 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FusionVAE: A Deep Hierarchical Variational Autoencoder for RGB Image Fusion
Sep 22, 2022
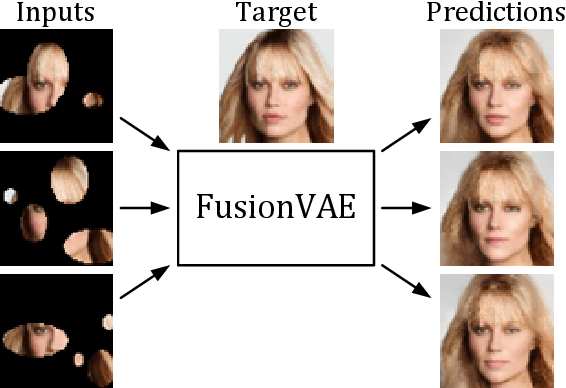
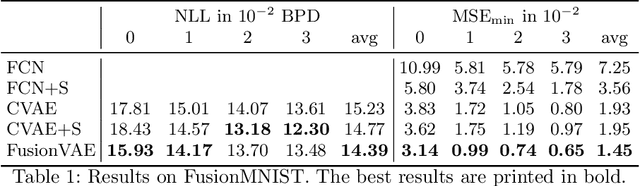
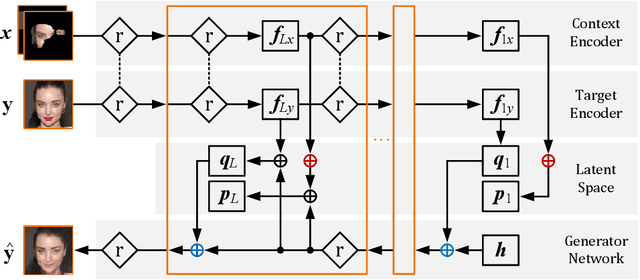
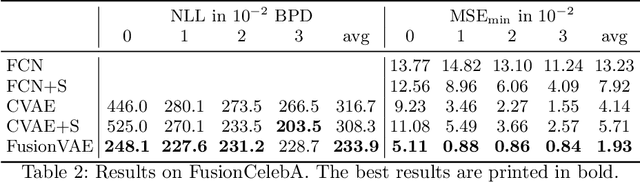
Sensor fusion can significantly improve the performance of many computer vision tasks. However, traditional fusion approaches are either not data-driven and cannot exploit prior knowledge nor find regularities in a given dataset or they are restricted to a single application. We overcome this shortcoming by presenting a novel deep hierarchical variational autoencoder called FusionVAE that can serve as a basis for many fusion tasks. Our approach is able to generate diverse image samples that are conditioned on multiple noisy, occluded, or only partially visible input images. We derive and optimize a variational lower bound for the conditional log-likelihood of FusionVAE. In order to assess the fusion capabilities of our model thoroughly, we created three novel datasets for image fusion based on popular computer vision datasets. In our experiments, we show that FusionVAE learns a representation of aggregated information that is relevant to fusion tasks. The results demonstrate that our approach outperforms traditional methods significantly. Furthermore, we present the advantages and disadvantages of different design choices.
A Case Report On The "A.I. Locked-In Problem": social concerns with modern NLP
Sep 22, 2022Modern NLP models are becoming better conversational agents than their predecessors. Recurrent Neural Networks (RNNs) and especially Long-Short Term Memory (LSTM) features allow the agent to better store and use information about semantic content, a trend that has become even more pronounced with the Transformer Models. Large Language Models (LLMs) such as GPT-3 by OpenAI have become known to be able to construct and follow a narrative, which enables the system to adopt personas on the go, adapt them and play along in conversational stories. However, practical experimentation with GPT-3 shows that there is a recurring problem with these modern NLP systems, namely that they can "get stuck" in the narrative so that further conversations, prompt executions or commands become futile. This is here referred to as the "Locked-In Problem" and is exemplified with an experimental case report, followed by practical and social concerns that are accompanied with this problem.
