 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information Symmetry Matters: A Modal-Alternating Propagation Network for Few-Shot Learning
Sep 03, 2021
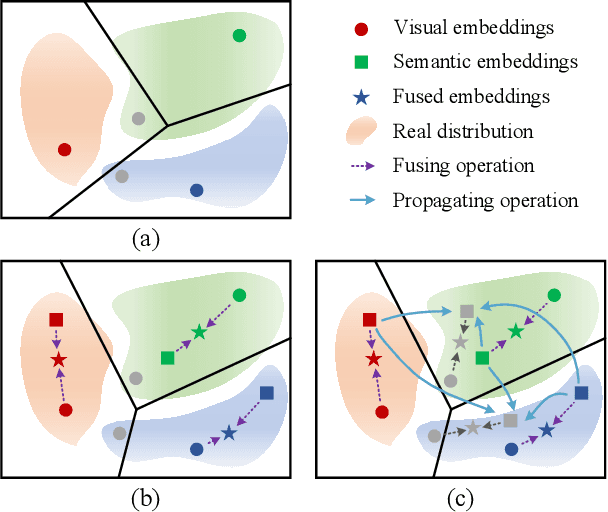
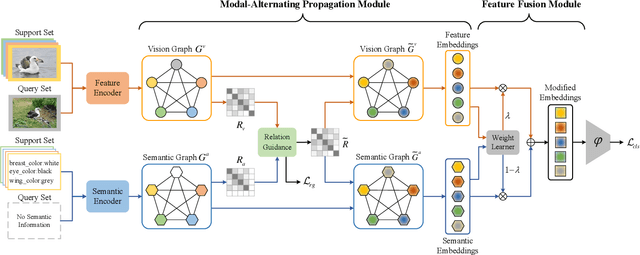
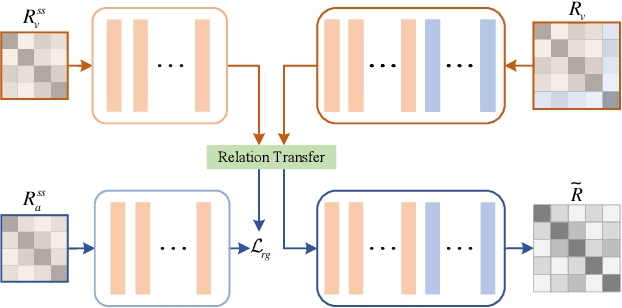
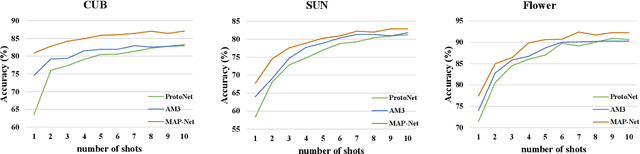
Semantic information provides intra-class consistency and inter-class discriminability beyond visual concepts, which has been employed in Few-Shot Learning (FSL) to achieve further gains. However, semantic information is only available for labeled samples but absent for unlabeled samples, in which the embeddings are rectified unilaterally by guiding the few labeled samples with semantics. Therefore, it is inevitable to bring a cross-modal bias between semantic-guided samples and nonsemantic-guided samples, which results in an information asymmetry problem. To address this problem, we propose a Modal-Alternating Propagation Network (MAP-Net) to supplement the absent semantic information of unlabeled samples, which builds information symmetry among all samples in both visual and semantic modalities. Specifically, the MAP-Net transfers the neighbor information by the graph propagation to generate the pseudo-semantics for unlabeled samples guided by the completed visual relationships and rectify the feature embeddings. In addition, due to the large discrepancy between visual and semantic modalities, we design a Relation Guidance (RG) strategy to guide the visual relation vectors via semantics so that the propagated information is more beneficial. Extensive experimental results on three semantic-labeled datasets, i.e., Caltech-UCSD-Birds 200-2011, SUN Attribute Database, and Oxford 102 Flower, have demonstrated that our proposed method achieves promising performance and outperforms the state-of-the-art approaches, which indicates the necessity of information symmetry.
