 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improve Transformer Pre-Training with Decoupled Directional Relative Position Encoding and Representation Differentiations
Oct 09, 2022
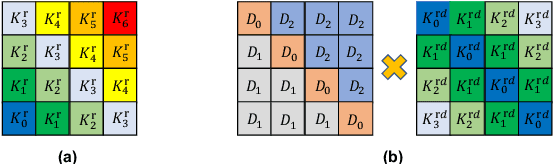
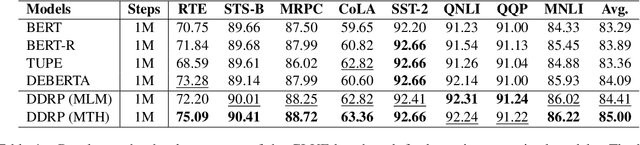
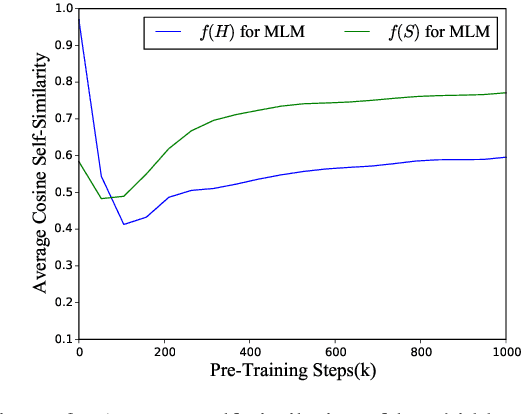
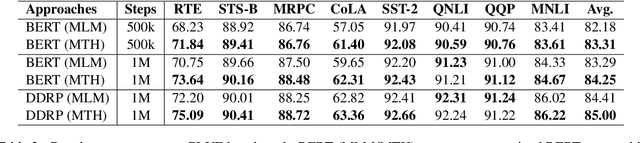
In this work, we revisit the Transformer-based pre-trained language models and identify two problems that may limit the expressiveness of the model. Firstly, existing relative position encoding models (e.g., T5 and DEBERTA) confuse two heterogeneous information: relative distance and direction. It may make the model unable to capture the associative semantics of the same direction or the same distance, which in turn affects the performance of downstream tasks. Secondly, we notice the pre-trained BERT with Mask Language Modeling (MLM) pre-training objective outputs similar token representations and attention weights of different heads, which may impose difficulties in capturing discriminative semantic representations. Motivated by the above investigation, we propose two novel techniques to improve pre-trained language models: Decoupled Directional Relative Position (DDRP) encoding and MTH pre-training objective. DDRP decouples the relative distance features and the directional features in classical relative position encoding for better position information understanding. MTH designs two novel auxiliary losses besides MLM to enlarge the dissimilarities between (a) last hidden states of different tokens, and (b) attention weights of different heads, alleviating homogenization and anisotropic problem in representation learning for better optimization. Extensive experiments and ablation studies on GLUE benchmark demonstrate the effectiveness of our proposed methods.
Sketched Multi-view Subspace Learning for Hyperspectral Anomalous Change Detection
Oct 09, 2022
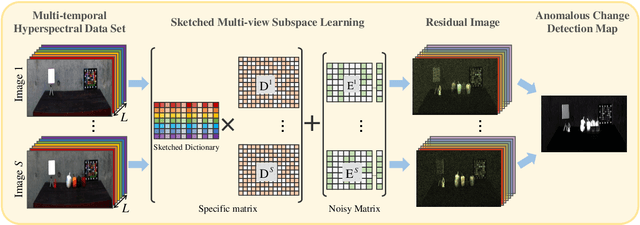
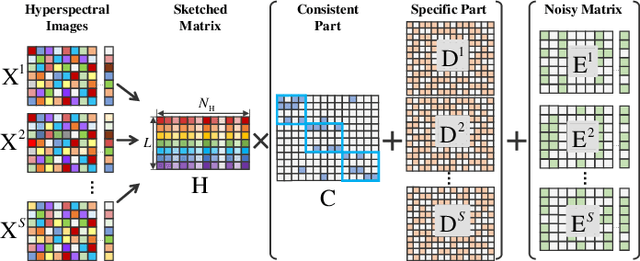

In recent years, multi-view subspace learning has been garnering increasing attention. It aims to capture the inner relationships of the data that are collected from multiple sources by learning a unified representation. In this way, comprehensive information from multiple views is shared and preserved for the generalization processes. As a special branch of temporal series hyperspectral image (HSI) processing, the anomalous change detection task focuses on detecting very small changes among different temporal images. However, when the volume of datasets is very large or the classes are relatively comprehensive, existing methods may fail to find those changes between the scenes, and end up with terrible detection results. In this paper, inspired by the sketched representation and multi-view subspace learning, a sketched multi-view subspace learning (SMSL) model is proposed for HSI anomalous change detection. The proposed model preserves major information from the image pairs and improves computational complexity by using a sketched representation matrix. Furthermore, the differences between scenes are extracted by utilizing the specific regularizer of the self-representation matrices. To evaluate the detection effectiveness of the proposed SMSL model, experiments are conducted on a benchmark hyperspectral remote sensing dataset and a natural hyperspectral dataset, and compared with other state-of-the art approaches.