Gender In Gender Out: A Closer Look at User Attributes in Context-Aware Recommendation
Jul 28, 2022
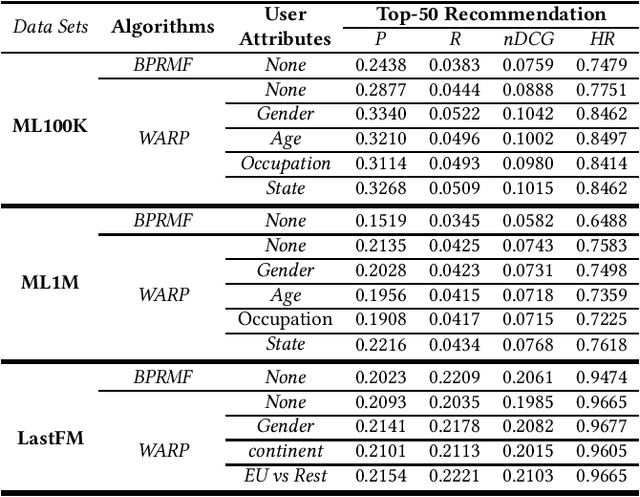
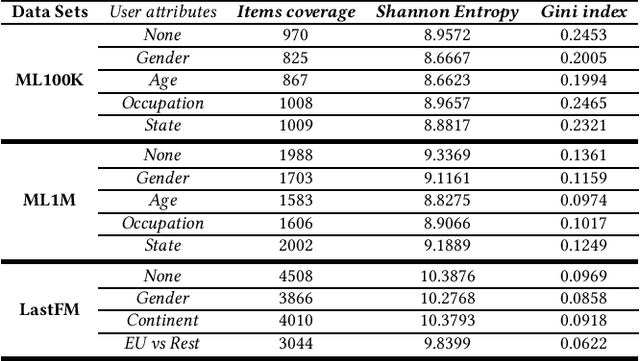
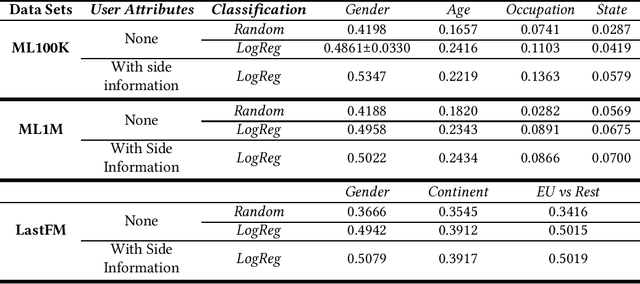
This paper studies user attributes in light of current concerns in the recommender system community: diversity, coverage, calibration, and data minimization. In experiments with a conventional context-aware recommender system that leverages side information, we show that user attributes do not always improve recommendation. Then, we demonstrate that user attributes can negatively impact diversity and coverage. Finally, we investigate the amount of information about users that ``survives'' from the training data into the recommendation lists produced by the recommender. This information is a weak signal that could in the future be exploited for calibration or studied further as a privacy leak.
Modality Mixer for Multi-modal Action Recognition
Aug 24, 2022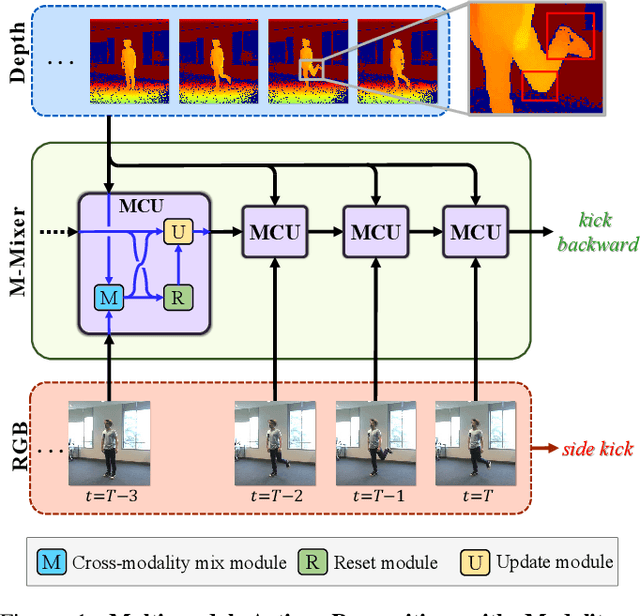

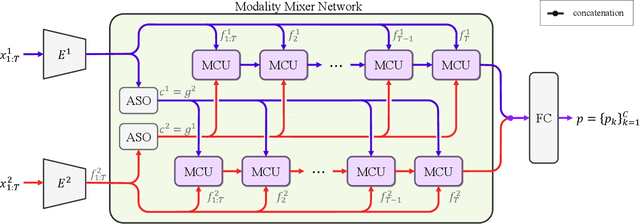
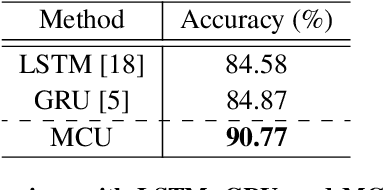
In multi-modal action recognition, it is important to consider not only the complementary nature of different modalities but also global action content. In this paper, we propose a novel network, named Modality Mixer (M-Mixer) network, to leverage complementary information across modalities and temporal context of an action for multi-modal action recognition. We also introduce a simple yet effective recurrent unit, called Multi-modal Contextualization Unit (MCU), which is a core component of M-Mixer. Our MCU temporally encodes a sequence of one modality (e.g., RGB) with action content features of other modalities (e.g., depth, IR). This process encourages M-Mixer to exploit global action content and also to supplement complementary information of other modalities. As a result, our proposed method outperforms state-of-the-art methods on NTU RGB+D 60, NTU RGB+D 120, and NW-UCLA datasets. Moreover, we demonstrate the effectiveness of M-Mixer by conducting comprehensive ablation studies.
