 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTADA! Tuning Audio Diffusion Models through Activation Steering
Feb 12, 2026Audio diffusion models can synthesize high-fidelity music from text, yet their internal mechanisms for representing high-level concepts remain poorly understood. In this work, we use activation patching to demonstrate that distinct semantic musical concepts, such as the presence of specific instruments, vocals, or genre characteristics, are controlled by a small, shared subset of attention layers in state-of-the-art audio diffusion architectures. Next, we demonstrate that applying Contrastive Activation Addition and Sparse Autoencoders in these layers enables more precise control over the generated audio, indicating a direct benefit of the specialization phenomenon. By steering activations of the identified layers, we can alter specific musical elements with high precision, such as modulating tempo or changing a track's mood.
ELROND: Exploring and decomposing intrinsic capabilities of diffusion models
Feb 10, 2026A single text prompt passed to a diffusion model often yields a wide range of visual outputs determined solely by stochastic process, leaving users with no direct control over which specific semantic variations appear in the image. While existing unsupervised methods attempt to analyze these variations via output features, they omit the underlying generative process. In this work, we propose a framework to disentangle these semantic directions directly within the input embedding space. To that end, we collect a set of gradients obtained by backpropagating the differences between stochastic realizations of a fixed prompt that we later decompose into meaningful steering directions with either Principal Components Analysis or Sparse Autoencoder. Our approach yields three key contributions: (1) it isolates interpretable, steerable directions for precise, fine-grained control over a single concept; (2) it effectively mitigates mode collapse in distilled models by reintroducing lost diversity; and (3) it establishes a novel estimator for concept complexity under a specific model, based on the dimensionality of the discovered subspace.
Membership and Dataset Inference Attacks on Large Audio Generative Models
Dec 10, 2025Generative audio models, based on diffusion and autoregressive architectures, have advanced rapidly in both quality and expressiveness. This progress, however, raises pressing copyright concerns, as such models are often trained on vast corpora of artistic and commercial works. A central question is whether one can reliably verify if an artist's material was included in training, thereby providing a means for copyright holders to protect their content. In this work, we investigate the feasibility of such verification through membership inference attacks (MIA) on open-source generative audio models, which attempt to determine whether a specific audio sample was part of the training set. Our empirical results show that membership inference alone is of limited effectiveness at scale, as the per-sample membership signal is weak for models trained on large and diverse datasets. However, artists and media owners typically hold collections of works rather than isolated samples. Building on prior work in text and vision domains, in this work we focus on dataset inference (DI), which aggregates diverse membership evidence across multiple samples. We find that DI is successful in the audio domain, offering a more practical mechanism for assessing whether an artist's works contributed to model training. Our results suggest DI as a promising direction for copyright protection and dataset accountability in the era of large audio generative models.
ExpertSim: Fast Particle Detector Simulation Using Mixture-of-Generative-Experts
Aug 28, 2025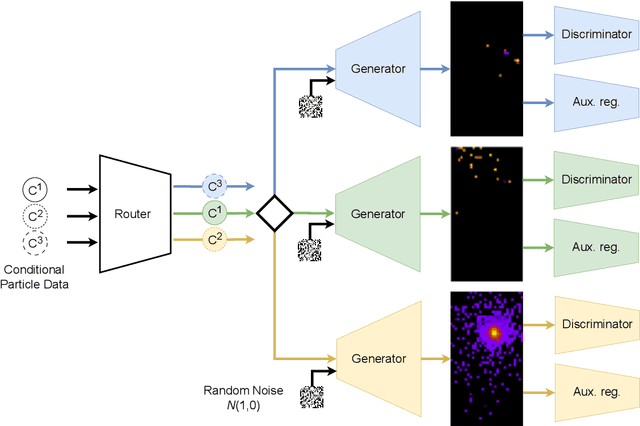
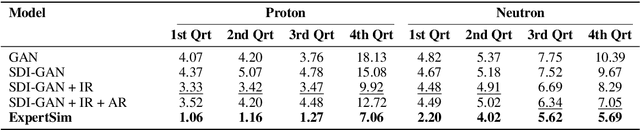
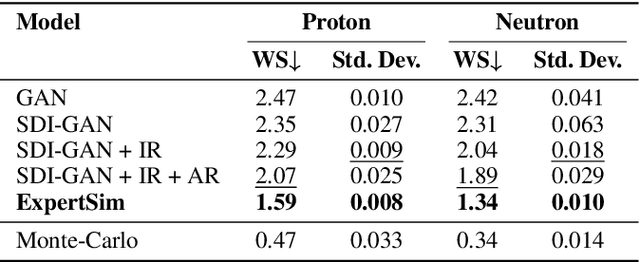
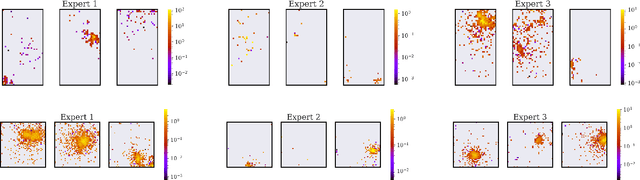
