 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Automatic Tooth Segmentation from 3D Dental Model using Deep Learning: A Quantitative Analysis of what can be learnt from a Single 3D Dental Model
Sep 16, 2022
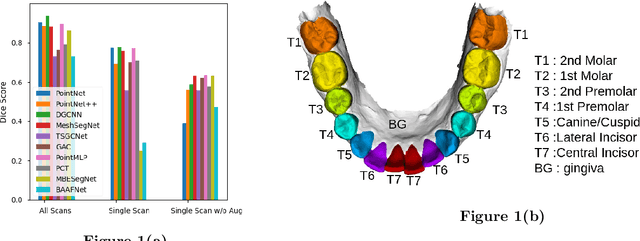

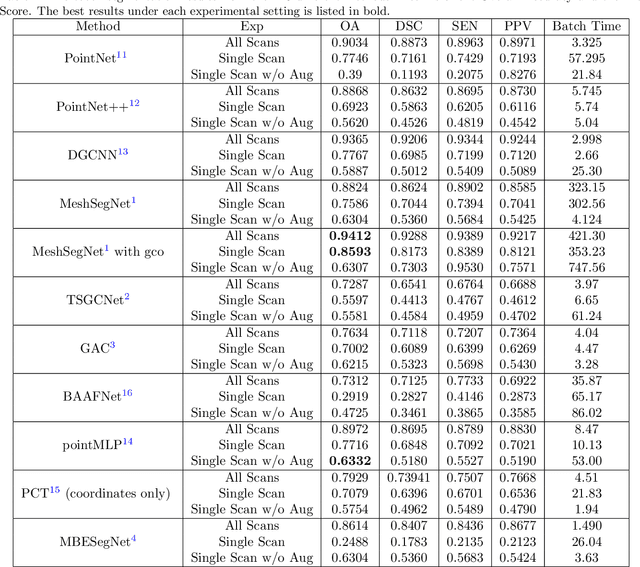
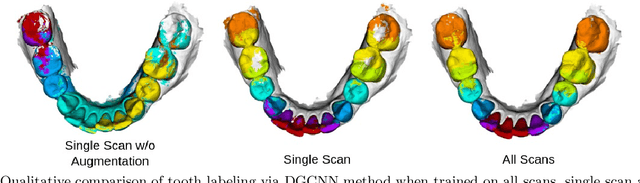
3D tooth segmentation is an important task for digital orthodontics. Several Deep Learning methods have been proposed for automatic tooth segmentation from 3D dental models or intraoral scans. These methods require annotated 3D intraoral scans. Manually annotating 3D intraoral scans is a laborious task. One approach is to devise self-supervision methods to reduce the manual labeling effort. Compared to other types of point cloud data like scene point cloud or shape point cloud data, 3D tooth point cloud data has a very regular structure and a strong shape prior. We look at how much representative information can be learnt from a single 3D intraoral scan. We evaluate this quantitatively with the help of ten different methods of which six are generic point cloud segmentation methods whereas the other four are tooth segmentation specific methods. Surprisingly, we find that with a single 3D intraoral scan training, the Dice score can be as high as 0.86 whereas the full training set gives Dice score of 0.94. We conclude that the segmentation methods can learn a great deal of information from a single 3D tooth point cloud scan under suitable conditions e.g. data augmentation. We are the first to quantitatively evaluate and demonstrate the representation learning capability of Deep Learning methods from a single 3D intraoral scan. This can enable building self-supervision methods for tooth segmentation under extreme data limitation scenario by leveraging the available data to the fullest possible extent.