Image Compressed Sensing with Multi-scale Dilated Convolutional Neural Network
Sep 28, 2022
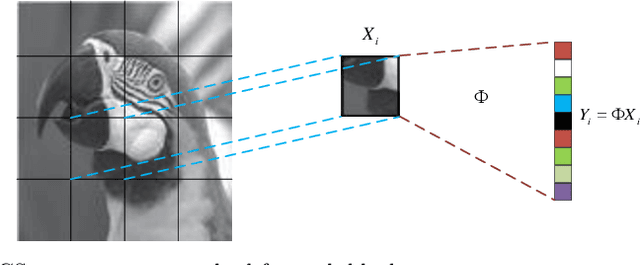
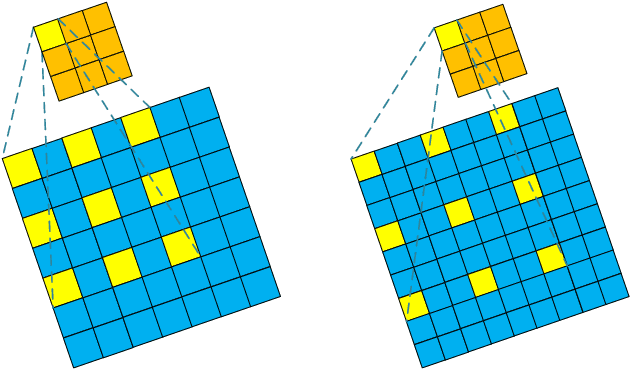
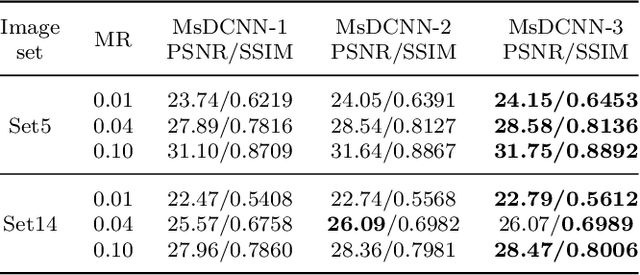
Deep Learning (DL) based Compressed Sensing (CS) has been applied for better performance of image reconstruction than traditional CS methods. However, most existing DL methods utilize the block-by-block measurement and each measurement block is restored separately, which introduces harmful blocking effects for reconstruction. Furthermore, the neuronal receptive fields of those methods are designed to be the same size in each layer, which can only collect single-scale spatial information and has a negative impact on the reconstruction process. This paper proposes a novel framework named Multi-scale Dilated Convolution Neural Network (MsDCNN) for CS measurement and reconstruction. During the measurement period, we directly obtain all measurements from a trained measurement network, which employs fully convolutional structures and is jointly trained with the reconstruction network from the input image. It needn't be cut into blocks, which effectively avoids the block effect. During the reconstruction period, we propose the Multi-scale Feature Extraction (MFE) architecture to imitate the human visual system to capture multi-scale features from the same feature map, which enhances the image feature extraction ability of the framework and improves the performance of image reconstruction. In the MFE, there are multiple parallel convolution channels to obtain multi-scale feature information. Then the multi-scale features information is fused and the original image is reconstructed with high quality. Our experimental results show that the proposed method performs favorably against the state-of-the-art methods in terms of PSNR and SSIM.
