 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Selectively increasing the diversity of GAN-generated samples
Jul 07, 2022
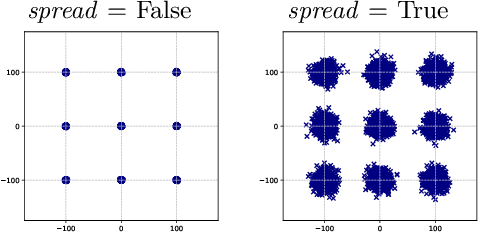
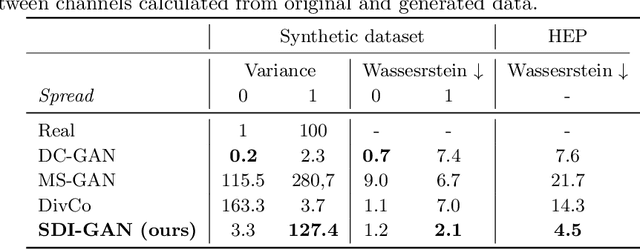
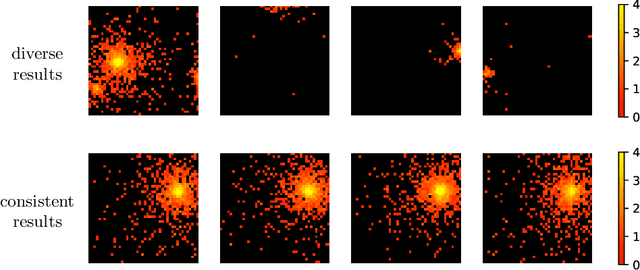
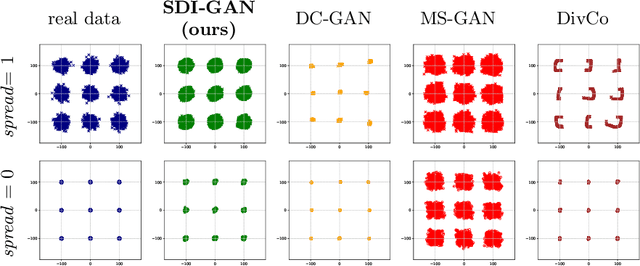
Generative Adversarial Networks (GANs) are powerful models able to synthesize data samples closely resembling the distribution of real data, yet the diversity of those generated samples is limited due to the so-called mode collapse phenomenon observed in GANs. Especially prone to mode collapse are conditional GANs, which tend to ignore the input noise vector and focus on the conditional information. Recent methods proposed to mitigate this limitation increase the diversity of generated samples, yet they reduce the performance of the models when similarity of samples is required. To address this shortcoming, we propose a novel method to selectively increase the diversity of GAN-generated samples. By adding a simple, yet effective regularization to the training loss function we encourage the generator to discover new data modes for inputs related to diverse outputs while generating consistent samples for the remaining ones. More precisely, we maximise the ratio of distances between generated images and input latent vectors scaling the effect according to the diversity of samples for a given conditional input. We show the superiority of our method in a synthetic benchmark as well as a real-life scenario of simulating data from the Zero Degree Calorimeter of ALICE experiment in LHC, CERN.
The least-control principle for learning at equilibrium
Jul 04, 2022



Equilibrium systems are a powerful way to express neural computations. As special cases, they include models of great current interest in both neuroscience and machine learning, such as equilibrium recurrent neural networks, deep equilibrium models, or meta-learning. Here, we present a new principle for learning such systems with a temporally- and spatially-local rule. Our principle casts learning as a least-control problem, where we first introduce an optimal controller to lead the system towards a solution state, and then define learning as reducing the amount of control needed to reach such a state. We show that incorporating learning signals within a dynamics as an optimal control enables transmitting credit assignment information in previously unknown ways, avoids storing intermediate states in memory, and does not rely on infinitesimal learning signals. In practice, our principle leads to strong performance matching that of leading gradient-based learning methods when applied to an array of problems involving recurrent neural networks and meta-learning. Our results shed light on how the brain might learn and offer new ways of approaching a broad class of machine learning problems.
Class Prior Estimation under Covariate Shift -- no Problem?
