 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SceneTrilogy: On Scene Sketches and its Relationship with Text and Photo
Apr 25, 2022
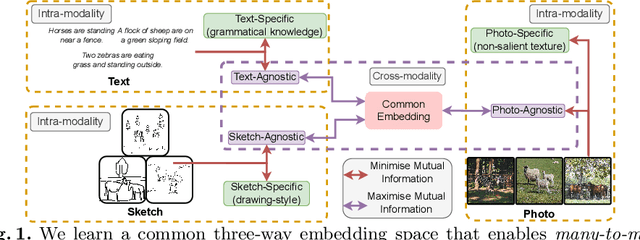
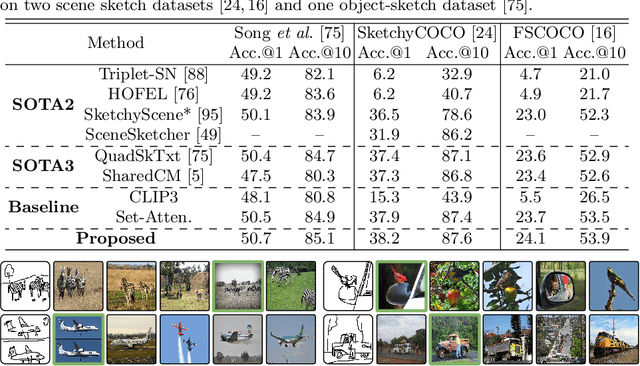
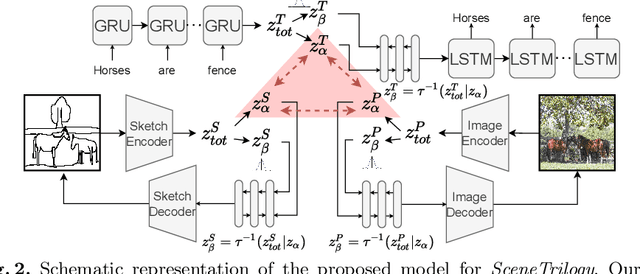

We for the first time extend multi-modal scene understanding to include that of free-hand scene sketches. This uniquely results in a trilogy of scene data modalities (sketch, text, and photo), where each offers unique perspectives for scene understanding, and together enable a series of novel scene-specific applications across discriminative (retrieval) and generative (captioning) tasks. Our key objective is to learn a common three-way embedding space that enables many-to-many modality interactions (e.g, sketch+text $\rightarrow$ photo retrieval). We importantly leverage the information bottleneck theory to achieve this goal, where we (i) decouple intra-modality information by minimising the mutual information between modality-specific and modality-agnostic components via a conditional invertible neural network, and (ii) align \textit{cross-modalities information} by maximising the mutual information between their modality-agnostic components using InfoNCE, with a specific multihead attention mechanism to allow many-to-many modality interactions. We spell out a few insights on the complementarity of each modality for scene understanding, and study for the first time a series of scene-specific applications like joint sketch- and text-based image retrieval, sketch captioning.
