 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Deep Learning-based clustering for Human Activity Recognition
Nov 10, 2022
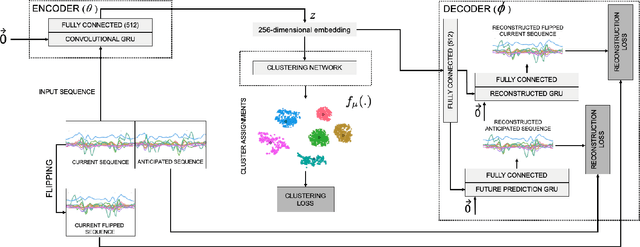
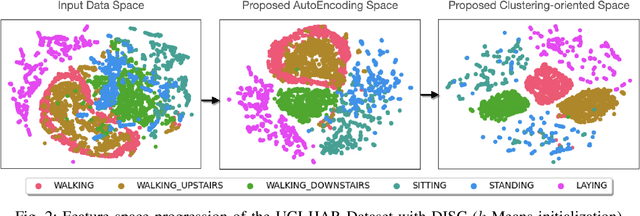
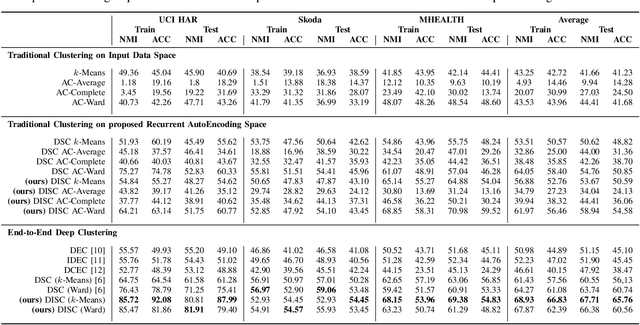
One of the main problems in applying deep learning techniques to recognize activities of daily living (ADLs) based on inertial sensors is the lack of appropriately large labelled datasets to train deep learning-based models. A large amount of data would be available due to the wide spread of mobile devices equipped with inertial sensors that can collect data to recognize human activities. Unfortunately, this data is not labelled. The paper proposes DISC (Deep Inertial Sensory Clustering), a DL-based clustering architecture that automatically labels multi-dimensional inertial signals. In particular, the architecture combines a recurrent AutoEncoder and a clustering criterion to predict unlabelled human activities-related signals. The proposed architecture is evaluated on three publicly available HAR datasets and compared with four well-known end-to-end deep clustering approaches. The experiments demonstrate the effectiveness of DISC on both clustering accuracy and normalized mutual information metrics.
Prior-enhanced Temporal Action Localization using Subject-aware Spatial Attention
Nov 10, 2022
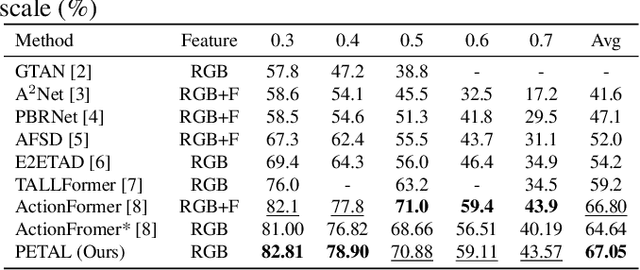
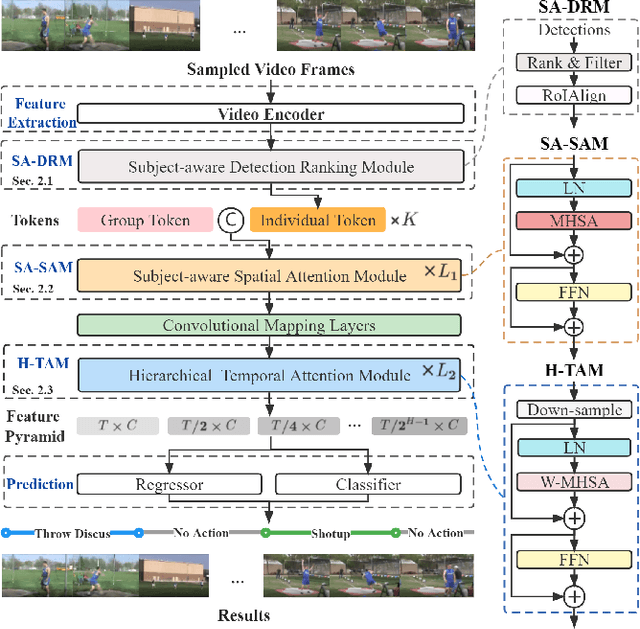
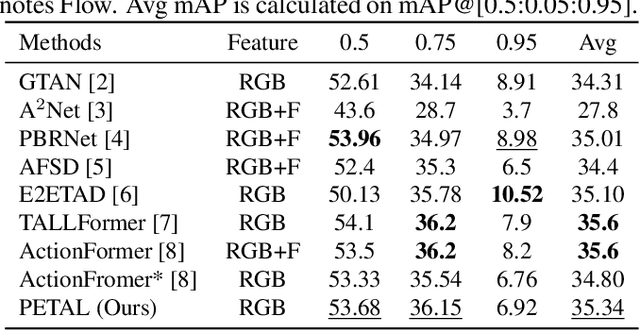
Temporal action localization (TAL) aims to detect the boundary and identify the class of each action instance in a long untrimmed video. Current approaches treat video frames homogeneously, and tend to give background and key objects excessive attention. This limits their sensitivity to localize action boundaries. To this end, we propose a prior-enhanced temporal