 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Gradient-based Mixup towards Flatter Minima for Domain Generalization
Sep 29, 2022
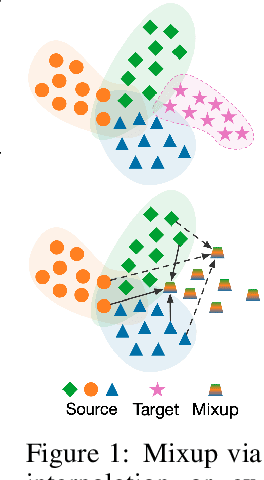
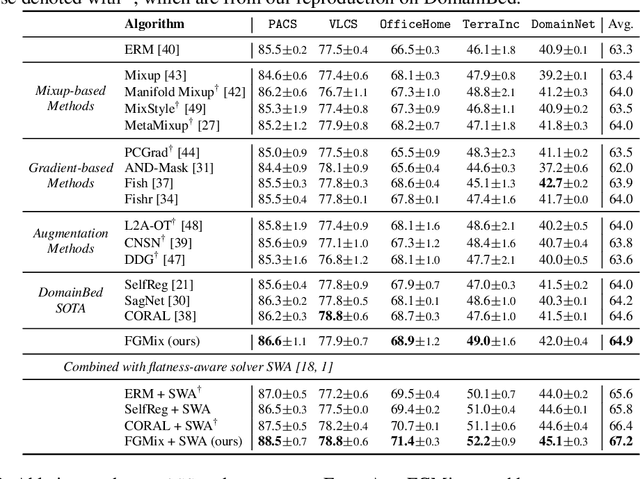
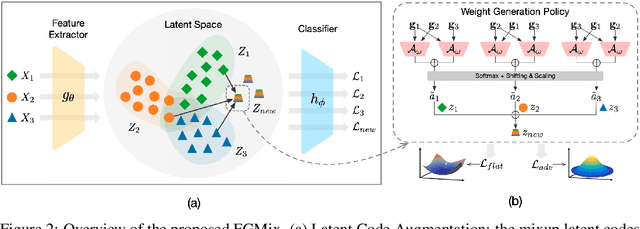
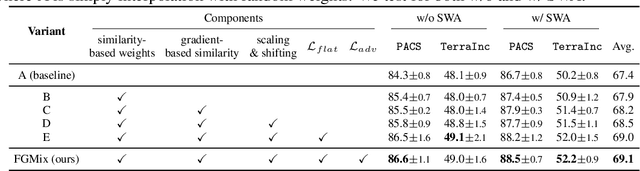
To address the distribution shifts between training and test data, domain generalization (DG) leverages multiple source domains to learn a model that generalizes well to unseen domains. However, existing DG methods generally suffer from overfitting to the source domains, partly due to the limited coverage of the expected region in feature space. Motivated by this, we propose to perform mixup with data interpolation and extrapolation to cover the potential unseen regions. To prevent the detrimental effects of unconstrained extrapolation, we carefully design a policy to generate the instance weights, named Flatness-aware Gradient-based Mixup (FGMix). The policy employs a gradient-based similarity to assign greater weights to instances that carry more invariant information, and learns the similarity function towards flatter minima for better generalization. On the DomainBed benchmark, we validate the efficacy of various designs of FGMix and demonstrate its superiority over other DG algorithms.
