 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Task2KB: A Public Task-Oriented Knowledge Base
Jan 24, 2023
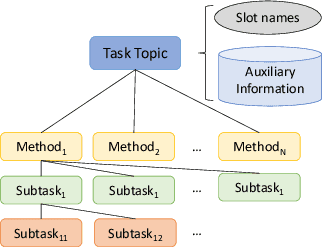
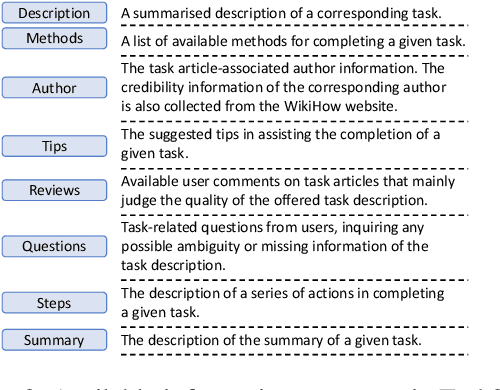
Search engines and conversational assistants are commonly used to help users complete their every day tasks such as booking travel, cooking, etc. While there are some existing datasets that can be used for this purpose, their coverage is limited to very few domains. In this paper, we propose a novel knowledge base, 'Task2KB', which is constructed using data crawled from WikiHow, an online knowledge resource offering instructional articles on a wide range of tasks. Task2KB encapsulates various types of task-related information and attributes, such as requirements, detailed step description, and available methods to complete tasks. Due to its higher coverage compared to existing related knowledge graphs, Task2KB can be highly useful in the development of general purpose task completion assistants
Preserving Fine-Grain Feature Information in Classification via Entropic Regularization
Aug 07, 2022
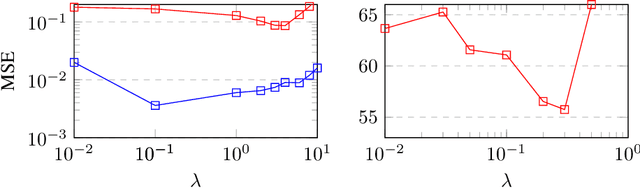
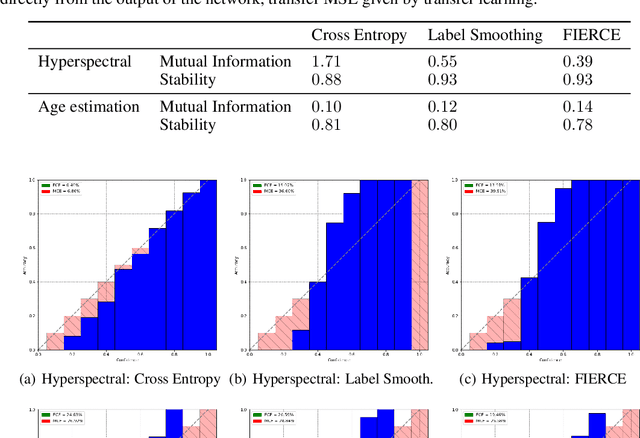

Labeling a classification dataset implies to define classes and associated coarse labels, that may approximate a smoother and more complicated ground truth. For example, natural images may contain multiple objects, only one of which is labeled in many vision datasets, or classes may result from the discretization of a regression problem. Using cross-entropy to train classification models on such coarse labels is likely to roughly cut through the feature space, potentially disregarding the most meaningful such features, in particular losing information on the underlying fine-grain task. In this paper we are interested in the problem of solving fine-grain classification or regression, using a model trained on coarse-grain labels only. We show that standard cross-entropy can lead to overfitting to coarse-related features. We introduce an entropy-based regularization to promote more diversity in the feature space of trained models, and empirically demonstrate the efficacy of this methodology to reach better performance on the fine-grain problems. Our results are supported through theoretical developments and empirical validation.