Compressed Particle-Based Federated Bayesian Learning and Unlearning
Sep 19, 2022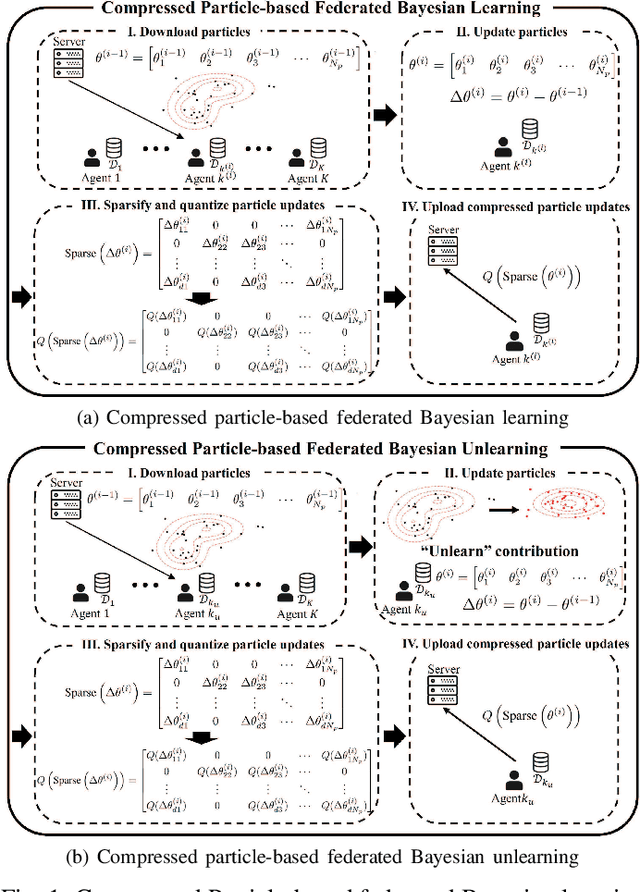
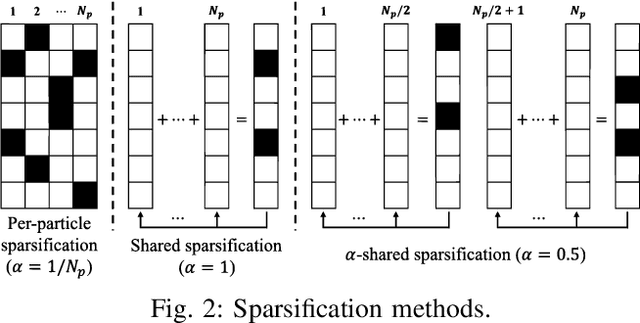
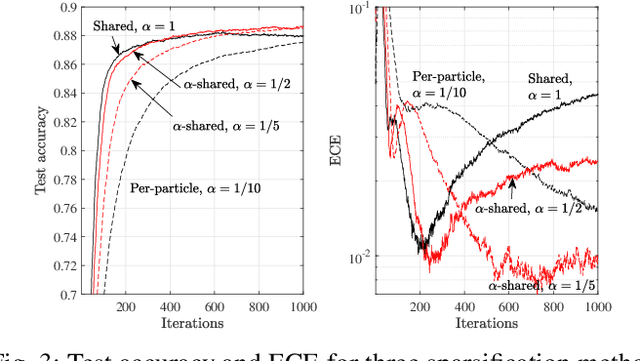
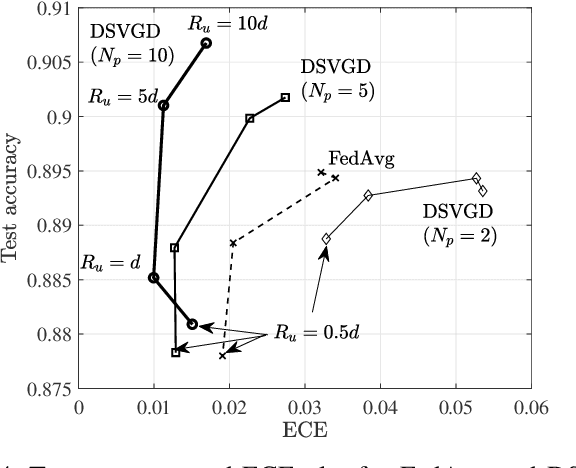
Conventional frequentist FL schemes are known to yield overconfident decisions. Bayesian FL addresses this issue by allowing agents to process and exchange uncertainty information encoded in distributions over the model parameters. However, this comes at the cost of a larger per-iteration communication overhead. This letter investigates whether Bayesian FL can still provide advantages in terms of calibration when constraining communication bandwidth. We present compressed particle-based Bayesian FL protocols for FL and federated "unlearning" that apply quantization and sparsification across multiple particles. The experimental results confirm that the benefits of Bayesian FL are robust to bandwidth constraints.