ADTR: Anomaly Detection Transformer with Feature Reconstruction
Sep 05, 2022
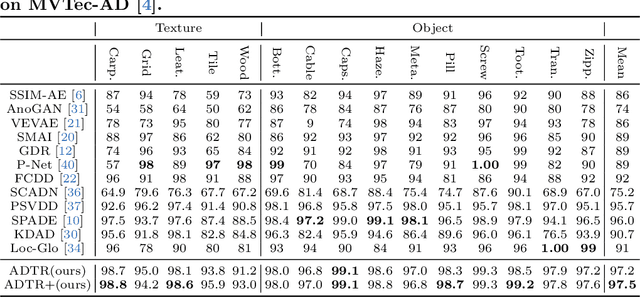
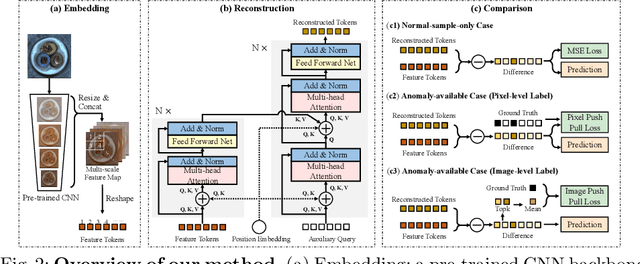
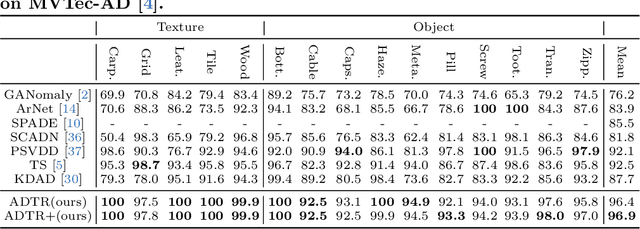
Anomaly detection with only prior knowledge from normal samples attracts more attention because of the lack of anomaly samples. Existing CNN-based pixel reconstruction approaches suffer from two concerns. First, the reconstruction source and target are raw pixel values that contain indistinguishable semantic information. Second, CNN tends to reconstruct both normal samples and anomalies well, making them still hard to distinguish. In this paper, we propose Anomaly Detection TRansformer (ADTR) to apply a transformer to reconstruct pre-trained features. The pre-trained features contain distinguishable semantic information. Also, the adoption of transformer limits to reconstruct anomalies well such that anomalies could be detected easily once the reconstruction fails. Moreover, we propose novel loss functions to make our approach compatible with the normal-sample-only case and the anomaly-available case with both image-level and pixel-level labeled anomalies. The performance could be further improved by adding simple synthetic or external irrelevant anomalies. Extensive experiments are conducted on anomaly detection datasets including MVTec-AD and CIFAR-10. Our method achieves superior performance compared with all baselines.
A Reference Model for Common Understanding of Capabilities and Skills in Manufacturing
Sep 15, 2022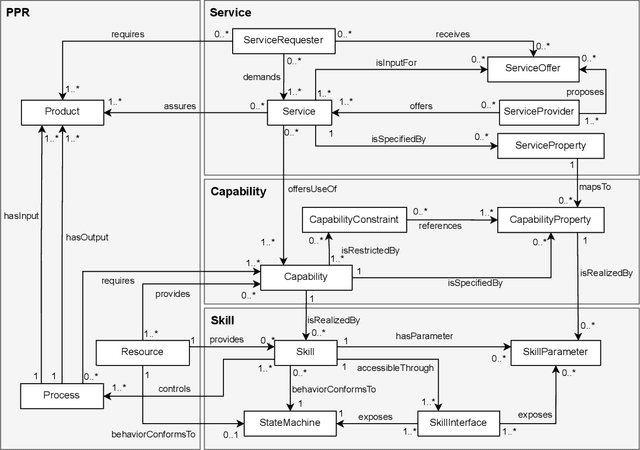
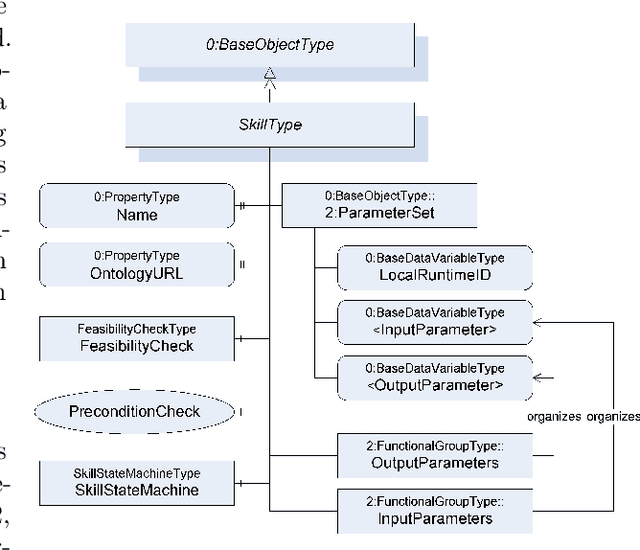
In manufacturing, many use cases of Industry 4.0 require vendor-neutral and machine-readable information models to describe, implement and execute resource functions. Such models have been researched under the terms capabilities and skills. Standardization of such models is required, but currently not available. This paper presents a reference model developed jointly by members of various organizations in a working group of the Plattform Industrie 4.0. This model covers definitions of most important aspects of capabilities and skills. It can be seen as a basis for further standardization efforts.
