 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hyperbolic Deep Reinforcement Learning
Oct 04, 2022
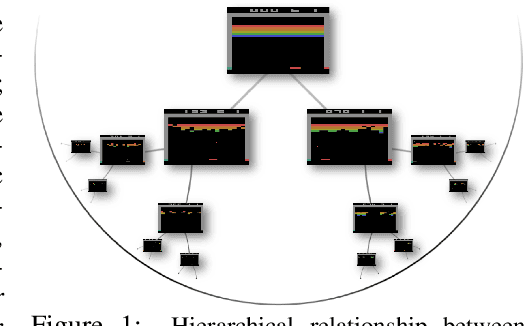
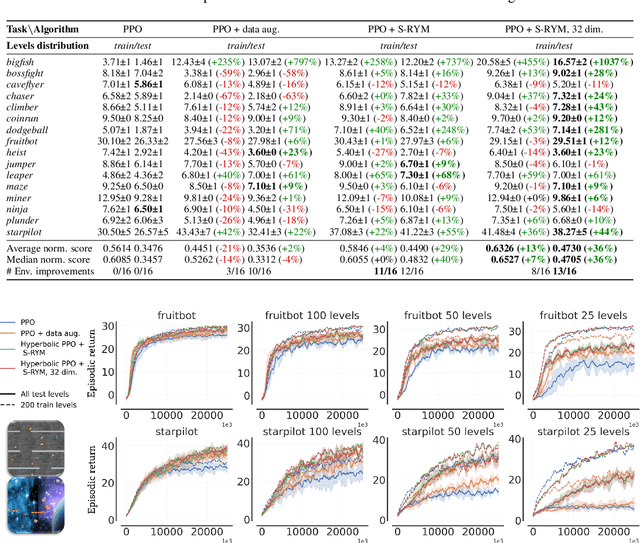
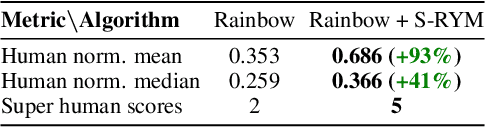
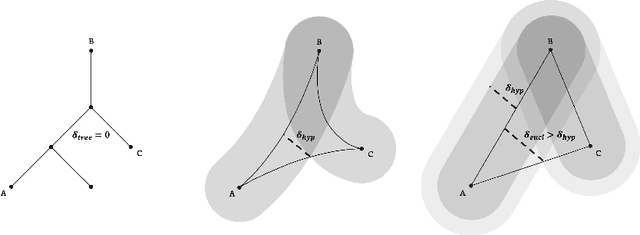
We propose a new class of deep reinforcement learning (RL) algorithms that model latent representations in hyperbolic space. Sequential decision-making requires reasoning about the possible future consequences of current behavior. Consequently, capturing the relationship between key evolving features for a given task is conducive to recovering effective policies. To this end, hyperbolic geometry provides deep RL models with a natural basis to precisely encode this inherently hierarchical information. However, applying existing methodologies from the hyperbolic deep learning literature leads to fatal optimization instabilities due to the non-stationarity and variance characterizing RL gradient estimators. Hence, we design a new general method that counteracts such optimization challenges and enables stable end-to-end learning with deep hyperbolic representations. We empirically validate our framework by applying it to popular on-policy and off-policy RL algorithms on the Procgen and Atari 100K benchmarks, attaining near universal performance and generalization benefits. Given its natural fit, we hope future RL research will consider hyperbolic representations as a standard tool.
