 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Explainable Action Prediction through Self-Supervision on Scene Graphs
Feb 07, 2023
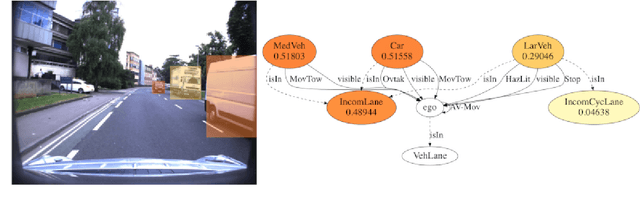
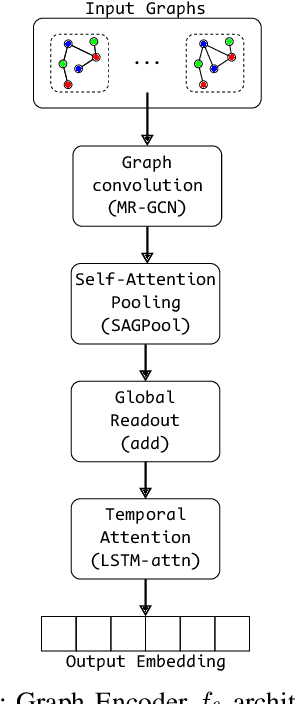
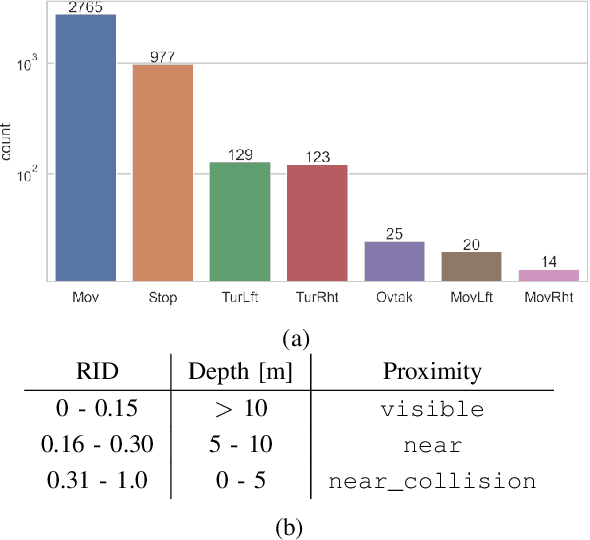
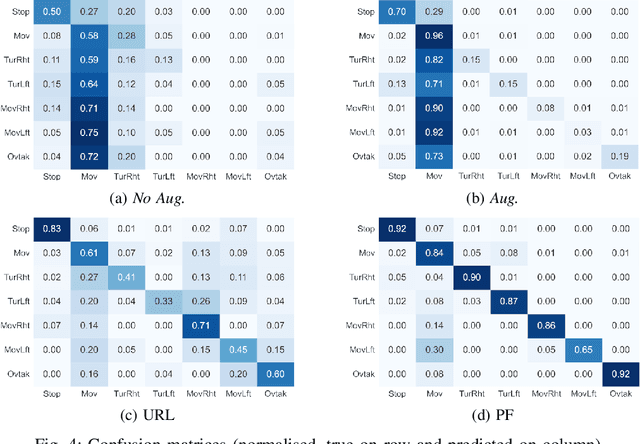
This work explores scene graphs as a distilled representation of high-level information for autonomous driving, applied to future driver-action prediction. Given the scarcity and strong imbalance of data samples, we propose a self-supervision pipeline to infer representative and well-separated embeddings. Key aspects are interpretability and explainability; as such, we embed in our architecture attention mechanisms that can create spatial and temporal heatmaps on the scene graphs. We evaluate our system on the ROAD dataset against a fully-supervised approach, showing the superiority of our training regime.