Jun 06, 2022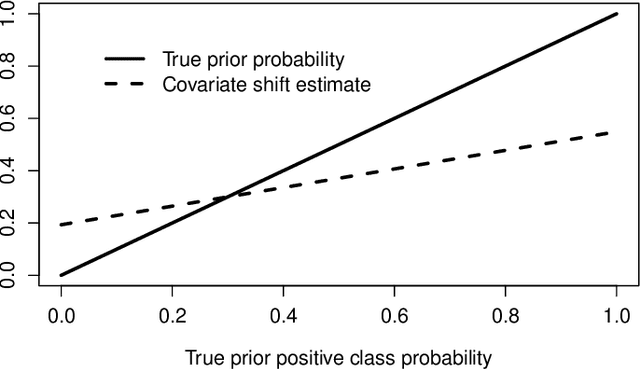
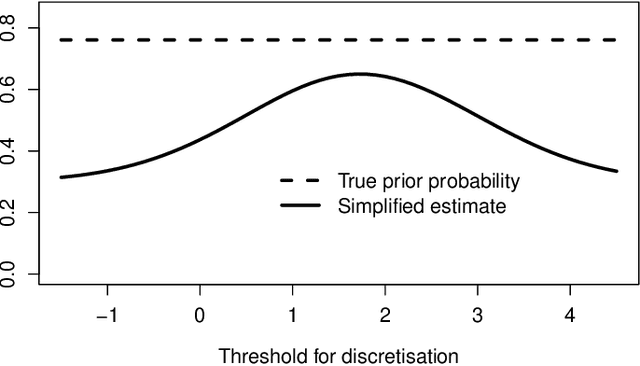
We show that in the context of classification the property of source and target distributions to be related by covariate shift may break down when the information content captured in the covariates is reduced, for instance by discretization of the covariates, dropping some of them, or by any transformation of the covariates even if it is domain-invariant. The consequences of this observation for class prior estimation under covariate shift are discussed. A probing algorithm as alternative approach to class prior estimation under covariate shift is proposed.
Unified Learning from Demonstrations, Corrections, and Preferences during Physical Human-Robot Interaction
Jul 07, 2022



Humans can leverage physical interaction to teach robot arms. This physical interaction takes multiple forms depending on the task, the user, and what the robot has learned so far. State-of-the-art approaches focus on learning from a single modality, or combine multiple interaction types by assuming that the robot has prior information about the human's intended task. By contrast, in this paper we introduce an algorithmic formalism that unites learning from demonstrations, corrections, and preferences. Our approach makes no assumptions about the tasks the human wants to teach the robot; instead, we learn a reward model from scratch by comparing the human's inputs to nearby alternatives. We first derive a loss function that trains an ensemble of reward models to match the human's demonstrations, corrections, and preferences. The type and order of feedback is up to the human teacher: we enable the robot to collect this feedback passively or actively. We then apply constrained optimization to convert our learned reward into a desired robot trajectory. Through simulations and a user study we demonstrate that our proposed approach more accurately learns manipulation tasks from physical human interaction than existing baselines, particularly when the robot is faced with new or unexpected objectives. Videos of our user study are available at: https://youtu.be/FSUJsTYvEKU
Deep Multi-view Semi-supervised Clustering with Sample Pairwise Constraints
Jun 10, 2022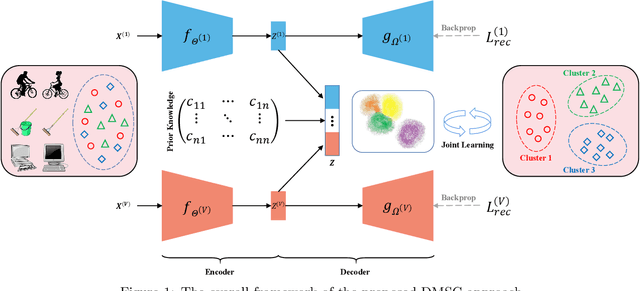


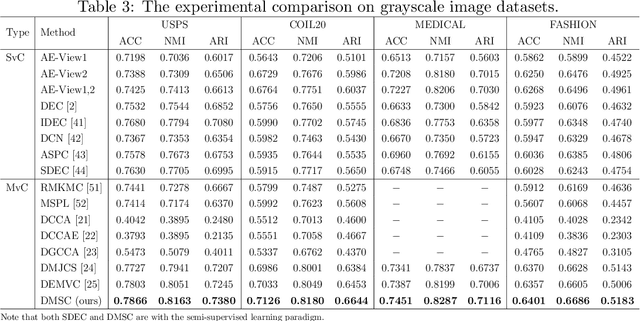
Multi-view clustering has attracted much attention thanks to the capacity of multi-source information integration. Although numerous advanced methods have been proposed in past decades, most of them generally overlook the significance of weakly-supervised information and fail to preserve the feature properties of multiple views, thus resulting in unsatisfactory clustering performance. To address these issues, in this paper, we propose a novel Deep Multi-view Semi-supervised Clustering (DMSC) method, which jointly optimizes three kinds of losses during networks finetuning, including multi-view clustering loss, semi-supervised pairwise constraint loss and multiple autoencoders reconstruction loss. Specifically, a KL divergence based multi-view clustering loss is imposed on the common representation of multi-view data to perform heterogeneous feature optimization, multi-view weighting and clustering prediction simultaneously. Then, we innovatively propose to integrate pairwise constraints into the process of multi-view clustering by enforcing the learned multi-view representation of must-link samples (cannot-link samples) to be similar (dissimilar), such that the formed clustering architecture can be more credible. Moreover, unlike existing rivals that only preserve the encoders for each heterogeneous branch during networks finetuning, we further propose to tune the intact autoencoders frame that contains both encoders and decoders. In this way, the issue of serious corruption of view-specific and view-shared feature space could be alleviated, making the whole training procedure more stable. Through comprehensive experiments on eight popular image datasets, we demonstrate that our proposed approach performs better than the state-of-the-art multi-view and single-view competitors.
Clustering of Time Series Data with Prior Geographical Information
Jul 03, 2021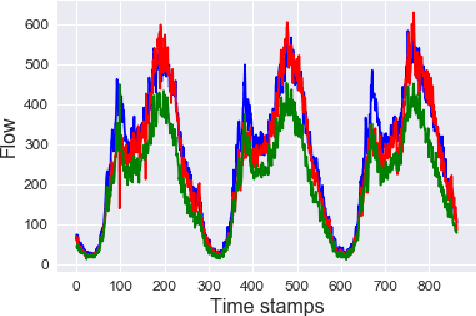
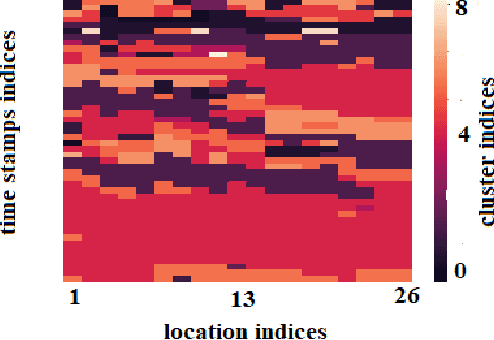
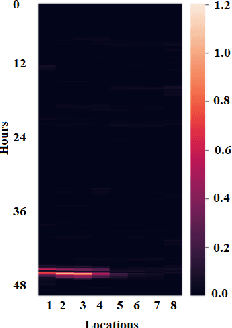
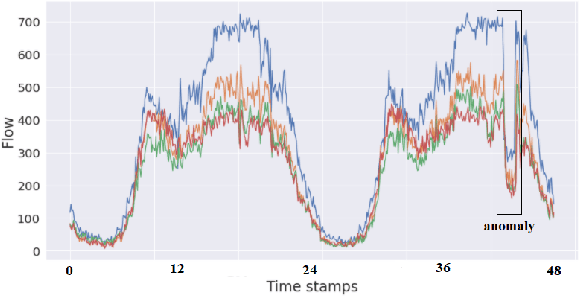
Time Series data are broadly studied in various domains of transportation systems. Traffic data area challenging example of spatio-temporal data, as it is multi-variate time series with high correlations in spatial and temporal neighborhoods. Spatio-temporal clustering of traffic flow data find similar patterns in both spatial and temporal domain, where it provides better capability for analyzing a transportation network, and improving related machine learning models, such as traffic flow prediction and anomaly detection. In this paper, we propose a spatio-temporal clustering model, where it clusters time series data based on spatial and temporal contexts. We propose a variation of a Deep Embedded Clustering(DEC) model for finding spatio-temporal clusters. The proposed model Spatial-DEC (S-DEC) use prior geographical information in building latent feature representations. We also define evaluation metrics for spatio-temporal clusters. Not only do the obtained clusters have better temporal similarity when evaluated using DTW distance, but also the clusters better represents spatial connectivity and dis-connectivity. We use traffic flow data obtained by PeMS in our analysis. The results show that the proposed Spatial-DEC can find more desired spatio-temporal clusters.