KL-divergence Based Deep Learning for Discrete Time Model
Aug 10, 2022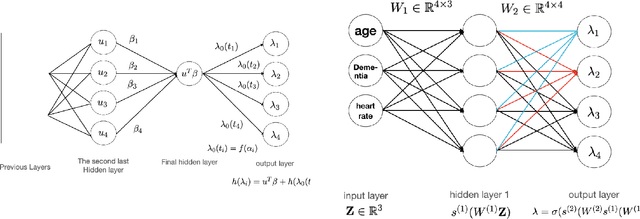
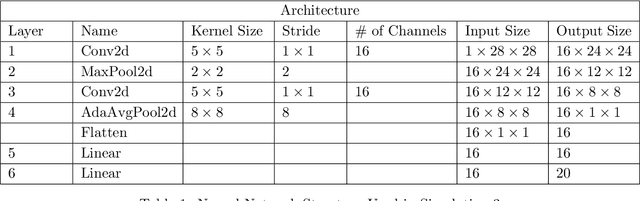
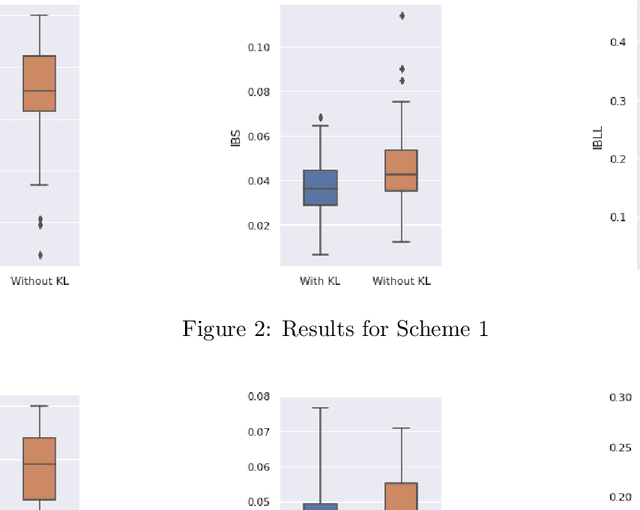
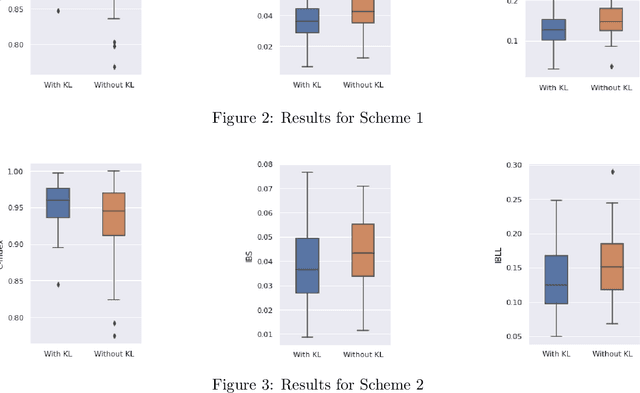
Neural Network (Deep Learning) is a modern model in Artificial Intelligence and it has been exploited in Survival Analysis. Although several improvements have been shown by previous works, training an excellent deep learning model requires a huge amount of data, which may not hold in practice. To address this challenge, we develop a Kullback-Leibler-based (KL) deep learning procedure to integrate external survival prediction models with newly collected time-to-event data. Time-dependent KL discrimination information is utilized to measure the discrepancy between the external and internal data. This is the first work considering using prior information to deal with short data problem in Survival Analysis for deep learning. Simulation and real data results show that the proposed model achieves better performance and higher robustness compared with previous works.