Tag-Aware Document Representation for Research Paper Recommendation
Sep 08, 2022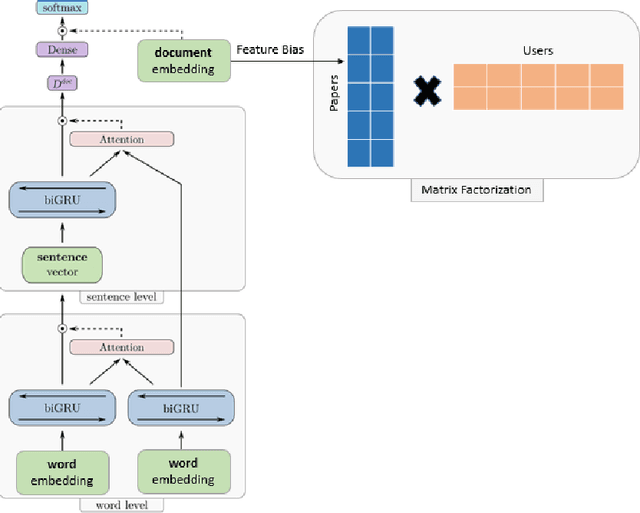

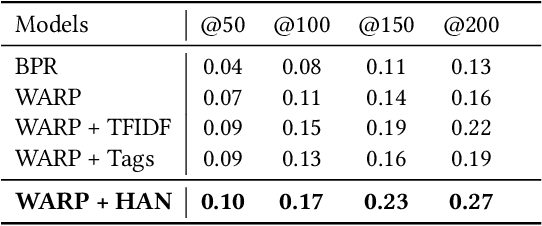
Finding online research papers relevant to one's interests is very challenging due to the increasing number of publications. Therefore, personalized research paper recommendation has become a significant and timely research topic. Collaborative filtering is a successful recommendation approach, which exploits the ratings given to items by users as a source of information for learning to make accurate recommendations. However, the ratings are often very sparse as in the research paper domain, due to the huge number of publications growing every year. Therefore, more attention has been drawn to hybrid methods that consider both ratings and content information. Nevertheless, most of the hybrid recommendation approaches that are based on text embedding have utilized bag-of-words techniques, which ignore word order and semantic meaning. In this paper, we propose a hybrid approach that leverages deep semantic representation of research papers based on social tags assigned by users. The experimental evaluation is performed on CiteULike, a real and publicly available dataset. The obtained findings show that the proposed model is effective in recommending research papers even when the rating data is very sparse.
Detection of Prosodic Boundaries in Speech Using Wav2Vec 2.0
Sep 29, 2022Prosodic boundaries in speech are of great relevance to both speech synthesis and audio annotation. In this paper, we apply the wav2vec 2.0 framework to the task of detecting these boundaries in speech signal, using only acoustic information. We test the approach on a set of recordings of Czech broadcast news, labeled by phonetic experts, and compare it to an existing text-based predictor, which uses the transcripts of the same data. Despite using a relatively small amount of labeled data, the wav2vec2 model achieves an accuracy of 94% and F1 measure of 83% on within-sentence prosodic boundaries (or 95% and 89% on all prosodic boundaries), outperforming the text-based approach. However, by combining the outputs of the two different models we can improve the results even further.