action localization method (PETAL), which only takes in RGB input and incorporates action subjects as priors. This proposal leverages action subjects' information with a plug-and-play subject-aware spatial attention module (SA-SAM) to generate an aggregated and subject-prioritized representation. Experimental results on THUMOS-14 and ActivityNet-1.3 datasets demonstrate that the proposed PETAL achieves competitive performance using only RGB features, e.g., boosting mAP by 2.41% or 0.25% over the state-of-the-art approach that uses RGB features or with additional optical flow features on the THUMOS-14 dataset.
Controllable Citation Text Generation
Nov 14, 2022
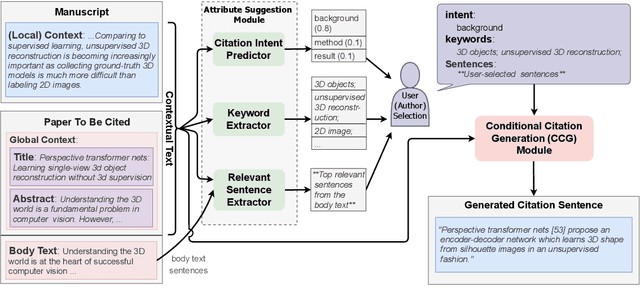

The aim of citation generation is usually to automatically generate a citation sentence that refers to a chosen paper in the context of a manuscript. However, a rigid citation generation process is at odds with an author's desire to control the generated text based on certain attributes, such as 1) the citation intent of e.g. either introducing background information or comparing results; 2) keywords that should appear in the citation text; or 3) specific sentences in the cited paper that characterize the citation content. To provide these degrees of freedom, we present a controllable citation generation system. In data from a large corpus, we first parse the attributes of each citation sentence and use these as additional input sources during training of the BART-based abstractive summarizer. We further develop an attribute suggestion module that infers the citation intent and suggests relevant keywords and sentences that users can select to tune the generation. Our framework gives users more control over generated citations, outperforming citation generation models without attribute awareness in both ROUGE and human evaluations.