Training a universal instance segmentation network for live cell images of various cell types and imaging modalities
Jul 28, 2022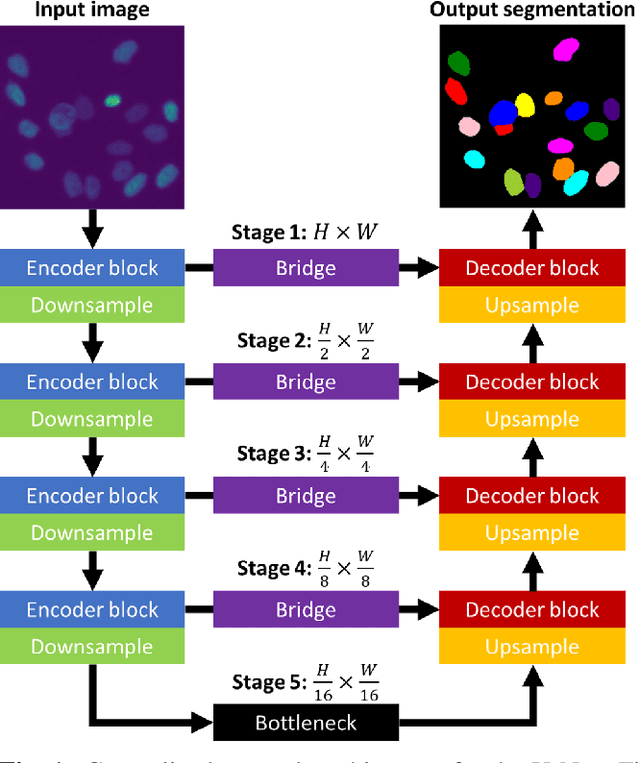
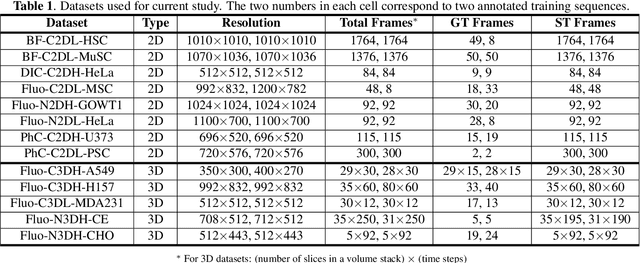

We share our recent findings in an attempt to train a universal segmentation network for various cell types and imaging modalities. Our method was built on the generalized U-Net architecture, which allows the evaluation of each component individually. We modified the traditional binary training targets to include three classes for direct instance segmentation. Detailed experiments were performed regarding training schemes, training settings, network backbones, and individual modules on the segmentation performance. Our proposed training scheme draws minibatches in turn from each dataset, and the gradients are accumulated before an optimization step. We found that the key to training a universal network is all-time supervision on all datasets, and it is necessary to sample each dataset in an unbiased way. Our experiments also suggest that there might exist common features to define cell boundaries across cell types and imaging modalities, which could allow application of trained models to totally unseen datasets. A few training tricks can further boost the segmentation performance, including uneven class weights in the cross-entropy loss function, well-designed learning rate scheduler, larger image crops for contextual information, and additional loss terms for unbalanced classes. We also found that segmentation performance can benefit from group normalization layer and Atrous Spatial Pyramid Pooling module, thanks to their more reliable statistics estimation and improved semantic understanding, respectively. We participated in the 6th Cell Tracking Challenge (CTC) held at IEEE International Symposium on Biomedical Imaging (ISBI) 2021 using one of the developed variants. Our method was evaluated as the best runner up during the initial submission for the primary track, and also secured the 3rd place in an additional round of competition in preparation for the summary publication.
Mirror Descent and the Information Ratio
Sep 25, 2020
We establish a connection between the stability of mirror descent and the information ratio by Russo and Van Roy [2014]. Our analysis shows that mirror descent with suitable loss estimators and exploratory distributions enjoys the same bound on the adversarial regret as the bounds on the Bayesian regret for information-directed sampling. Along the way, we develop the theory for information-directed sampling and provide an efficient algorithm for adversarial bandits for which the regret upper bound matches exactly the best known information-theoretic upper bound.
