 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SSD-Faster Net: A Hybrid Network for Industrial Defect Inspection
Jul 03, 2022

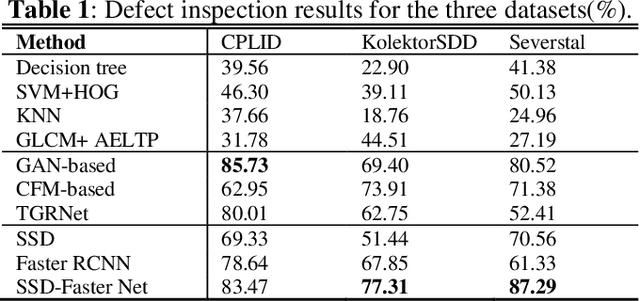
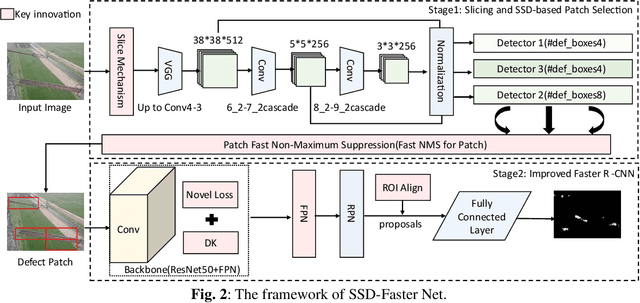
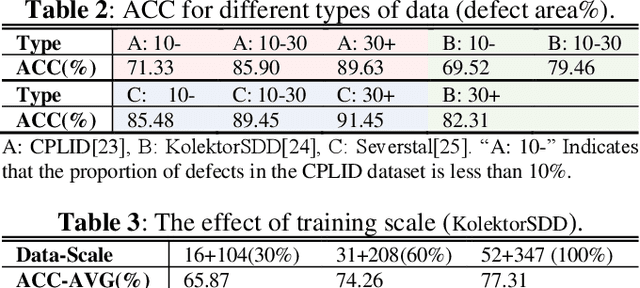
The quality of industrial components is critical to the production of special equipment such as robots. Defect inspection of these components is an efficient way to ensure quality. In this paper, we propose a hybrid network, SSD-Faster Net, for industrial defect inspection of rails, insulators, commutators etc. SSD-Faster Net is a two-stage network, including SSD for quickly locating defective blocks, and an improved Faster R-CNN for defect segmentation. For the former, we propose a novel slice localization mechanism to help SSD scan quickly. The second stage is based on improved Faster R-CNN, using FPN, deformable kernel(DK) to enhance representation ability. It fuses multi-scale information, and self-adapts the receptive field. We also propose a novel loss function and use ROI Align to improve accuracy. Experiments show that our SSD-Faster Net achieves an average accuracy of 84.03%, which is 13.42% higher than the nearest competitor based on Faster R-CNN, 4.14% better than GAN-based methods, more than 10% higher than that of DNN-based detectors. And the computing speed is improved by nearly 7%, which proves its robustness and superior performance.