Denoising Diffusion Models for Out-of-Distribution Detection
Nov 14, 2022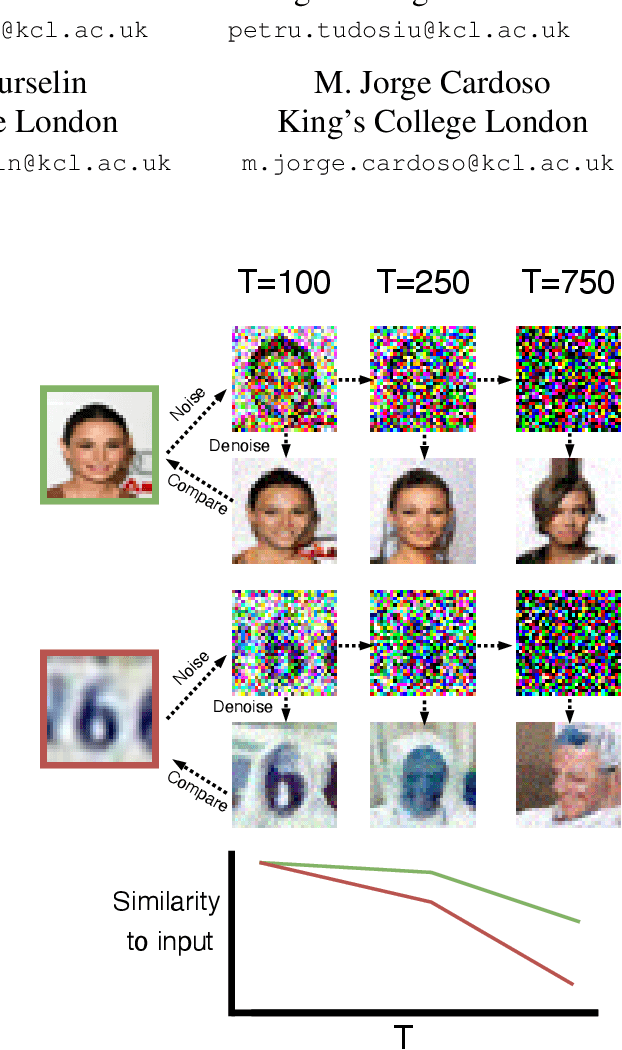
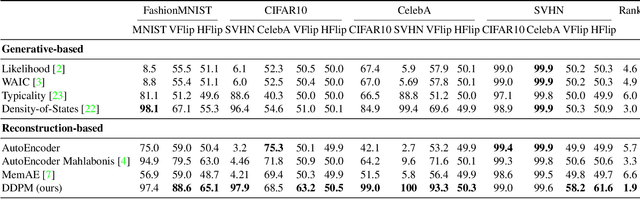


Out-of-distribution detection is crucial to the safe deployment of machine learning systems. Currently, the state-of-the-art in unsupervised out-of-distribution detection is dominated by generative-based approaches that make use of estimates of the likelihood or other measurements from a generative model. Reconstruction-based methods offer an alternative approach, in which a measure of reconstruction error is used to determine if a sample is out-of-distribution. However, reconstruction-based approaches are less favoured, as they require careful tuning of the model's information bottleneck - such as the size of the latent dimension - to produce good results. In this work, we exploit the view of denoising diffusion probabilistic models (DDPM) as denoising autoencoders where the bottleneck is controlled externally, by means of the amount of noise applied. We propose to use DDPMs to reconstruct an input that has been noised to a range of noise levels, and use the resulting multi-dimensional reconstruction error to classify out-of-distribution inputs. Our approach outperforms not only reconstruction-based methods, but also state-of-the-art generative-based approaches.