* This preprint is a pre-review version of the paper and does not contain any post-submission improvements or corrections. The Version of Record of this contribution is published in the proceedings of the International Conference on Text, Speech, and Dialogue (TSD 2022), LNAI volume 13502, and is available online at https://doi.org/10.1007/978-3-031-16270-1_31
Modelling Business Agreements in the Multimodal Transportation Domain through Ontological Smart Contracts
Sep 05, 2022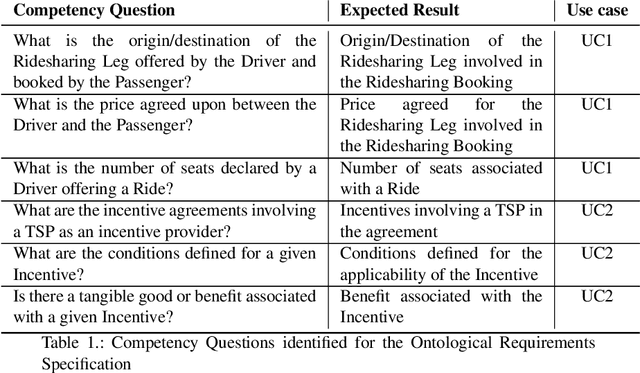
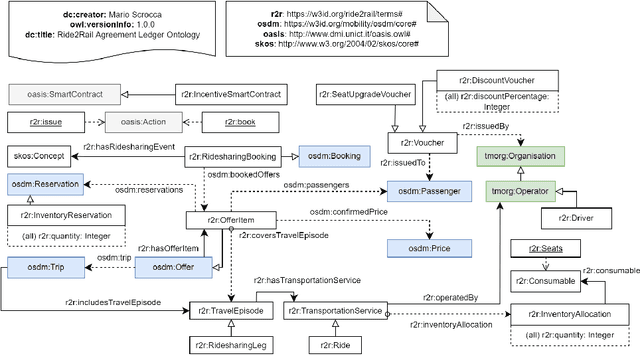
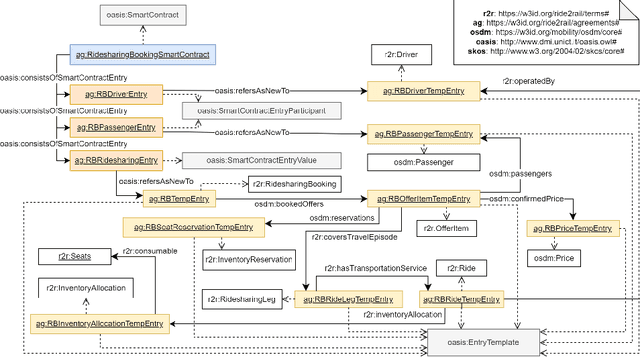
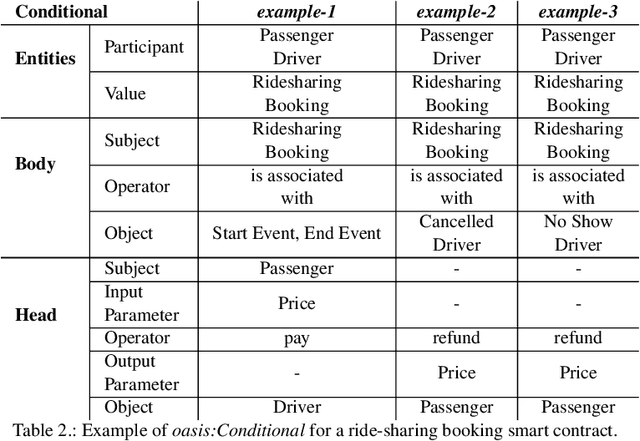
The blockchain technology provides integrity and reliability of the information, thus offering a suitable solution to guarantee trustability in a multi-stakeholder scenario that involves actors defining business agreements. The Ride2Rail project investigated the use of the blockchain to record as smart contracts the agreements between different stakeholders defined in a multimodal transportation domain. Modelling an ontology to represent the smart contracts enables the possibility of having a machine-readable and interoperable representation of the agreements. On one hand, the underlying blockchain ensures trust in the execution of the contracts, on the other hand, their ontological representation facilitates the retrieval of information within the ecosystem. The paper describes the development of the Ride2Rail Ontology for Agreements to showcase how the concept of an ontological smart contract, defined in the OASIS ontology, can be applied to a specific domain. The usage of the designed ontology is discussed by describing the modelling as ontological smart contracts of business agreements defined in a ride-sharing scenario.