The Dependence of Parallel Imaging with Linear Predictability on the Undersampling Direction
Jan 18, 2023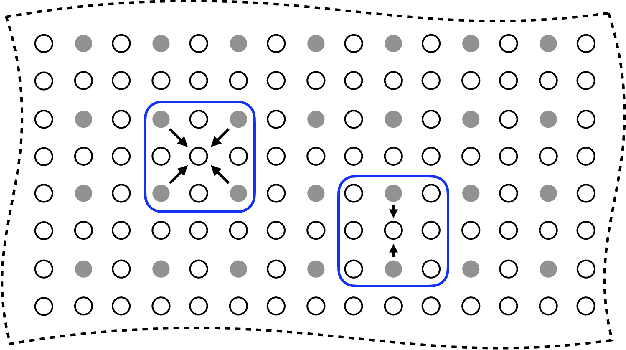
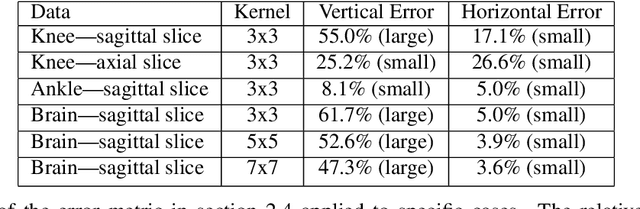
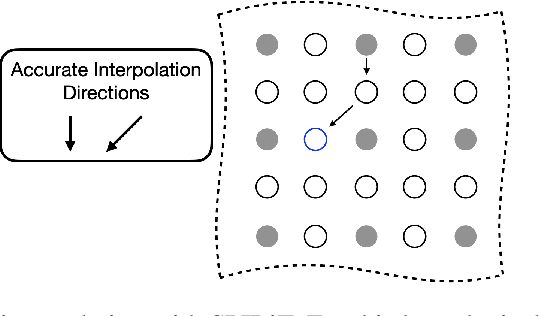
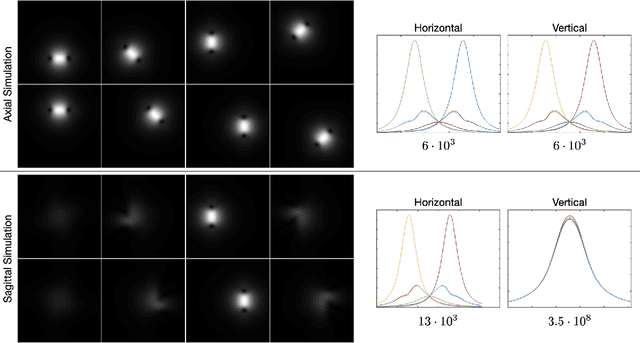
Parallel imaging with linear predictability takes advantage of information present in multiple receive coils to accurately reconstruct the image with fewer samples. Commonly used algorithms based on linear predictability include GRAPPA and SPIRiT. We present a sufficient condition for reconstruction based on the direction of undersampling and the arrangement of the sensing coils. This condition is justified theoretically and examples are shown using real data. We also propose a metric based on the fully-sampled auto-calibration region which can show which direction(s) of undersampling will allow for a good quality image reconstruction.