Linear Partial Monitoring for Sequential Decision-Making: Algorithms, Regret Bounds and Applications
Feb 07, 2023
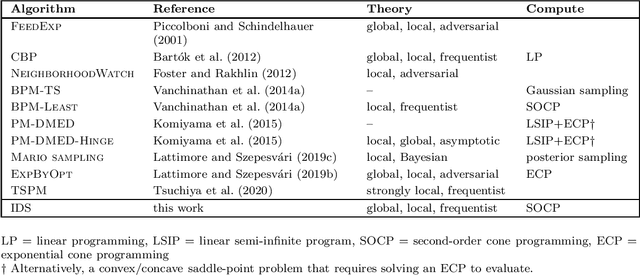
Partial monitoring is an expressive framework for sequential decision-making with an abundance of applications, including graph-structured and dueling bandits, dynamic pricing and transductive feedback models. We survey and extend recent results on the linear formulation of partial monitoring that naturally generalizes the standard linear bandit setting. The main result is that a single algorithm, information-directed sampling (IDS), is (nearly) worst-case rate optimal in all finite-action games. We present a simple and unified analysis of stochastic partial monitoring, and further extend the model to the contextual and kernelized setting.
Cluster-based Deep Ensemble Learning for Emotion Classification in Internet Memes
Feb 16, 2023
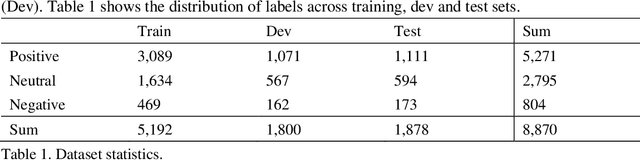
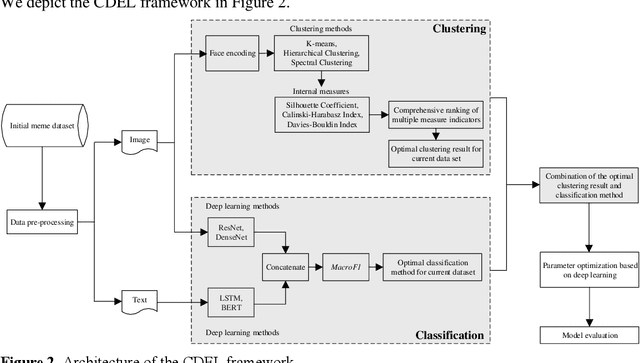

Memes have gained popularity as a means to share visual ideas through the Internet and social media by mixing text, images and videos, often for humorous purposes. Research enabling automated analysis of memes has gained attention in recent years, including among others the task of classifying the emotion expressed in memes. In this paper, we propose a novel model, cluster-based deep ensemble learning (CDEL), for emotion classification in memes. CDEL is a hybrid model that leverages the benefits of a deep learning model in combination with a clustering algorithm, which enhances the model with additional information after clustering memes with similar facial features. We evaluate the performance of CDEL on a benchmark dataset for emotion classification, proving its effectiveness by outperforming a wide range of baseline models and achieving state-of-the-art performance. Further evaluation through ablated models demonstrates the effectiveness of the different components of CDEL.