Improved Stein Variational Gradient Descent with Importance Weights
Oct 04, 2022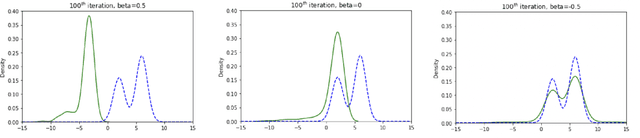
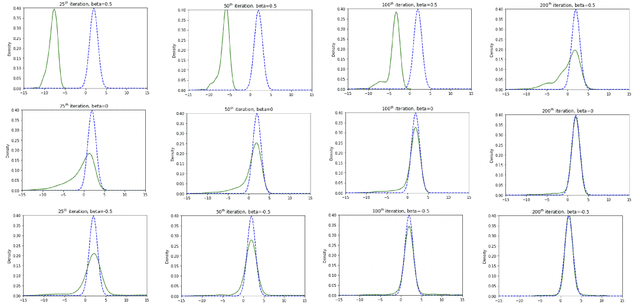
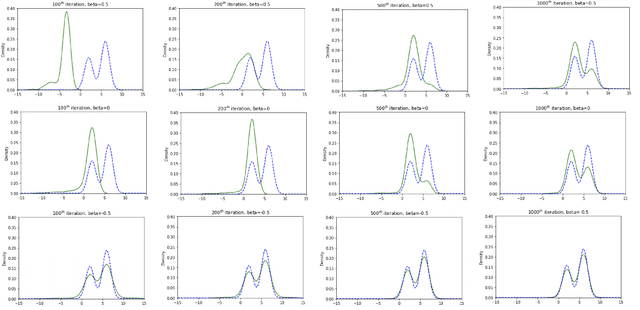
Stein Variational Gradient Descent (SVGD) is a popular sampling algorithm used in various machine learning tasks. It is well known that SVGD arises from a discretization of the kernelized gradient flow of the Kullback-Leibler divergence $D_{KL}\left(\cdot\mid\pi\right)$, where $\pi$ is the target distribution. In this work, we propose to enhance SVGD via the introduction of importance weights, which leads to a new method for which we coin the name $\beta$-SVGD. In the continuous time and infinite particles regime, the time for this flow to converge to the equilibrium distribution $\pi$, quantified by the Stein Fisher information, depends on $\rho_0$ and $\pi$ very weakly. This is very different from the kernelized gradient flow of Kullback-Leibler divergence, whose time complexity depends on $D_{KL}\left(\rho_0\mid\pi\right)$. Under certain assumptions, we provide a descent lemma for the population limit $\beta$-SVGD, which covers the descent lemma for the population limit SVGD when $\beta\to 0$. We also illustrate the advantages of $\beta$-SVGD over SVGD by simple experiments.