Analyzing Adversarial Robustness of Vision Transformers against Spatial and Spectral Attacks
Aug 20, 2022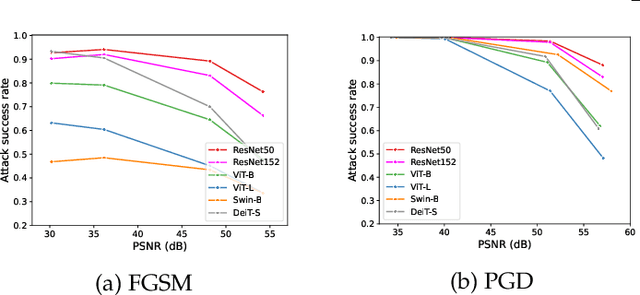
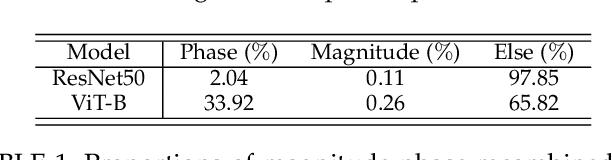
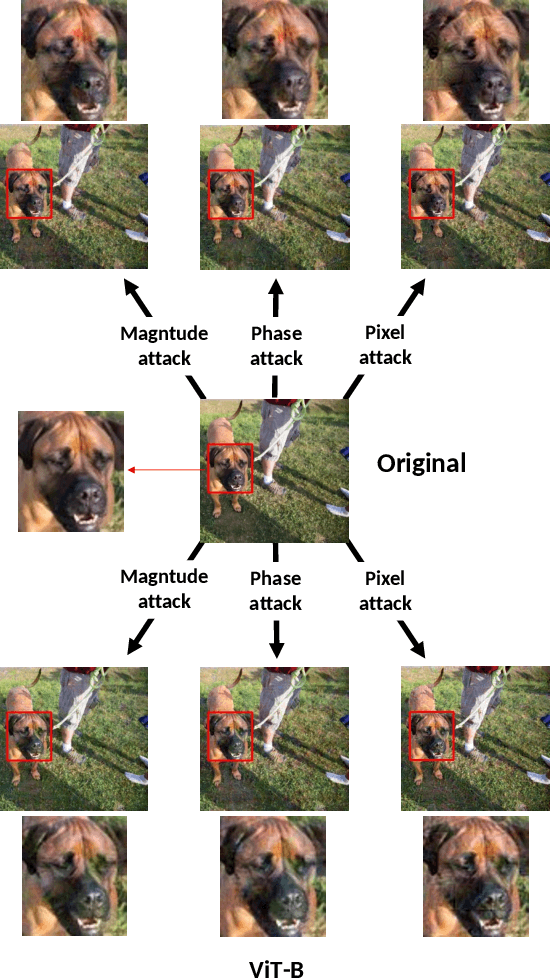
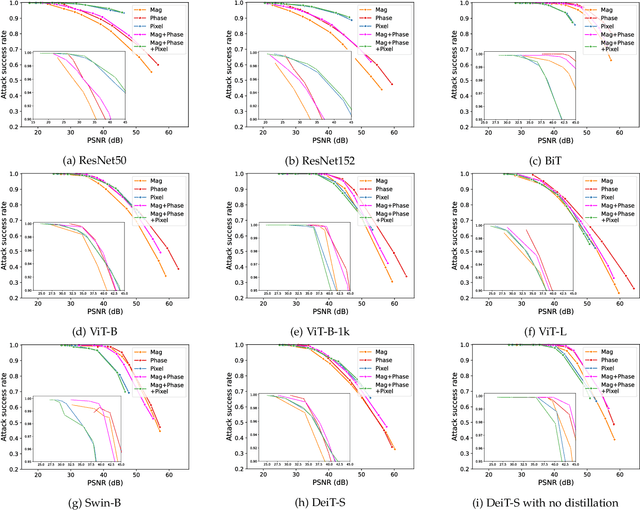
Vision Transformers have emerged as a powerful architecture that can outperform convolutional neural networks (CNNs) in image classification tasks. Several attempts have been made to understand robustness of Transformers against adversarial attacks, but existing studies draw inconsistent results, i.e., some conclude that Transformers are more robust than CNNs, while some others find that they have similar degrees of robustness. In this paper, we address two issues unexplored in the existing studies examining adversarial robustness of Transformers. First, we argue that the image quality should be simultaneously considered in evaluating adversarial robustness. We find that the superiority of one architecture to another in terms of robustness can change depending on the attack strength expressed by the quality of the attacked images. Second, by noting that Transformers and CNNs rely on different types of information in images, we formulate an attack framework, called Fourier attack, as a tool for implementing flexible attacks, where an image can be attacked in the spectral domain as well as in the spatial domain. This attack perturbs the magnitude and phase information of particular frequency components selectively. Through extensive experiments, we find that Transformers tend to rely more on phase information and low frequency information than CNNs, and thus sometimes they are even more vulnerable under frequency-selective attacks. It is our hope that this work provides new perspectives in understanding the properties and adversarial robustness of Transformers.