Nanoscale Imaging of Super-High-Frequency Microelectromechanical Resonators with Femtometer Sensitivity
Feb 16, 2023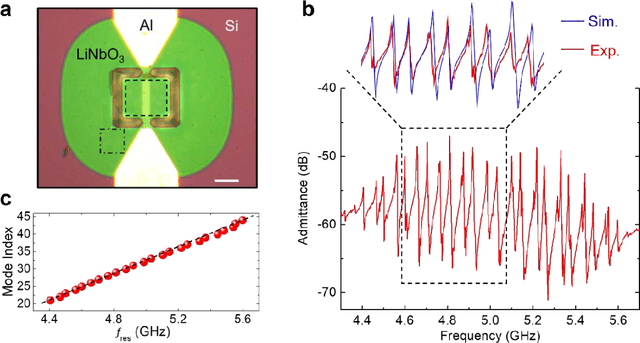
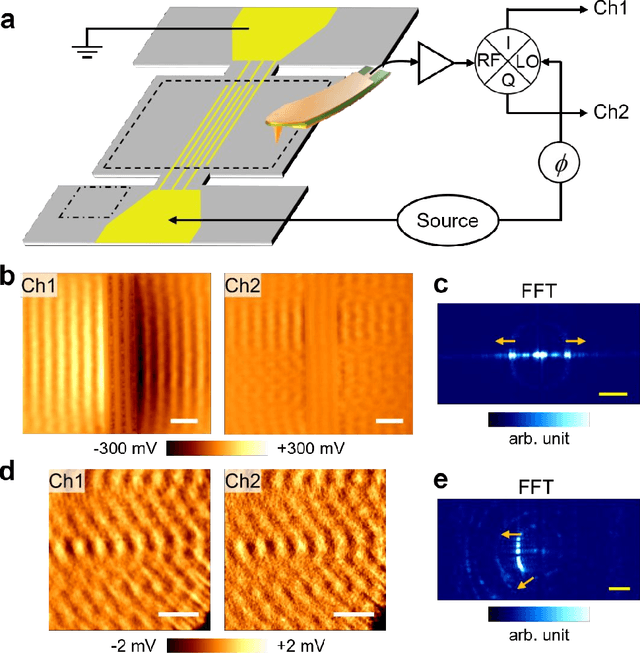
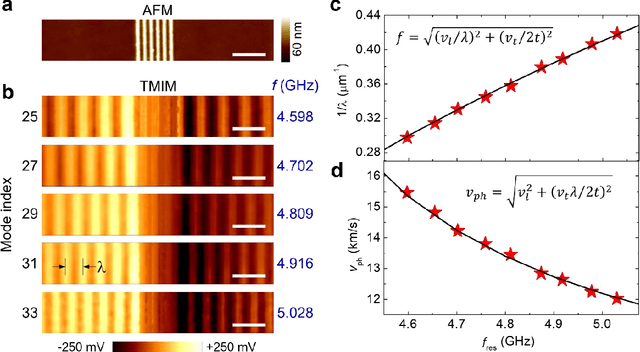
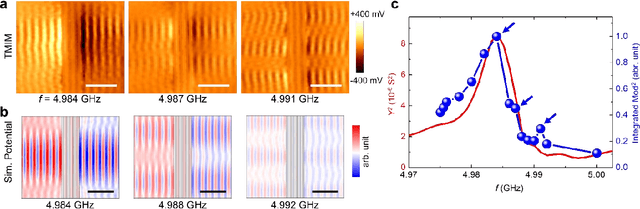
Implementing microelectromechanical system (MEMS) resonators calls for detailed microscopic understanding of the devices, such as energy dissipation channels, spurious modes, and imperfections from microfabrication. Here, we report the nanoscale imaging of a freestanding super-high-frequency (3 ~ 30 GHz) lateral overtone bulk acoustic resonator with unprecedented spatial resolution and displacement sensitivity. Using transmission-mode microwave impedance microscopy, we have visualized mode profiles of individual overtones and analyzed higher-order transverse spurious modes and anchor loss. The integrated TMIM signals are in good agreement with the stored mechanical energy in the resonator. Quantitative analysis with finite-element modeling shows that the noise floor is equivalent to an in-plane displacement of 10 fm/sqrt(Hz) at room temperatures, which can be further improved under cryogenic environments. Our work contributes to the design and characterization of MEMS resonators with better performance for telecommunication, sensing, and quantum information science applications.