An Interpretable Neuron Embedding for Static Knowledge Distillation
Nov 14, 2022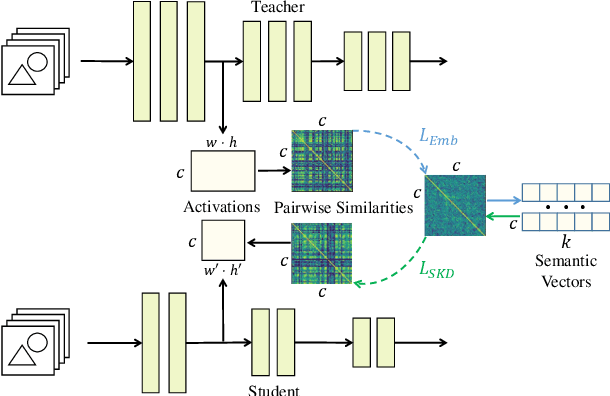
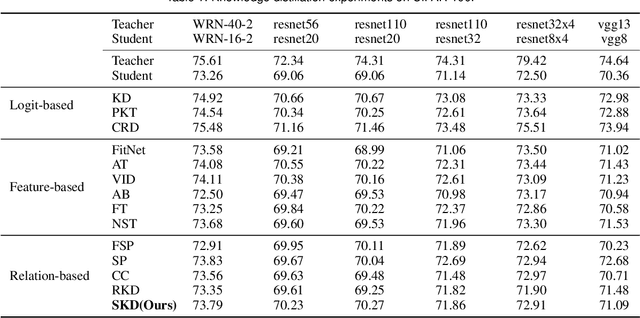


Although deep neural networks have shown well-performance in various tasks, the poor interpretability of the models is always criticized. In the paper, we propose a new interpretable neural network method, by embedding neurons into the semantic space to extract their intrinsic global semantics. In contrast to previous methods that probe latent knowledge inside the model, the proposed semantic vector externalizes the latent knowledge to static knowledge, which is easy to exploit. Specifically, we assume that neurons with similar activation are of similar semantic information. Afterwards, semantic vectors are optimized by continuously aligning activation similarity and semantic vector similarity during the training of the neural network. The visualization of semantic vectors allows for a qualitative explanation of the neural network. Moreover, we assess the static knowledge quantitatively by knowledge distillation tasks. Empirical experiments of visualization show that semantic vectors describe neuron activation semantics well. Without the sample-by-sample guidance from the teacher model, static knowledge distillation exhibit comparable or even superior performance with existing relation-based knowledge distillation methods.
Language models are good pathologists: using attention-based sequence reduction and text-pretrained transformers for efficient WSI classification
Nov 14, 2022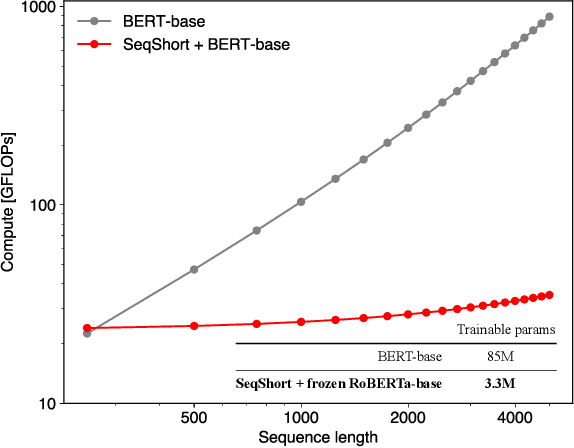
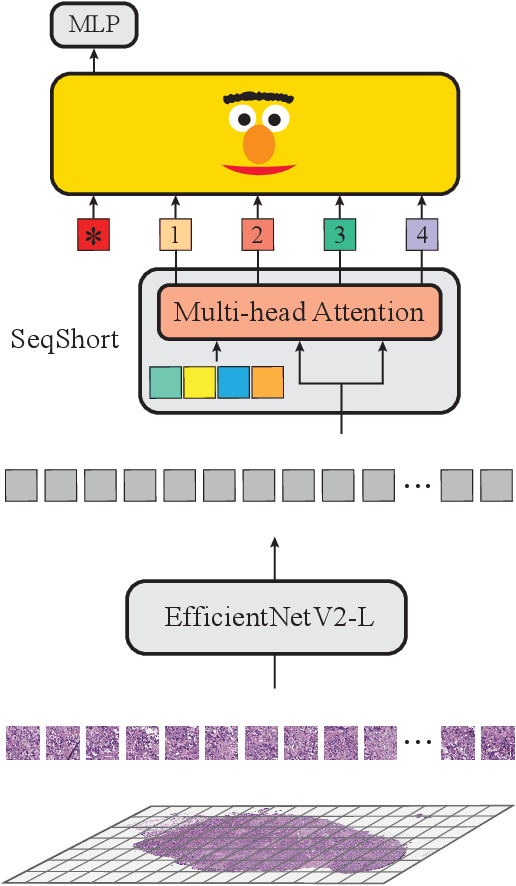

In digital pathology, Whole Slide Image (WSI) analysis is usually formulated as a Multiple Instance Learning (MIL) problem. Although transformer-based architectures have been used for WSI classification, these methods require modifications to adapt them to specific challenges of this type of image data. Despite their power across domains, reference transformer models in classical Computer Vision (CV) and Natural Language Processing (NLP) tasks are not used for pathology