MotifClass: Weakly Supervised Text Classification with Higher-order Metadata Information
Nov 07, 2021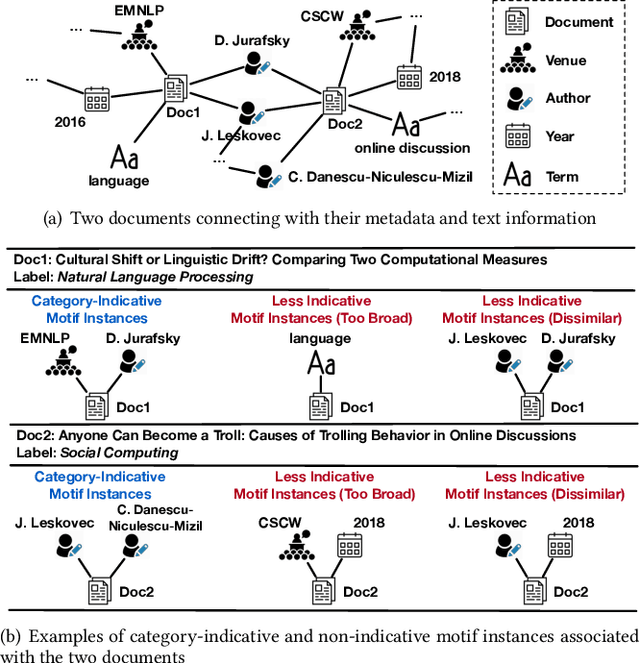
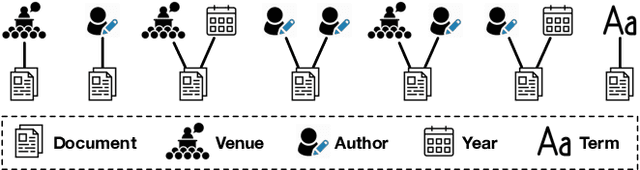
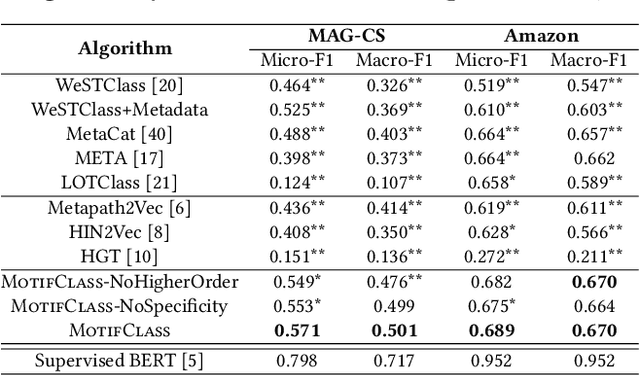
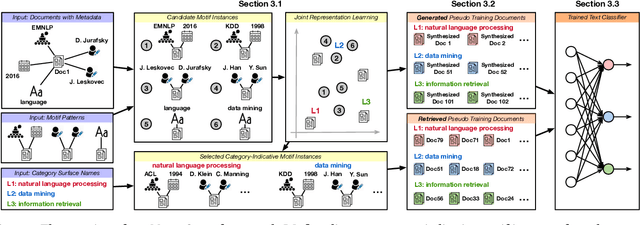
We study the problem of weakly supervised text classification, which aims to classify text documents into a set of pre-defined categories with category surface names only and without any annotated training document provided. Most existing approaches leverage textual information in each document. However, in many domains, documents are accompanied by various types of metadata (e.g., authors, venue, and year of a research paper). These metadata and their combinations may serve as strong category indicators in addition to textual contents. In this paper, we explore the potential of using metadata to help weakly supervised text classification. To be specific, we model the relationships between documents and metadata via a heterogeneous information network. To effectively capture higher-order structures in the network, we use motifs to describe metadata combinations. We propose a novel framework, named MotifClass, which (1) selects category-indicative motif instances, (2) retrieves and generates pseudo-labeled training samples based on category names and indicative motif instances, and (3) trains a text classifier using the pseudo training data. Extensive experiments on real-world datasets demonstrate the superior performance of MotifClass to existing weakly supervised text classification approaches. Further analysis shows the benefit of considering higher-order metadata information in our framework.
CLOWER: A Pre-trained Language Model with Contrastive Learning over Word and Character Representations
Aug 23, 2022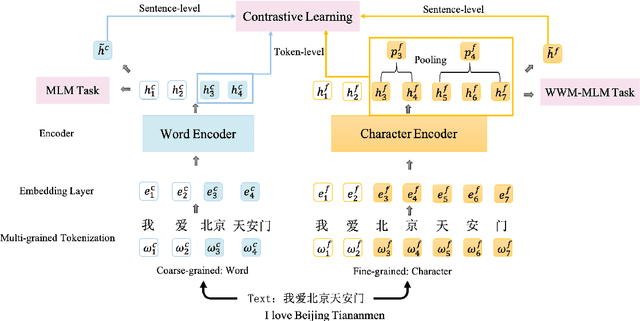
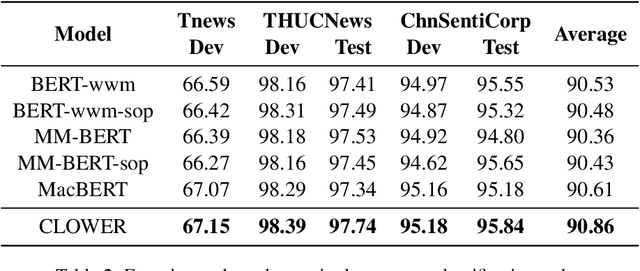
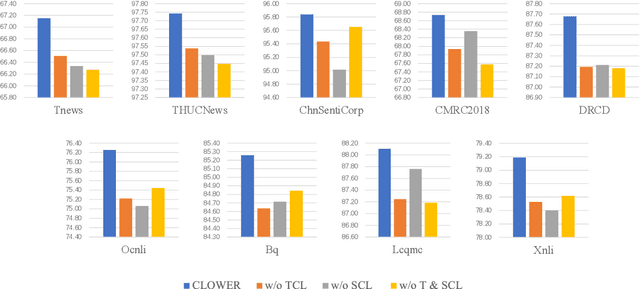
Pre-trained Language Models (PLMs) have achieved remarkable performance gains across numerous downstream tasks in natural language understanding. Various Chinese PLMs have been successively proposed for learning better Chinese language representation. However, most current models use Chinese characters as inputs and are not able to encode semantic information contained in Chinese words. While recent