 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated electro-optic attention nonlinearities for transformers
Apr 10, 2026Transformers have emerged as the dominant neural-network architecture, achieving state-of-the-art performance in language processing and computer vision. At the core of these models lies the attention mechanism, which requires a nonlinear, non-negative mapping using the Softmax function. However, although Softmax operations account for less than 1% of the total operation count, they can disproportionately bottleneck overall inference latency. Here, we use thin-film lithium niobate (TFLN) Mach-Zehnder modulators (MZMs) as analog nonlinear computational elements to drastically reduce the latency of nonlinear computations. We implement electro-optic alternatives to digital Softmax and Sigmoid, and evaluate their performance in Vision Transformers and Large Language Models. Our system maintains highly competitive accuracy, even under aggressive 4-bit input-output quantization of the analog units. We further characterize system noise at encoding speeds up to 10 GBaud and assess model robustness under various noise conditions. Our findings suggest that TFLN modulators can serve as nonlinear function units within hybrid co-packaged hardware, enabling high-speed and energy-efficient nonlinear computation.
Encoding information in the mutual coherence of spatially separated light beams
Aug 02, 2022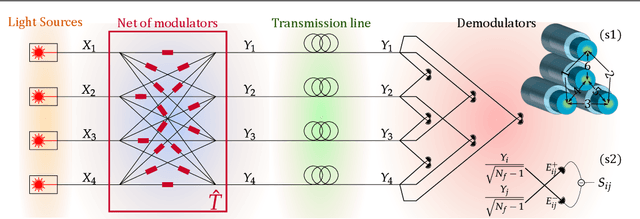
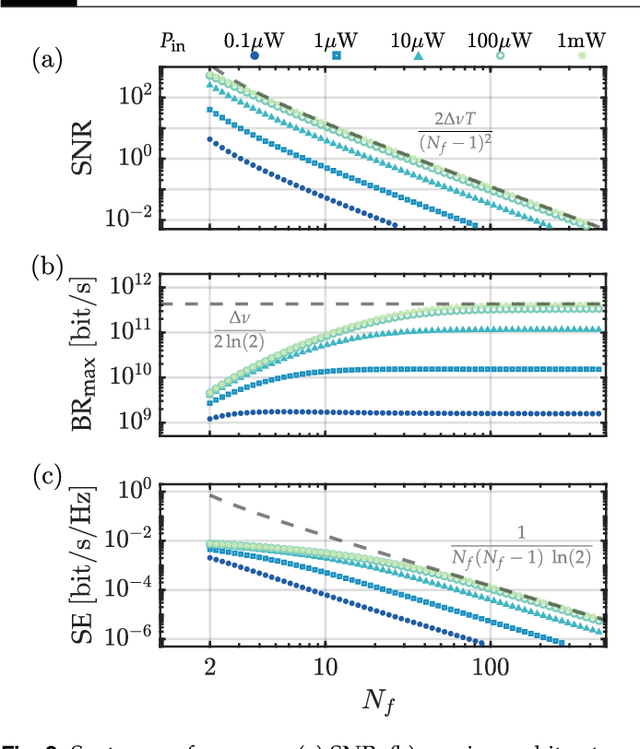
Coherence has been used as a resource for optical communications since its earliest days. It is widely used for multiplexing of data, but not for encoding of data. Here we introduce a coding scheme, which we call \textit{mutual coherence coding}, to encode information in the mutual coherence of spatially separated light beams. We describe its implementation and analyze its performance by deriving the relevant figures of merit (signal-to-noise ratio, maximum bit-rate, and spectral efficiency) with respect to the number of transmitted beams. Mutual coherence coding yields a quadratic scaling of the number of transmitted signals with the number of employed light beams, which might have benefits for cryptography and data security.