 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Can deep learning match the efficiency of human visual long-term memory in storing object details?
Apr 28, 2022

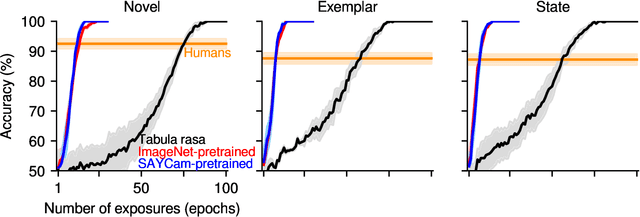
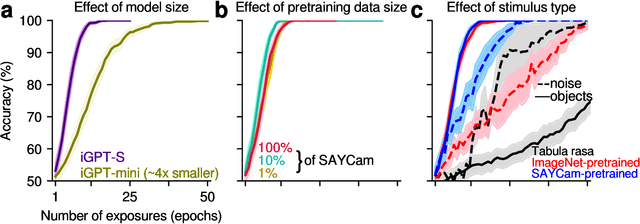
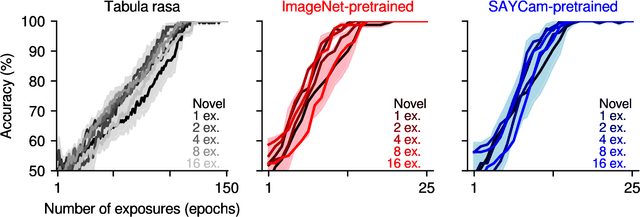
Humans have a remarkably large capacity to store detailed visual information in long-term memory even after a single exposure, as demonstrated by classic experiments in psychology. For example, Standing (1973) showed that humans could recognize with high accuracy thousands of pictures that they had seen only once a few days prior to a recognition test. In deep learning, the primary mode of incorporating new information into a model is through gradient descent in the model's parameter space. This paper asks whether deep learning via gradient descent can match the efficiency of human visual long-term memory to incorporate new information in a rigorous, head-to-head, quantitative comparison. We answer this in the negative: even in the best case, models learning via gradient descent appear to require approximately 10 exposures to the same visual materials in order to reach a recognition memory performance humans achieve after only a single exposure. Prior knowledge induced via pretraining and bigger model sizes improve performance, but these improvements are not very visible after a single exposure (it takes a few exposures for the improvements to become apparent), suggesting that simply scaling up the pretraining data size or model size might not be enough for the model to reach human-level memory efficiency.
Diffusion Models for Video Prediction and Infilling
Jun 15, 2022



To predict and anticipate future outcomes or reason about missing information in a sequence is a key ability for agents to be able to make intelligent decisions. This requires strong temporally coherent generative capabilities. Diffusion models have shown huge success in several generative tasks lately, but have not been extensively explored in the video domain. We present Random-Mask Video Diffusion (RaMViD), which extends image diffusion models to videos using 3D convolutions, and introduces a new conditioning technique during training. By varying the mask we condition on, the model is able to perform video prediction, infilling and upsampling. Since we do not use concatenation to condition on a mask, as done in most conditionally trained diffusion models, we are able to decrease the memory footprint. We evaluated the model on two benchmark datasets for video prediction and one for video generation on which we achieved competitive results. On Kinetics-600 we achieved state-of-the-art for video prediction.