Less is More: Task-aware Layer-wise Distillation for Language Model Compression
Oct 05, 2022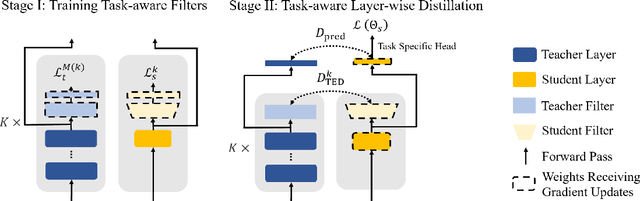
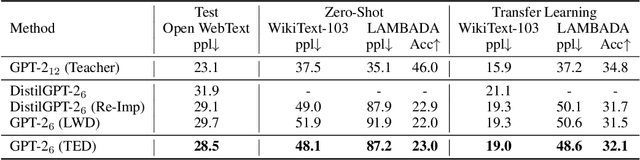
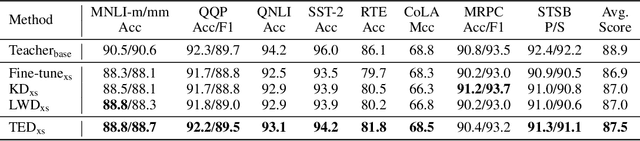
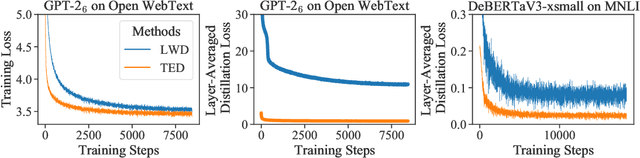
Layer-wise distillation is a powerful tool to compress large models (i.e. teacher models) into small ones (i.e., student models). The student distills knowledge from the teacher by mimicking the hidden representations of the teacher at every intermediate layer. However, layer-wise distillation is difficult. Since the student has a smaller model capacity than the teacher, it is often under-fitted. Furthermore, the hidden representations of the teacher contain redundant information that the student does not necessarily need for the target task's learning. To address these challenges, we propose a novel Task-aware layEr-wise Distillation (TED). TED designs task-aware filters to align the hidden representations of the student and the teacher at each layer. The filters select the knowledge that is useful for the target task from the hidden representations. As such, TED reduces the knowledge gap between the two models and helps the student to fit better on the target task. We evaluate TED in two scenarios: continual pre-training and fine-tuning. TED demonstrates significant and consistent improvements over existing distillation methods in both scenarios.
Multi-class Classifier based Failure Prediction with Artificial and Anonymous Training for Data Privacy
Sep 06, 2022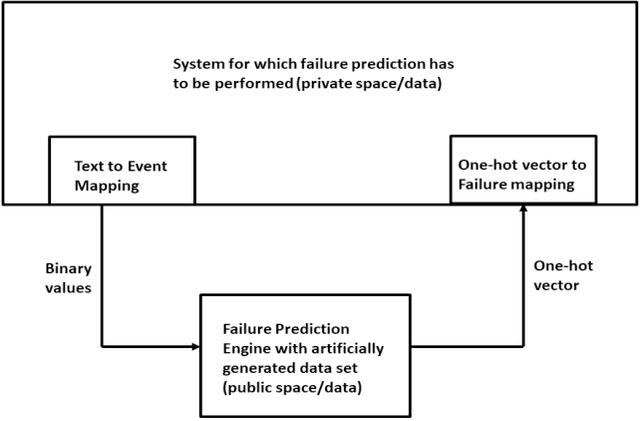
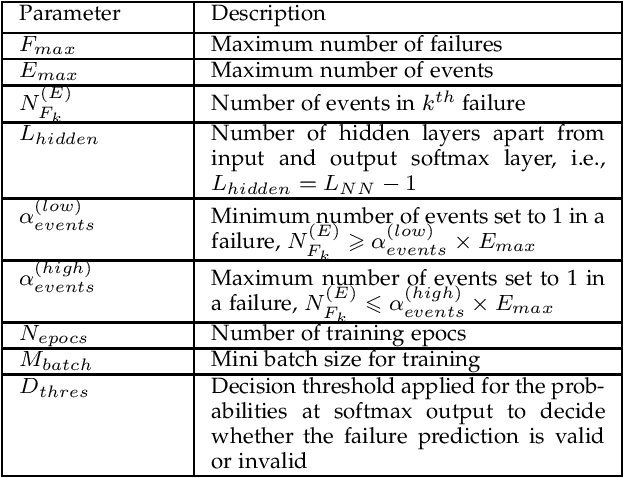
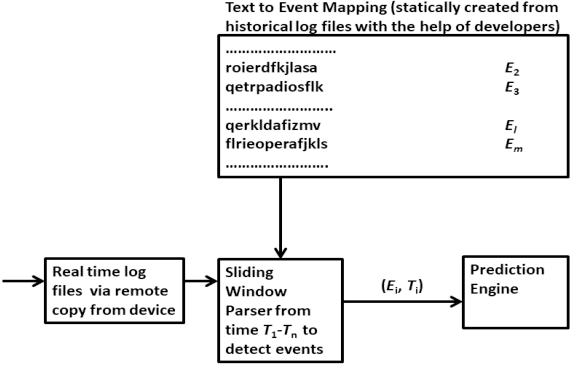
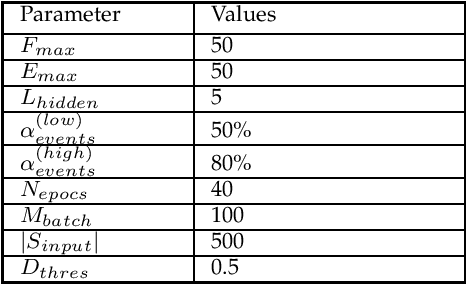
This paper proposes a novel non-intrusive system failure prediction technique using available information from developers and minimal information from raw logs (rather than mining entire logs) but keeping the data entirely private with the data owners. A neural network based multi-class classifier is developed for failure prediction, using artificially generated anonymous data set, applying a combination of techniques, viz., genetic