A Neural Network Based Method with Transfer Learning for Genetic Data Analysis
Jun 20, 2022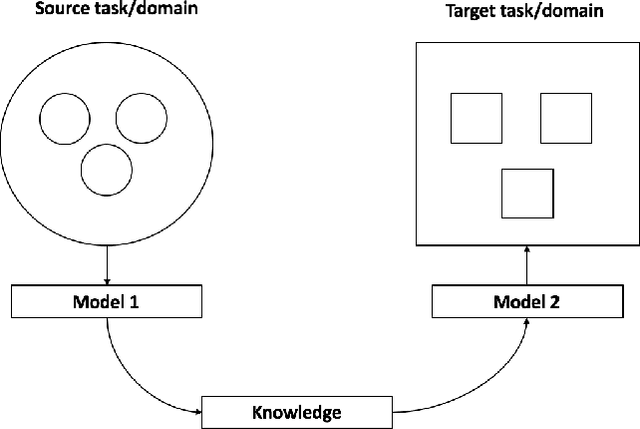
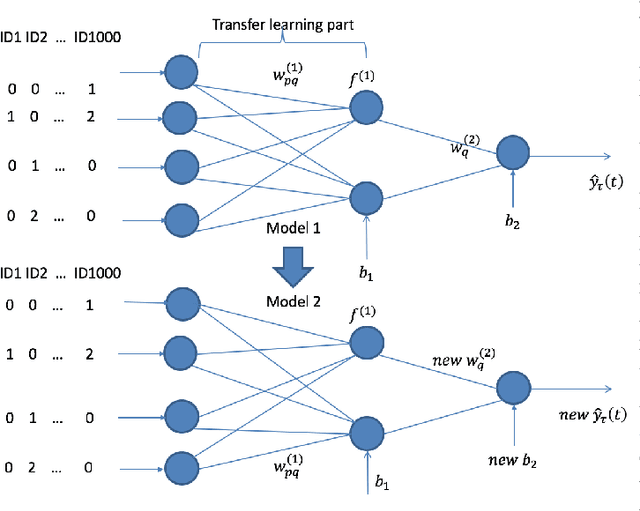
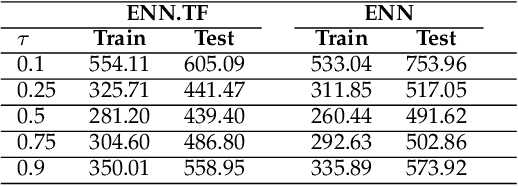
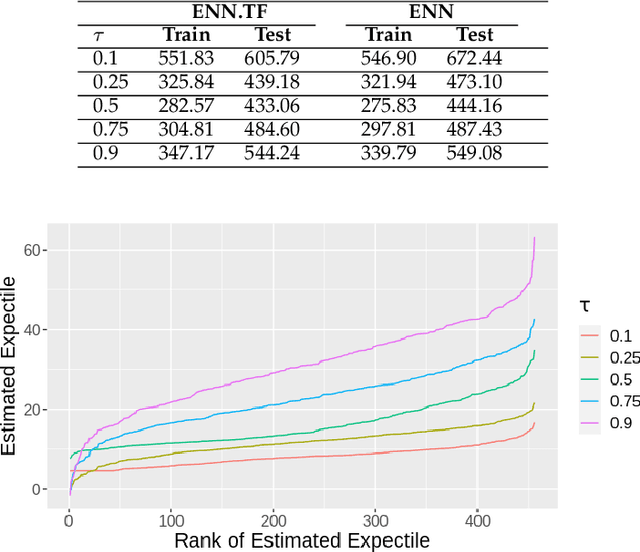
Transfer learning has emerged as a powerful technique in many application problems, such as computer vision and natural language processing. However, this technique is largely ignored in application to genetic data analysis. In this paper, we combine transfer learning technique with a neural network based method(expectile neural networks). With transfer learning, instead of starting the learning process from scratch, we start from one task that have been learned when solving a different task. We leverage previous learnings and avoid starting from scratch to improve the model performance by passing information gained in different but related task. To demonstrate the performance, we run two real data sets. By using transfer learning algorithm, the performance of expectile neural networks is improved compared to expectile neural network without using transfer learning technique.