Semantic Room Wireframe Detection from a Single View
Jun 01, 2022
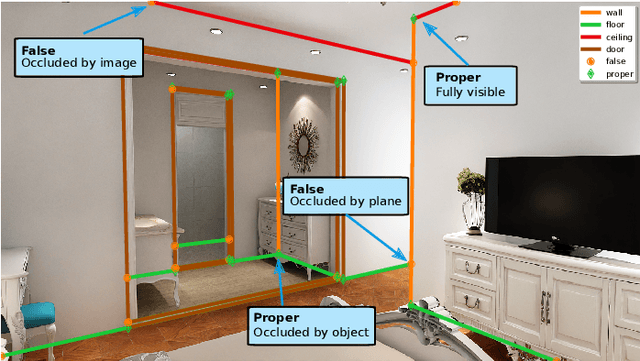
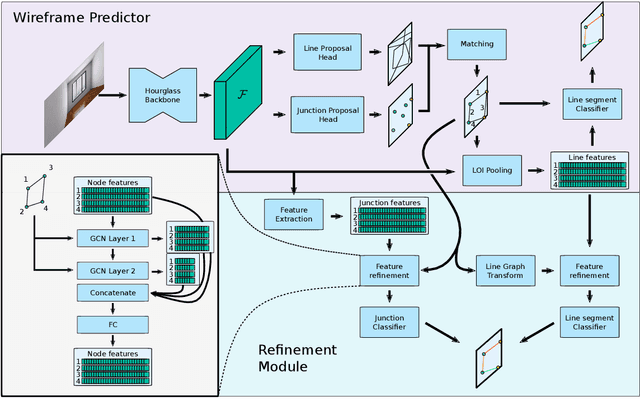
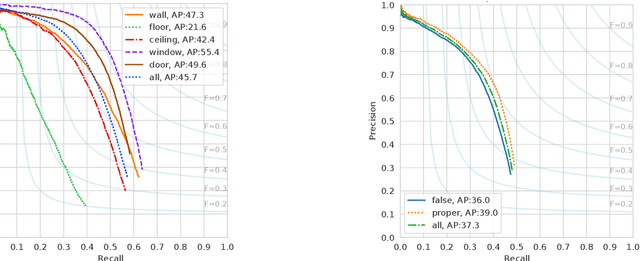
Reconstruction of indoor surfaces with limited texture information or with repeated textures, a situation common in walls and ceilings, may be difficult with a monocular Structure from Motion system. We propose a Semantic Room Wireframe Detection task to predict a Semantic Wireframe from a single perspective image. Such predictions may be used with shape priors to estimate the Room Layout and aid reconstruction. To train and test the proposed algorithm we create a new set of annotations from the simulated Structured3D dataset. We show qualitatively that the SRW-Net handles complex room geometries better than previous Room Layout Estimation algorithms while quantitatively out-performing the baseline in non-semantic Wireframe Detection.
Learning to Look Inside: Augmenting Token-Based Encoders with Character-Level Information
Aug 01, 2021
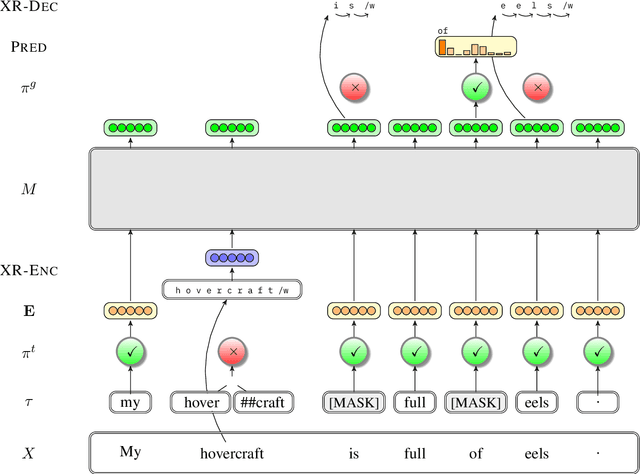

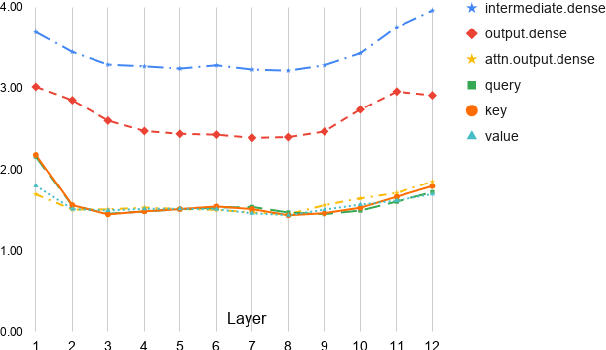
Commonly-used transformer language models depend on a tokenization schema which sets an unchangeable subword vocabulary prior to pre-training, destined to be applied to all downstream tasks regardless of domain shift, novel word formations, or other sources of vocabulary mismatch. Recent work has shown that "token-free" models can be trained directly on characters or bytes, but training these models from scratch requires substantial computational resources, and this implies discarding the many domain-specific models that were trained on tokens. In this paper, we present XRayEmb, a method for retrofitting existing token-based models with character-level information. XRayEmb is composed of a character-level "encoder" that computes vector representations of character sequences, and a generative component that decodes from the internal representation to a character sequence. We show that incorporating XRayEmb's learned vectors into sequences of pre-trained token embeddings helps performance on both autoregressive and masked pre-trained transformer architectures and on both sequence-level and sequence tagging tasks, particularly on non-standard English text.