Pretraining on Interactions for Learning Grounded Affordance Representations
Jul 05, 2022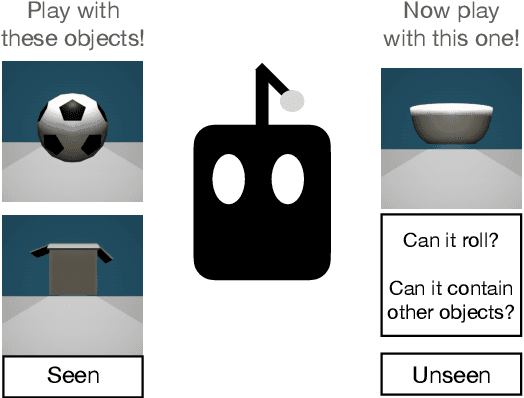
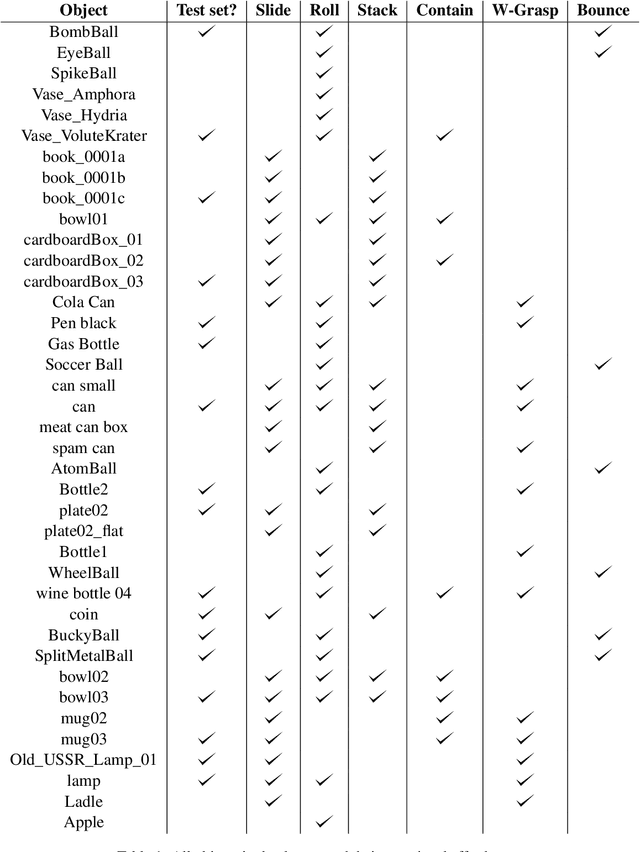

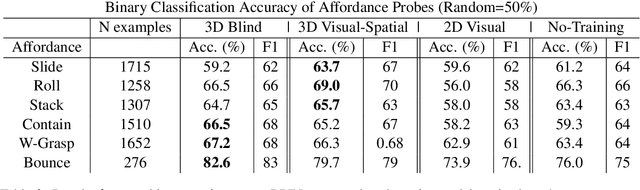
Lexical semantics and cognitive science point to affordances (i.e. the actions that objects support) as critical for understanding and representing nouns and verbs. However, study of these semantic features has not yet been integrated with the "foundation" models that currently dominate language representation research. We hypothesize that predictive modeling of object state over time will result in representations that encode object affordance information "for free". We train a neural network to predict objects' trajectories in a simulated interaction and show that our network's latent representations differentiate between both observed and unobserved affordances. We find that models trained using 3D simulations from our SPATIAL dataset outperform conventional 2D computer vision models trained on a similar task, and, on initial inspection, that differences between concepts correspond to expected features (e.g., roll entails rotation). Our results suggest a way in which modern deep learning approaches to grounded language learning can be integrated with traditional formal semantic notions of lexical representations.