Meta-Learning over Time for Destination Prediction Tasks
Jun 29, 2022
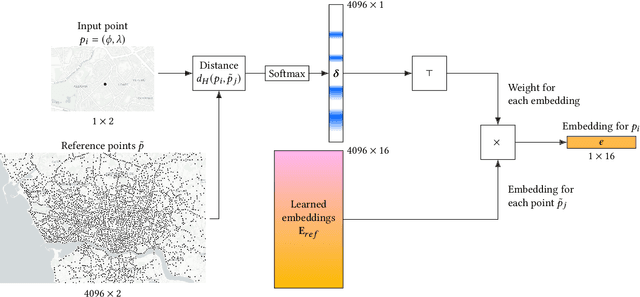

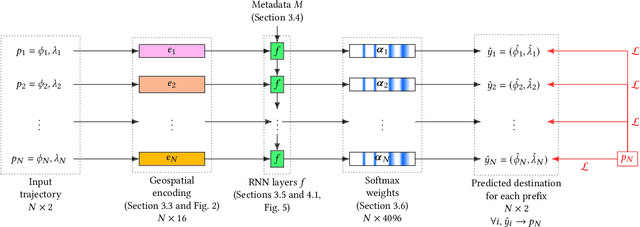
A need to understand and predict vehicles' behavior underlies both public and private goals in the transportation domain, including urban planning and management, ride-sharing services, and intelligent transportation systems. Individuals' preferences and intended destinations vary throughout the day, week, and year: for example, bars are most popular in the evenings, and beaches are most popular in the summer. Despite this principle, we note that recent studies on a popular benchmark dataset from Porto, Portugal have found, at best, only marginal improvements in predictive performance from incorporating temporal information. We propose an approach based on hypernetworks, a variant of meta-learning ("learning to learn") in which a neural network learns to change its own weights in response to an input. In our case, the weights responsible for destination prediction vary with the metadata, in particular the time, of the input trajectory. The time-conditioned weights notably improve the model's error relative to ablation studies and comparable prior work, and we confirm our hypothesis that knowledge of time should improve prediction of a vehicle's intended destination.
Two-terminal source coding with common sum reconstruction
Jun 14, 2022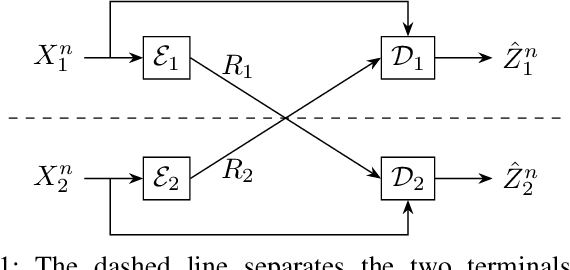
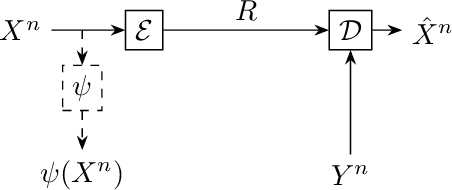
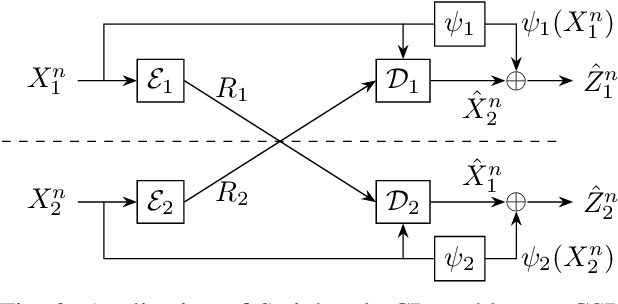
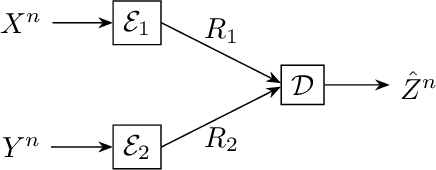
We present the problem of two-terminal source coding with Common Sum Reconstruction (CSR). Consider two terminals, each with access to one of two correlated sources. Both terminals want to reconstruct the sum of the two sources under some average distortion constraint, and the reconstructions at two terminals must be identical with high probability. In this paper, we develop inner and outer bounds to the achievable rate distortion region of the CSR problem for a doubly symmetric binary source. We employ existing achievability results for Steinberg's common reconstruction and Wyner-Ziv's source coding with side information problems, and an achievability result for the lossy version of Korner-Marton's modulo-two sum computation problem.