Semantic Segmentation for Thermal Images: A Comparative Survey
May 26, 2022
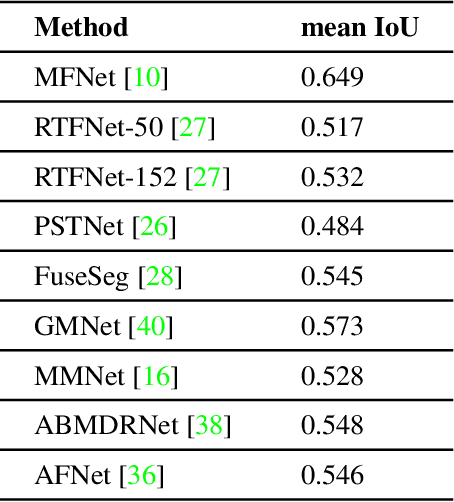


Semantic segmentation is a challenging task since it requires excessively more low-level spatial information of the image compared to other computer vision problems. The accuracy of pixel-level classification can be affected by many factors, such as imaging limitations and the ambiguity of object boundaries in an image. Conventional methods exploit three-channel RGB images captured in the visible spectrum with deep neural networks (DNN). Thermal images can significantly contribute during the segmentation since thermal imaging cameras are capable of capturing details despite the weather and illumination conditions. Using infrared spectrum in semantic segmentation has many real-world use cases, such as autonomous driving, medical imaging, agriculture, defense industry, etc. Due to this wide range of use cases, designing accurate semantic segmentation algorithms with the help of infrared spectrum is an important challenge. One approach is to use both visible and infrared spectrum images as inputs. These methods can accomplish higher accuracy due to enriched input information, with the cost of extra effort for the alignment and processing of multiple inputs. Another approach is to use only thermal images, enabling less hardware cost for smaller use cases. Even though there are multiple surveys on semantic segmentation methods, the literature lacks a comprehensive survey centered explicitly around semantic segmentation using infrared spectrum. This work aims to fill this gap by presenting algorithms in the literature and categorizing them by their input images.
AMR Alignment: Paying Attention to Cross-Attention
Jun 15, 2022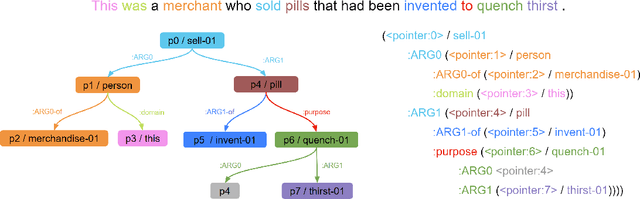
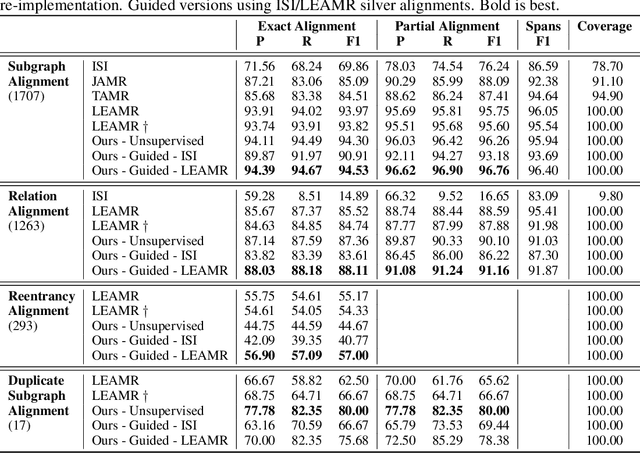

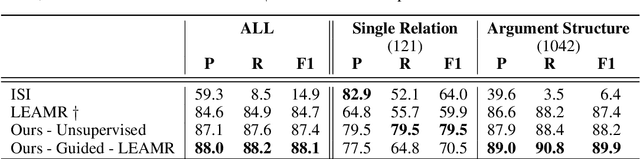
With the surge of Transformer models, many have investigated how attention acts on the learned representations. However, attention is still overlooked for specific tasks, such as Semantic Parsing. A popular approach to the formal representation of a sentence's meaning is Abstract Meaning Representation (AMR). Until now, the alignment between a sentence and its AMR representation has been explored in different ways, such as through rules or via the Expectation Maximization (EM) algorithm. In this paper, we investigate the ability of Transformer-based parsing models to yield effective alignments without ad-hoc strategies. We present the first in-depth exploration of cross-attention for AMR by proxy of alignment between the sentence spans and the semantic units in the graph. We show how current Transformer-based parsers implicitly encode the alignment information in the cross-attention weights and how to leverage it to extract such alignment. Furthermore, we supervise and guide cross-attention using alignment, dropping the need for English- and AMR-specific rules.