Decomposed Prompting: A Modular Approach for Solving Complex Tasks
Oct 05, 2022

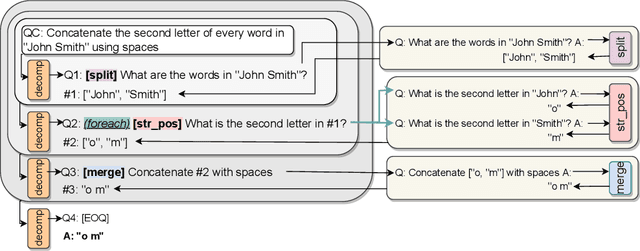

Few-shot prompting is a surprisingly powerful way to use Large Language Models (LLMs) to solve various tasks. However, this approach struggles as the task complexity increases or when the individual reasoning steps of the task themselves are hard to learn, especially when embedded in more complex tasks. To address this, we propose Decomposed Prompting, a new approach to solve complex tasks by decomposing them (via prompting) into simpler sub-tasks that can be delegated to a library of prompting-based LLMs dedicated to these sub-tasks. This modular structure allows each prompt to be optimized for its specific sub-task, further decomposed if necessary, and even easily replaced with more effective prompts, trained models, or symbolic functions if desired. We show that the flexibility and modularity of Decomposed Prompting allows it to outperform prior work on few-shot prompting using GPT3. On symbolic reasoning tasks, we can further decompose sub-tasks that are hard for LLMs into even simpler solvable sub-tasks. When the complexity comes from the input length, we can recursively decompose the task into the same task but with smaller inputs. We also evaluate our approach on textual multi-step reasoning tasks: on long-context multi-hop QA task, we can more effectively teach the sub-tasks via our separate sub-tasks prompts; and on open-domain multi-hop QA, we can incorporate a symbolic information retrieval within our decomposition framework, leading to improved performance on both tasks.