Transfer functions of FXLMS-based Multi-channel Multi-tone Active Noise Equalizers
Jul 03, 2022
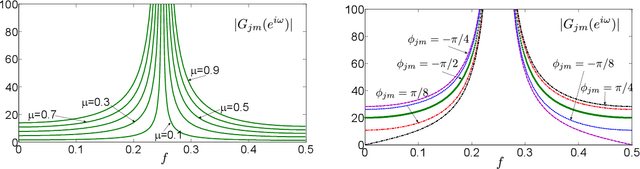
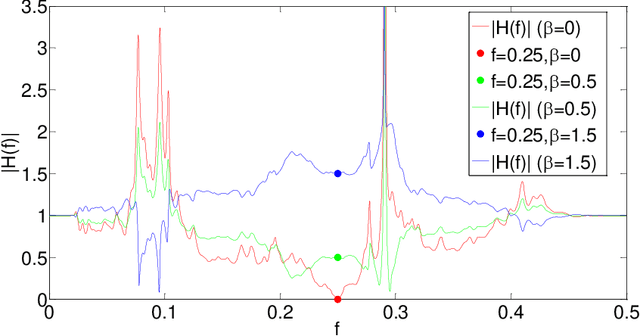
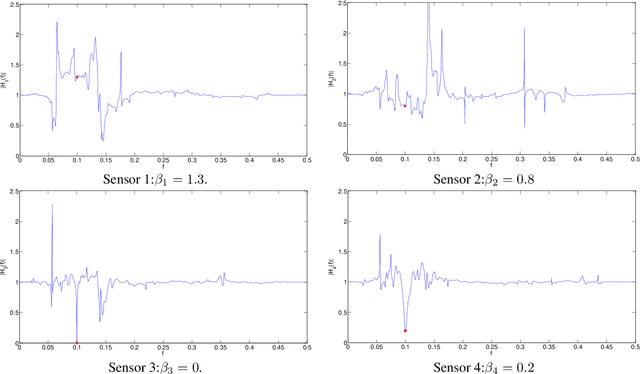
Multi-channel Multi-tone Active Noise Equalizers can achieve different user-selected noise spectrum profiles even at different space positions. They can apply a different equalization factor at each noise frequency component and each control point. Theoretically, the value of the transfer function at the frequencies where the noise signal has energy is determined by the equalizer configuration. In this work, we show how to calculate these transfer functions with a double aim: to verify that at the frequencies of interest the values imposed by the equalizer settings are obtained, and to characterize the behavior of these transfer functions in the rest of the spectrum, as well as to get clues to predict the convergence behaviour of the algorithm. The information provided thanks to these transfer functions serves as a practical alternative to the cumbersome statistical analysis of convergence, whose results are often of no practical use.
Putting the Con in Context: Identifying Deceptive Actors in the Game of Mafia
Jul 05, 2022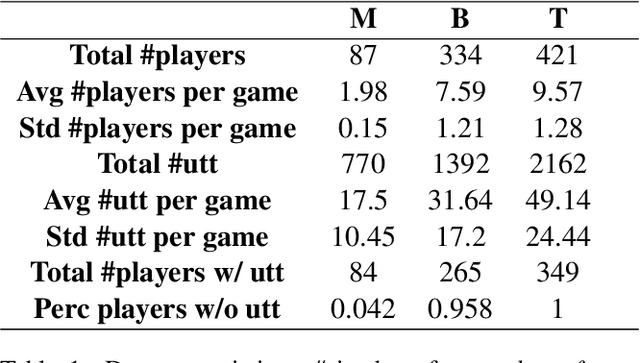
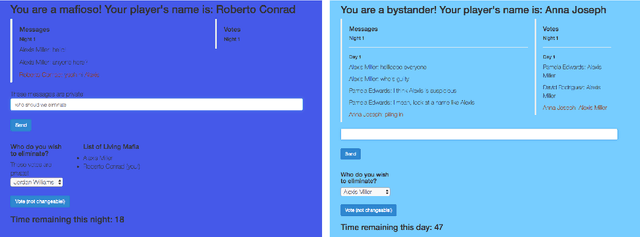


While neural networks demonstrate a remarkable ability to model linguistic content, capturing contextual information related to a speaker's conversational role is an open area of research. In this work, we analyze the effect of speaker role on language use through the game of Mafia, in which participants are assigned either an honest or a deceptive role. In addition to building a framework to collect a dataset of Mafia game records, we demonstrate that there are differences in the language produced by players with different roles. We confirm that classification models are able to rank deceptive players as more suspicious than honest ones based only on their use of language. Furthermore, we show that training models on two auxiliary tasks outperforms a standard BERT-based text classification approach. We also present methods for using our trained models to identify features that distinguish between player roles, which could be used to assist players during the Mafia game.