Pay Attention to Hidden States for Video Deblurring: Ping-Pong Recurrent Neural Networks and Selective Non-Local Attention
Apr 07, 2022
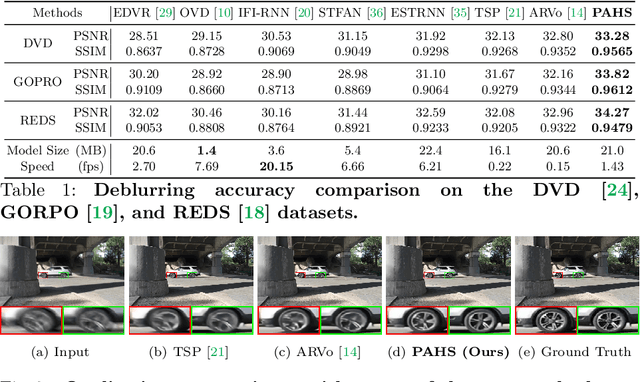
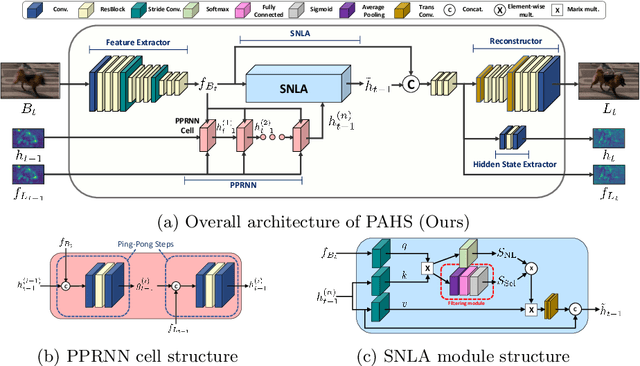

Video deblurring models exploit information in the neighboring frames to remove blur caused by the motion of the camera and the objects. Recurrent Neural Networks~(RNNs) are often adopted to model the temporal dependency between frames via hidden states. When motion blur is strong, however, hidden states are hard to deliver proper information due to the displacement between different frames. While there have been attempts to update the hidden states, it is difficult to handle misaligned features beyond the receptive field of simple modules. Thus, we propose 2 modules to supplement the RNN architecture for video deblurring. First, we design Ping-Pong RNN~(PPRNN) that acts on updating the hidden states by referring to the features from the current and the previous time steps alternately. PPRNN gathers relevant information from the both features in an iterative and balanced manner by utilizing its recurrent architecture. Second, we use a Selective Non-Local Attention~(SNLA) module to additionally refine the hidden state by aligning it with the positional information from the input frame feature. The attention score is scaled by the relevance to the input feature to focus on the necessary information. By paying attention to hidden states with both modules, which have strong synergy, our PAHS framework improves the representation powers of RNN structures and achieves state-of-the-art deblurring performance on standard benchmarks and real-world videos.