algorithm (steps), pattern repetition, etc., to train and test the network. The proposed mechanism completely decouples the data set used for training process from the actual data which is kept private. Moreover, multi-criteria decision making (MCDM) schemes are used to prioritize failures meeting business requirements. Results show high accuracy in failure prediction under different parameter configurations. On a broader context, any classification problem, beyond failure prediction, can be performed using the proposed mechanism with artificially generated data set without looking into the actual data as long as the input features can be translated to binary values (e.g. output from private binary classifiers) and can provide classification-as-a-service.
Seventy Years of Radar and Communications: The Road from Separation to Integration
Oct 02, 2022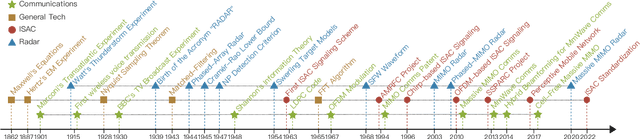
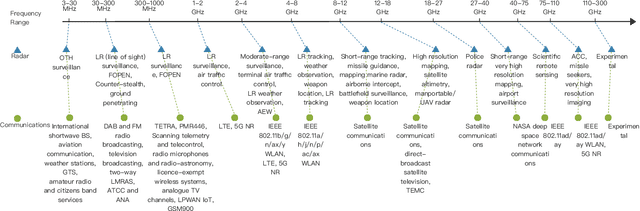
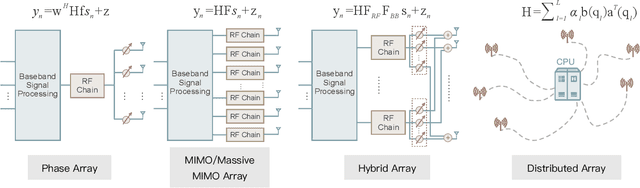
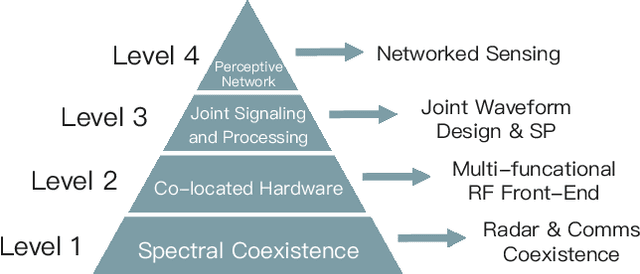
Radar and communications (R&C) as key utilities of electromagnetic (EM) waves have fundamentally shaped human society and triggered the modern information age. Although R&C have been historically progressing separately, in recent decades they have been moving from separation to integration, forming integrated sensing and communication (ISAC) systems, which find extensive applications in next-generation wireless networks and future radar systems. To better understand the essence of ISAC systems, this paper provides a systematic overview on the historical development of R&C from a signal processing (SP) perspective. We first interpret the duality between R&C as signals and systems, followed by an introduction of their fundamental principles. We then elaborate on the two main trends in their technological evolution, namely, the increase of frequencies and bandwidths, and the expansion of antenna arrays. Moreover, we show how the intertwined narratives of R\&C evolved into ISAC, and discuss the resultant SP framework. Finally, we overview future research directions in this field.