Learning Perception-Aware Agile Flight in Cluttered Environments
Oct 04, 2022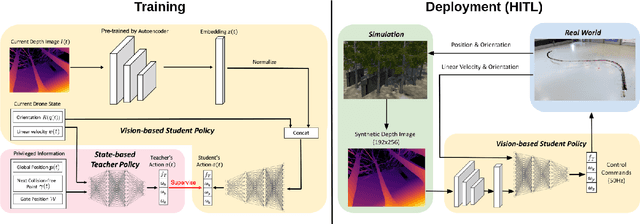

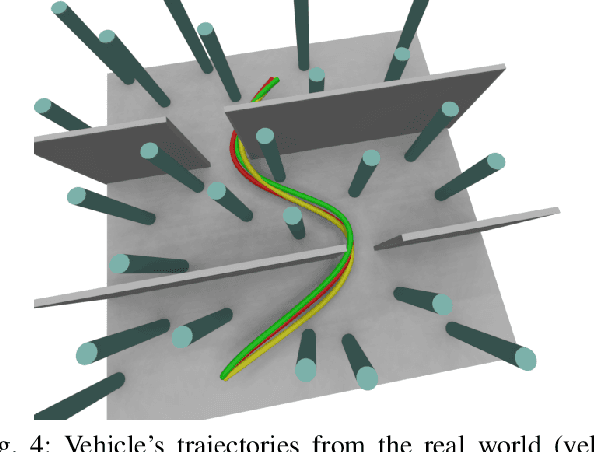
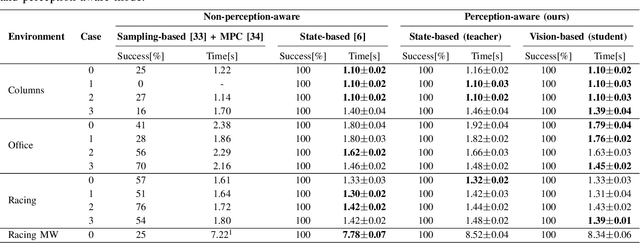
Recently, neural control policies have outperformed existing model-based planning-and-control methods for autonomously navigating quadrotors through cluttered environments in minimum time. However, they are not perception aware, a crucial requirement in vision-based navigation due to the camera's limited field of view and the underactuated nature of a quadrotor. We propose a method to learn neural network policies that achieve perception-aware, minimum-time flight in cluttered environments. Our method combines imitation learning and reinforcement learning (RL) by leveraging a privileged learning-by-cheating framework. Using RL, we first train a perception-aware teacher policy with full-state information to fly in minimum time through cluttered environments. Then, we use imitation learning to distill its knowledge into a vision-based student policy that only perceives the environment via a camera. Our approach tightly couples perception and control, showing a significant advantage in computation speed (10x faster) and success rate. We demonstrate the closed-loop control performance using a physical quadrotor and hardware-in-the-loop simulation at speeds up to 50km/h.
CLINICAL: Targeted Active Learning for Imbalanced Medical Image Classification
Oct 04, 2022Training deep learning models on medical datasets that perform well for all classes is a challenging task. It is often the case that a suboptimal performance is obtained on some classes due to the natural class imbalance issue that comes with medical data. An effective way to tackle this problem is by using targeted active learning, where we iteratively add data points to the training data that belong to the rare classes. However, existing active learning methods are ineffective in targeting rare classes in medical datasets. In this work, we propose Clinical (targeted aCtive Learning for ImbalaNced medICal imAge cLassification) a framework that uses submodular mutual information functions as acquisition functions to mine critical