Sequential- and Parallel- Constrained Max-value Entropy Search via Information Lower Bound
Feb 19, 2021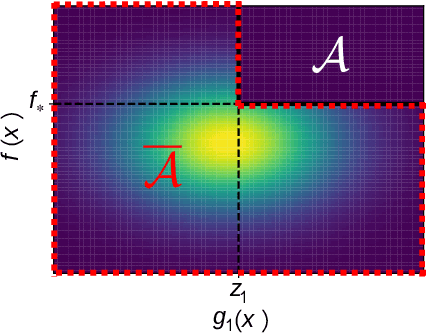
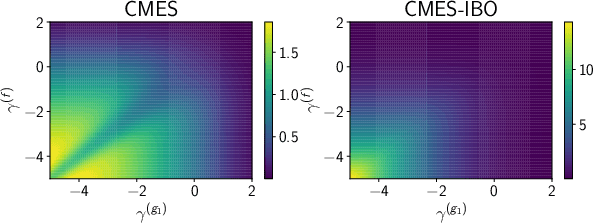
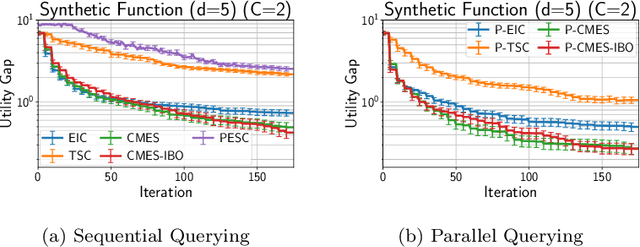
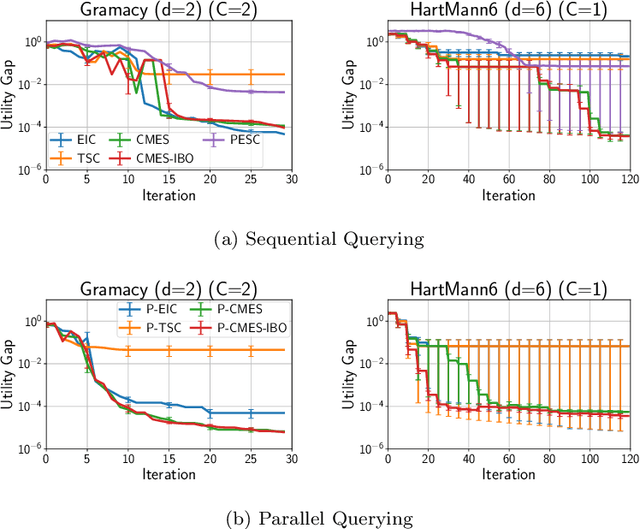
Recently, several Bayesian optimization (BO) methods have been extended to the expensive black-box optimization problem with unknown constraints, which is an important problem that appears frequently in practice. We focus on an information-theoretic approach called Max-value Entropy Search (MES) whose superior performance has been repeatedly shown in BO literature. Since existing MES-based constrained BO is restricted to only one constraint, we first extend it to multiple constraints, but we found that this approach can cause negative approximate values for the mutual information, which can result in unreasonable decisions. In this paper, we employ a different approximation strategy that is based on a lower bound of the mutual information, and propose a novel constrained BO method called Constrained Max-value Entropy Search via Information lower BOund (CMES-IBO). Our approximate mutual information derived from the lower bound has a simple closed-form that is guaranteed to be nonnegative, and we show that irrational behavior caused by the negative value can be avoided. Furthermore, by using conditional mutual information, we extend our methods to the parallel setting in which multiple queries can be issued simultaneously. Finally, we demonstrate the effectiveness of our proposed methods by benchmark functions and real-world applications to materials science.