A Tree-structured Transformer for Program Representation Learning
Aug 18, 2022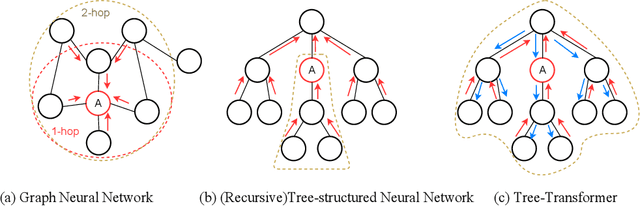
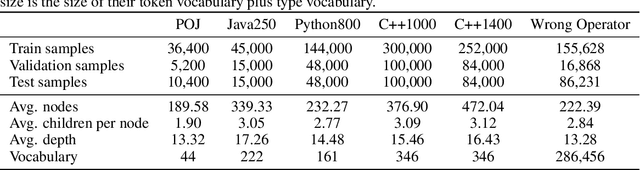
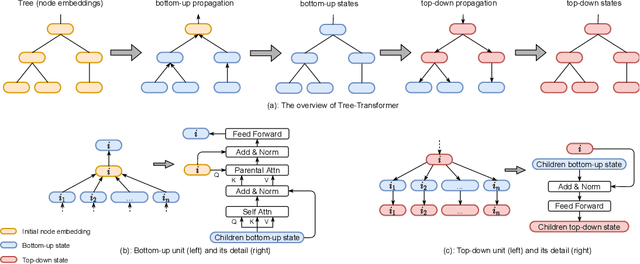
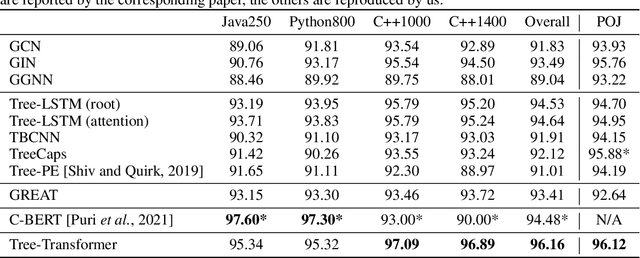
When using deep learning techniques to model program languages, neural networks with tree or graph structures are widely adopted to capture the rich structural information within program abstract syntax trees (AST). However, long-term/global dependencies widely exist in programs, and most of these neural architectures fail to capture these dependencies. In this paper, we propose Tree-Transformer, a novel recursive tree-structured neural network which aims to overcome the above limitations. Tree-Transformer leverages two multi-head attention units to model the dependency between siblings and parent-children node pairs. Moreover, we propose a bi-directional propagation strategy to allow node information passing in two directions: bottom-up and top-down along trees. By combining bottom-up and top-down propagation, Tree-Transformer can learn both global contexts and meaningful node features. The extensive experimental results show that our Tree-Transformer outperforms existing tree-based or graph-based neural networks in program-related tasks with tree-level and node-level prediction tasks, indicating that Tree-Transformer performs well on learning both tree-level and node-level representations.
Information-Theoretic Based Target Search with Multiple Agents
Jul 27, 2021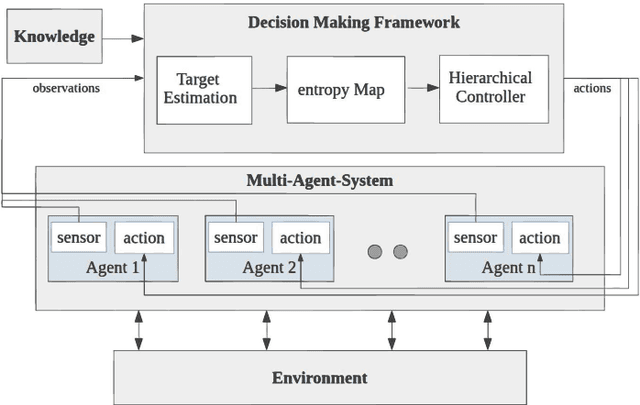
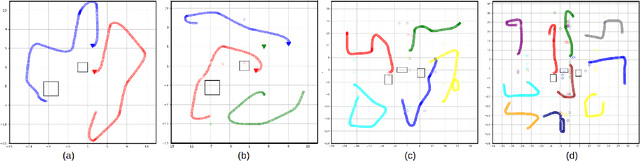
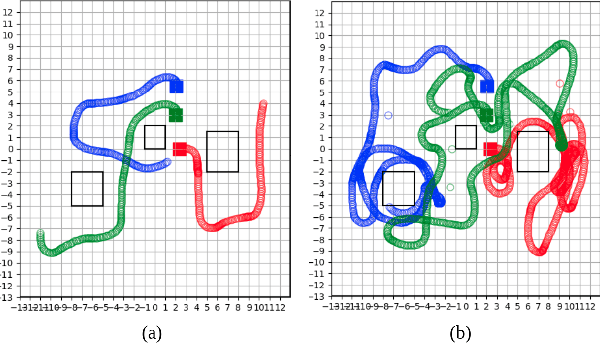
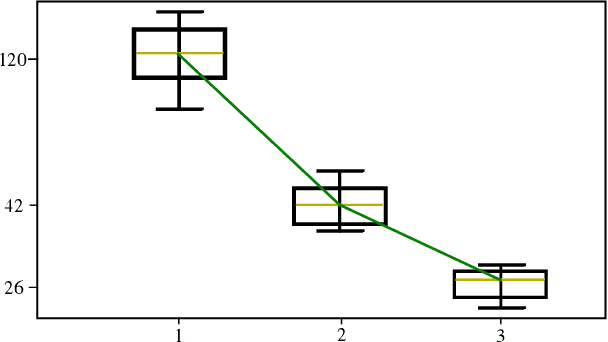
This paper proposes an online path planning and motion generation algorithm for heterogeneous robot teams performing target search in a real-world environment. Path selection for each robot is optimized using an information-theoretic formulation and is computed sequentially for each agent. First, we generate candidate trajectories sampled from both global waypoints derived from vertical cell decomposition and local frontier points. From this set, we choose the path with maximum information gain. We demonstrate that the hierarchical sequential decision-making structure provided by the algorithm is scalable to multiple agents in a simulation setup. We also validate our framework in a real-world apartment setting using a two robot team comprised of the Unitree A1 quadruped and the Toyota HSR mobile manipulator searching for a person. The agents leverage an efficient leader-follower communication structure where only critical information is shared.