Self-Supervised Deep Subspace Clustering with Entropy-norm
Jun 10, 2022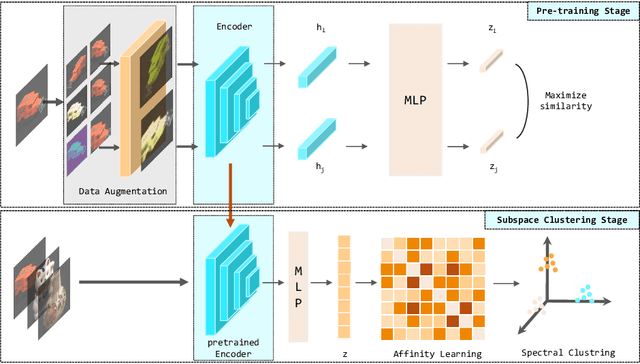
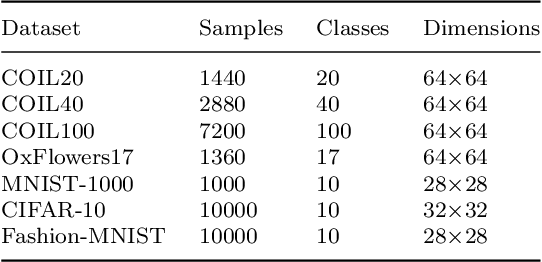
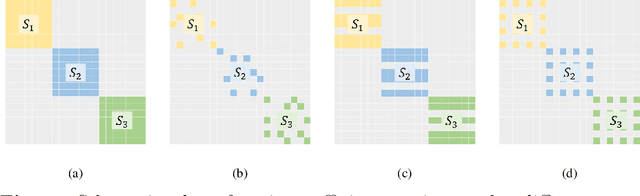

Auto-Encoder based deep subspace clustering (DSC) is widely used in computer vision, motion segmentation and image processing. However, it suffers from the following three issues in the self-expressive matrix learning process: the first one is less useful information for learning self-expressive weights due to the simple reconstruction loss; the second one is that the construction of the self-expression layer associated with the sample size requires high-computational cost; and the last one is the limited connectivity of the existing regularization terms. In order to address these issues, in this paper we propose a novel model named Self-Supervised deep Subspace Clustering with Entropy-norm (S$^{3}$CE). Specifically, S$^{3}$CE exploits a self-supervised contrastive network to gain a more effetive feature vector. The local structure and dense connectivity of the original data benefit from the self-expressive layer and additional entropy-norm constraint. Moreover, a new module with data enhancement is designed to help S$^{3}$CE focus on the key information of data, and improve the clustering performance of positive and negative instances through spectral clustering. Extensive experimental results demonstrate the superior performance of S$^{3}$CE in comparison to the state-of-the-art approaches.
UniCon+: ICTCAS-UCAS Submission to the AVA-ActiveSpeaker Task at ActivityNet Challenge 2022
Jun 22, 2022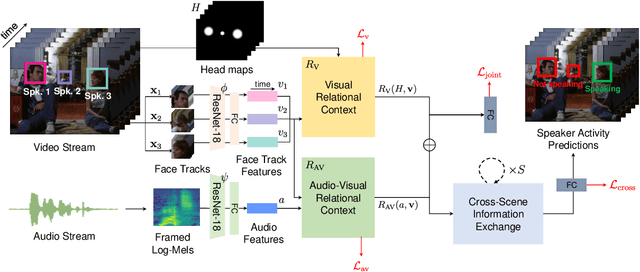
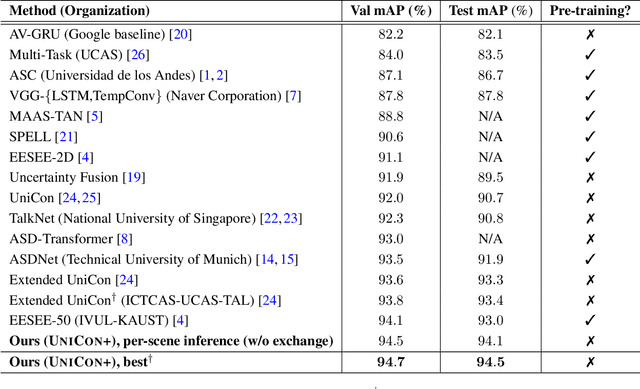
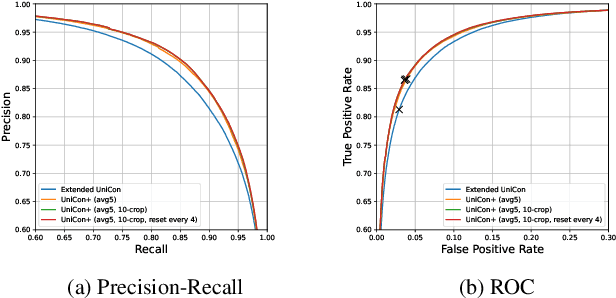
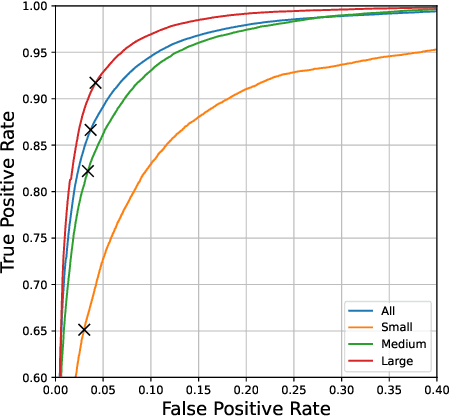
This report presents a brief description of our winning solution to the AVA Active Speaker Detection (ASD) task at ActivityNet Challenge 2022. Our underlying model UniCon+ continues to build on our previous work, the Unified Context Network (UniCon) and Extended UniCon which are designed for robust scene-level ASD. We augment the architecture with a simple GRU-based module that allows information of recurring identities to flow across scenes through read and update operations. We report a best result of 94.47% mAP on the AVA-ActiveSpeaker test set, which continues to rank first on this year's challenge leaderboard and significantly pushes the state-of-the-art.