Goal Recognition as a Deep Learning Task: the GRNet Approach
Oct 05, 2022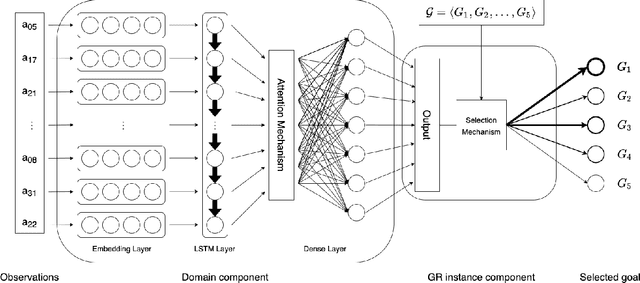
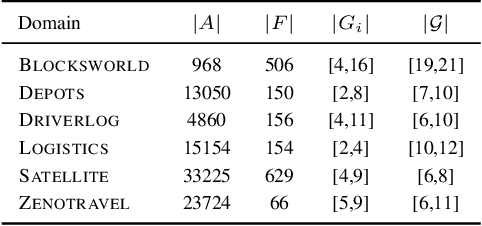
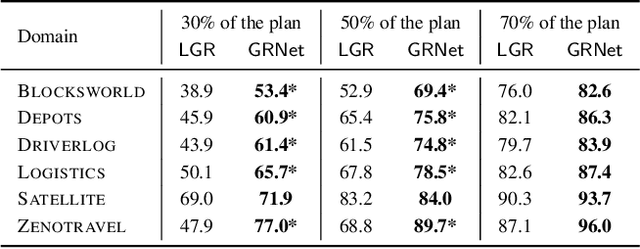
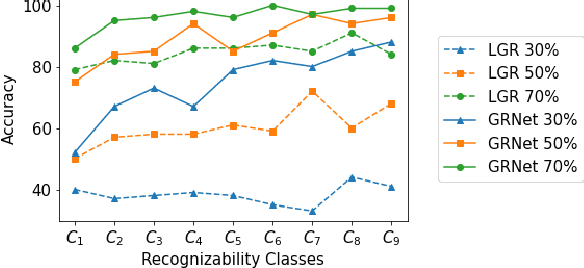
In automated planning, recognising the goal of an agent from a trace of observations is an important task with many applications. The state-of-the-art approaches to goal recognition rely on the application of planning techniques, which requires a model of the domain actions and of the initial domain state (written, e.g., in PDDL). We study an alternative approach where goal recognition is formulated as a classification task addressed by machine learning. Our approach, called GRNet, is primarily aimed at making goal recognition more accurate as well as faster by learning how to solve it in a given domain. Given a planning domain specified by a set of propositions and a set of action names, the goal classification instances in the domain are solved by a Recurrent Neural Network (RNN). A run of the RNN processes a trace of observed actions to compute how likely it is that each domain proposition is part of the agent's goal, for the problem instance under considerations. These predictions are then aggregated to choose one of the candidate goals. The only information required as input of the trained RNN is a trace of action labels, each one indicating just the name of an observed action. An experimental analysis confirms that \our achieves good performance in terms of both goal classification accuracy and runtime, obtaining better performance w.r.t. a state-of-the-art goal recognition system over the considered benchmarks.
Facial Information Analysis Technology for Gender and Age Estimation
Nov 17, 2021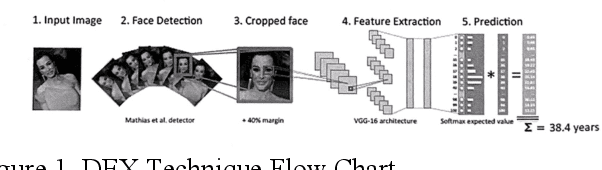
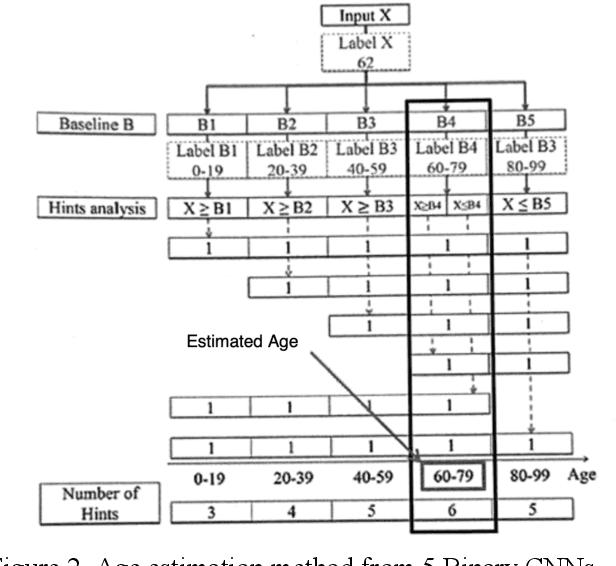
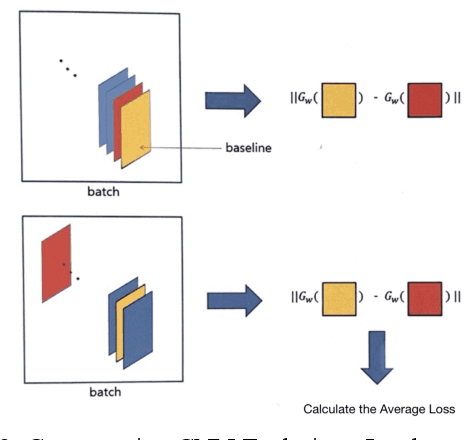
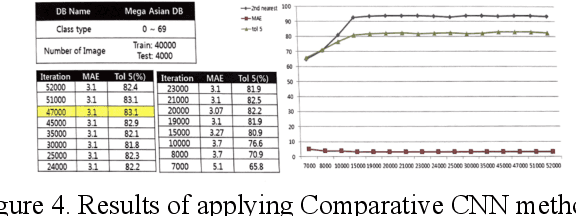
This is a study on facial information analysis technology for estimating gender and age, and poses are estimated using a transformation relationship matrix between the camera coordinate system and the world coordinate system for estimating the pose of a face image. Gender classification was relatively simple compared to age estimation, and age estimation was made possible using deep learning-based facial recognition technology. A comparative CNN was proposed to calculate the experimental results using the purchased database and the public database, and deep learning-based gender classification and age estimation performed at a significant level and was more robust to environmental changes compared to the existing machine learning techniques.