GO-Surf: Neural Feature Grid Optimization for Fast, High-Fidelity RGB-D Surface Reconstruction
Jun 29, 2022
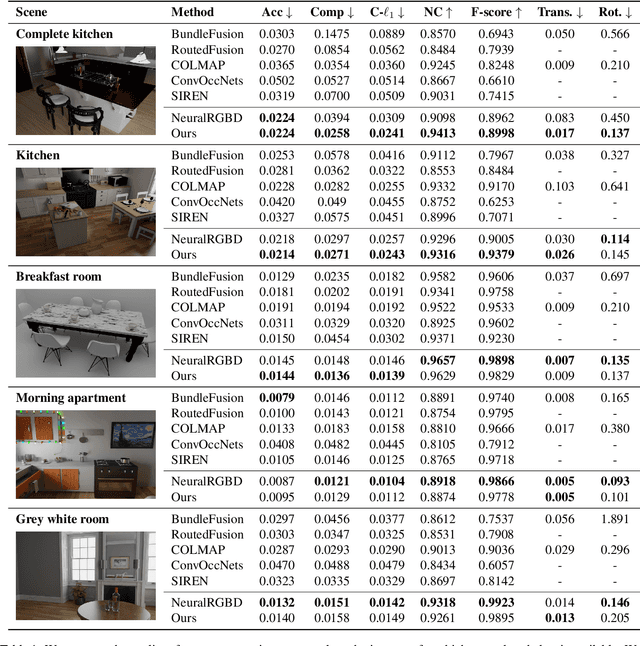
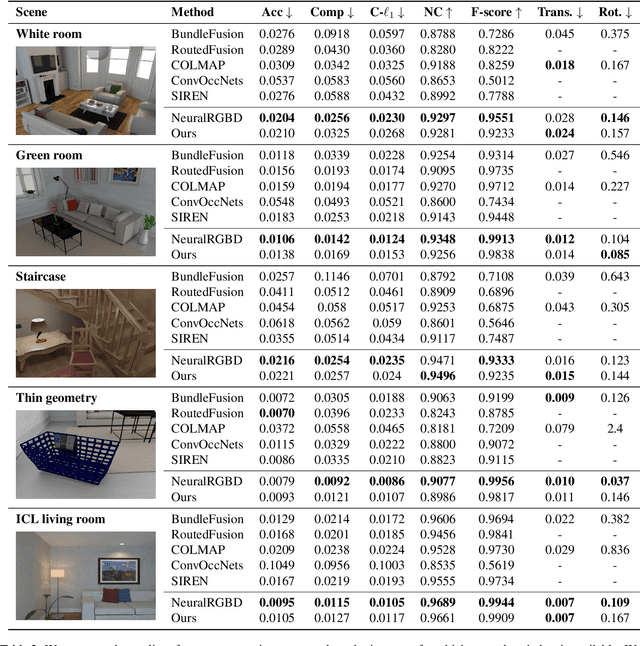
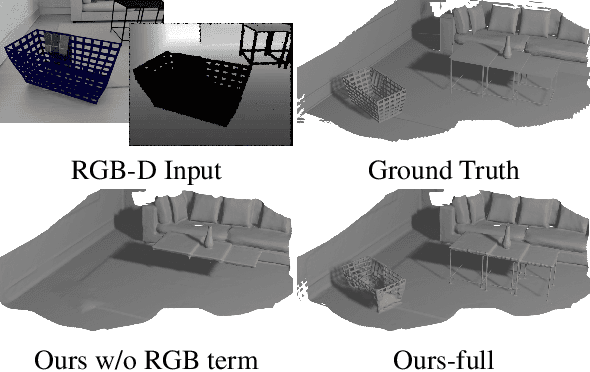
We present GO-Surf, a direct feature grid optimization method for accurate and fast surface reconstruction from RGB-D sequences. We model the underlying scene with a learned hierarchical feature voxel grid that encapsulates multi-level geometric and appearance local information. Feature vectors are directly optimized such that after being tri-linearly interpolated, decoded by two shallow MLPs into signed distance and radiance values, and rendered via surface volume rendering, the discrepancy between synthesized and observed RGB/depth values is minimized. Our supervision signals -- RGB, depth and approximate SDF -- can be obtained directly from input images without any need for fusion or post-processing. We formulate a novel SDF gradient regularization term that encourages surface smoothness and hole filling while maintaining high frequency details. GO-Surf can optimize sequences of $1$-$2$K frames in $15$-$45$ minutes, a speedup of $\times60$ over NeuralRGB-D, the most related approach based on an MLP representation, while maintaining on par performance on standard benchmarks. Project page: https://jingwenwang95.github.io/go_surf/