pre-trained models incorporate both words and characters simultaneously, they usually suffer from deficient semantic interactions and fail to capture the semantic relation between words and characters. To address the above issues, we propose a simple yet effective PLM CLOWER, which adopts the Contrastive Learning Over Word and charactER representations. In particular, CLOWER implicitly encodes the coarse-grained information (i.e., words) into the fine-grained representations (i.e., characters) through contrastive learning on multi-grained information. CLOWER is of great value in realistic scenarios since it can be easily incorporated into any existing fine-grained based PLMs without modifying the production pipelines.Extensive experiments conducted on a range of downstream tasks demonstrate the superior performance of CLOWER over several state-of-the-art baselines.
LMQFormer: A Laplace-Prior-Guided Mask Query Transformer for Lightweight Snow Removal
Oct 12, 2022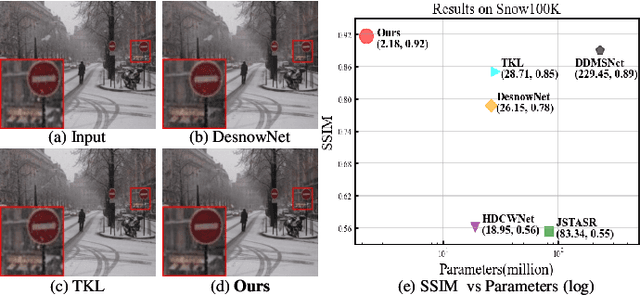



Snow removal aims to locate snow areas and recover clean images without repairing traces. Unlike the regularity and semitransparency of rain, snow with various patterns and degradations seriously occludes the background. As a result, the state-of-the-art snow removal methods usually retains a large parameter size. In this paper, we propose a lightweight but high-efficient snow removal network called Laplace Mask Query Transformer (LMQFormer). Firstly, we present a Laplace-VQVAE to generate a coarse mask as prior knowledge of snow. Instead of using the mask in dataset, we aim at reducing both the information entropy of snow and the computational cost of recovery. Secondly, we design a Mask Query Transformer (MQFormer) to remove snow with the coarse mask, where we use two parallel encoders and a hybrid decoder to learn extensive snow features under lightweight requirements. Thirdly, we develop a Duplicated Mask Query Attention (DMQA) that converts the coarse mask into a specific number of queries, which constraint the attention areas of MQFormer with reduced parameters. Experimental results in popular datasets have demonstrated the efficiency of our proposed model, which achieves the state-of-the-art snow removal quality with significantly reduced parameters and the lowest running time.