"Help Me Help the AI": Understanding How Explainability Can Support Human-AI Interaction
Oct 02, 2022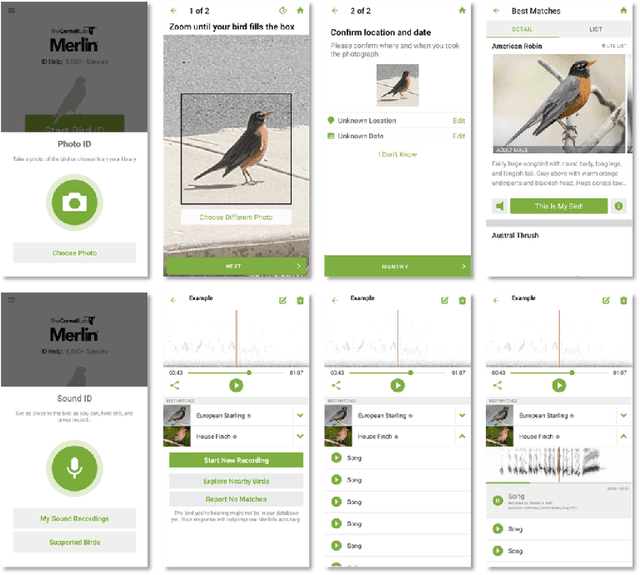
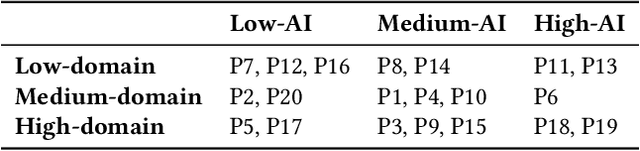

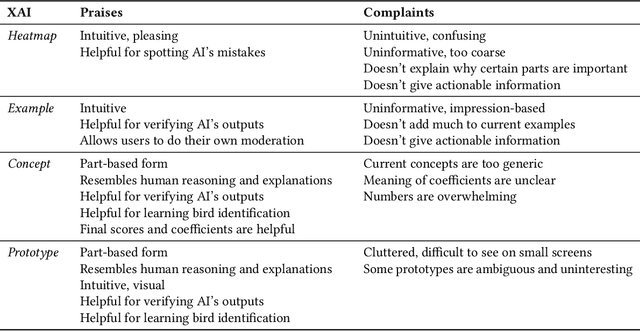
Despite the proliferation of explainable AI (XAI) methods, little is understood about end-users' explainability needs. This gap is critical, because end-users may have needs that XAI methods should but don't yet support. To address this gap and contribute to understanding how explainability can support human-AI interaction, we conducted a study of a real-world AI application via interviews with 20 end-users of Merlin, a bird-identification app. We found that people express a need for practically useful information that can improve their collaboration with the AI system, and intend to use XAI explanations for calibrating trust, improving their task skills, changing their behavior to supply better inputs to the AI system, and giving constructive feedback to developers. We also assessed end-users' perceptions of existing XAI approaches, finding that they prefer part-based explanations. Finally, we discuss implications of our findings and provide recommendations for future designs of XAI, specifically XAI for human-AI collaboration.
News Category Dataset
Sep 23, 2022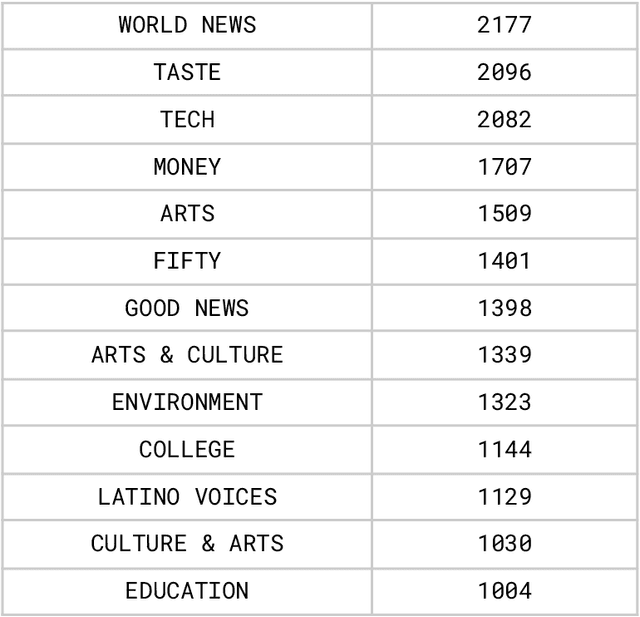
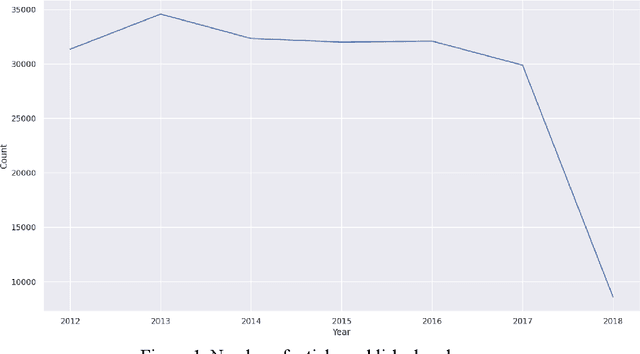
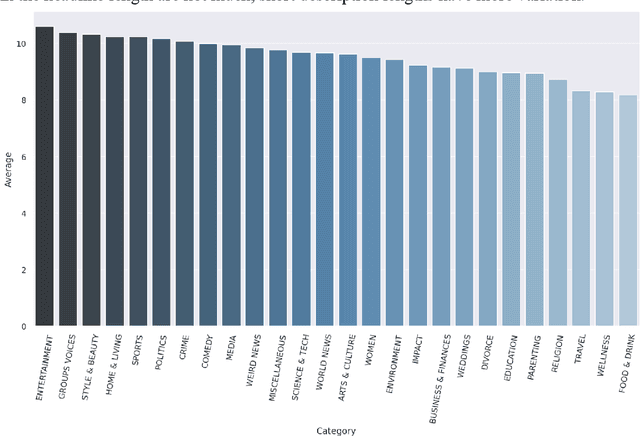
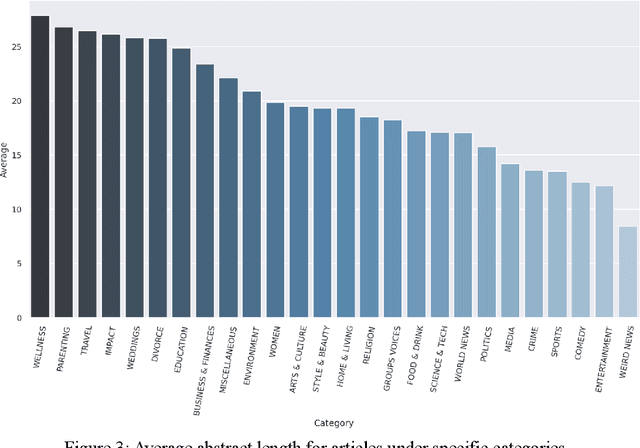