VTrackIt: A Synthetic Self-Driving Dataset with Infrastructure and Pooled Vehicle Information
Jul 15, 2022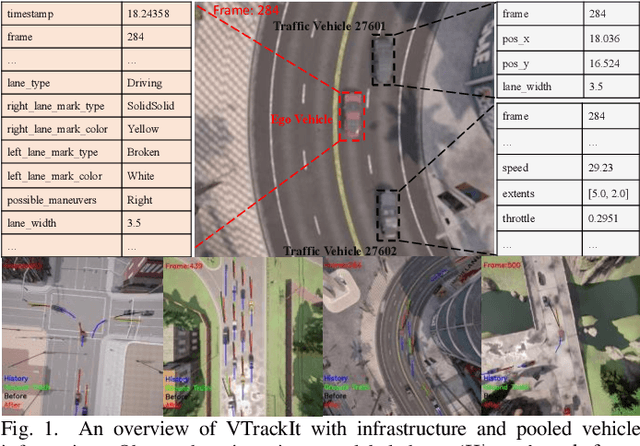
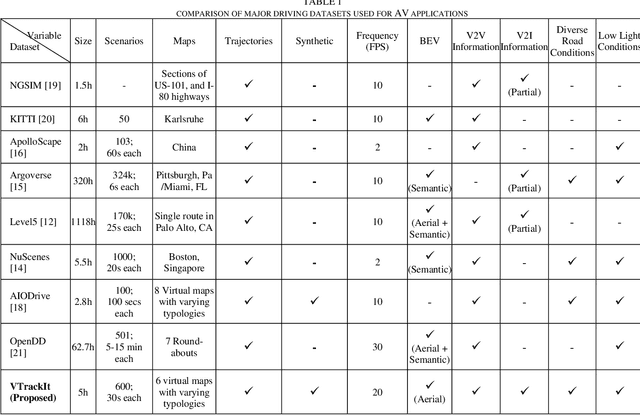
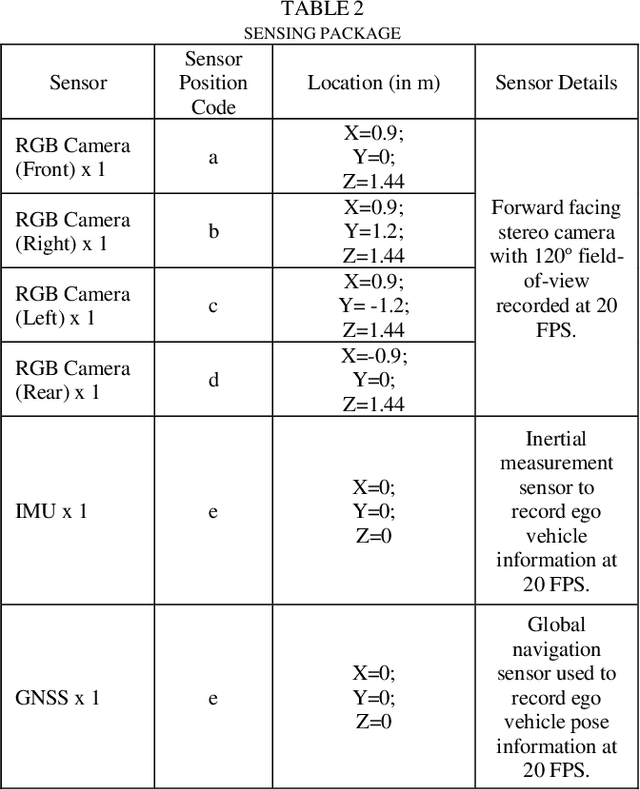
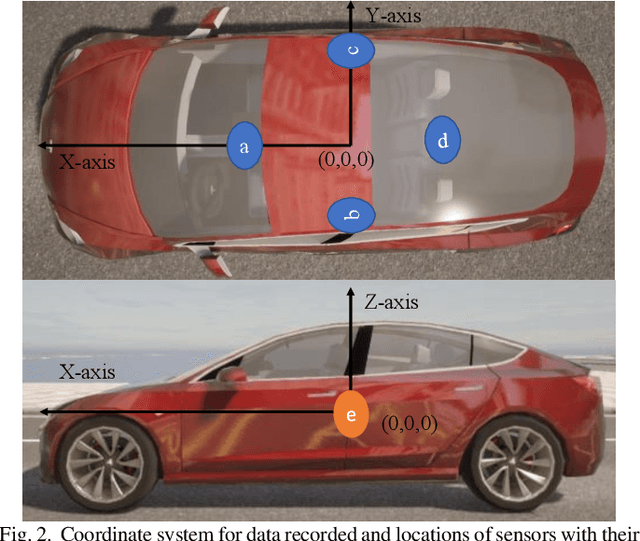
Artificial intelligence solutions for Autonomous Vehicles (AVs) have been developed using publicly available datasets such as Argoverse, ApolloScape, Level5, and NuScenes. One major limitation of these datasets is the absence of infrastructure and/or pooled vehicle information like lane line type, vehicle speed, traffic signs, and intersections. Such information is necessary and not complementary to eliminating high-risk edge cases. The rapid advancements in Vehicle-to-Infrastructure and Vehicle-to-Vehicle technologies show promise that infrastructure and pooled vehicle information will soon be accessible in near real-time. Taking a leap in the future, we introduce the first comprehensive synthetic dataset with intelligent infrastructure and pooled vehicle information for advancing the next generation of AVs, named VTrackIt. We also introduce the first deep learning model (InfraGAN) for trajectory predictions that considers such information. Our experiments with InfraGAN show that the comprehensive information offered by VTrackIt reduces the number of high-risk edge cases. The VTrackIt dataset is available upon request under the Creative Commons CC BY-NC-SA 4.0 license at http://vtrackit.irda.club.