DEMI: Discriminative Estimator of Mutual Information
Oct 05, 2020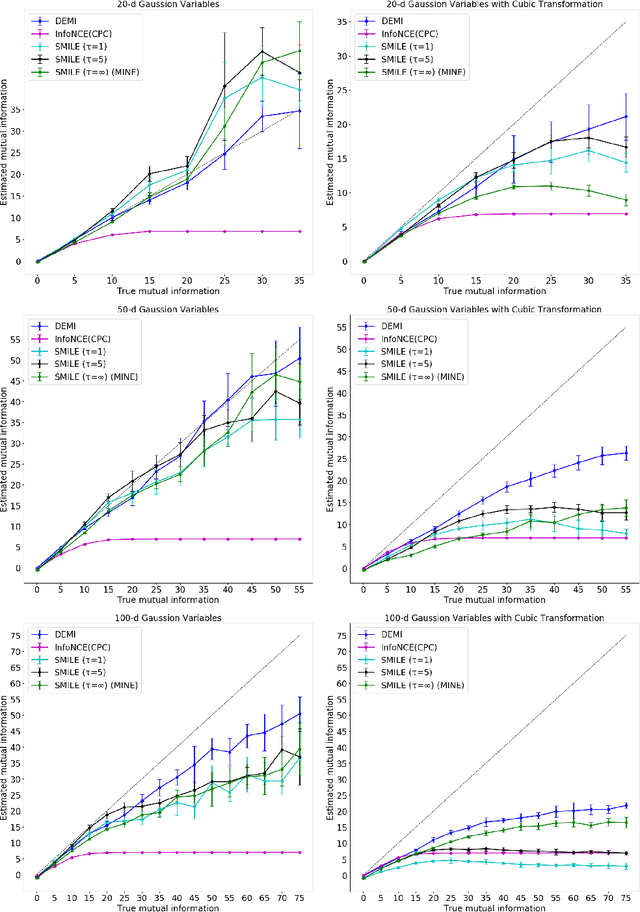
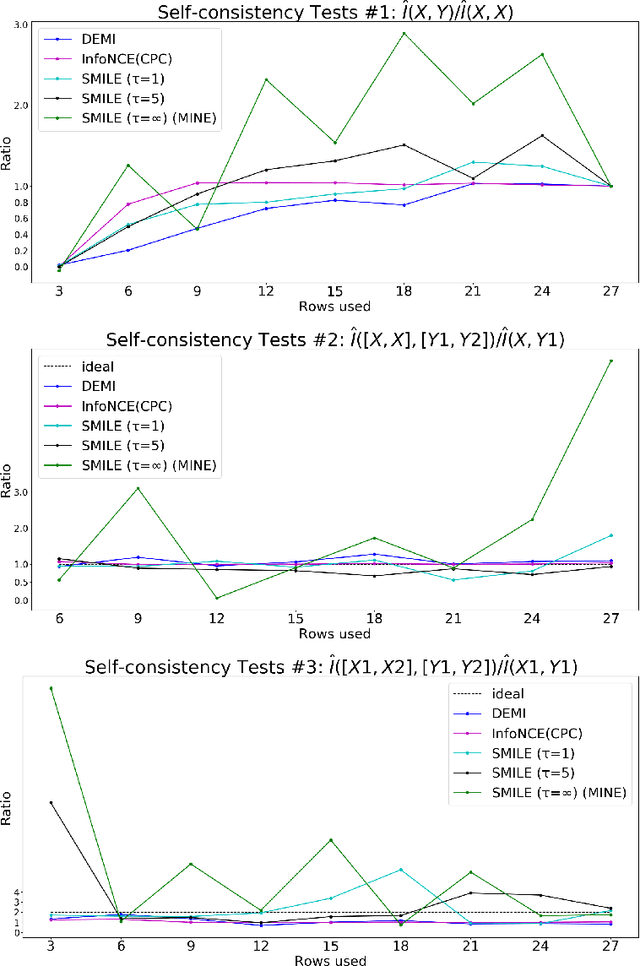
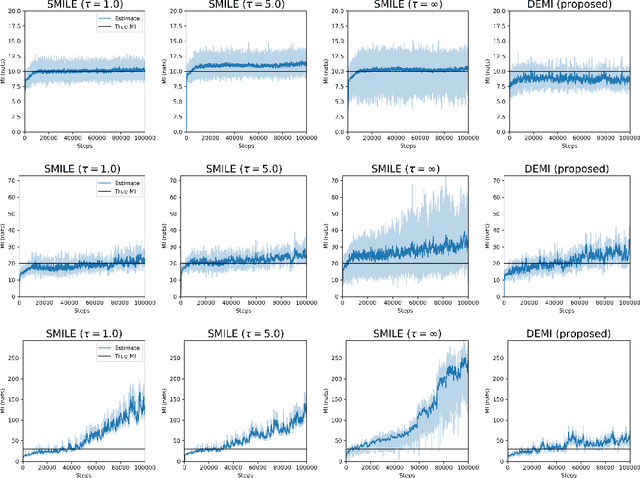
Estimating mutual information between continuous random variables is often intractable and extremely challenging for high-dimensional data. Recent progress has leveraged neural networks to optimize variational lower bounds on mutual information. Although showing promise for this difficult problem, the variational methods have been theoretically and empirically proven to have serious statistical limitations: 1) most of the approaches cannot make accurate estimates when the underlying mutual information is either low or high; 2) the resulting estimators may suffer from high variance. Our approach is based on training a classifier that provides the probability whether a data sample pair is drawn from the joint distribution or from the product of its marginal distributions. We use this probabilistic prediction to estimate mutual information. We show theoretically that our method and other variational approaches are equivalent when they achieve their optimum, while our approach does not optimize a variational bound. Empirical results demonstrate high accuracy and a good bias/variance tradeoff using our approach.
Waveform Design and Hybrid Duplex Exploiting Radar Features for Joint Communication and Sensing
Jul 07, 2022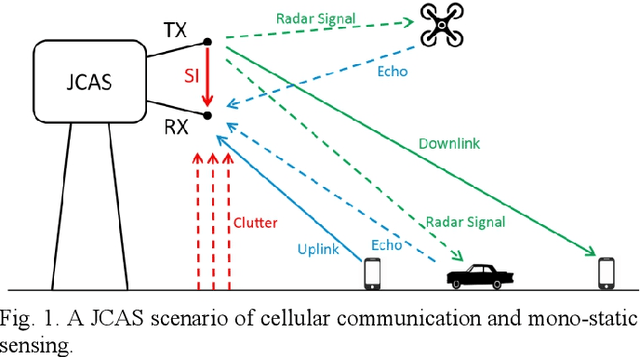
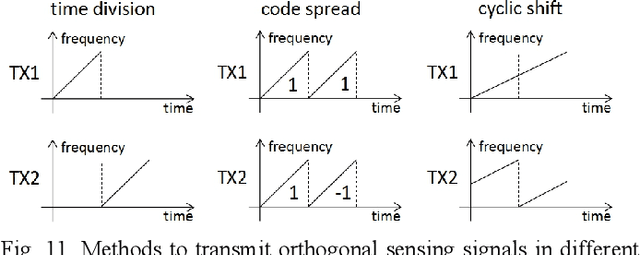
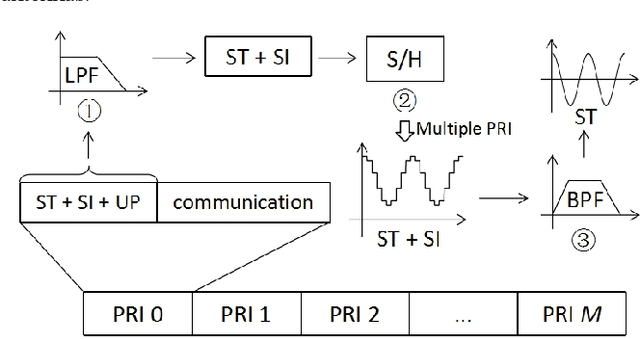
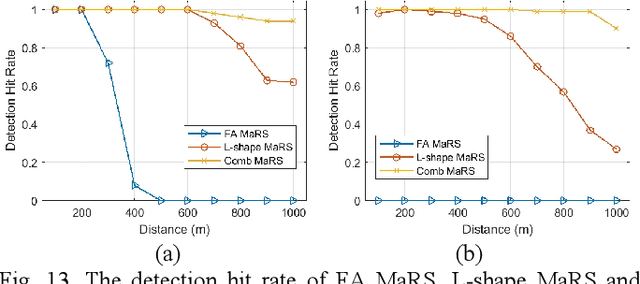