Resonant Tunnelling Diode Nano-Optoelectronic Spiking Nodes For Neuromorphic Information Processing
Jul 14, 2021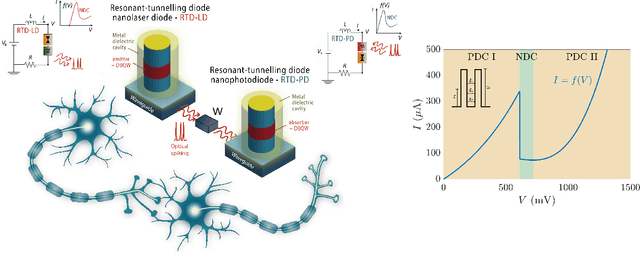
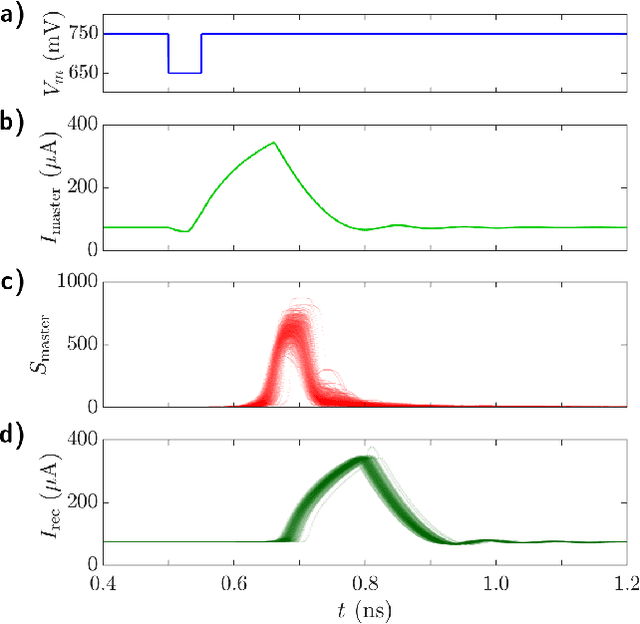
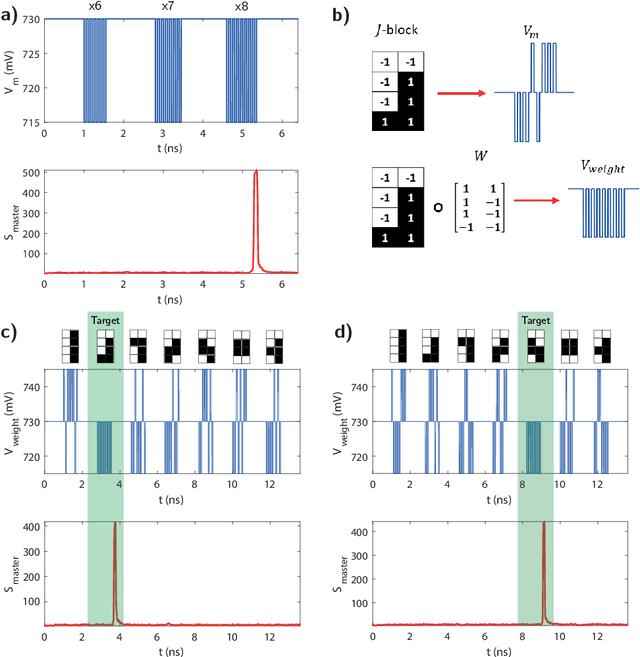
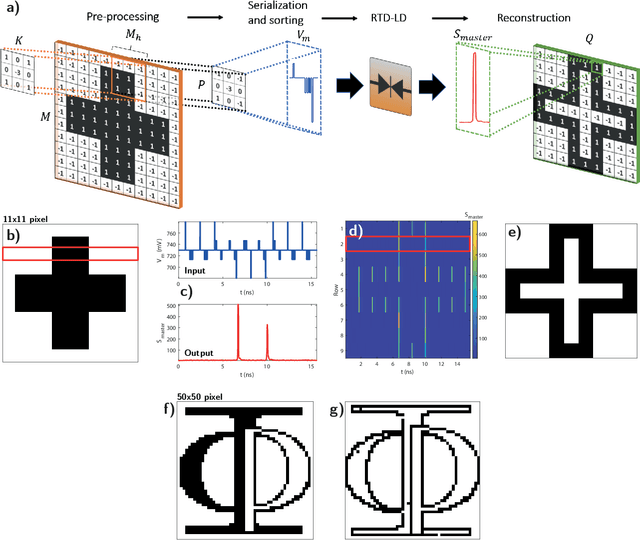
In this work, we introduce an optoelectronic spiking artificial neuron capable of operating at ultrafast rates ($\approx$ 100 ps/optical spike) and with low energy consumption ($<$ pJ/spike). The proposed system combines an excitable resonant tunnelling diode (RTD) element exhibiting negative differential conductance, coupled to a nanoscale light source (forming a master node) or a photodetector (forming a receiver node). We study numerically the spiking dynamical responses and information propagation functionality of an interconnected master-receiver RTD node system. Using the key functionality of pulse thresholding and integration, we utilize a single node to classify sequential pulse patterns and perform convolutional functionality for image feature (edge) recognition. We also demonstrate an optically-interconnected spiking neural network model for processing of spatiotemporal data at over 10 Gbps with high inference accuracy. Finally, we demonstrate an off-chip supervised learning approach utilizing spike-timing dependent plasticity for the RTD-enabled photonic spiking neural network. These results demonstrate the potential and viability of RTD spiking nodes for low footprint, low energy, high-speed optoelectronic realization of neuromorphic hardware.