CoBigICP: Robust and Precise Point Set Registration using Correntropy Metrics and Bidirectional Correspondence
Jan 21, 2023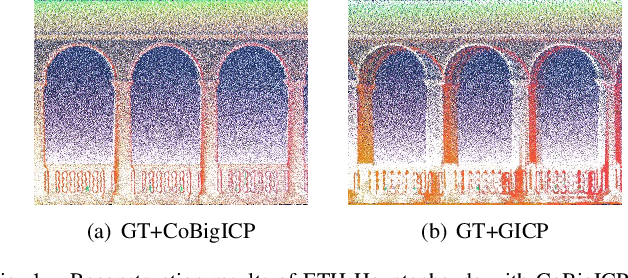
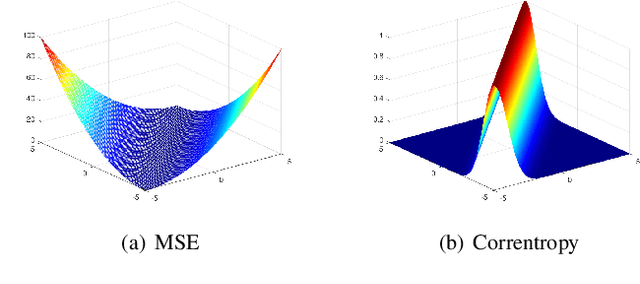
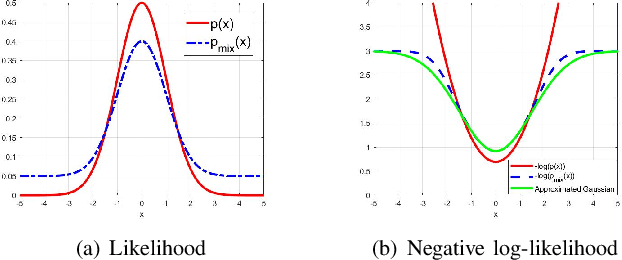
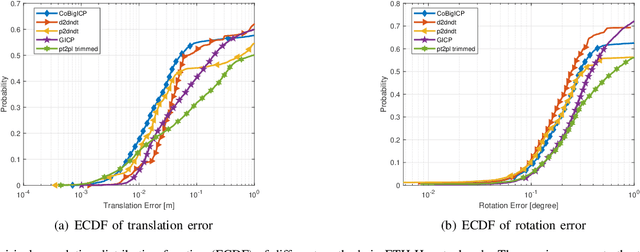
In this paper, we propose a novel probabilistic variant of iterative closest point (ICP) dubbed as CoBigICP. The method leverages both local geometrical information and global noise characteristics. Locally, the 3D structure of both target and source clouds are incorporated into the objective function through bidirectional correspondence. Globally, error metric of correntropy is introduced as noise model to resist outliers. Importantly, the close resemblance between normal-distributions transform (NDT) and correntropy is revealed. To ease the minimization step, an on-manifold parameterization of the special Euclidean group is proposed. Extensive experiments validate that CoBigICP outperforms several well-known and state-of-the-art methods.
Decentralized Multi-agent Filtering
Jan 21, 2023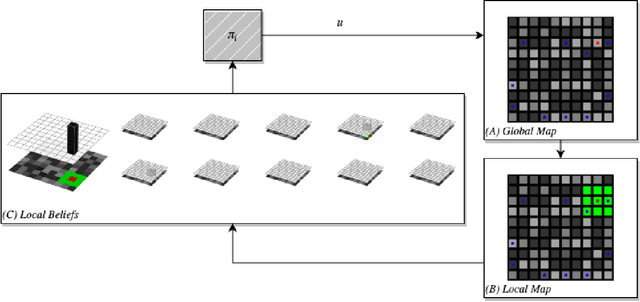
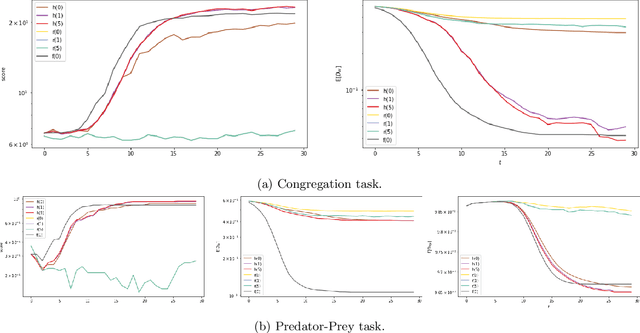
This paper addresses the considerations that comes along with adopting decentralized communication for multi-agent localization applications in discrete state spaces. In this framework, we extend the original formulation of the Bayes filter, a foundational probabilistic tool for discrete state estimation, by appending a step of greedy belief sharing as a method to propagate information and improve local estimates' posteriors. We apply our work in a model-based multi-agent grid-world setting, where each agent maintains a belief distribution for every agents' state. Our results affirm the utility of our proposed extensions for decentralized collaborative tasks. The code base for this work is available in the following repo
Encoding information in the mutual coherence of spatially separated light beams
Aug 02, 2022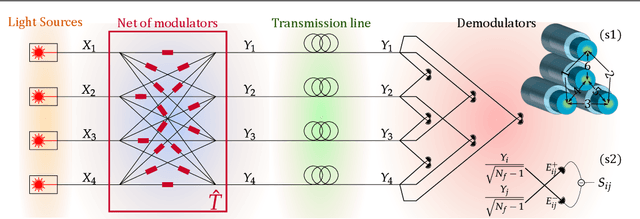
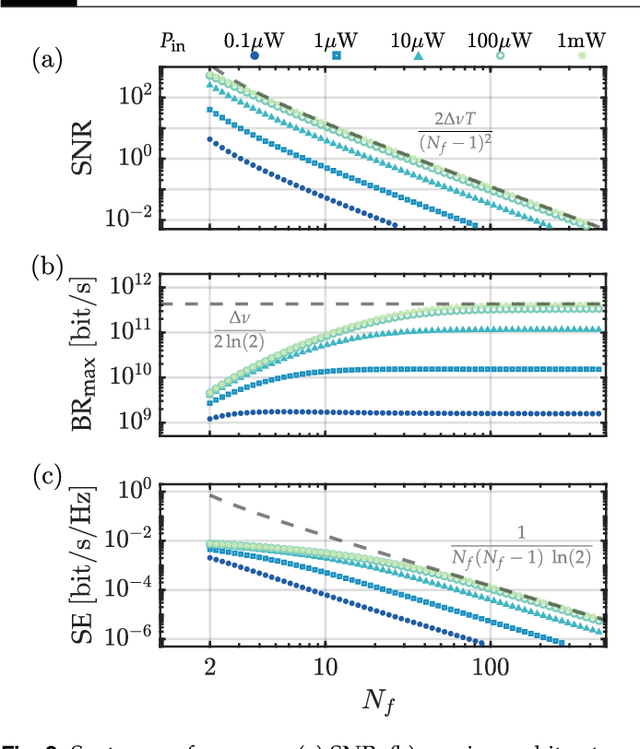