SuperYOLO: Super Resolution Assisted Object Detection in Multimodal Remote Sensing Imagery
Sep 27, 2022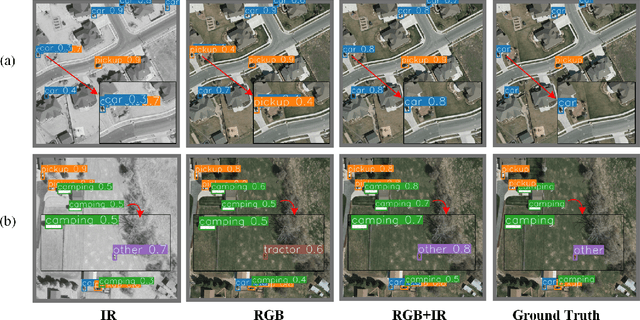
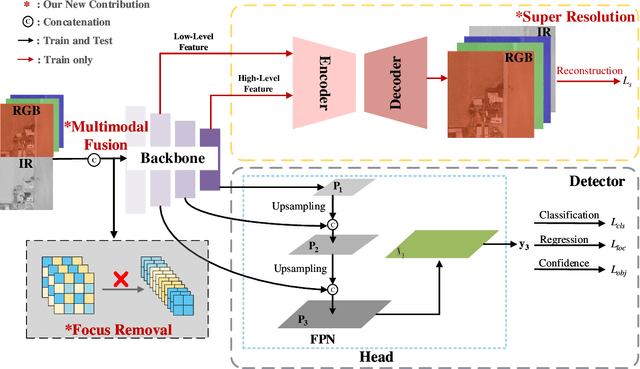
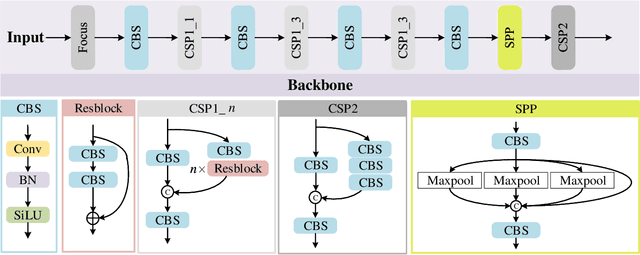
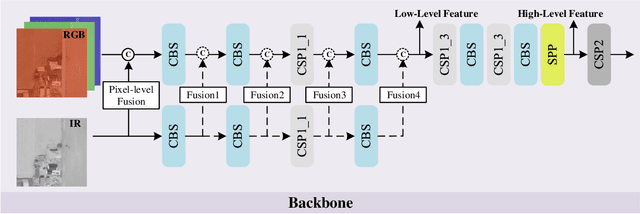
In this paper, we propose an accurate yet fast small object detection method for RSI, named SuperYOLO, which fuses multimodal data and performs high resolution (HR) object detection on multiscale objects by utilizing the assisted super resolution (SR) learning and considering both the detection accuracy and computation cost. First, we construct a compact baseline by removing the Focus module to keep the HR features and significantly overcomes the missing error of small objects. Second, we utilize pixel-level multimodal fusion (MF) to extract information from various data to facilitate more suitable and effective features for small objects in RSI. Furthermore, we design a simple and flexible SR branch to learn HR feature representations that can discriminate small objects from vast backgrounds with low-resolution (LR) input, thus further improving the detection accuracy. Moreover, to avoid introducing additional computation, the SR branch is discarded in the inference stage and the computation of the network model is reduced due to the LR input. Experimental results show that, on the widely used VEDAI RS dataset, SuperYOLO achieves an accuracy of 73.61% (in terms of mAP50), which is more than 10% higher than the SOTA large models such as YOLOv5l, YOLOv5x and RS designed YOLOrs. Meanwhile, the GFOLPs and parameter size of SuperYOLO are about 18.1x and 4.2x less than YOLOv5x. Our proposed model shows a favorable accuracy-speed trade-off compared to the state-of-art models. The code will be open sourced at https://github.com/icey-zhang/SuperYOLO.