Compositional Human-Scene Interaction Synthesis with Semantic Control
Jul 26, 2022


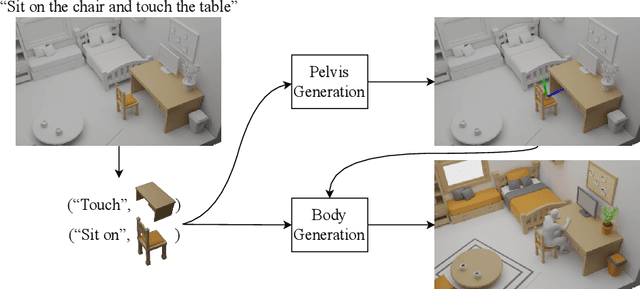
Synthesizing natural interactions between virtual humans and their 3D environments is critical for numerous applications, such as computer games and AR/VR experiences. Our goal is to synthesize humans interacting with a given 3D scene controlled by high-level semantic specifications as pairs of action categories and object instances, e.g., "sit on the chair". The key challenge of incorporating interaction semantics into the generation framework is to learn a joint representation that effectively captures heterogeneous information, including human body articulation, 3D object geometry, and the intent of the interaction. To address this challenge, we design a novel transformer-based generative model, in which the articulated 3D human body surface points and 3D objects are jointly encoded in a unified latent space, and the semantics of the interaction between the human and objects are embedded via positional encoding. Furthermore, inspired by the compositional nature of interactions that humans can simultaneously interact with multiple objects, we define interaction semantics as the composition of varying numbers of atomic action-object pairs. Our proposed generative model can naturally incorporate varying numbers of atomic interactions, which enables synthesizing compositional human-scene interactions without requiring composite interaction data. We extend the PROX dataset with interaction semantic labels and scene instance segmentation to evaluate our method and demonstrate that our method can generate realistic human-scene interactions with semantic control. Our perceptual study shows that our synthesized virtual humans can naturally interact with 3D scenes, considerably outperforming existing methods. We name our method COINS, for COmpositional INteraction Synthesis with Semantic Control. Code and data are available at https://github.com/zkf1997/COINS.