Deep Learning-Derived Optimal Aviation Strategies to Control Pandemics
Oct 12, 2022
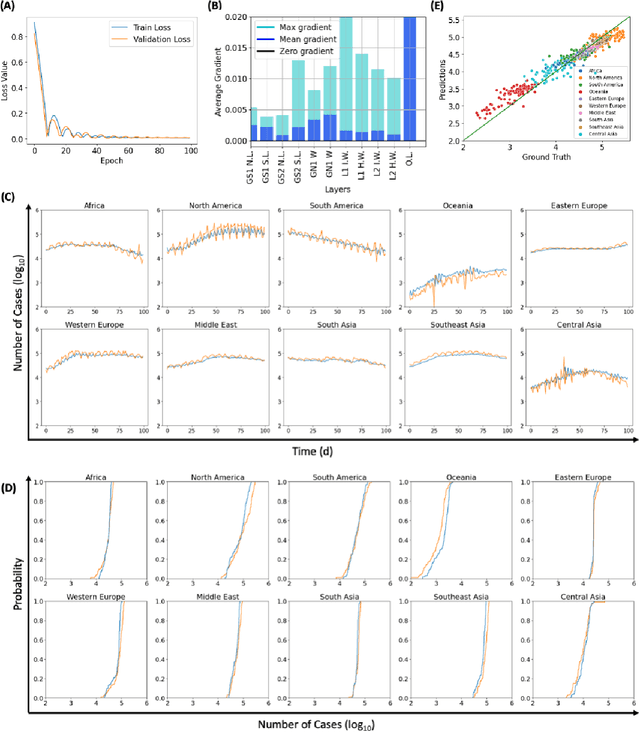
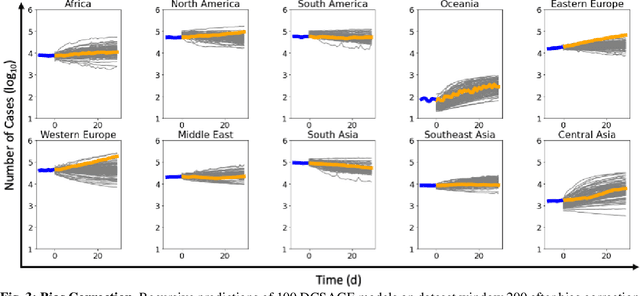
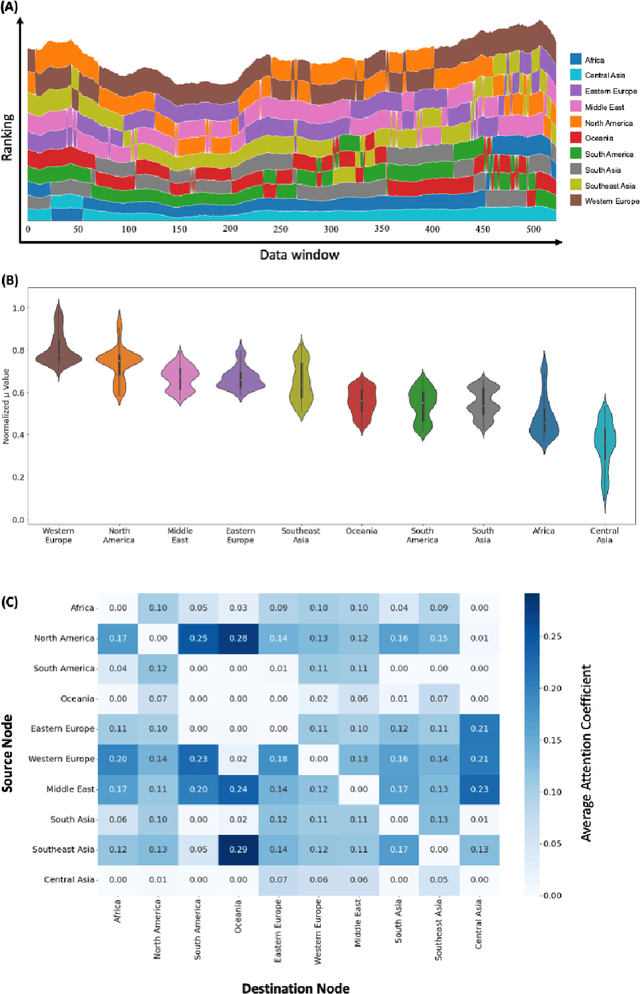
The COVID-19 pandemic has affected countries across the world, demanding drastic public health policies to mitigate the spread of infection, leading to economic crisis as a collateral damage. In this work, we investigated the impact of human mobility (described via international commercial flights) on COVID-19 infection dynamics at the global scale. For this, we developed a graph neural network-based framework referred to as Dynamic Connectivity GraphSAGE (DCSAGE), which operates over spatiotemporal graphs and is well-suited for dynamically changing adjacency information. To obtain insights on the relative impact of different geographical locations, due to their associated air traffic, on the evolution of the pandemic, we conducted local sensitivity analysis on our model through node perturbation experiments. From our analyses, we identified Western Europe, North America, and Middle East as the leading geographical locations fueling the pandemic, attributed to the enormity of air traffic originating or transiting through these regions. We used these observations to identify tangible air traffic reduction strategies that can have a high impact on controlling the pandemic, with minimal interference to human mobility. Our work provides a robust deep learning-based tool to study global pandemics and is of key relevance to policy makers to take informed decisions regarding air traffic restrictions during future outbreaks.