Joint communication and sensing (JCAS) is a very promising 6G technology, which attracts more and more research attention. Unlike communication, radar has many unique features in terms of waveform criteria, self-interference cancellation (SIC), aperture-dependent resolution, and virtual aperture. This paper proposes a waveform design named max-aperture radar slicing (MaRS) to gain a large time-frequency aperture, which reuses the orthogonal frequency division multiplexing (OFDM) hardware and occupies only a tiny fraction of OFDM resources. The proposed MaRS keeps the radar advantages of constant modulus, zero auto-correlation, and simple SIC. Joint space-time processing algorithms are proposed to recover the range-velocity-angle information from strong clutters. Furthermore, this paper proposes a hybrid-duplex JCAS scheme where communication is half-duplex while radar is full-duplex. In this scheme, the half-duplex communication antenna array is reused, and a small sensing-dedicated antenna array is specially designed. Using these two arrays, a large space-domain aperture is virtually formed to greatly improve the angle resolution. The numerical results show that the proposed MaRS and hybrid-duplex schemes achieve a high sensing resolution with less than 0.4% OFDM resources and gain an almost 100% hit rate for both car and UAV detection at a range up to 1 km.
Multilingual Medical Question Answering and Information Retrieval for Rural Health Intelligence Access
Jun 02, 2021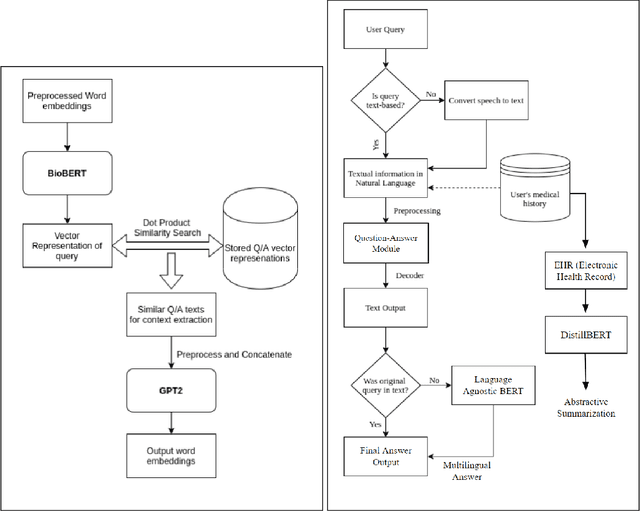