Designing a 3D-Aware StyleNeRF Encoder for Face Editing
Feb 19, 2023
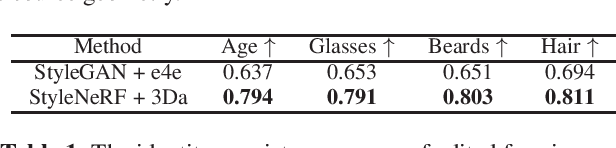
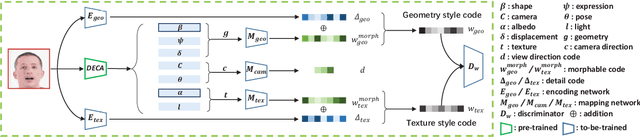
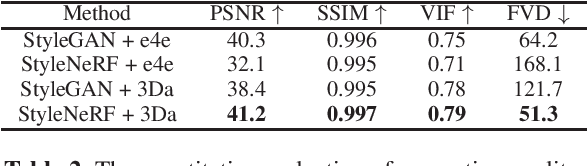
GAN inversion has been exploited in many face manipulation tasks, but 2D GANs often fail to generate multi-view 3D consistent images. The encoders designed for 2D GANs are not able to provide sufficient 3D information for the inversion and editing. Therefore, 3D-aware GAN inversion is proposed to increase the 3D editing capability of GANs. However, the 3D-aware GAN inversion remains under-explored. To tackle this problem, we propose a 3D-aware (3Da) encoder for GAN inversion and face editing based on the powerful StyleNeRF model. Our proposed 3Da encoder combines a parametric 3D face model with a learnable detail representation model to generate geometry, texture and view direction codes. For more flexible face manipulation, we then design a dual-branch StyleFlow module to transfer the StyleNeRF codes with disentangled geometry and texture flows. Extensive experiments demonstrate that we realize 3D consistent face manipulation in both facial attribute editing and texture transfer. Furthermore, for video editing, we make the sequence of frame codes share a common canonical manifold, which improves the temporal consistency of the edited attributes.