Coherence has been used as a resource for optical communications since its earliest days. It is widely used for multiplexing of data, but not for encoding of data. Here we introduce a coding scheme, which we call \textit{mutual coherence coding}, to encode information in the mutual coherence of spatially separated light beams. We describe its implementation and analyze its performance by deriving the relevant figures of merit (signal-to-noise ratio, maximum bit-rate, and spectral efficiency) with respect to the number of transmitted beams. Mutual coherence coding yields a quadratic scaling of the number of transmitted signals with the number of employed light beams, which might have benefits for cryptography and data security.
I See-Through You: A Framework for Removing Foreground Occlusion in Both Sparse and Dense Light Field Images
Jan 16, 2023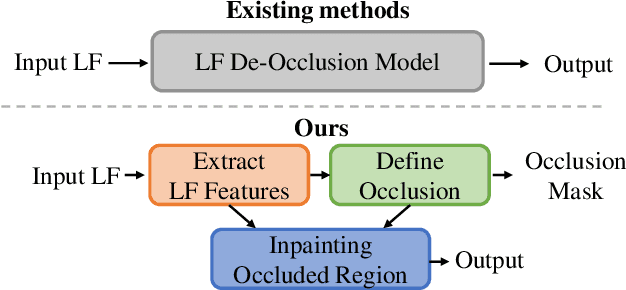

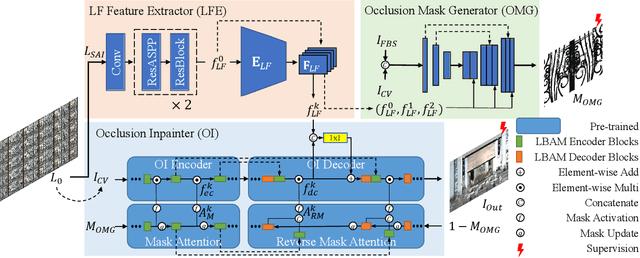

Light field (LF) camera captures rich information from a scene. Using the information, the LF de-occlusion (LF-DeOcc) task aims to reconstruct the occlusion-free center view image. Existing LF-DeOcc studies mainly focus on the sparsely sampled (sparse) LF images where most of the occluded regions are visible in other views due to the large disparity. In this paper, we expand LF-DeOcc in more challenging datasets, densely sampled (dense) LF images, which are taken by a micro-lens-based portable LF camera. Due to the small disparity ranges of dense LF images, most of the background regions are invisible in any view. To apply LF-DeOcc in both LF datasets, we propose a framework, ISTY, which is defined and divided into three roles: (1) extract LF features, (2) define the occlusion, and (3) inpaint occluded regions. By dividing the framework into three specialized components according to the roles, the development and analysis can be easier. Furthermore, an explainable intermediate representation, an occlusion mask, can be obtained in the proposed framework. The occlusion mask is useful for comprehensive analysis of the model and other applications by manipulating the mask. In experiments, qualitative and quantitative results show that the proposed framework outperforms state-of-the-art LF-DeOcc methods in both sparse and dense LF datasets.
