 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Domain Generalization in Fine-Tuning via Joint Parameter Selection
Aug 23, 2025Domain generalization seeks to develop models trained on a limited set of source domains that are capable of generalizing effectively to unseen target domains. While the predominant approach leverages large-scale pre-trained vision models as initialization, recent studies have highlighted that full fine-tuning can compromise the intrinsic generalization capabilities of these models. To address this limitation, parameter-efficient adaptation strategies have emerged, wherein only a subset of model parameters is selectively fine-tuned, thereby balancing task adaptation with the preservation of generalization. Motivated by this paradigm, we introduce Joint Parameter Selection (JPS), a novel method that restricts updates to a small, sparse subset of parameters, thereby retaining and harnessing the generalization strength of pre-trained models. Theoretically, we establish a generalization error bound that explicitly accounts for the sparsity of parameter updates, thereby providing a principled justification for selective fine-tuning. Practically, we design a selection mechanism employing dual operators to identify and update parameters exhibiting consistent and significant gradients across all source domains. Extensive benchmark experiments demonstrate that JPS achieves superior performance compared to state-of-the-art domain generalization methods, substantiating both the efficiency and efficacy of the proposed approach.
Multitemporal Latent Dynamical Framework for Hyperspectral Images Unmixing
May 27, 2025Multitemporal hyperspectral unmixing can capture dynamical evolution of materials. Despite its capability, current methods emphasize variability of endmembers while neglecting dynamics of abundances, which motivates our adoption of neural ordinary differential equations to model abundances temporally. However, this motivation is hindered by two challenges: the inherent complexity in defining, modeling and solving problem, and the absence of theoretical support. To address above challenges, in this paper, we propose a multitemporal latent dynamical (MiLD) unmixing framework by capturing dynamical evolution of materials with theoretical validation. For addressing multitemporal hyperspectral unmixing, MiLD consists of problem definition, mathematical modeling, solution algorithm and theoretical support. We formulate multitemporal unmixing problem definition by conducting ordinary differential equations and developing latent variables. We transfer multitemporal unmixing to mathematical model by dynamical discretization approaches, which describe the discreteness of observed sequence images with mathematical expansions. We propose algorithm to solve problem and capture dynamics of materials, which approximates abundance evolution by neural networks. Furthermore, we provide theoretical support by validating the crucial properties, which verifies consistency, convergence and stability theorems. The major contributions of MiLD include defining problem by ordinary differential equations, modeling problem by dynamical discretization approach, solving problem by multitemporal unmixing algorithm, and presenting theoretical support. Our experiments on both synthetic and real datasets have validated the utility of our work
Transformer for Multitemporal Hyperspectral Image Unmixing
Jul 15, 2024



Multitemporal hyperspectral image unmixing (MTHU) holds significant importance in monitoring and analyzing the dynamic changes of surface. However, compared to single-temporal unmixing, the multitemporal approach demands comprehensive consideration of information across different phases, rendering it a greater challenge. To address this challenge, we propose the Multitemporal Hyperspectral Image Unmixing Transformer (MUFormer), an end-to-end unsupervised deep learning model. To effectively perform multitemporal hyperspectral image unmixing, we introduce two key modules: the Global Awareness Module (GAM) and the Change Enhancement Module (CEM). The Global Awareness Module computes self-attention across all phases, facilitating global weight allocation. On the other hand, the Change Enhancement Module dynamically learns local temporal changes by comparing endmember changes between adjacent phases. The synergy between these modules allows for capturing semantic information regarding endmember and abundance changes, thereby enhancing the effectiveness of multitemporal hyperspectral image unmixing. We conducted experiments on one real dataset and two synthetic datasets, demonstrating that our model significantly enhances the effect of multitemporal hyperspectral image unmixing.
CIPER: Combining Invariant and Equivariant Representations Using Contrastive and Predictive Learning
Feb 05, 2023Self-supervised representation learning (SSRL) methods have shown great success in computer vision. In recent studies, augmentation-based contrastive learning methods have been proposed for learning representations that are invariant or equivariant to pre-defined data augmentation operations. However, invariant or equivariant features favor only specific downstream tasks depending on the augmentations chosen. They may result in poor performance when a downstream task requires the counterpart of those features (e.g., when the task is to recognize hand-written digits while the model learns to be invariant to in-plane image rotations rendering it incapable of distinguishing "9" from "6"). This work introduces Contrastive Invariant and Predictive Equivariant Representation learning (CIPER). CIPER comprises both invariant and equivariant learning objectives using one shared encoder and two different output heads on top of the encoder. One output head is a projection head with a state-of-the-art contrastive objective to encourage invariance to augmentations. The other is a prediction head estimating the augmentation parameters, capturing equivariant features. Both heads are discarded after training and only the encoder is used for downstream tasks. We evaluate our method on static image tasks and time-augmented image datasets. Our results show that CIPER outperforms a baseline contrastive method on various tasks, especially when the downstream task requires the encoding of augmentation-related information.