Rank-Minimizing and Structured Model Inference
Feb 19, 2023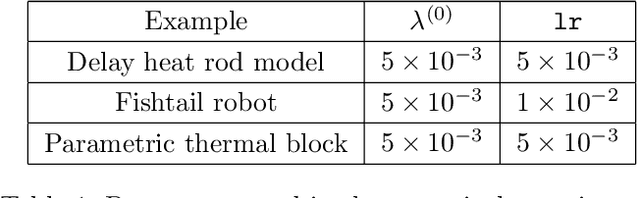
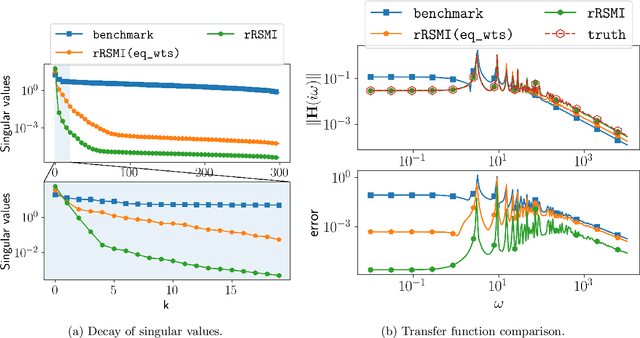
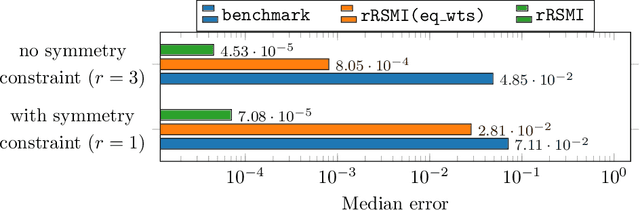
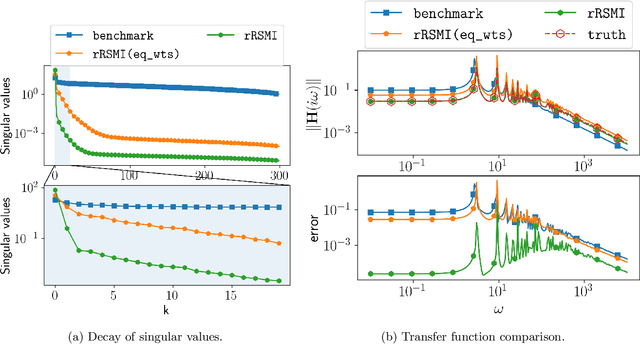
While extracting information from data with machine learning plays an increasingly important role, physical laws and other first principles continue to provide critical insights about systems and processes of interest in science and engineering. This work introduces a method that infers models from data with physical insights encoded in the form of structure and that minimizes the model order so that the training data are fitted well while redundant degrees of freedom without conditions and sufficient data to fix them are automatically eliminated. The models are formulated via solution matrices of specific instances of generalized Sylvester equations that enforce interpolation of the training data and relate the model order to the rank of the solution matrices. The proposed method numerically solves the Sylvester equations for minimal-rank solutions and so obtains models of low order. Numerical experiments demonstrate that the combination of structure preservation and rank minimization leads to accurate models with orders of magnitude fewer degrees of freedom than models of comparable prediction quality that are learned with structure preservation alone.
A Neuromorphic Dataset for Object Segmentation in Indoor Cluttered Environment
Feb 17, 2023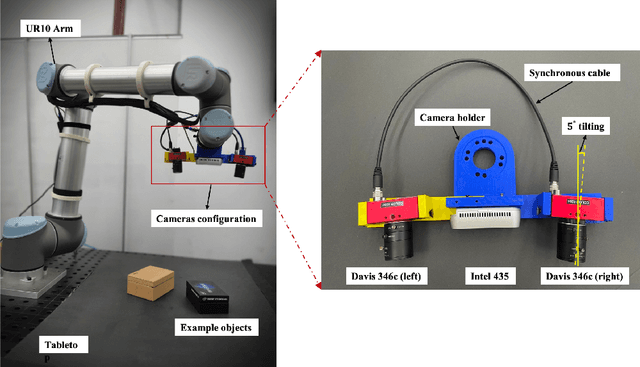
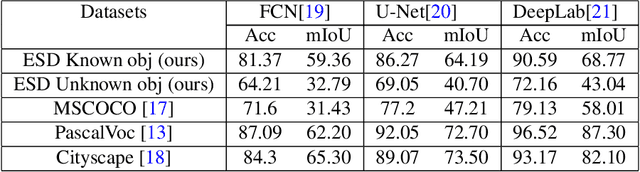

Taking advantage of an event-based camera, the issues of motion blur, low dynamic range and low time sampling of standard cameras can all be addressed. However, there is a lack of event-based datasets dedicated to the benchmarking of segmentation algorithms, especially those that provide depth information which is critical for segmentation in occluded scenes. This paper proposes a new Event-based Segmentation Dataset (ESD), a high-quality 3D spatial and temporal dataset for object segmentation in an indoor cluttered environment. Our proposed dataset ESD comprises 145 sequences with 14,166 RGB frames that are manually annotated with instance masks. Overall 21.88 million and 20.80 million events from two event-based cameras in a stereo-graphic configuration are collected, respectively. To the best of our knowledge, this densely annotated and 3D spatial-temporal event-based segmentation benchmark of tabletop objects is the first of its kind. By releasing ESD, we expect to provide the community with a challenging segmentation benchmark with high quality.