slide analysis. In this work we demonstrate the use of standard, frozen, text-pretrained, transformer language models in application to WSI classification. We propose SeqShort, a multi-head attention-based sequence reduction input layer to summarize each WSI in a fixed and short size sequence of instances. This allows us to reduce the computational costs of self-attention on long sequences, and to include positional information that is unavailable in other MIL approaches. We demonstrate the effectiveness of our methods in the task of cancer subtype classification, without the need of designing a WSI-specific transformer or performing in-domain self-supervised pretraining, while keeping a reduced compute budget and number of trainable parameters.
Marine Microalgae Detection in Microscopy Images: A New Dataset
Nov 14, 2022

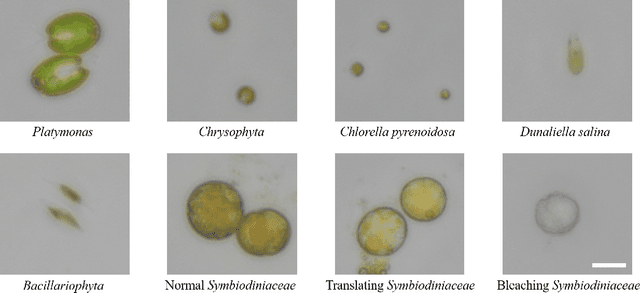
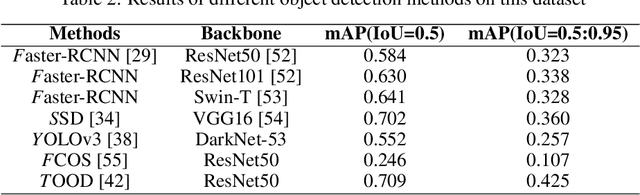
Marine microalgae are widespread in the ocean and play a crucial role in the ecosystem. Automatic identification and location of marine microalgae in microscopy images would help establish marine ecological environment monitoring and water quality evaluation system. A new dataset for marine microalgae detection is proposed in this paper. Six classes of microalgae commonlyfound in the ocean (Bacillariophyta, Chlorella pyrenoidosa, Platymonas, Dunaliella salina, Chrysophyta, Symbiodiniaceae) are microscopically imaged in real-time. Images of Symbiodiniaceae in three physiological states known as normal, bleaching, and translating are also included. We annotated these images with bounding boxes using Labelme software and split them into the training and testing sets. The total number of images in the dataset is 937 and all the objects in these images were annotated. The total number of annotated objects is 4201. The training set contains 537 images and the testing set contains 430 images. Baselines of different object detection algorithms are trained, validated and tested on this dataset. This data set can be got accessed via tianchi.aliyun.com/competition/entrance/532036/information.