A Robust Morphological Approach for Semantic Segmentation of Very High Resolution Images
Aug 02, 2022
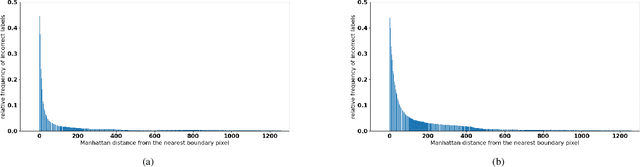
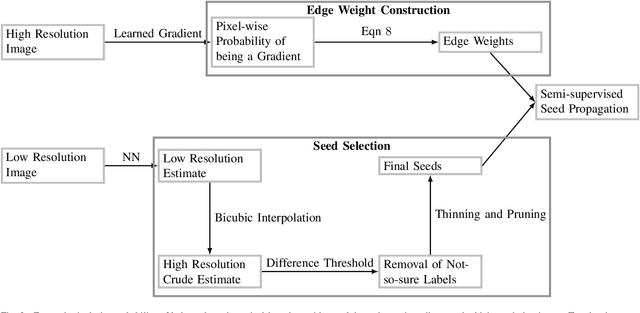

State-of-the-art methods for semantic segmentation of images involve computationally intensive neural network architectures. Most of these methods are not adaptable to high-resolution image segmentation due to memory and other computational issues. Typical approaches in literature involve design of neural network architectures that can fuse global information from low-resolution images and local information from the high-resolution counterparts. However, architectures designed for processing high resolution images are unnecessarily complex and involve a lot of hyper parameters that can be difficult to tune. Also, most of these architectures require ground truth annotations of the high resolution images to train, which can be hard to obtain. In this article, we develop a robust pipeline based on mathematical morphological (MM) operators that can seamlessly extend any existing semantic segmentation algorithm to high resolution images. Our method does not require the ground truth annotations of the high resolution images. It is based on efficiently utilizing information from the low-resolution counterparts, and gradient information on the high-resolution images. We obtain high quality seeds from the inferred labels on low-resolution images using traditional morphological operators and propagate seed labels using a random walker to refine the semantic labels at the boundaries. We show that the semantic segmentation results obtained by our method beat the existing state-of-the-art algorithms on high-resolution images. We empirically prove the robustness of our approach to the hyper parameters used in our pipeline. Further, we characterize some necessary conditions under which our pipeline is applicable and provide an in-depth analysis of the proposed approach.
Assessing Lower Limb Strength using Internet-of-Things Enabled Chair and Processing of Time-Series Data in Google GPU Tensorflow CoLab
Sep 08, 2022

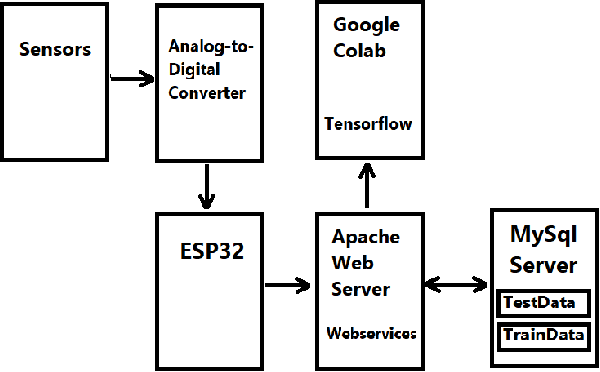

This project describes the application of the technologies of Machine Learning and Internet-of-Things to assess the lower limb strength of individuals undergoing rehabilitation or therapy. Specifically, it seeks to measure and assess the progress of individuals by sensors attached to chairs and processing the data through Google GPU Tensorflow CoLab. Pressure sensors are attached to various locations on a chair, including but not limited to the seating area, backrest, hand rests, and legs. Sensor data from the individual performing both sit-to-stand transition and stand-to-sit transition provides a time series dataset regarding the pressure distribution and vibratory motion on the chair. The dataset and timing information can then be fed into a machine learning model to estimate the relative strength and weakness during various phases of the movement.