SRDA-Net: Super-Resolution Domain Adaptation Networks for Semantic Segmentation
May 21, 2020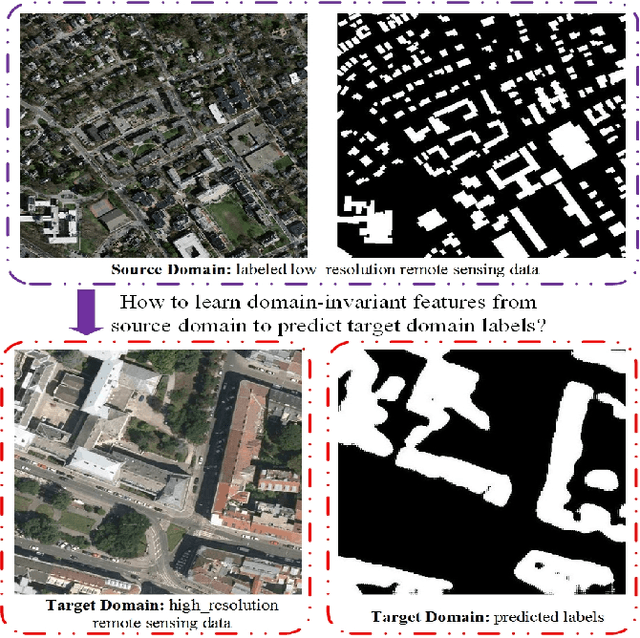
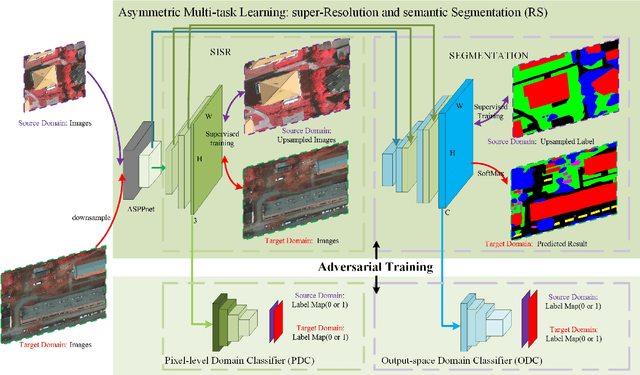

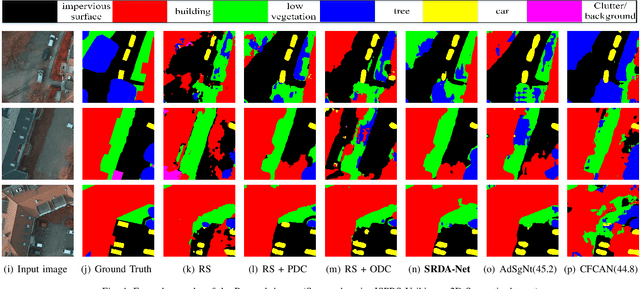
Recently, Unsupervised Domain Adaptation was proposed to address the domain shift problem in semantic segmentation task, but it may perform poor when source and target domains belong to different resolutions. In this work, we design a novel end-to-end semantic segmentation network, Super-Resolution Domain Adaptation Network (SRDA-Net), which could simultaneously complete super-resolution and domain adaptation. Such characteristics exactly meet the requirement of semantic segmentation for remote sensing images which usually involve various resolutions. Generally, SRDA-Net includes three deep neural networks: a Super-Resolution and Segmentation (SRS) model focuses on recovering high-resolution image and predicting segmentation map; a pixel-level domain classifier (PDC) tries to distinguish the images from which domains; and output-space domain classifier (ODC) discriminates pixel label distributions from which domains. PDC and ODC are considered as the discriminators, and SRS is treated as the generator. By the adversarial learning, SRS tries to align the source with target domains on pixel-level visual appearance and output-space. Experiments are conducted on the two remote sensing datasets with different resolutions. SRDA-Net performs favorably against the state-of-the-art methods in terms of accuracy and visual quality. Code and models are available at https://github.com/tangzhenjie/SRDA-Net.