Predicting probability distributions for cancer therapy drug selection optimization
Sep 13, 2022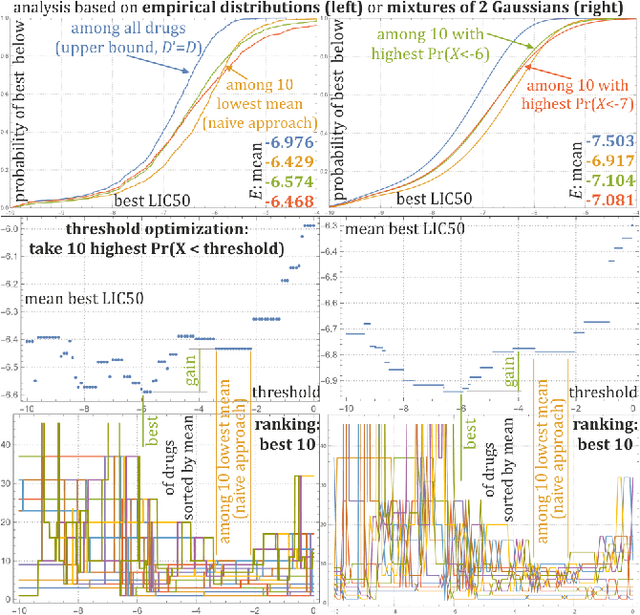
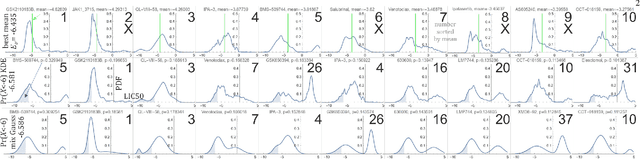
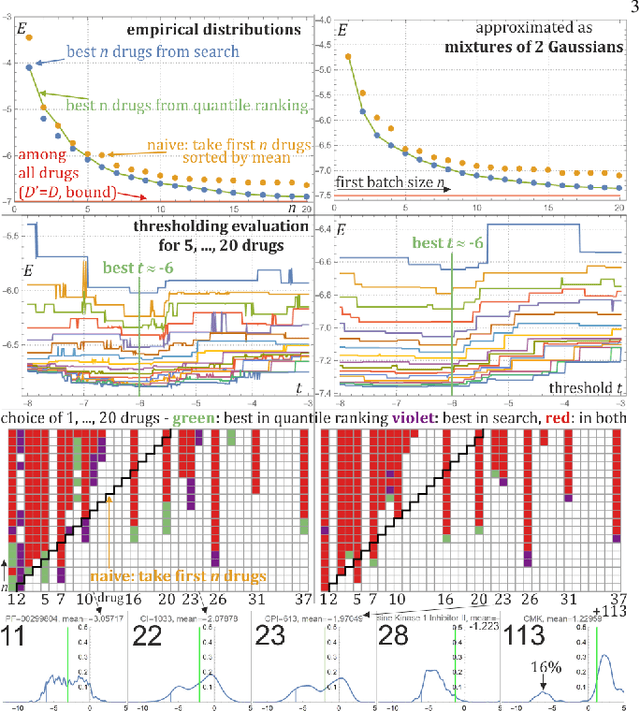
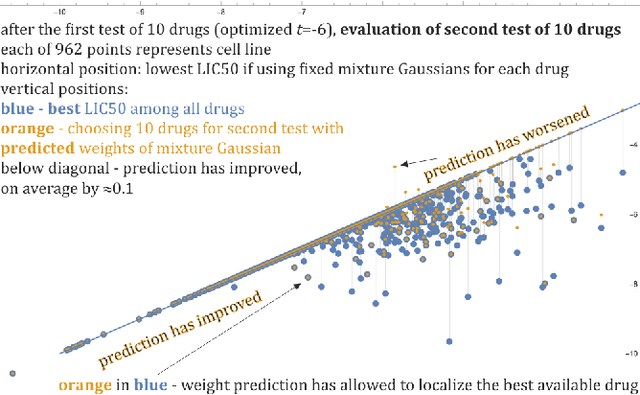
Large variability between cell lines brings a difficult optimization problem of drug selection for cancer therapy. Standard approaches use prediction of value for this purpose, corresponding e.g. to expected value of their distribution. This article shows superiority of working on, predicting the entire probability distributions - proposing basic tools for this purpose. We are mostly interested in the best drug in their batch to be tested - proper optimization of their selection for extreme statistics requires knowledge of the entire probability distributions, which for distributions of drug properties among cell lines often turn out binomial, e.g. depending on corresponding gene. Hence for basic prediction mechanism there is proposed mixture of two Gaussians, trying to predict its weight based on additional information.