In rural regions of several developing countries, access to quality healthcare, medical infrastructure, and professional diagnosis is largely unavailable. Many of these regions are gradually gaining access to internet infrastructure, although not with a strong enough connection to allow for sustained communication with a medical practitioner. Several deaths resulting from this lack of medical access, absence of patient's previous health records, and the unavailability of information in indigenous languages can be easily prevented. In this paper, we describe an approach leveraging the phenomenal progress in Machine Learning and NLP (Natural Language Processing) techniques to design a model that is low-resource, multilingual, and a preliminary first-point-of-contact medical assistant. Our contribution includes defining the NLP pipeline required for named-entity-recognition, language-agnostic sentence embedding, natural language translation, information retrieval, question answering, and generative pre-training for final query processing. We obtain promising results for this pipeline and preliminary results for EHR (Electronic Health Record) analysis with text summarization for medical practitioners to peruse for their diagnosis. Through this NLP pipeline, we aim to provide preliminary medical information to the user and do not claim to supplant diagnosis from qualified medical practitioners. Using the input from subject matter experts, we have compiled a large corpus to pre-train and fine-tune our BioBERT based NLP model for the specific tasks. We expect recent advances in NLP architectures, several of which are efficient and privacy-preserving models, to further the impact of our solution and improve on individual task performance.