data points from rare classes. We apply our framework to a wide-array of medical imaging datasets on a variety of real-world class imbalance scenarios - namely, binary imbalance and long-tail imbalance. We show that Clinical outperforms the state-of-the-art active learning methods by acquiring a diverse set of data points that belong to the rare classes.
MTSMAE: Masked Autoencoders for Multivariate Time-Series Forecasting
Oct 04, 2022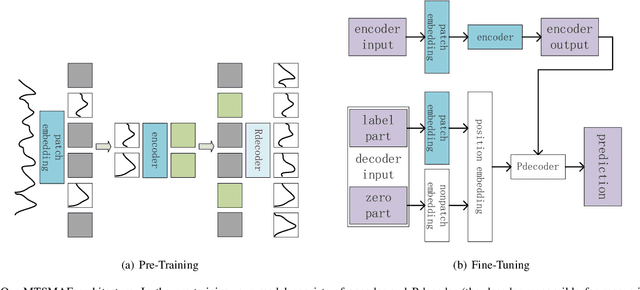
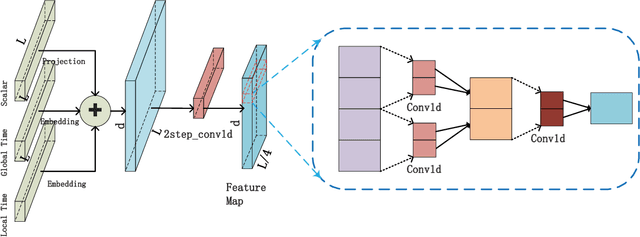
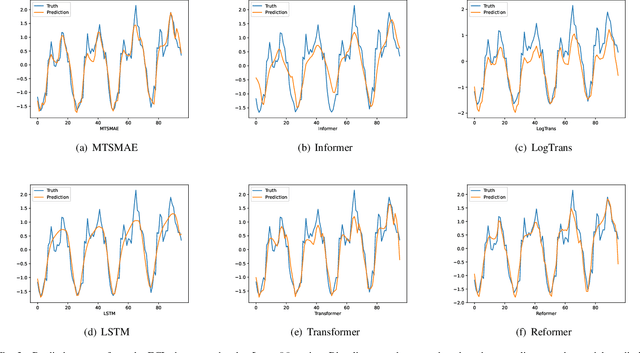
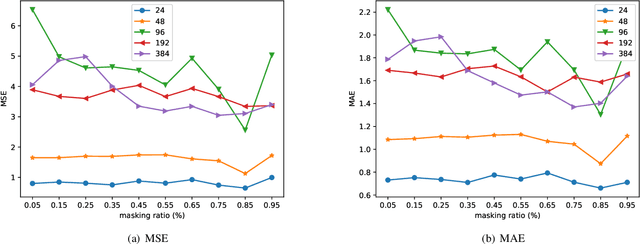
Large-scale self-supervised pre-training Transformer architecture have significantly boosted the performance for various tasks in natural language processing (NLP) and computer vision (CV). However, there is a lack of researches on processing multivariate time-series by pre-trained Transformer, and especially, current study on masking time-series for self-supervised learning is still a gap. Different from language and image processing, the information density of time-series increases the difficulty of research. The challenge goes further with the invalidity of the previous patch embedding and mask methods. In this paper, according to the data characteristics of multivariate time-series, a patch embedding method is proposed, and we present an self-supervised pre-training approach based on Masked Autoencoders (MAE), called MTSMAE, which can improve the performance significantly over supervised learning without pre-training. Evaluating our method on several common multivariate time-series datasets from different fields and with different characteristics, experiment results demonstrate that the performance of our method is significantly better than the best method currently available.
Cut-Paste Consistency Learning for Semi-Supervised Lesion Segmentation
Oct 01, 2022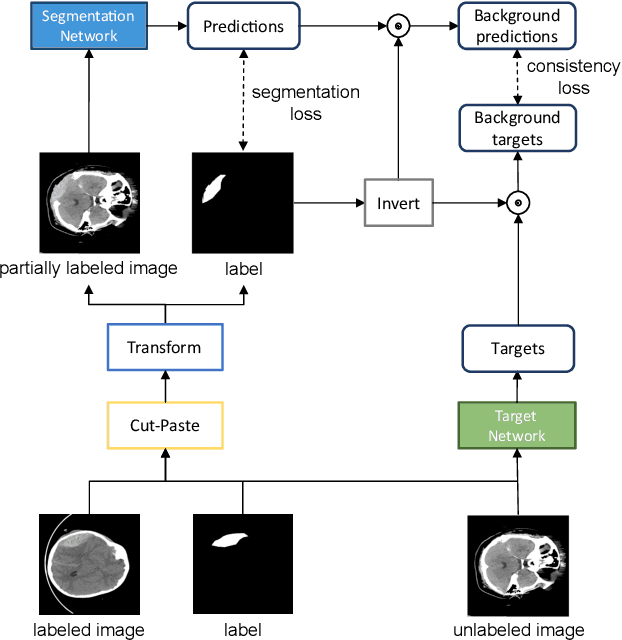
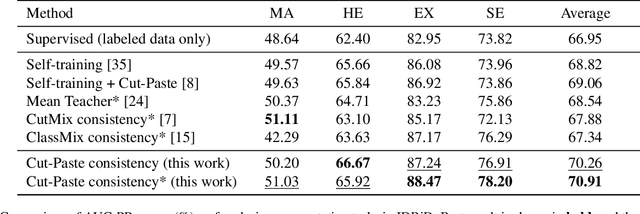
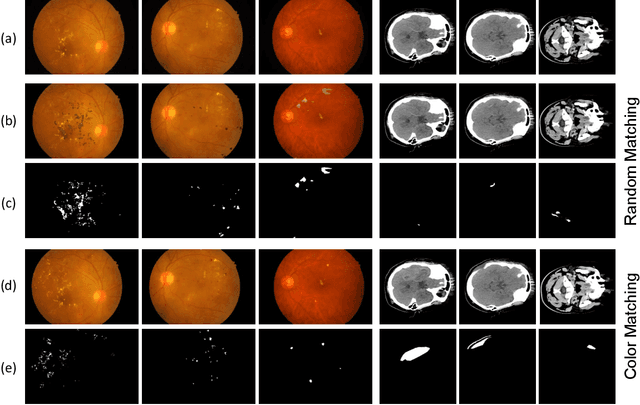
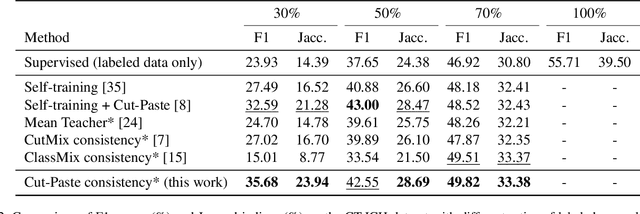