Outcome-Oriented Prescriptive Process Monitoring Based on Temporal Logic Patterns
Nov 14, 2022
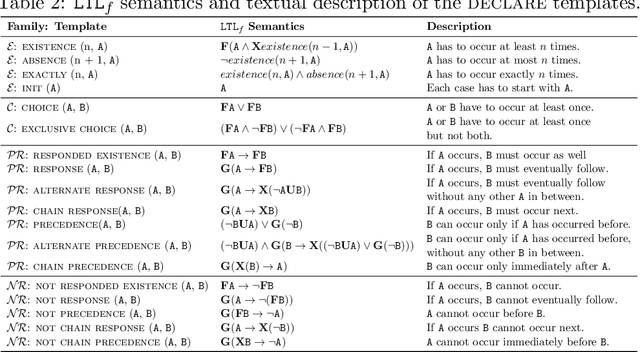
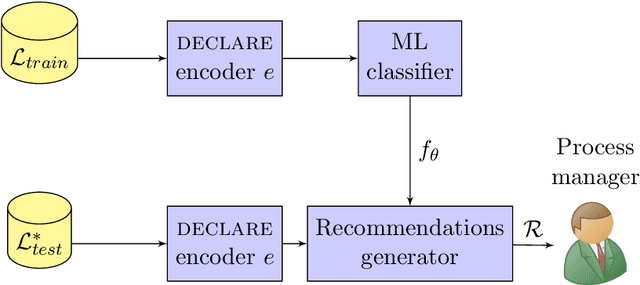

Prescriptive Process Monitoring systems recommend, during the execution of a business process, interventions that, if followed, prevent a negative outcome of the process. Such interventions have to be reliable, that is, they have to guarantee the achievement of the desired outcome or performance, and they have to be flexible, that is, they have to avoid overturning the normal process execution or forcing the execution of a given activity. Most of the existing Prescriptive Process Monitoring solutions, however, while performing well in terms of recommendation reliability, provide the users with very specific (sequences of) activities that have to be executed without caring about the feasibility of these recommendations. In order to face this issue, we propose a new Outcome-Oriented Prescriptive Process Monitoring system recommending temporal relations between activities that have to be guaranteed during the process execution in order to achieve a desired outcome. This softens the mandatory execution of an activity at a given point in time, thus leaving more freedom to the user in deciding the interventions to put in place. Our approach defines these temporal relations with Linear Temporal Logic over finite traces patterns that are used as features to describe the historical process data recorded in an event log by the information systems supporting the execution of the process. Such encoded log is used to train a Machine Learning classifier to learn a mapping between the temporal patterns and the outcome of a process execution. The classifier is then queried at runtime to return as recommendations the most salient temporal patterns to be satisfied to maximize the likelihood of a certain outcome for an input ongoing process execution. The proposed system is assessed using a pool of 22 real-life event logs that have already been used as a benchmark in the Process Mining community.