Exploiting Social Graph Networks for Emotion Prediction
Jul 12, 2022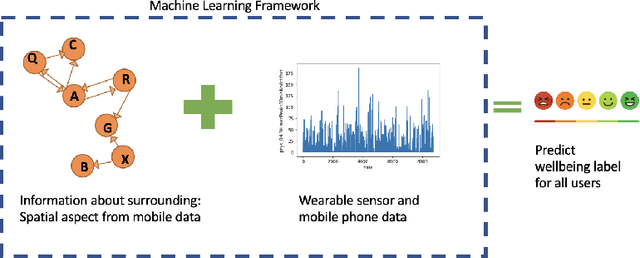
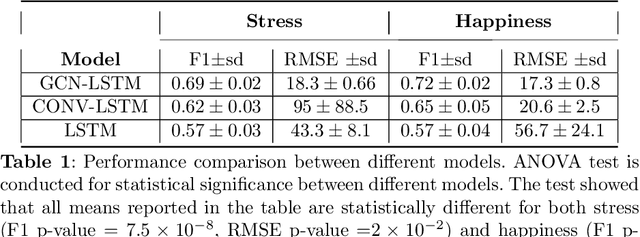
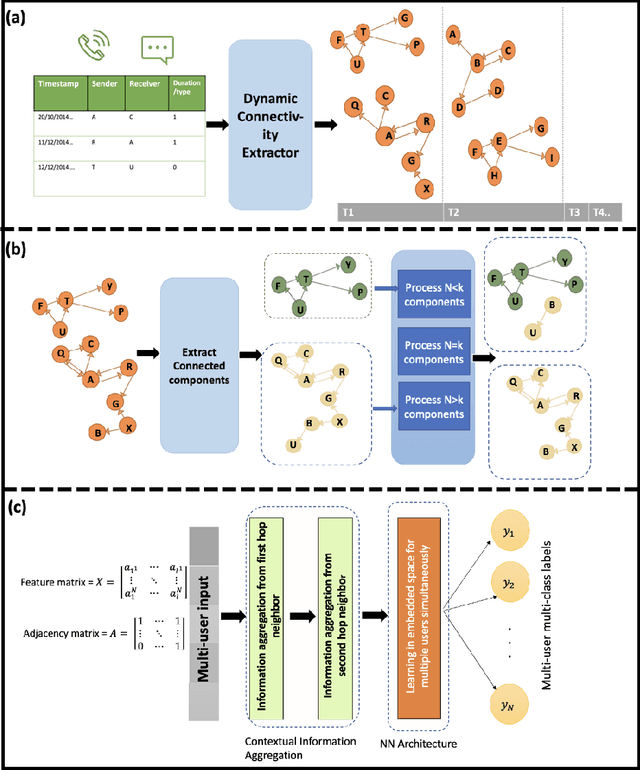
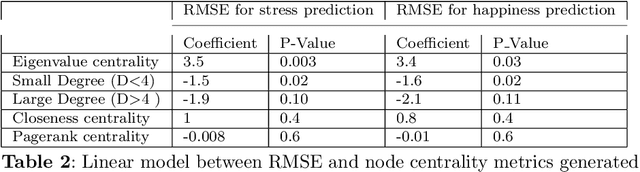
Emotion prediction plays an essential role in mental health and emotion-aware computing. The complex nature of emotion resulting from its dependency on a person's physiological health, mental state, and his surroundings makes its prediction a challenging task. In this work, we utilize mobile sensing data to predict happiness and stress. In addition to a person's physiological features, we also incorporate the environment's impact through weather and social network. To this end, we leverage phone data to construct social networks and develop a machine learning architecture that aggregates information from multiple users of the graph network and integrates it with the temporal dynamics of data to predict emotion for all the users. The construction of social networks does not incur additional cost in terms of EMAs or data collection from users and doesn't raise privacy concerns. We propose an architecture that automates the integration of a user's social network affect prediction, is capable of dealing with the dynamic distribution of real-life social networks, making it scalable to large-scale networks. Our extensive evaluation highlights the improvement provided by the integration of social networks. We further investigate the impact of graph topology on model's performance.