Trial2Vec: Zero-Shot Clinical Trial Document Similarity Search using Self-Supervision
Jun 29, 2022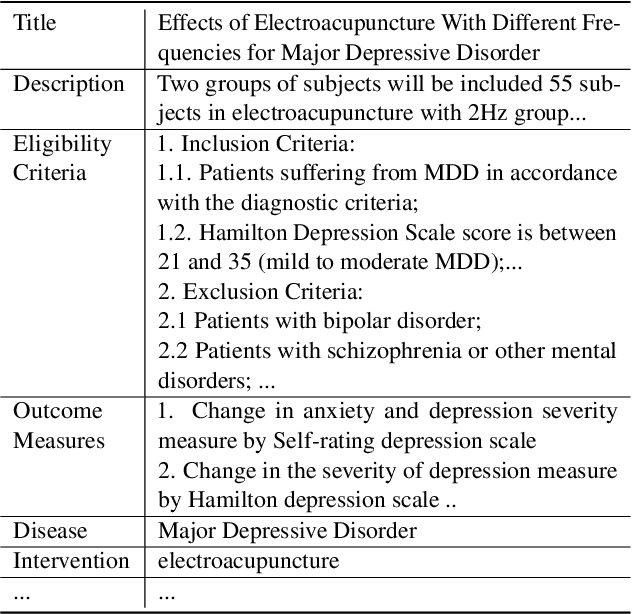
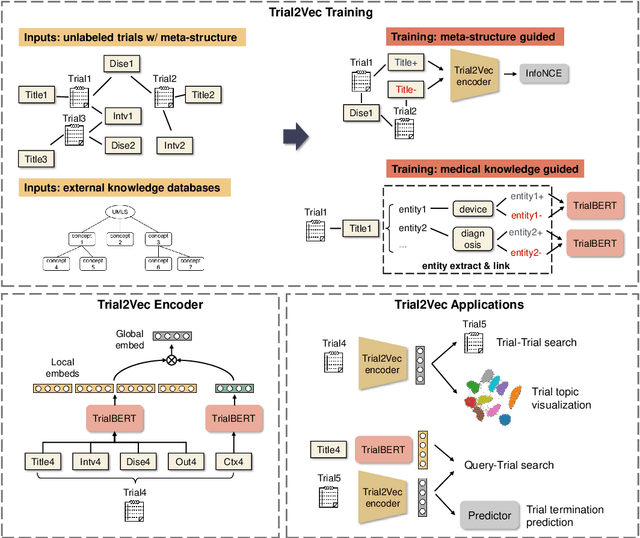
Clinical trials are essential for drug development but are extremely expensive and time-consuming to conduct. It is beneficial to study similar historical trials when designing a clinical trial. However, lengthy trial documents and lack of labeled data make trial similarity search difficult. We propose a zero-shot clinical trial retrieval method, Trial2Vec, which learns through self-supervision without annotating similar clinical trials. Specifically, the meta-structure of trial documents (e.g., title, eligibility criteria, target disease) along with clinical knowledge (e.g., UMLS knowledge base https://www.nlm.nih.gov/research/umls/index.html) are leveraged to automatically generate contrastive samples. Besides, Trial2Vec encodes trial documents considering meta-structure thus producing compact embeddings aggregating multi-aspect information from the whole document. We show that our method yields medically interpretable embeddings by visualization and it gets a 15% average improvement over the best baselines on precision/recall for trial retrieval, which is evaluated on our labeled 1600 trial pairs. In addition, we prove the pre-trained embeddings benefit the downstream trial outcome prediction task over 240k trials.
