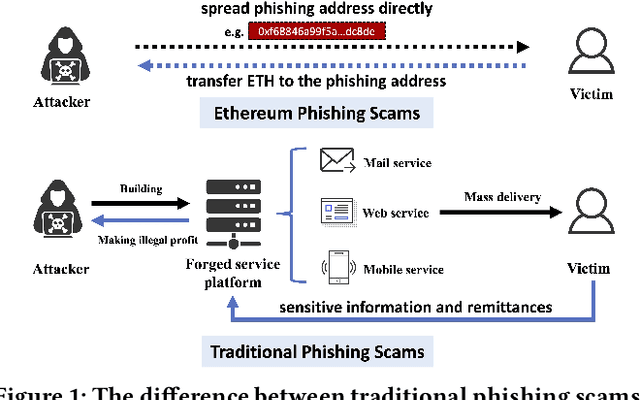
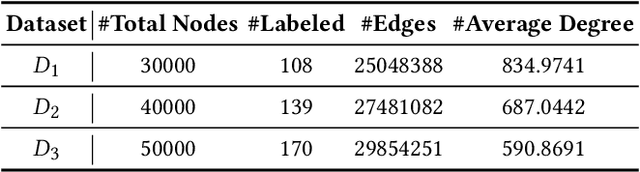
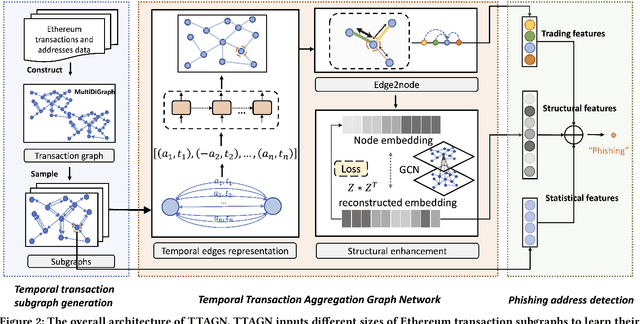
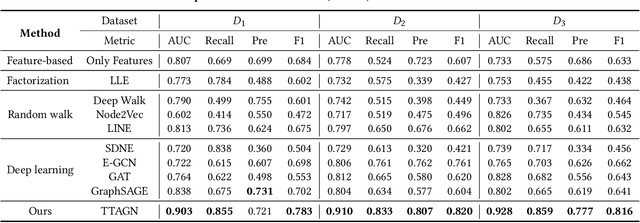
In recent years, phishing scams have become the most serious type of crime involved in Ethereum, the second-largest blockchain platform. The existing phishing scams detection technology on Ethereum mostly uses traditional machine learning or network representation learning to mine the key information from the transaction network to identify phishing addresses. However, these methods adopt the last transaction record or even completely ignore these records, and only manual-designed features are taken for the node representation. In this paper, we propose a Temporal Transaction Aggregation Graph Network (TTAGN) to enhance phishing scams detection performance on Ethereum. Specifically, in the temporal edges representation module, we model the temporal relationship of historical transaction records between nodes to construct the edge representation of the Ethereum transaction network. Moreover, the edge representations around the node are aggregated to fuse topological interactive relationships into its representation, also named as trading features, in the edge2node module. We further combine trading features with common statistical and structural features obtained by graph neural networks to identify phishing addresses. Evaluated on real-world Ethereum phishing scams datasets, our TTAGN (92.8% AUC, and 81.6% F1score) outperforms the state-of-the-art methods, and the effectiveness of temporal edges representation and edge2node module is also demonstrated.