Self-Evolutionary Reservoir Computer Based on Kuramoto Model
Jan 25, 2023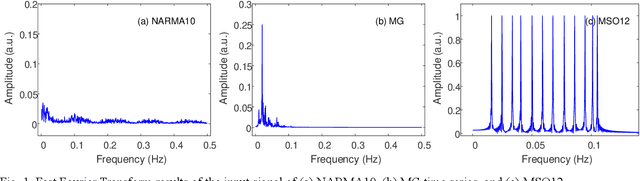
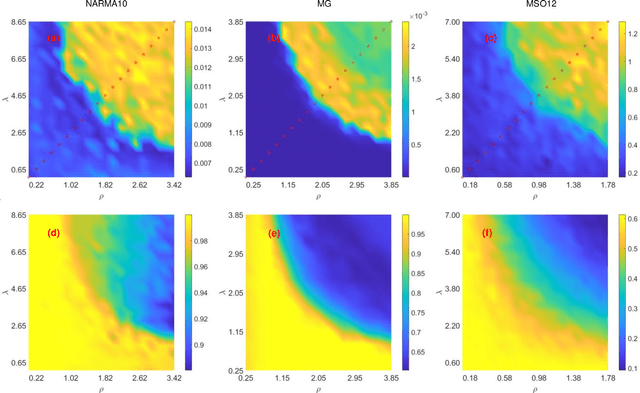
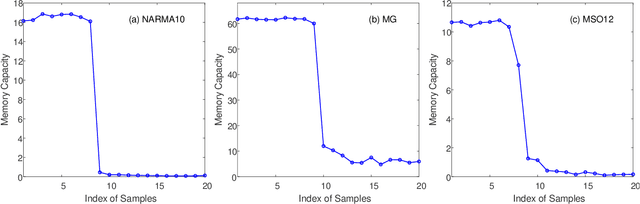
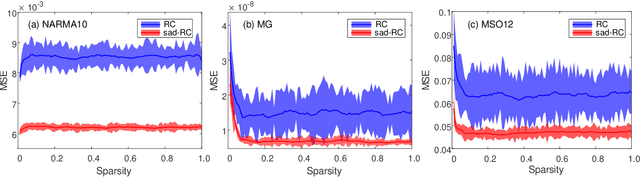
The human brain's synapses have remarkable activity-dependent plasticity, where the connectivity patterns of neurons change dramatically, relying on neuronal activities. As a biologically inspired neural network, reservoir computing (RC) has unique advantages in processing spatiotemporal information. However, typical reservoir architectures only take static random networks into account or consider the dynamics of neurons and connectivity separately. In this paper, we propose a structural autonomous development reservoir computing model (sad-RC), which structure can adapt to the specific problem at hand without any human expert knowledge. Specifically, we implement the reservoir by adaptive networks of phase oscillators, a commonly used model for synaptic plasticity in biological neural networks. In this co-evolving dynamic system, the dynamics of nodes and coupling weights in the reservoir constantly interact and evolve together when disturbed by external inputs.