Anatomy-Aware Contrastive Representation Learning for Fetal Ultrasound
Aug 22, 2022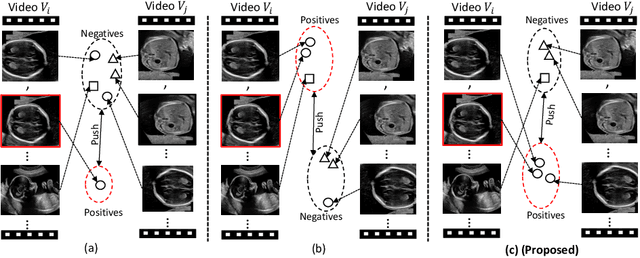

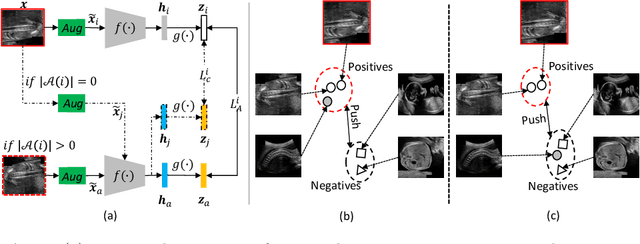
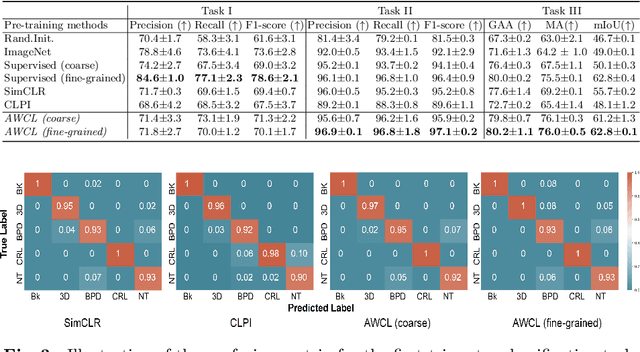
Self-supervised contrastive representation learning offers the advantage of learning meaningful visual representations from unlabeled medical datasets for transfer learning. However, applying current contrastive learning approaches to medical data without considering its domain-specific anatomical characteristics may lead to visual representations that are inconsistent in appearance and semantics. In this paper, we propose to improve visual representations of medical images via anatomy-aware contrastive learning (AWCL), which incorporates anatomy information to augment the positive/negative pair sampling in a contrastive learning manner. The proposed approach is demonstrated for automated fetal ultrasound imaging tasks, enabling the positive pairs from the same or different ultrasound scans that are anatomically similar to be pulled together and thus improving the representation learning. We empirically investigate the effect of inclusion of anatomy information with coarse- and fine-grained granularity, for contrastive learning and find that learning with fine-grained anatomy information which preserves intra-class difference is more effective than its counterpart. We also analyze the impact of anatomy ratio on our AWCL framework and find that using more distinct but anatomically similar samples to compose positive pairs results in better quality representations. Experiments on a large-scale fetal ultrasound dataset demonstrate that our approach is effective for learning representations that transfer well to three clinical downstream tasks, and achieves superior performance compared to ImageNet supervised and the current state-of-the-art contrastive learning methods. In particular, AWCL outperforms ImageNet supervised method by 13.8% and state-of-the-art contrastive-based method by 7.1% on a cross-domain segmentation task.