On the complexity of finding set repairs for data-graphs
Jun 15, 2022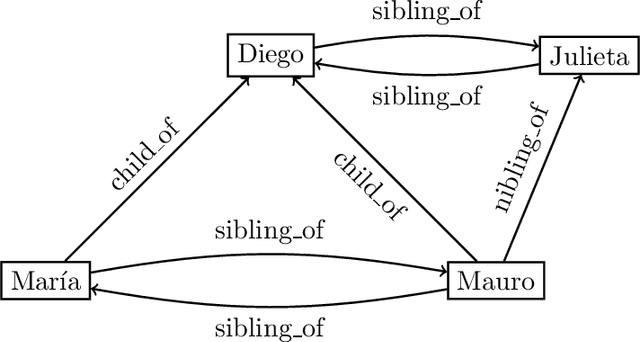
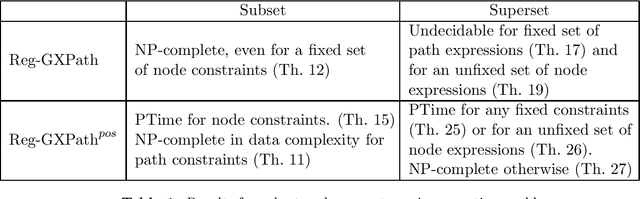
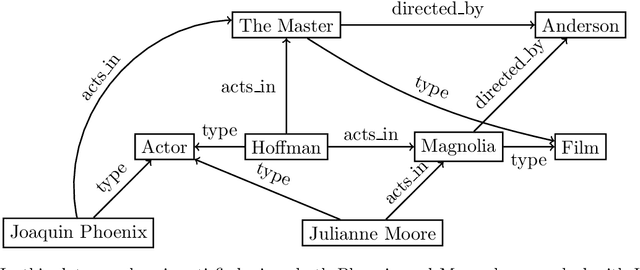
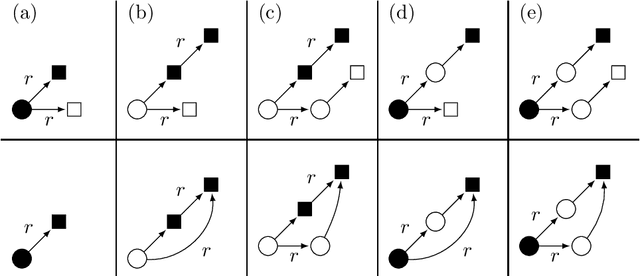
In the deeply interconnected world we live in, pieces of information link domains all around us. As graph databases embrace effectively relationships among data and allow processing and querying these connections efficiently, they are rapidly becoming a popular platform for storage that supports a wide range of domains and applications. As in the relational case, it is expected that data preserves a set of integrity constraints that define the semantic structure of the world it represents. When a database does not satisfy its integrity constraints, a possible approach is to search for a 'similar' database that does satisfy the constraints, also known as a repair. In this work, we study the problem of computing subset and superset repairs for graph databases with data values using a notion of consistency based on a set of Reg-GXPath expressions as integrity constraints. We show that for positive fragments of Reg-GXPath these problems admit a polynomial-time algorithm, while the full expressive power of the language renders them intractable.