Simulating detector responses is a crucial part of understanding the inner workings of particle collisions in the Large Hadron Collider at CERN. Such simulations are currently performed with statistical Monte Carlo methods, which are computationally expensive and put a significant strain on CERN's computational grid. Therefore, recent proposals advocate for generative machine learning methods to enable more efficient simulations. However, the distribution of the data varies significantly across the simulations, which is hard to capture with out-of-the-box methods. In this study, we present ExpertSim - a deep learning simulation approach tailored for the Zero Degree Calorimeter in the ALICE experiment. Our method utilizes a Mixture-of-Generative-Experts architecture, where each expert specializes in simulating a different subset of the data. This allows for a more precise and efficient generation process, as each expert focuses on a specific aspect of the calorimeter response. ExpertSim not only improves accuracy, but also provides a significant speedup compared to the traditional Monte-Carlo methods, offering a promising solution for high-efficiency detector simulations in particle physics experiments at CERN. We make the code available at https://github.com/patrick-bedkowski/expertsim-mix-of-generative-experts.
SAeUron: Interpretable Concept Unlearning in Diffusion Models with Sparse Autoencoders
Jan 31, 2025



Diffusion models, while powerful, can inadvertently generate harmful or undesirable content, raising significant ethical and safety concerns. Recent machine unlearning approaches offer potential solutions but often lack transparency, making it difficult to understand the changes they introduce to the base model. In this work, we introduce SAeUron, a novel method leveraging features learned by sparse autoencoders (SAEs) to remove unwanted concepts in text-to-image diffusion models. First, we demonstrate that SAEs, trained in an unsupervised manner on activations from multiple denoising timesteps of the diffusion model, capture sparse and interpretable features corresponding to specific concepts. Building on this, we propose a feature selection method that enables precise interventions on model activations to block targeted content while preserving overall performance. Evaluation with the competitive UnlearnCanvas benchmark on object and style unlearning highlights SAeUron's state-of-the-art performance. Moreover, we show that with a single SAE, we can remove multiple concepts simultaneously and that in contrast to other methods, SAeUron mitigates the possibility of generating unwanted content, even under adversarial attack. Code and checkpoints are available at: https://github.com/cywinski/SAeUron.
Joint Diffusion models in Continual Learning
Nov 12, 2024



In this work, we introduce JDCL - a new method for continual learning with generative rehearsal based on joint diffusion models. Neural networks suffer from catastrophic forgetting defined as abrupt loss in the model's performance when retrained with additional data coming from a different distribution. Generative-replay-based continual learning methods try to mitigate this issue by retraining a model with a combination of new and rehearsal data sampled from a generative model. In this work, we propose to extend this idea by combining a continually trained classifier with a diffusion-based generative model into a single - jointly optimized neural network. We show that such shared parametrization, combined with the knowledge distillation technique allows for stable adaptation to new tasks without catastrophic forgetting. We evaluate our approach on several benchmarks, where it outperforms recent state-of-the-art generative replay techniques. Additionally, we extend our method to the semi-supervised continual learning setup, where it outperforms competing buffer-based replay techniques, and evaluate, in a self-supervised manner, the quality of trained representations.
Mediffusion: Joint Diffusion for Self-Explainable Semi-Supervised Classification and Medical Image Generation
Nov 12, 2024We introduce Mediffusion -- a new method for semi-supervised learning with explainable classification based on a joint diffusion model. The medical imaging domain faces unique challenges due to scarce data labelling -- insufficient for standard training, and critical nature of the applications that require high performance, confidence, and explainability of the models. In this work, we propose to tackle those challenges with a single model that combines standard classification with a diffusion-based generative task in a single shared parametrisation. By sharing representations, our model effectively learns from both labeled and unlabeled data while at the same time providing accurate explanations through counterfactual examples. In our experiments, we show that our Mediffusion achieves results comparable to recent semi-supervised methods while providing more reliable and precise explanations.