Semi-supervised learning has the potential to improve the data-efficiency of training data-hungry deep neural networks, which is especially important for medical image analysis tasks where labeled data is scarce. In this work, we present a simple semi-supervised learning method for lesion segmentation tasks based on the ideas of cut-paste augmentation and consistency regularization. By exploiting the mask information available in the labeled data, we synthesize partially labeled samples from the unlabeled images so that the usual supervised learning objective (e.g., binary cross entropy) can be applied. Additionally, we introduce a background consistency term to regularize the training on the unlabeled background regions of the synthetic images. We empirically verify the effectiveness of the proposed method on two public lesion segmentation datasets, including an eye fundus photograph dataset and a brain CT scan dataset. The experiment results indicate that our method achieves consistent and superior performance over other self-training and consistency-based methods without introducing sophisticated network components.
Physical computation and compositionality
Oct 01, 2022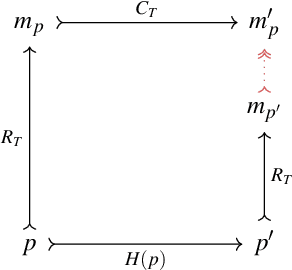
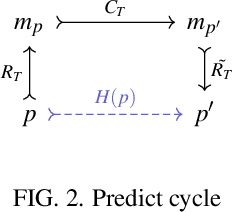
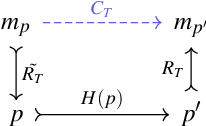
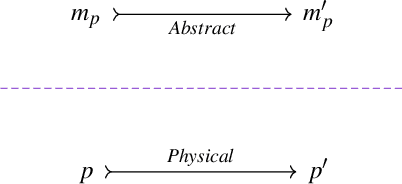
Developments in quantum computing and, more in general, non-standard computing systems, represent a clear indication that the very notion of what a physical computing device is and does should be recast in a rigorous and sound framework. Physical computing has opened a whole stream of new research aimed to understand and control how information is processed by several types of physical devices. Therefore, classical definitions and entire frameworks need to be adapted in order to fit a broader notion of what physical computing systems really are. Recent studies have proposed a formalism that can be used to carve out a more proper notion of physical computing. In this paper we present a framework which capture such results in a very natural way via some basic constructions in Category Theory. Furthermore, we show that, within our framework, the compositional nature of physical computing systems is naturally formalized, and that it can be organized in coherent structures by the means of their relational nature.