People rely on news to know what is happening around the world and inform their daily lives. In today's world, when the proliferation of fake news is rampant, having a large-scale and high-quality source of authentic news articles with the published category information is valuable to learning authentic news' Natural Language syntax and semantics. As part of this work, we present a News Category Dataset that contains around 200k news headlines from the year 2012 to 2018 obtained from HuffPost, along with useful metadata to enable various NLP tasks. In this paper, we also produce some novel insights from the dataset and describe various existing and potential applications of our dataset.
Rethinking Skip Connections in Encoder-decoder Networks for Monocular Depth Estimation
Aug 29, 2022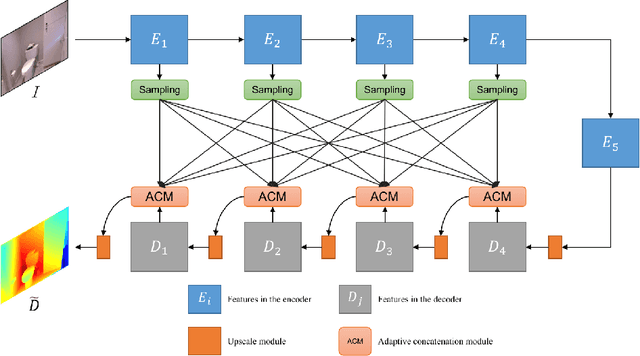
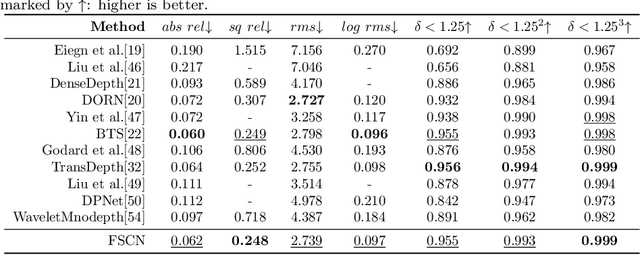
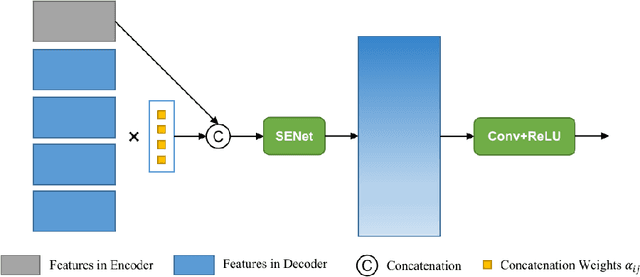
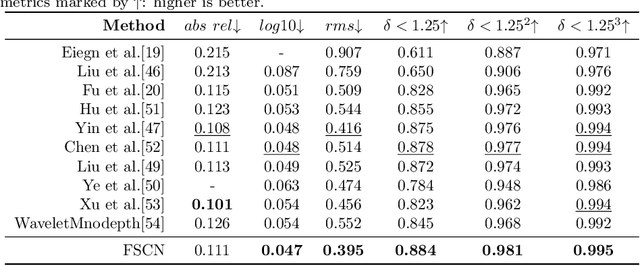
Skip connections are fundamental units in encoder-decoder networks, which are able to improve the feature propagtion of the neural networks. However, most methods with skip connections just connected features with the same resolution in the encoder and the decoder, which ignored the information loss in the encoder with the layers going deeper. To leverage the information loss of the features in shallower layers of the encoder, we propose a full skip connection network (FSCN) for monocular depth estimation task. In addition, to fuse features within skip connections more closely, we present an adaptive concatenation module (ACM). Further more, we conduct extensive experiments on the ourdoor and indoor datasets (i.e., the KITTI dataste and the NYU Depth V2 dataset) for FSCN and FSCN gets the state-of-the-art results.