Pre-screening breast cancer with machine learning and deep learning
Feb 05, 2023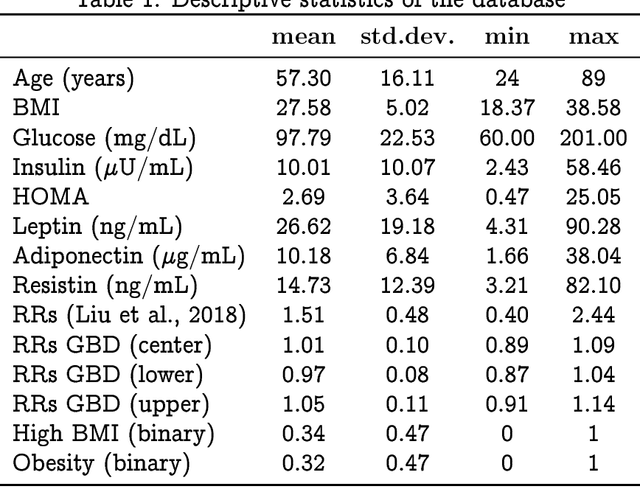
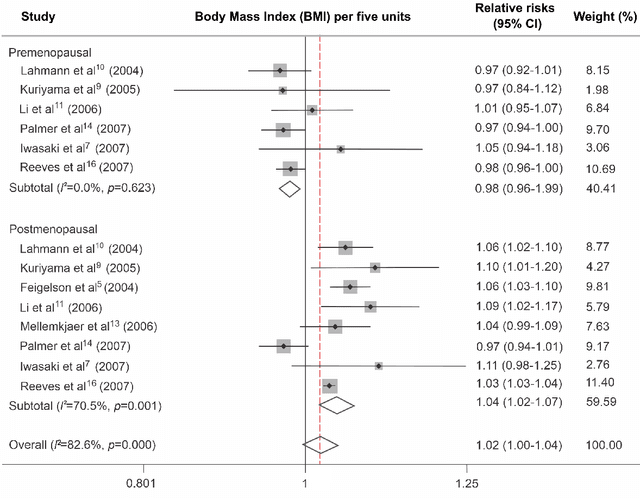
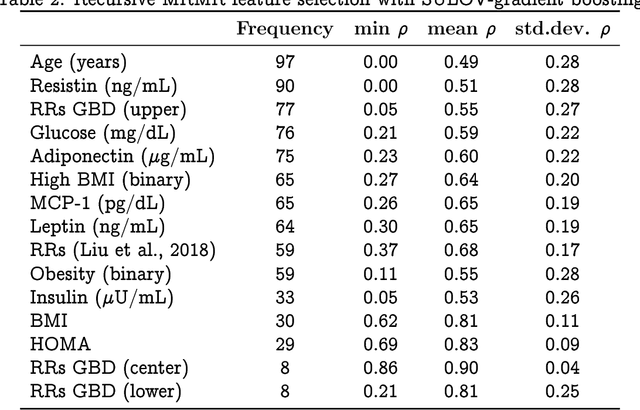
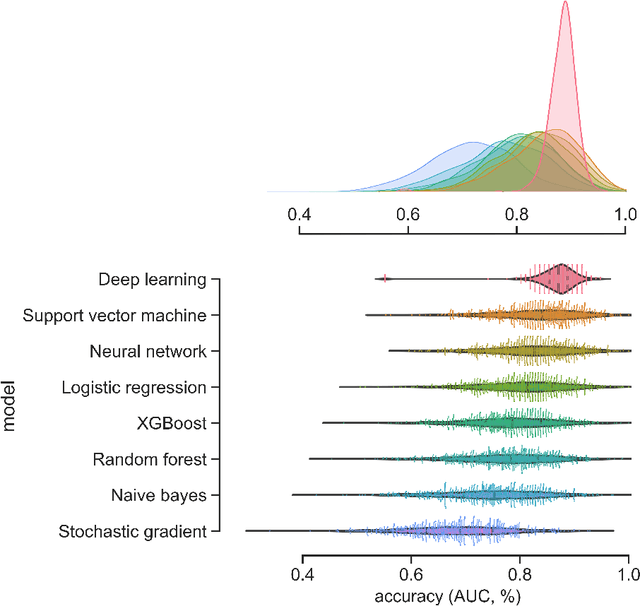
We suggest that deep learning can be used for pre-screening cancer by analyzing demographic and anthropometric information of patients, as well as biological markers obtained from routine blood samples and relative risks obtained from meta-analysis and international databases. We applied feature selection algorithms to a database of 116 women, including 52 healthy women and 64 women diagnosed with breast cancer, to identify the best pre-screening predictors of cancer. We utilized the best predictors to perform k-fold Monte Carlo cross-validation experiments that compare deep learning against traditional machine learning algorithms. Our results indicate that a deep learning model with an input-layer architecture that is fine-tuned using feature selection can effectively distinguish between patients with and without cancer. Additionally, compared to machine learning, deep learning has the lowest uncertainty in its predictions. These findings suggest that deep learning algorithms applied to cancer pre-screening offer a radiation-free, non-invasive, and affordable complement to screening methods based on imagery. The implementation of deep learning algorithms in cancer pre-screening offer opportunities to identify individuals who may require imaging-based screening, can encourage self-examination, and decrease the psychological externalities associated with false positives in cancer screening. The integration of deep learning algorithms for both screening and pre-screening will ultimately lead to earlier detection of malignancy, reducing the healthcare and societal burden associated to cancer treatment.