RIS Design to Optimize the CRB for Source Localization
Oct 01, 2022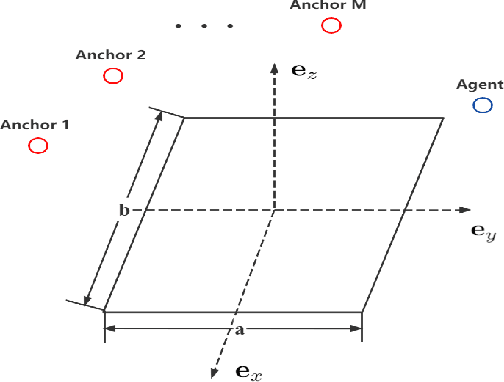
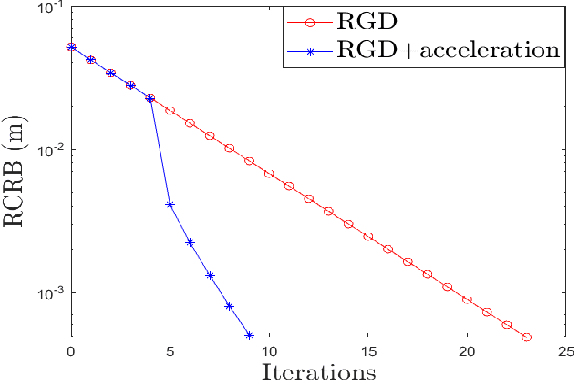
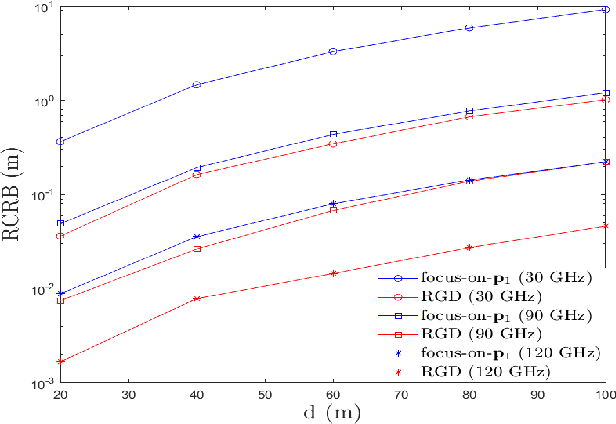
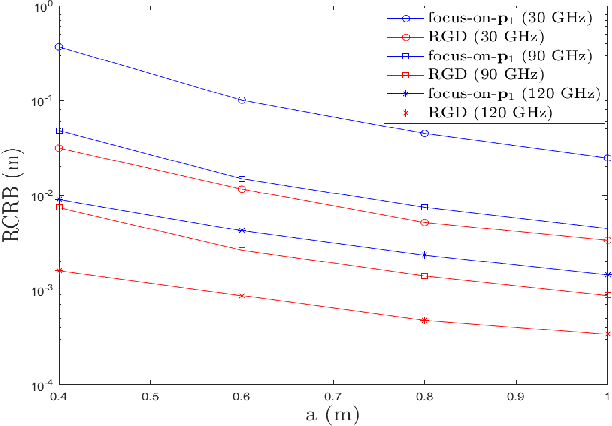
Reconfigurable Intelligent Surface (RIS) plays a pivotal role in enhancing source localization accuracy. Based on the information inequality of Fisher information analyses, the Cram\'{e}r-Rao Bound (CRB) of the localization error can be used to evaluate the localization accuracy for a given set of RIS coefficients. However, there is a lack of research in optimizing these RIS coefficients to decrease the CRB under the constraint imposed by the RIS hardware. In this paper, we adopt the manifold optimization method to derive the locally optimal CRB of the localization error, where the RIS coefficients are restricted to lie on the complex circle manifold. Specifically, the Wirtinger derivatives are calculated in the gradient descent part, and the Riemannian nonlinear acceleration technique is employed to speed up the convergence rate. Simulation results show that the proposed method can yield the locally optimal RIS coefficients and can significantly decrease the CRB of localization error. Moreover, the iteration number can be reduced by the acceleration technique.
Weighted MMSE Precoding for Constructive Interference Region
Oct 01, 2022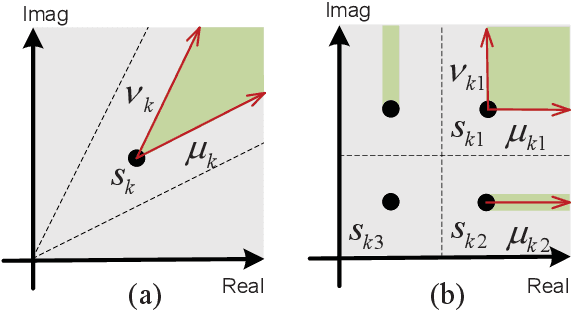
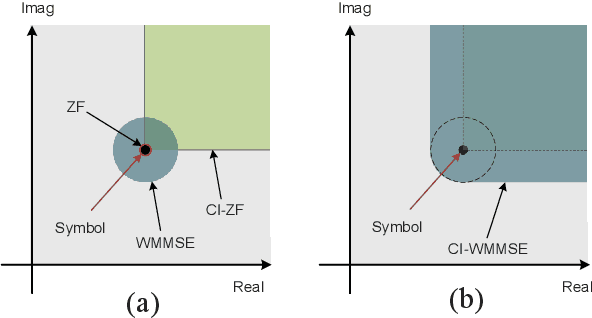
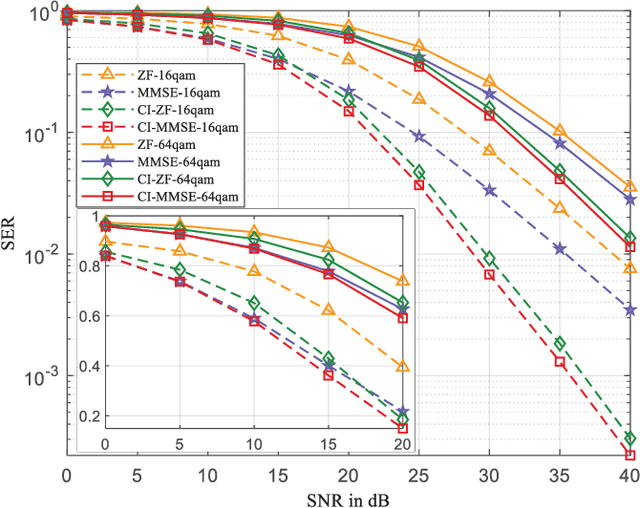
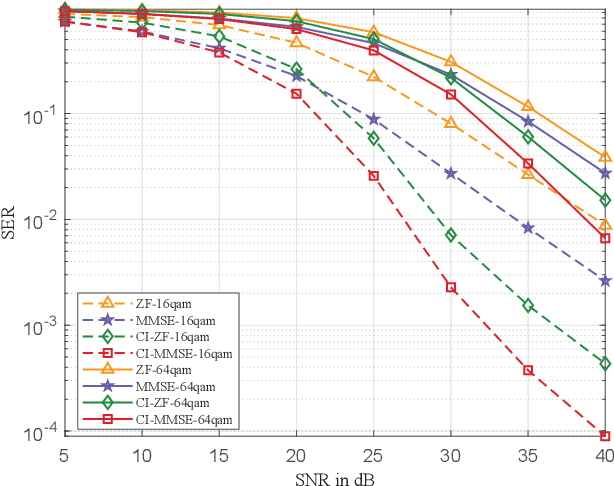
In this paper, we propose a symbol-level precoding (SLP) design that aims to minimize the weighted mean square error between the received signal and the constellation point located in the constructive interference region (CIR). Unlike most existing SLP schemes that rely on channel state information (CSI) only, the proposed scheme exploits both CSI and the distribution information of the noise to achieve improved performance. We firstly propose a simple generic description of CIR that facilitates the subsequent SLP design. Such an objective can further be formulated as a nonnegative least