AdaWAC: Adaptively Weighted Augmentation Consistency Regularization for Volumetric Medical Image Segmentation
Oct 04, 2022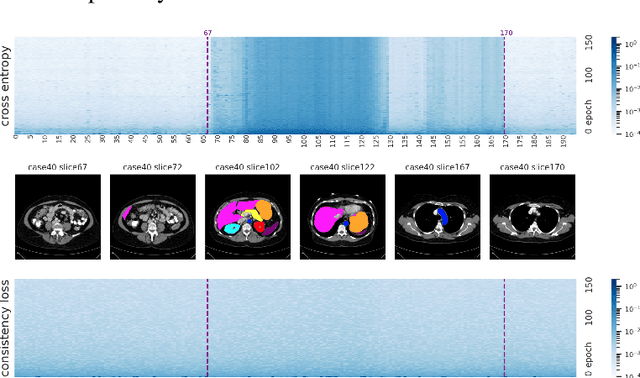
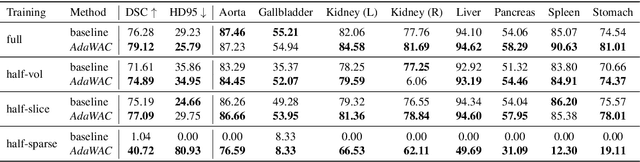
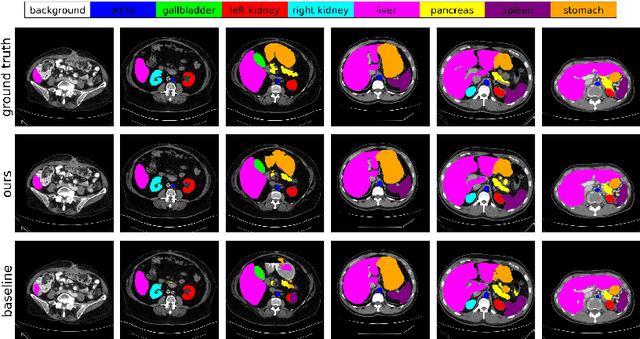
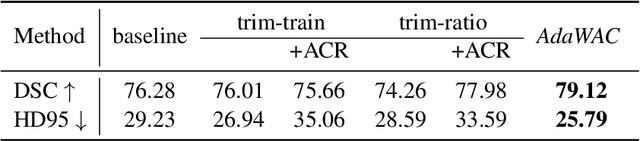
Sample reweighting is an effective strategy for learning from training data coming from a mixture of subpopulations. In volumetric medical image segmentation, the data inputs are similarly distributed, but the associated data labels fall into two subpopulations -- "label-sparse" and "label-dense" -- depending on whether the data image occurs near the beginning/end of the volumetric scan or the middle. Existing reweighting algorithms have focused on hard- and soft- thresholding of the label-sparse data, which results in loss of information and reduced sample efficiency by discarding valuable data input. For this setting, we propose AdaWAC as an adaptive weighting algorithm that introduces a set of trainable weights which, at the saddle point of the underlying objective, assigns label-dense samples to supervised cross-entropy loss and label-sparse samples to unsupervised consistency regularization. We provide a convergence guarantee for AdaWAC by recasting the optimization as online mirror descent on a saddle point problem. Moreover, we empirically demonstrate that AdaWAC not only enhances segmentation performance and sample efficiency but also improves robustness to the subpopulation shift in labels.