Gaussian Process Hydrodynamics
Sep 21, 2022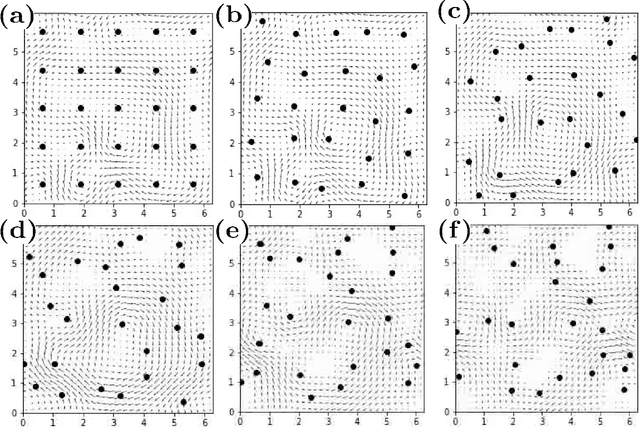
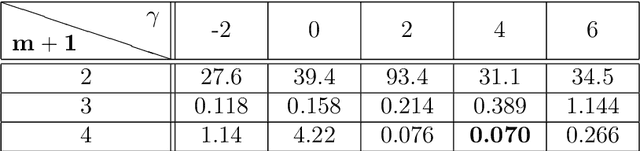
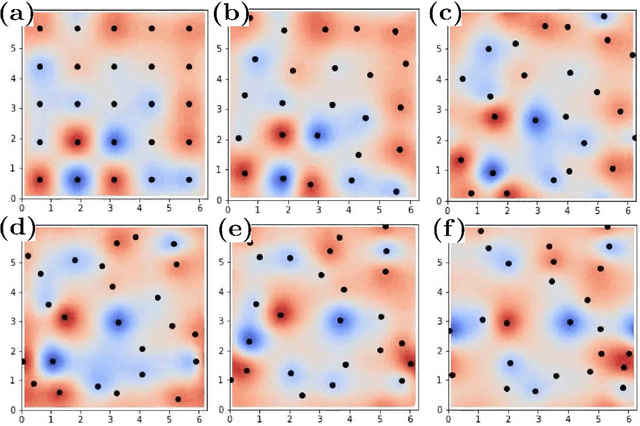
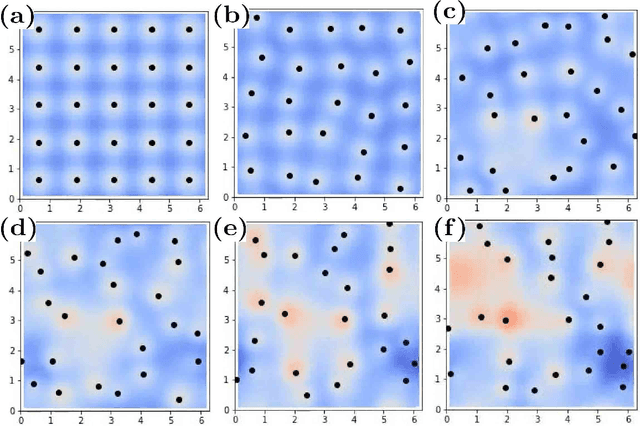
We present a Gaussian Process (GP) approach (Gaussian Process Hydrodynamics, GPH) for solving the Euler and Navier-Stokes equations. As in Smoothed Particle Hydrodynamics (SPH), GPH is a Lagrangian particle-based approach involving the tracking of a finite number of particles transported by the flow. However, these particles do not represent mollified particles of matter but carry discrete/partial information about the continuous flow. Closure is achieved by placing a divergence-free GP prior $\xi$ on the velocity field and conditioning on vorticity at particle locations. Known physics (e.g., the Richardson cascade and velocity-increments power laws) is incorporated into the GP prior through physics-informed additive kernels. This is equivalent to expressing $\xi$ as a sum of independent GPs $\xi^l$, which we call modes, acting at different scales. This approach leads to a quantitative analysis of the Richardson cascade through the analysis of the activation of these modes and allows us to coarse-grain turbulence in a statistical manner rather than a deterministic one. Since GPH is formulated on the vorticity equations, it does not require solving a pressure equation. By enforcing incompressibility and fluid/structure boundary conditions through the selection of the kernel, GPH requires much fewer particles than SPH. Since GPH has a natural probabilistic interpretation, numerical results come with uncertainty estimates enabling their incorporation into a UQ pipeline and the adding/removing of particles in an adapted manner. The proposed approach is amenable to analysis, it inherits the complexity of state-of-the-art solvers for dense kernel matrices, and it leads to a natural definition of turbulence as information loss. Numerical experiments support the importance of selecting physics-informed kernels and illustrate the major impact of such kernels on accuracy and stability.