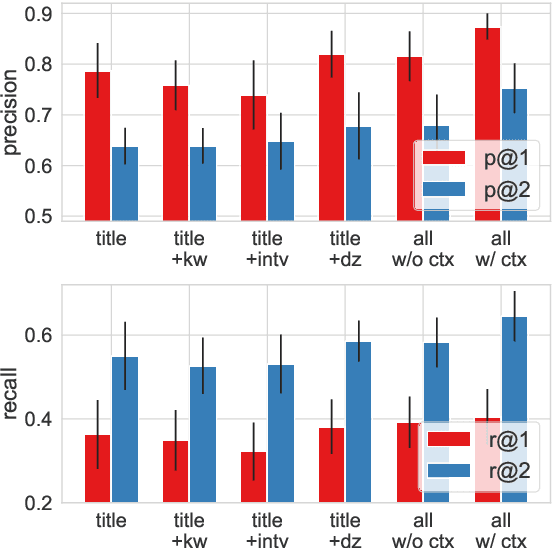
Multi-Perspective Semantic Information Retrieval
Sep 03, 2020

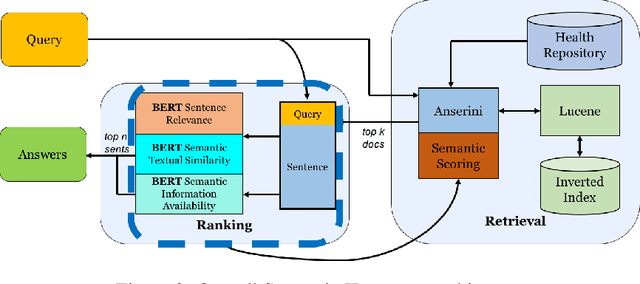

Information Retrieval (IR) is the task of obtaining pieces of data (such as documents or snippets of text) that are relevant to a particular query or need from a large repository of information. While a combination of traditional keyword- and modern BERT-based approaches have been shown to be effective in recent work, there are often nuances in identifying what information is "relevant" to a particular query, which can be difficult to properly capture using these systems. This work introduces the concept of a Multi-Perspective IR system, a novel methodology that combines multiple deep learning and traditional IR models to better predict the relevance of a query-sentence pair, along with a standardized framework for tuning this system. This work is evaluated on the BioASQ Biomedical IR + QA challenges.
Temporal Multimodal Multivariate Learning
Jun 14, 2022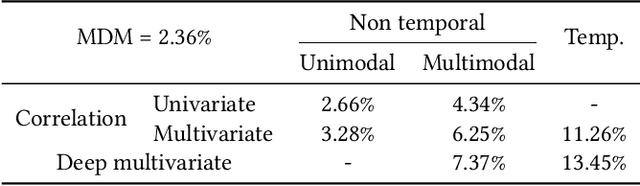
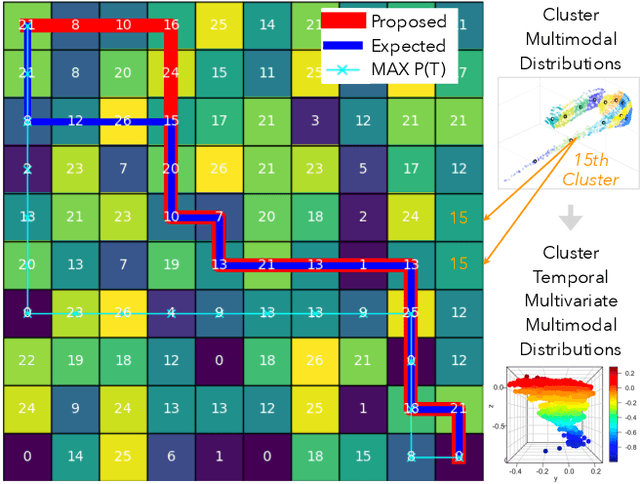

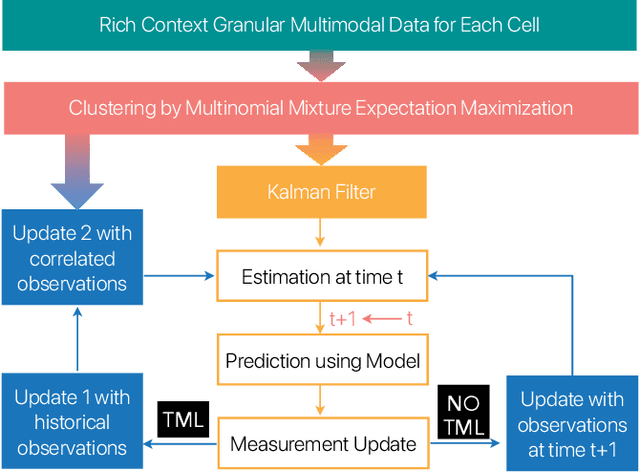
We introduce temporal multimodal multivariate learning, a new family of decision making models that can indirectly learn and transfer online information from simultaneous observations of a probability distribution with more than one peak or more than one outcome variable from one time stage to another. We approximate the posterior by sequentially removing additional uncertainties across different variables and time, based on data-physics driven correlation, to address a broader class of challenging time-dependent decision-making problems under uncertainty. Extensive experiments on real-world datasets ( i.e., urban traffic data and hurricane ensemble forecasting data) demonstrate the superior performance of the proposed targeted decision-making over the state-of-the-art baseline prediction methods across various settings.
Nonstationary Bandit Learning via Predictive Sampling