Pose-Guided Graph Convolutional Networks for Skeleton-Based Action Recognition
Oct 10, 2022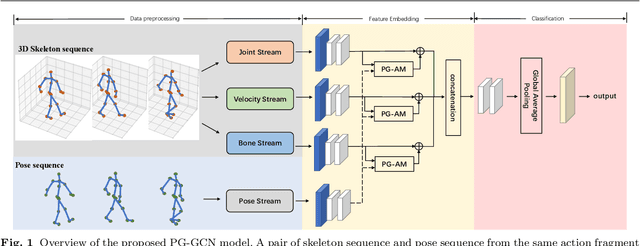
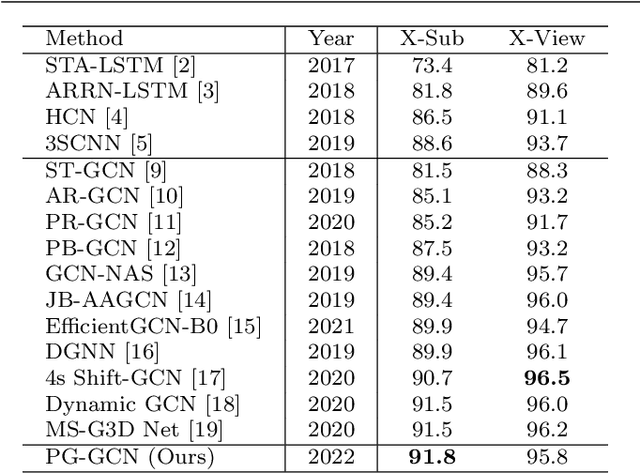
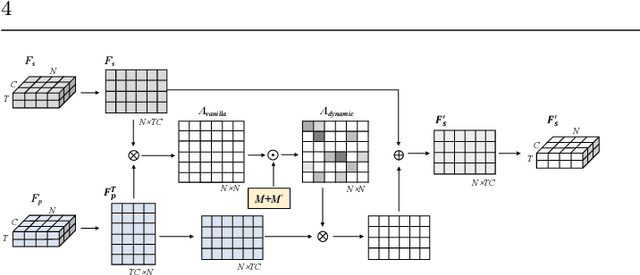
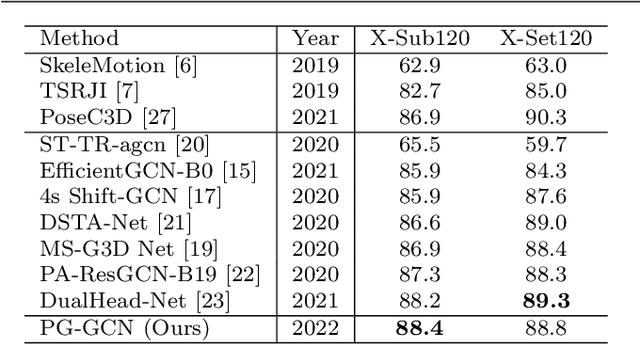
Graph convolutional networks (GCNs), which can model the human body skeletons as spatial and temporal graphs, have shown remarkable potential in skeleton-based action recognition. However, in the existing GCN-based methods, graph-structured representation of the human skeleton makes it difficult to be fused with other modalities, especially in the early stages. This may limit their scalability and performance in action recognition tasks. In addition, the pose information, which naturally contains informative and discriminative clues for action recognition, is rarely explored together with skeleton data in existing methods. In this work, we propose pose-guided GCN (PG-GCN), a multi-modal framework for high-performance human action recognition. In particular, a multi-stream network is constructed to simultaneously explore the robust features from both the pose and skeleton data, while a dynamic attention module is designed for early-stage feature fusion. The core idea of this module is to utilize a trainable graph to aggregate features from the skeleton stream with that of the pose stream, which leads to a network with more robust feature representation ability. Extensive experiments show that the proposed PG-GCN can achieve state-of-the-art performance on the NTU RGB+D 60 and NTU RGB+D 120 datasets.