squares (NNLS) problem, which can be solved efficiently by the active-set algorithm. Furthermore, the weighted minimum mean square error (WMMSE) precoding and the existing SLP can be easily verified as special cases of the proposed scheme. Finally, simulation results show that the proposed precoding outperforms the state-of-the-art SLP schemes in full signal-to-noise ratio ranges in both uncoded and coded systems without additional complexity over conventional SLP.
LightVessel: Exploring Lightweight Coronary Artery Vessel Segmentation via Similarity Knowledge Distillation
Nov 02, 2022
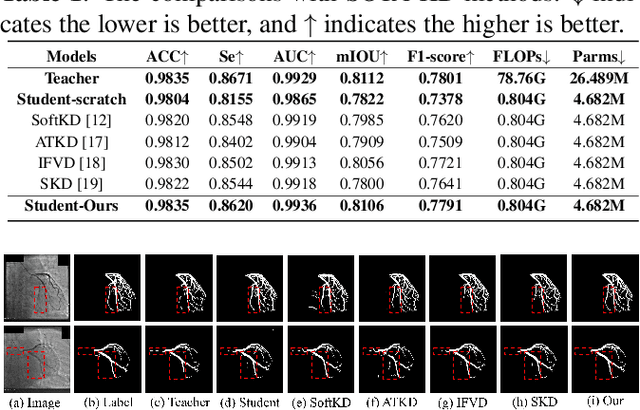
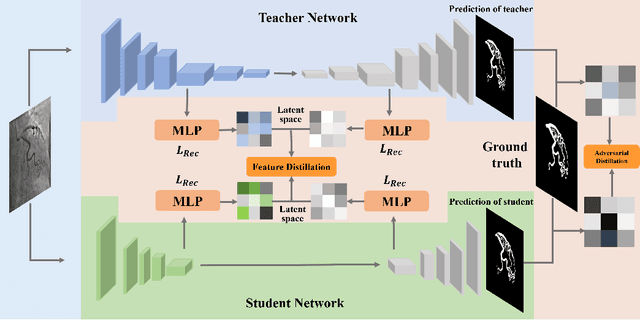
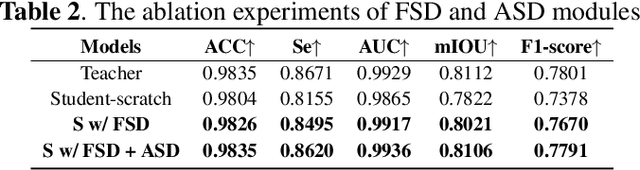
In recent years, deep convolution neural networks (DCNNs) have achieved great prospects in coronary artery vessel segmentation. However, it is difficult to deploy complicated models in clinical scenarios since high-performance approaches have excessive parameters and high computation costs. To tackle this problem, we propose \textbf{LightVessel}, a Similarity Knowledge Distillation Framework, for lightweight coronary artery vessel segmentation. Primarily, we propose a Feature-wise Similarity Distillation (FSD) module for semantic-shift modeling. Specifically, we calculate the feature similarity between the symmetric layers from the encoder and decoder. Then the similarity is transferred as knowledge from a cumbersome teacher network to a non-trained lightweight student network. Meanwhile, for encouraging the student model to learn more pixel-wise semantic information, we introduce the Adversarial Similarity Distillation (ASD) module. Concretely, the ASD module aims to construct the spatial adversarial correlation between the annotation and prediction from the teacher and student models, respectively. Through the ASD module, the student model obtains fined-grained subtle edge segmented results of the coronary artery vessel. Extensive experiments conducted on Clinical Coronary Artery Vessel Dataset demonstrate that LightVessel outperforms various knowledge distillation counterparts.