May 04, 2022
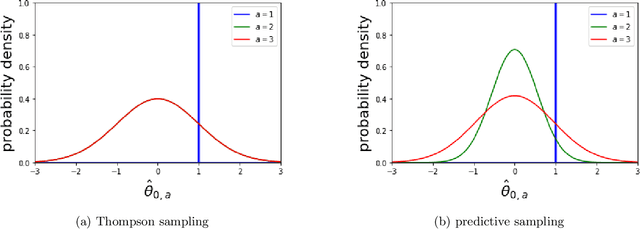
We propose predictive sampling as an approach to selecting actions that balance between exploration and exploitation in nonstationary bandit environments. When specialized to stationary environments, predictive sampling is equivalent to Thompson sampling. However, predictive sampling is effective across a range of nonstationary environments in which Thompson sampling suffers. We establish a general information-theoretic bound on the Bayesian regret of predictive sampling. We then specialize this bound to study a modulated Bernoulli bandit environment. Our analysis highlights a key advantage of predictive sampling over Thompson sampling: predictive sampling deprioritizes investments in exploration where acquired information will quickly become less relevant.
IDPS Signature Classification with a Reject Option and the Incorporation of Expert Knowledge
Jul 19, 2022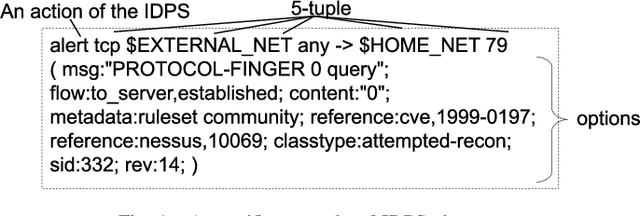
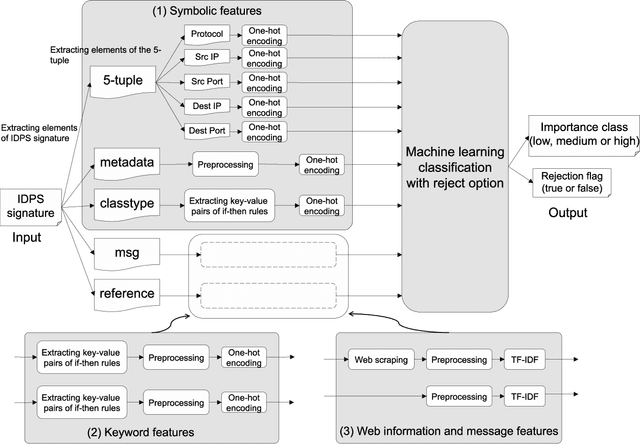
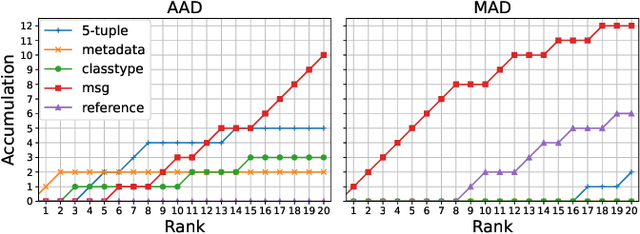
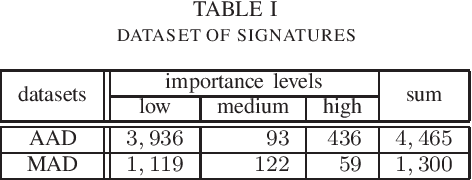
As the importance of intrusion detection and prevention systems (IDPSs) increases, great costs are incurred to manage the signatures that are generated by malicious communication pattern files. Experts in network security need to classify signatures by importance for an IDPS to work. We propose and evaluate a machine learning signature classification model with a reject option (RO) to reduce the cost of setting up an IDPS. To train the proposed model, it is essential to design features that are effective for signature classification. Experts classify signatures with predefined if-then rules. An if-then rule returns a label of low, medium, high, or unknown importance based on keyword matching of the elements in the signature. Therefore, we first design two types of features, symbolic features (SFs) and keyword features (KFs), which are used in keyword matching for the if-then rules. Next, we design