PIMIP: An Open Source Platform for Pathology Information Management and Integration
Nov 09, 2021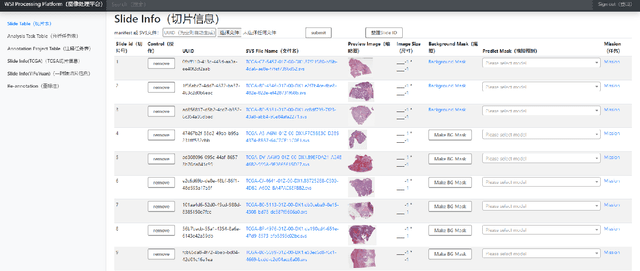
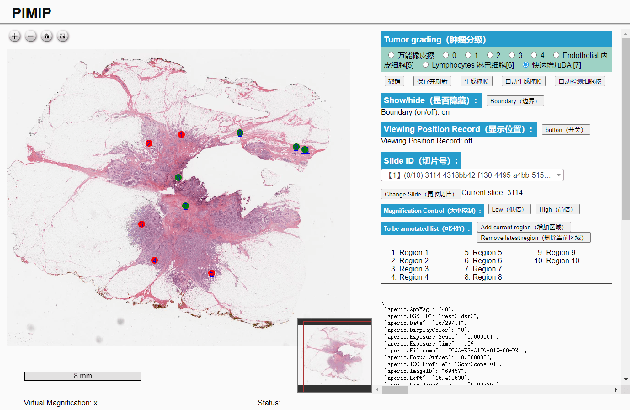
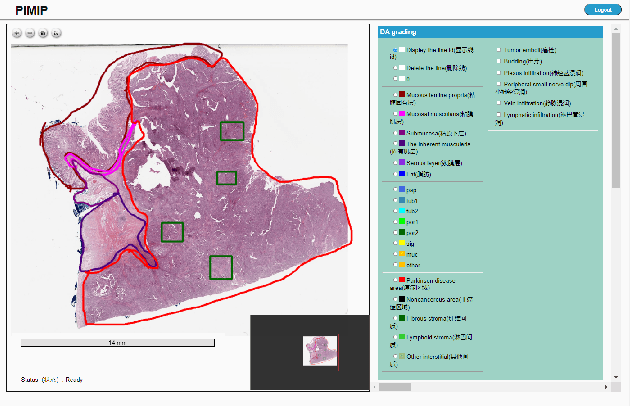
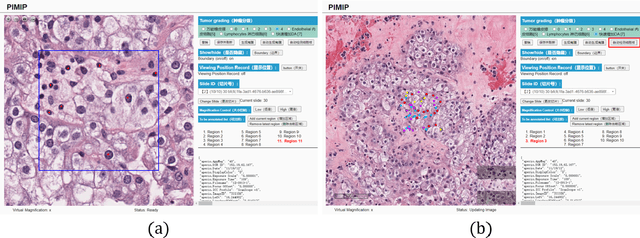
Digital pathology plays a crucial role in the development of artificial intelligence in the medical field. The digital pathology platform can make the pathological resources digital and networked, and realize the permanent storage of visual data and the synchronous browsing processing without the limitation of time and space. It has been widely used in various fields of pathology. However, there is still a lack of an open and universal digital pathology platform to assist doctors in the management and analysis of digital pathological sections, as well as the management and structured description of relevant patient information. Most platforms cannot integrate image viewing, annotation and analysis, and text information management. To solve the above problems, we propose a comprehensive and extensible platform PIMIP. Our PIMIP has developed the image annotation functions based on the visualization of digital pathological sections. Our annotation functions support multi-user collaborative annotation and multi-device annotation, and realize the automation of some annotation tasks. In the annotation task, we invited a professional pathologist for guidance. We introduce a machine learning module for image analysis. The data we collected included public data from local hospitals and clinical examples. Our platform is more clinical and suitable for clinical use. In addition to image data, we also structured the management and display of text information. So our platform is comprehensive. The platform framework is built in a modular way to support users to add machine learning modules independently, which makes our platform extensible.