Controllable GAN Synthesis Using Non-Rigid Structure-from-Motion
Nov 14, 2022
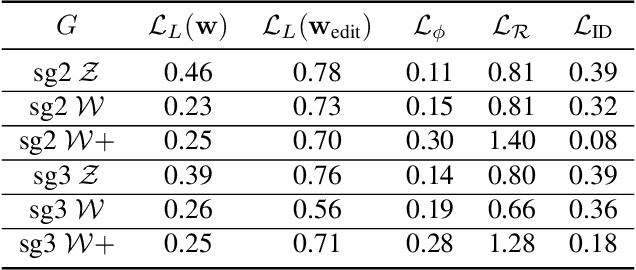

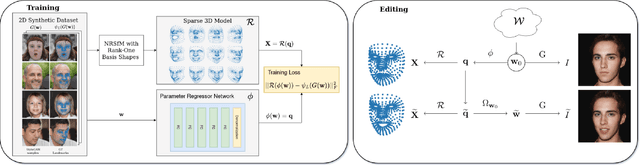
In this paper, we present an approach for combining non-rigid structure-from-motion (NRSfM) with deep generative models,and propose an efficient framework for discovering trajectories in the latent space of 2D GANs corresponding to changes in 3D geometry. Our approach uses recent advances in NRSfM and enables editing of the camera and non-rigid shape information associated with the latent codes without needing to retrain the generator. This formulation provides an implicit dense 3D reconstruction as it enables the image synthesis of novel shapes from arbitrary view angles and non-rigid structure. The method is built upon a sparse backbone, where a neural regressor is first trained to regress parameters describing the cameras and sparse non-rigid structure directly from the latent codes. The latent trajectories associated with changes in the camera and structure parameters are then identified by estimating the local inverse of the regressor in the neighborhood of a given latent code. The experiments show that our approach provides a versatile, systematic way to model, analyze, and edit the geometry and non-rigid structures of faces.
Seamlessly Integrating Factual Information and Social Content with Persuasive Dialogue
Mar 16, 2022
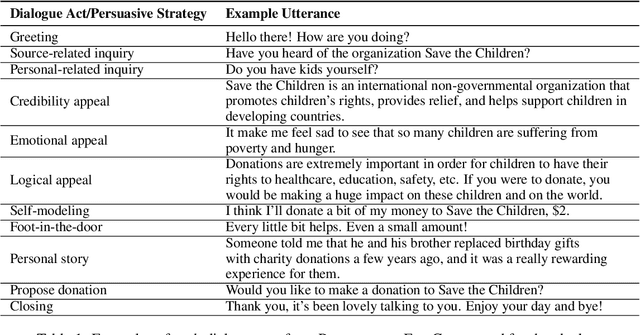
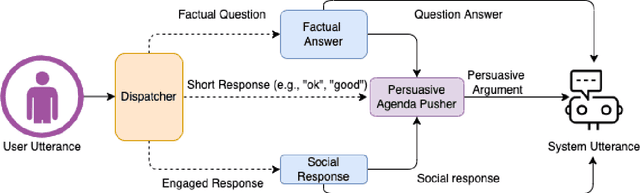
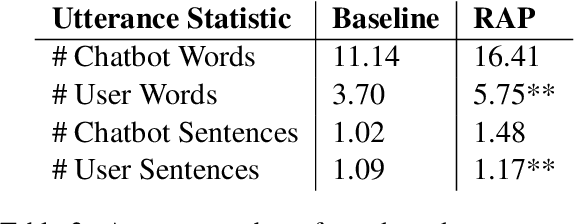
Effective human-chatbot conversations need to achieve both coherence and efficiency. Complex conversation settings such as persuasion involve communicating changes in attitude or behavior, so users' perspectives need to be carefully considered and addressed, even when not directly related to the topic. In this work, we contribute a novel modular dialogue system framework that seamlessly integrates factual information and social content into persuasive dialogue. Our framework is generalizable to any dialogue tasks that have mixed social and task contents. We conducted a study that compared user evaluations of our framework versus a baseline end-to-end generation model. We found our model was evaluated to be more favorable in all dimensions including competence and friendliness compared to the baseline model which does not explicitly handle social content or factual questions.