CIPER: Combining Invariant and Equivariant Representations Using Contrastive and Predictive Learning
Feb 05, 2023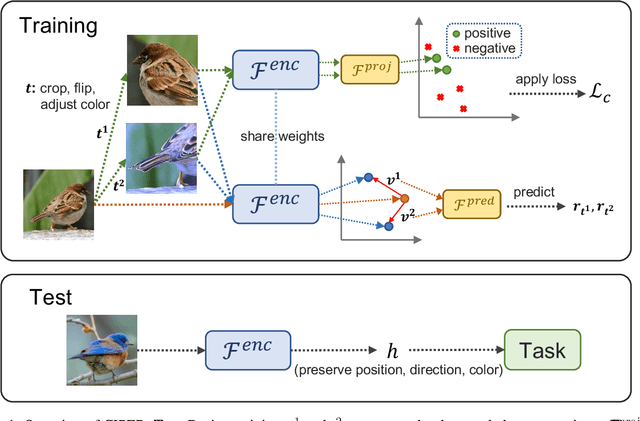


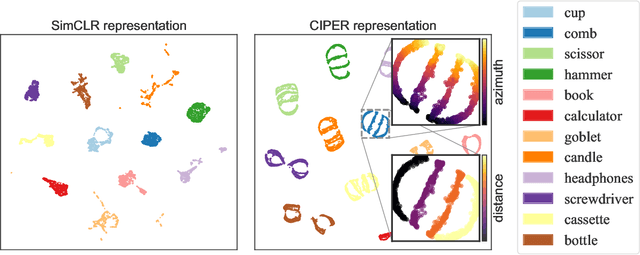
Self-supervised representation learning (SSRL) methods have shown great success in computer vision. In recent studies, augmentation-based contrastive learning methods have been proposed for learning representations that are invariant or equivariant to pre-defined data augmentation operations. However, invariant or equivariant features favor only specific downstream tasks depending on the augmentations chosen. They may result in poor performance when a downstream task requires the counterpart of those features (e.g., when the task is to recognize hand-written digits while the model learns to be invariant to in-plane image rotations rendering it incapable of distinguishing "9" from "6"). This work introduces Contrastive Invariant and Predictive Equivariant Representation learning (CIPER). CIPER comprises both invariant and equivariant learning objectives using one shared encoder and two different output heads on top of the encoder. One output head is a projection head with a state-of-the-art contrastive objective to encourage invariance to augmentations. The other is a prediction head estimating the augmentation parameters, capturing equivariant features. Both heads are discarded after training and only the encoder is used for downstream tasks. We evaluate our method on static image tasks and time-augmented image datasets. Our results show that CIPER outperforms a baseline contrastive method on various tasks, especially when the downstream task requires the encoding of augmentation-related information.