web information and message features (WMFs) to capture the properties of signatures that do not match the if-then rules. The WMFs are extracted as term frequency-inverse document frequency (TF-IDF) features of the message text in the signatures. The features are obtained by web scraping from the referenced external attack identification systems described in the signature. Because failure needs to be minimized in the classification of IDPS signatures, as in the medical field, we consider introducing a RO in our proposed model. The effectiveness of the proposed classification model is evaluated in experiments with two real datasets composed of signatures labeled by experts: a dataset that can be classified with if-then rules and a dataset with elements that do not match an if-then rule. In the experiment, the proposed model is evaluated. In both cases, the combined SFs and WMFs performed better than the combined SFs and KFs. In addition, we also performed feature analysis.
Multi-Frequency Joint Community Detection and Phase Synchronization
Jun 16, 2022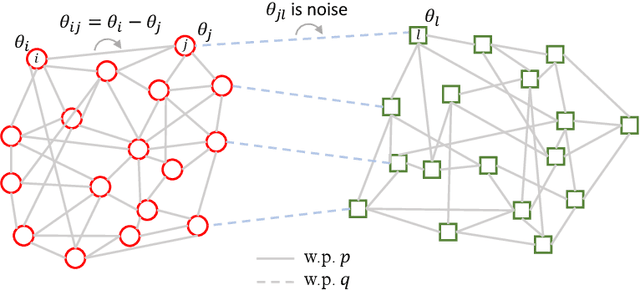


This paper studies the joint community detection and phase synchronization problem on the \textit{stochastic block model with relative phase}, where each node is associated with a phase. This problem, with a variety of real-world applications, aims to recover community memberships and associated phases simultaneously. By studying the maximum likelihood estimation formulation, we show that this problem exhibits a \textit{``multi-frequency''} structure. To this end, two simple yet efficient algorithms that leverage information across multiple frequencies are proposed. The former is a spectral method based on the novel multi-frequency column-pivoted QR factorization, and the latter is an iterative multi-frequency generalized power method. Numerical experiments indicate our proposed algorithms outperform state-of-the-art algorithms, in recovering community memberships and associated phases.