ReaRev: Adaptive Reasoning for Question Answering over Knowledge Graphs
Oct 24, 2022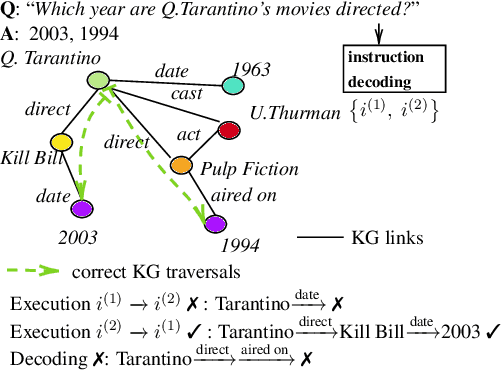
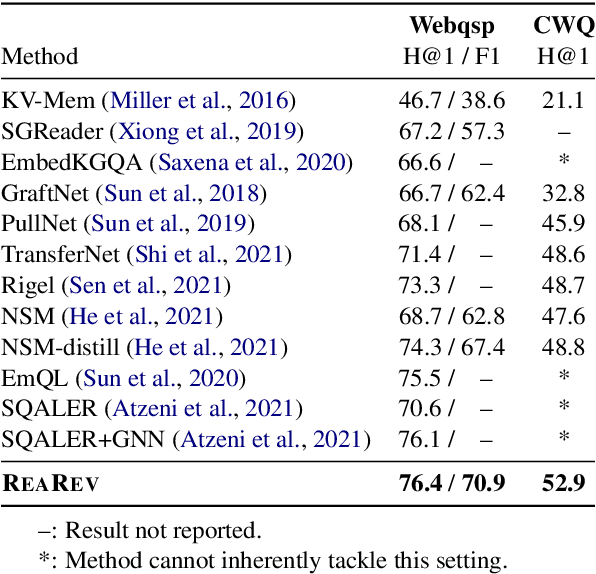
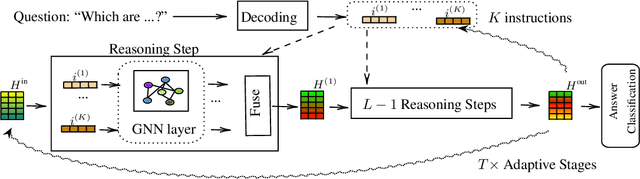
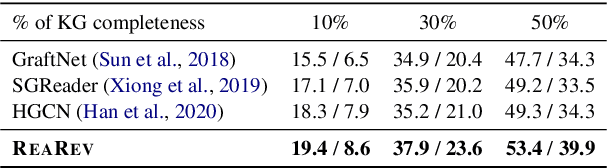
Knowledge Graph Question Answering (KGQA) involves retrieving entities as answers from a Knowledge Graph (KG) using natural language queries. The challenge is to learn to reason over question-relevant KG facts that traverse KG entities and lead to the question answers. To facilitate reasoning, the question is decoded into instructions, which are dense question representations used to guide the KG traversals. However, if the derived instructions do not exactly match the underlying KG information, they may lead to reasoning under irrelevant context. Our method, termed ReaRev, introduces a new way to KGQA reasoning with respect to both instruction decoding and execution. To improve instruction decoding, we perform reasoning in an adaptive manner, where KG-aware information is used to iteratively update the initial instructions. To improve instruction execution, we emulate breadth-first search (BFS) with graph neural networks (GNNs). The BFS strategy treats the instructions as a set and allows our method to decide on their execution order on the fly. Experimental results on three KGQA benchmarks demonstrate the ReaRev's effectiveness compared with previous state-of-the-art, especially when the KG is incomplete or when we tackle complex questions. Our code is publicly available at https://github.com/cmavro/ReaRev_KGQA.