There and Back Again: On the relation between noises, images, and their inversions in diffusion models
Oct 31, 2024Denoising Diffusion Probabilistic Models (DDPMs) achieve state-of-the-art performance in synthesizing new images from random noise, but they lack meaningful latent space that encodes data into features. Recent DDPM-based editing techniques try to mitigate this issue by inverting images back to their approximated staring noise. In this work, we study the relation between the initial Gaussian noise, the samples generated from it, and their corresponding latent encodings obtained through the inversion procedure. First, we interpret their spatial distance relations to show the inaccuracy of the DDIM inversion technique by localizing latent representations manifold between the initial noise and generated samples. Then, we demonstrate the peculiar relation between initial Gaussian noise and its corresponding generations during diffusion training, showing that the high-level features of generated images stabilize rapidly, keeping the spatial distance relationship between noises and generations consistent throughout the training.
Low-Rank Continual Personalization of Diffusion Models
Oct 07, 2024



Recent personalization methods for diffusion models, such as Dreambooth, allow fine-tuning pre-trained models to generate new concepts. However, applying these techniques across multiple tasks in order to include, e.g., several new objects or styles, leads to mutual interference between their adapters. While recent studies attempt to mitigate this issue by combining trained adapters across tasks after fine-tuning, we adopt a more rigorous regime and investigate the personalization of large diffusion models under a continual learning scenario, where such interference leads to catastrophic forgetting of previous knowledge. To that end, we evaluate the na\"ive continual fine-tuning of customized models and compare this approach with three methods for consecutive adapters' training: sequentially merging new adapters, merging orthogonally initialized adapters, and updating only relevant parameters according to the task. In our experiments, we show that the proposed approaches mitigate forgetting when compared to the na\"ive approach.
Generative Diffusion Models for Fast Simulations of Particle Collisions at CERN
Jun 05, 2024
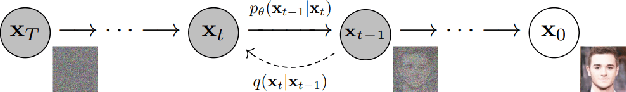
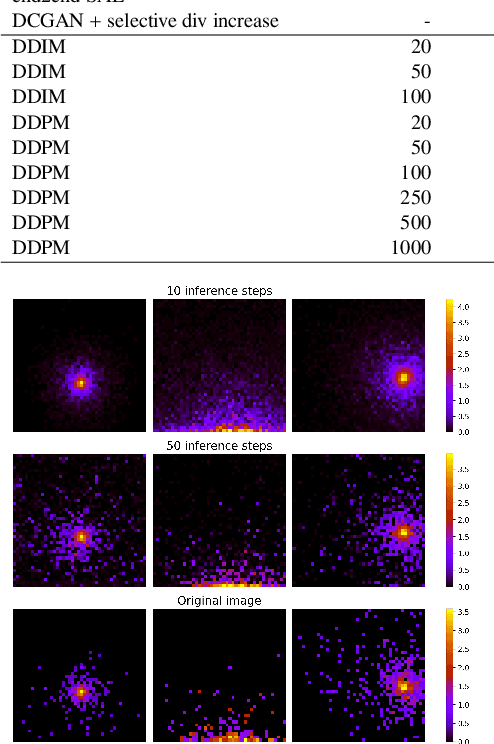
In High Energy Physics simulations play a crucial role in unraveling the complexities of particle collision experiments within CERN's Large Hadron Collider. Machine learning simulation methods have garnered attention as promising alternatives to traditional approaches. While existing methods mainly employ Variational Autoencoders (VAEs) or Generative Adversarial Networks (GANs), recent advancements highlight the efficacy of diffusion models as state-of-the-art generative machine learning methods. We present the first simulation for Zero Degree Calorimeter (ZDC) at the ALICE experiment based on diffusion models, achieving the highest fidelity compared to existing baselines. We perform an analysis of trade-offs between generation times and the simulation quality. The results indicate a significant potential of latent diffusion model due to its rapid generation time.