Bounding The Rademacher Complexity of Fourier Neural Operator
Sep 12, 2022
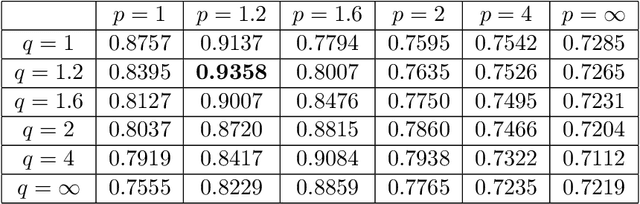
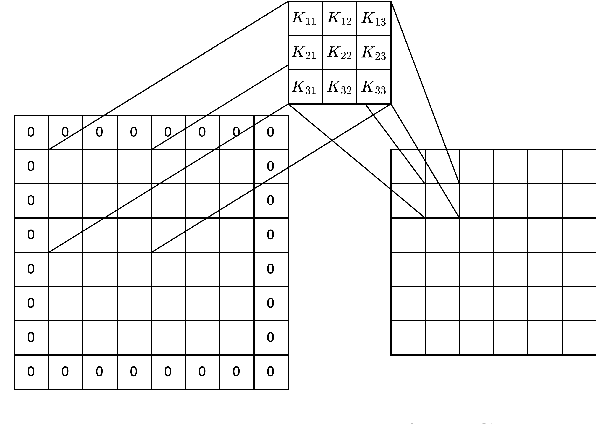

A Fourier neural operator (FNO) is one of the physics-inspired machine learning methods. In particular, it is a neural operator. In recent times, several types of neural operators have been developed, e.g., deep operator networks, GNO, and MWTO. Compared with other models, the FNO is computationally efficient and can learn nonlinear operators between function spaces independent of a certain finite basis. In this study, we investigated the bounding of the Rademacher complexity of the FNO based on specific group norms. Using capacity based on these norms, we bound the generalization error of the FNO model. In addition, we investigated the correlation between the empirical generalization error and the proposed capacity of FNO. Based on this investigation, we gained insight into the impact of the model architecture on the generalization error and estimated the amount of information about FNO models stored in various types of capacities.
Privacy Safe Representation Learning via Frequency Filtering Encoder
Aug 04, 2022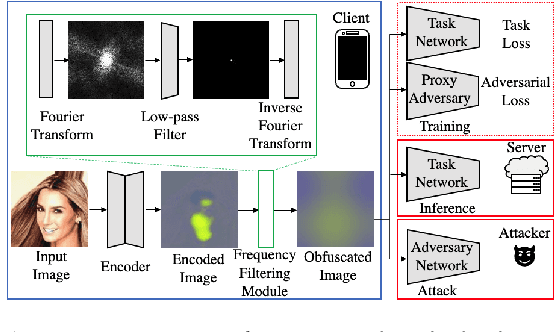
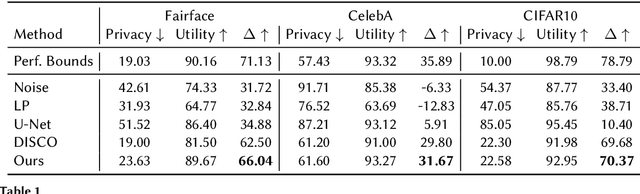

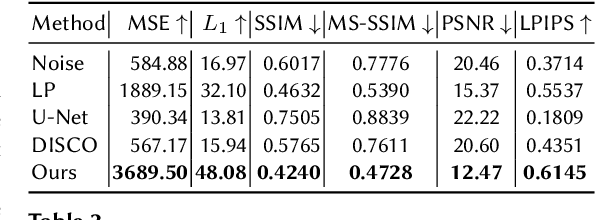
Deep learning models are increasingly deployed in real-world applications. These models are often deployed on the server-side and receive user data in an information-rich representation to solve a specific task, such as image classification. Since images can contain sensitive information, which users might not be willing to share, privacy protection becomes increasingly important. Adversarial Representation Learning (ARL) is a common approach to train an encoder that runs on the client-side and obfuscates an image. It is assumed, that the obfuscated image can safely be transmitted and used for the task on the server without privacy concerns. However, in this work, we find that training a reconstruction attacker can successfully recover the original image of existing ARL methods. To this end, we introduce a novel ARL method enhanced through low-pass filtering, limiting the available information amount to be encoded in the frequency domain. Our experimental results reveal that our approach withstands reconstruction attacks while outperforming previous state-of-the-art methods regarding the privacy-utility trade-off. We further conduct a user study to qualitatively assess our defense of the reconstruction attack.