DC-cycleGAN: Bidirectional CT-to-MR Synthesis from Unpaired Data
Nov 02, 2022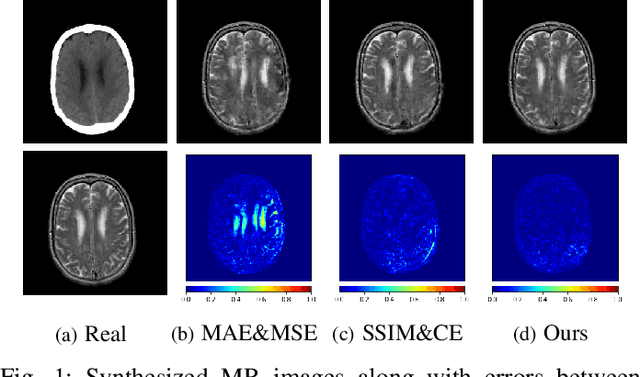
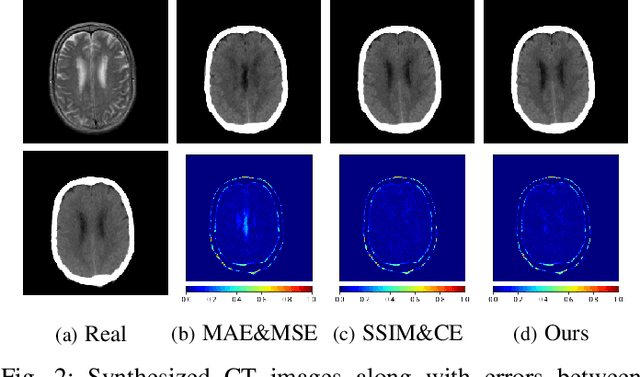
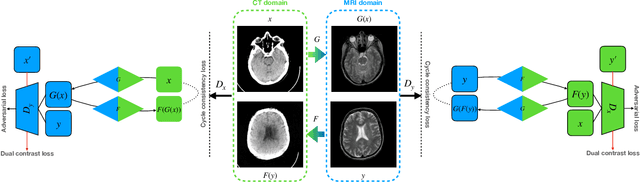
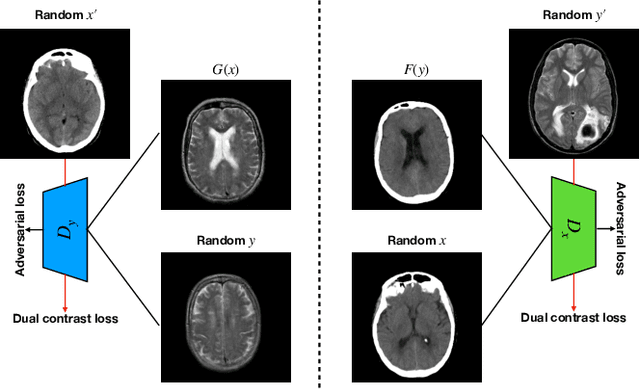
Magnetic resonance (MR) and computer tomography (CT) images are two typical types of medical images that provide mutually-complementary information for accurate clinical diagnosis and treatment. However, obtaining both images may be limited due to some considerations such as cost, radiation dose and modality missing. Recently, medical image synthesis has aroused gaining research interest to cope with this limitation. In this paper, we propose a bidirectional learning model, denoted as dual contrast cycleGAN (DC-cycleGAN), to synthesis medical images from unpaired data. Specifically, a dual contrast loss is introduced into the discriminators to indirectly build constraints between MR and CT images by taking the advantage of samples from the source domain as negative sample and enforce the synthetic images fall far away from the source domain. In addition, cross entropy and structural similarity index (SSIM) are integrated into the cycleGAN in order to consider both luminance and structure of samples when synthesizing images. The experimental results indicates that DC-cycleGAN is able to produce promising results as compared with other cycleGAN-based medical image synthesis methods such as cycleGAN, RegGAN, DualGAN and NiceGAN. The code will be available at https://github.com/JiayuanWang-JW/DC-cycleGAN.