JukeDrummer: Conditional Beat-aware Audio-domain Drum Accompaniment Generation via Transformer VQ-VA
Oct 12, 2022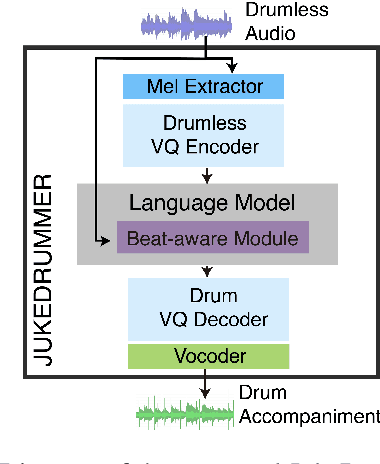
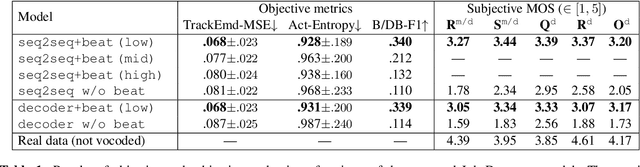
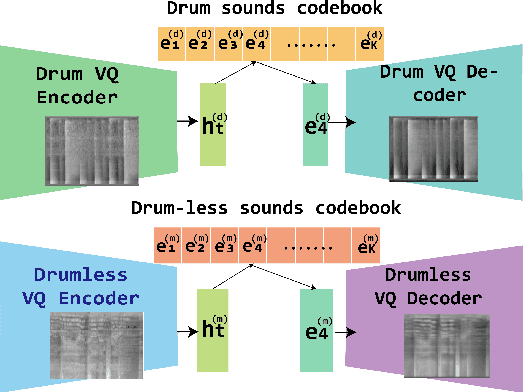
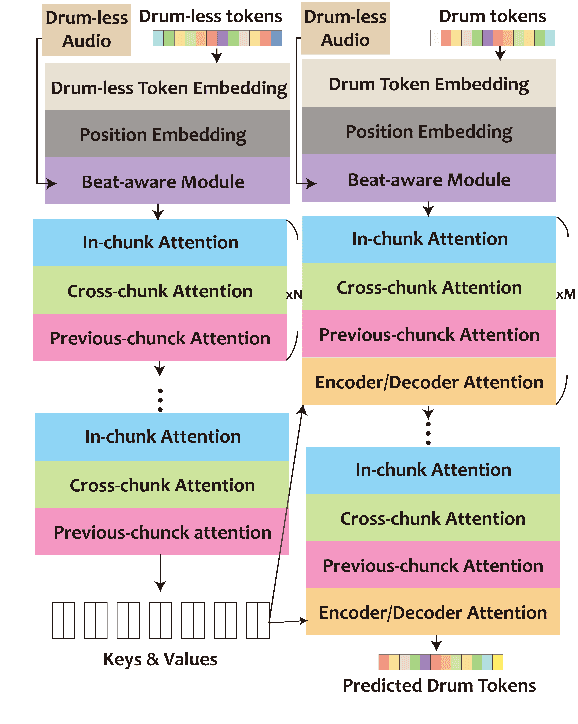
This paper proposes a model that generates a drum track in the audio domain to play along to a user-provided drum-free recording. Specifically, using paired data of drumless tracks and the corresponding human-made drum tracks, we train a Transformer model to improvise the drum part of an unseen drumless recording. We combine two approaches to encode the input audio. First, we train a vector-quantized variational autoencoder (VQ-VAE) to represent the input audio with discrete codes, which can then be readily used in a Transformer. Second, using an audio-domain beat tracking model, we compute beat-related features of the input audio and use them as embeddings in the Transformer. Instead of generating the drum track directly as waveforms, we use a separate VQ-VAE to encode the mel-spectrogram of a drum track into another set of discrete codes, and train the Transformer to predict the sequence of drum-related discrete codes. The output codes are then converted to a mel-spectrogram with a decoder, and then to the waveform with a vocoder. We report both objective and subjective evaluations of variants of the proposed model, demonstrating that the model with beat information generates drum accompaniment that is rhythmically and stylistically consistent with the input audio.