Causal Effect Estimation using Variational Information Bottleneck
Oct 26, 2021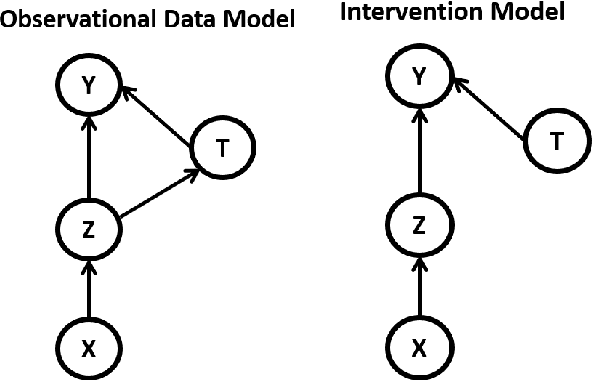
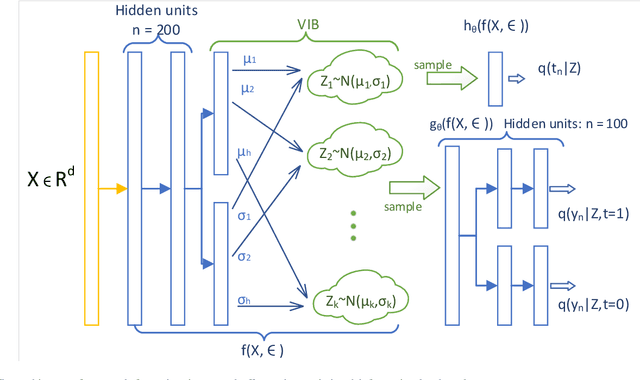
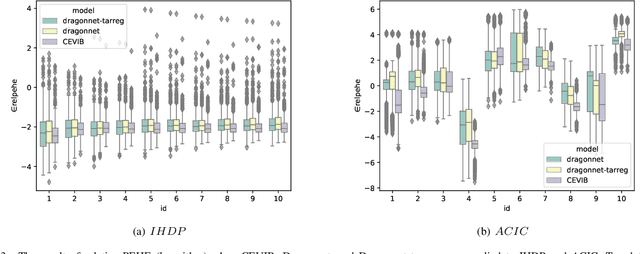
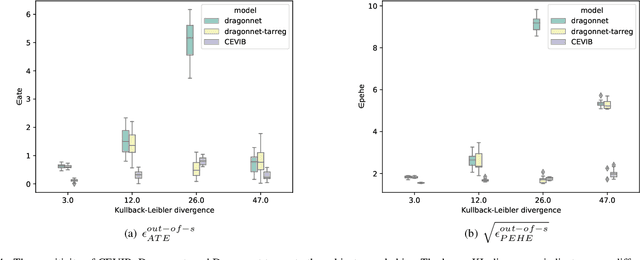
Causal inference is to estimate the causal effect in a causal relationship when intervention is applied. Precisely, in a causal model with binary interventions, i.e., control and treatment, the causal effect is simply the difference between the factual and counterfactual. The difficulty is that the counterfactual may never been obtained which has to be estimated and so the causal effect could only be an estimate. The key challenge for estimating the counterfactual is to identify confounders which effect both outcomes and treatments. A typical approach is to formulate causal inference as a supervised learning problem and so counterfactual could be predicted. Including linear regression and deep learning models, recent machine learning methods have been adapted to causal inference. In this paper, we propose a method to estimate Causal Effect by using Variational Information Bottleneck (CEVIB). The promising point is that VIB is able to naturally distill confounding variables from the data, which enables estimating causal effect by using observational data. We have compared CEVIB to other methods by applying them to three data sets showing that our approach achieved the best performance. We also experimentally showed the robustness of our method.