Investigation of chemical structure recognition by encoder-decoder models in learning progress
Nov 02, 2022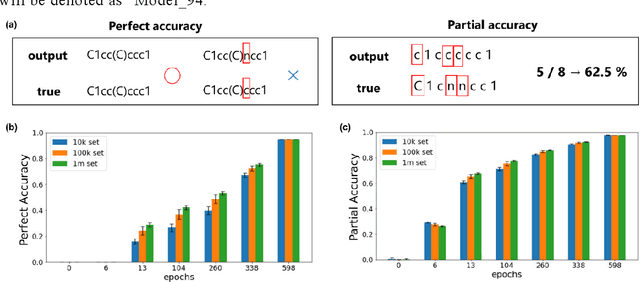
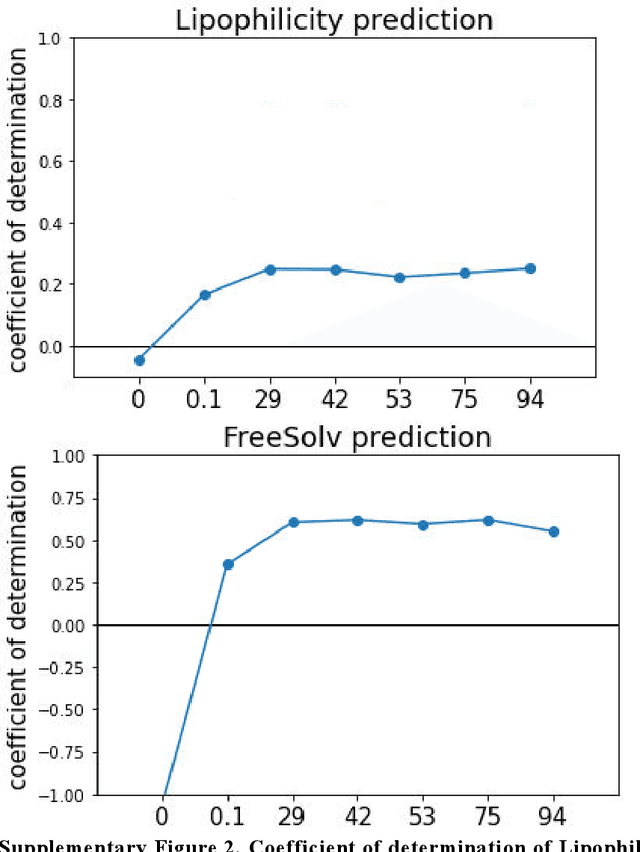
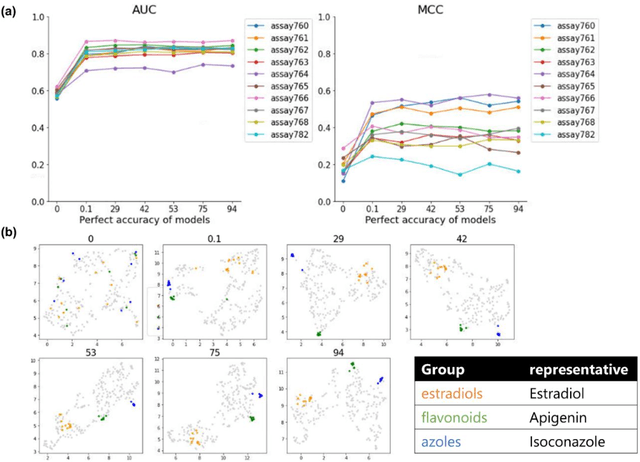
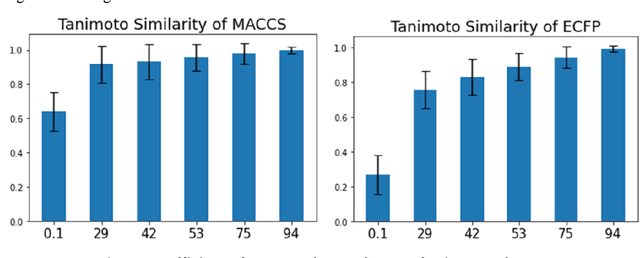
Descriptor generation methods using latent representations of encoder$-$decoder (ED) models with SMILES as input are useful because of the continuity of descriptor and restorability to the structure. However, it is not clear how the structure is recognized in the learning progress of ED models. In this work, we created ED models of various learning progress and investigated the relationship between structural information and learning progress. We showed that compound substructures were learned early in ED models by monitoring the accuracy of downstream tasks and input$-$output substructure similarity using substructure$-$based descriptors, which suggests that existing evaluation methods based on the accuracy of downstream tasks may not be sensitive enough to evaluate the performance of ED models with SMILES as descriptor generation methods. On the other hand, we showed that structure restoration was time$-$consuming, and in particular, insufficient learning led to the estimation of a larger structure than the actual one. It can be inferred that determining the endpoint of the structure is a difficult task for the model. To our knowledge, this is the first study to link the learning progress of SMILES by ED model to chemical structures for a wide range of chemicals.
Modern GPR Target Recognition Methods
Nov 02, 2022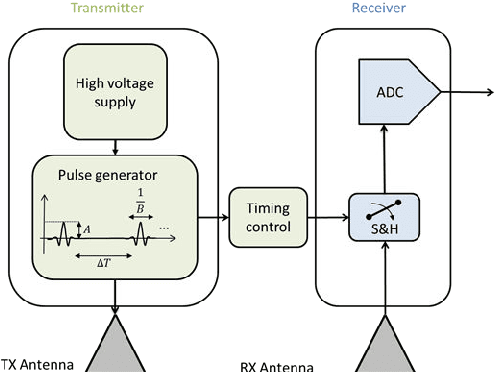
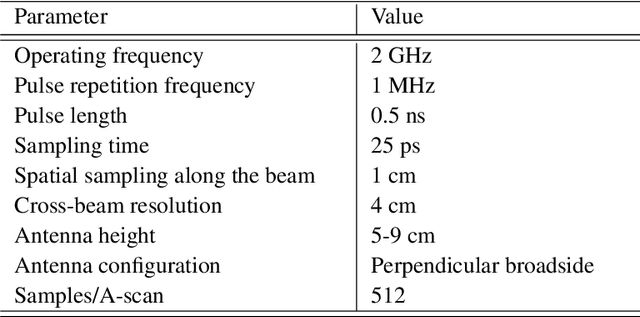
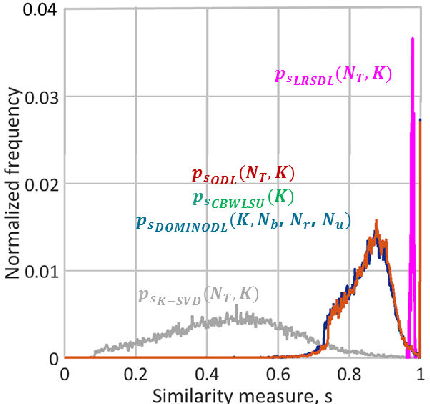
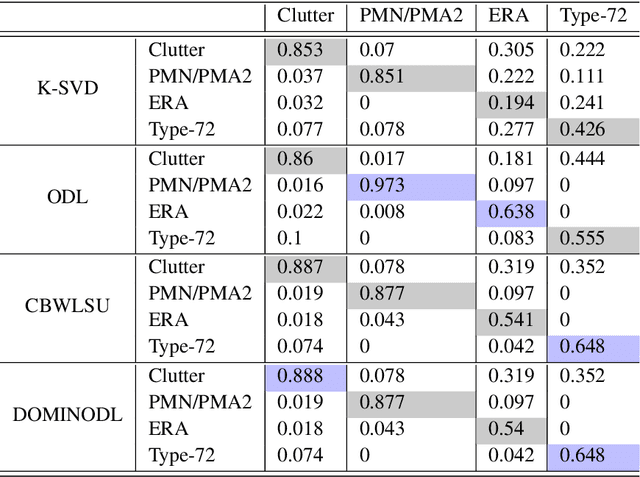
Traditional GPR target recognition methods include pre-processing the data by removal of noisy signatures, dewowing (high-pass filtering to remove low-frequency noise), filtering, deconvolution, migration (correction of the effect of survey geometry), and can rely on the simulation of GPR responses. The techniques usually suffer from the loss of information, inability to adapt from prior results, and inefficient performance in the presence of strong clutter and noise. To address these challenges, several advanced processing methods have been developed over the past decade to enhance GPR target recognition. In this chapter, we provide an overview of these modern GPR processing techniques. In particular, we focus on the following methods: adaptive receive processing of range profiles depending on the target environment; adoption of learning-based methods so that the radar utilizes the results from prior measurements; application of methods that exploit the fact that the target scene is sparse in some domain or dictionary; application of advanced classification techniques; and convolutional coding which provides succinct and representatives features of the targets. We describe each of these techniques or their combinations through a representative application of landmine detection.
* Book chapter, 56 pages, 17 figures, 12 tables. arXiv admin note: substantial text overlap with arXiv:1806.04599