Efficiently Forgetting What You Have Learned in Graph Representation Learning via Projection
Feb 17, 2023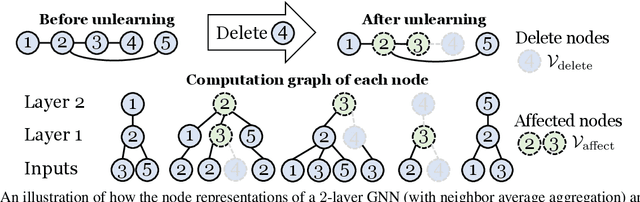
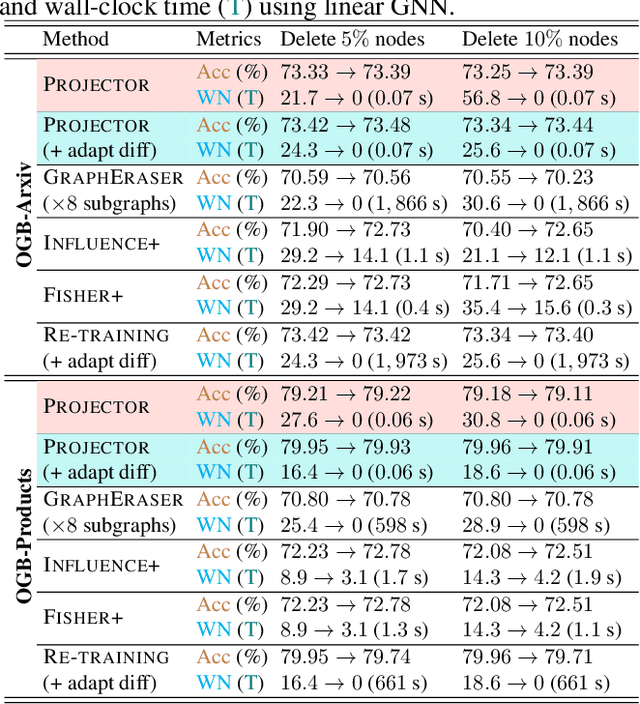
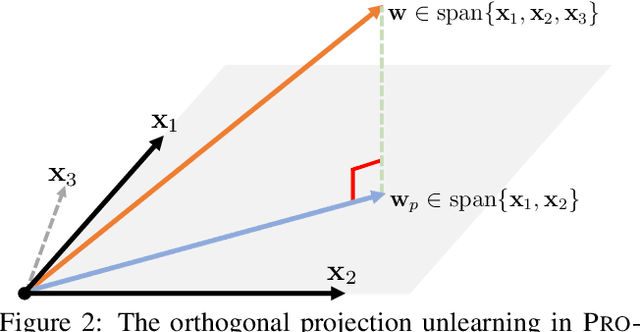

As privacy protection receives much attention, unlearning the effect of a specific node from a pre-trained graph learning model has become equally important. However, due to the node dependency in the graph-structured data, representation unlearning in Graph Neural Networks (GNNs) is challenging and less well explored. In this paper, we fill in this gap by first studying the unlearning problem in linear-GNNs, and then introducing its extension to non-linear structures. Given a set of nodes to unlearn, we propose PROJECTOR that unlearns by projecting the weight parameters of the pre-trained model onto a subspace that is irrelevant to features of the nodes to be forgotten. PROJECTOR could overcome the challenges caused by node dependency and enjoys a perfect data removal, i.e., the unlearned model parameters do not contain any information about the unlearned node features which is guaranteed by algorithmic construction. Empirical results on real-world datasets illustrate the effectiveness and efficiency of PROJECTOR.
Sleep Model -- A Sequence Model for Predicting the Next Sleep Stage
Feb 17, 2023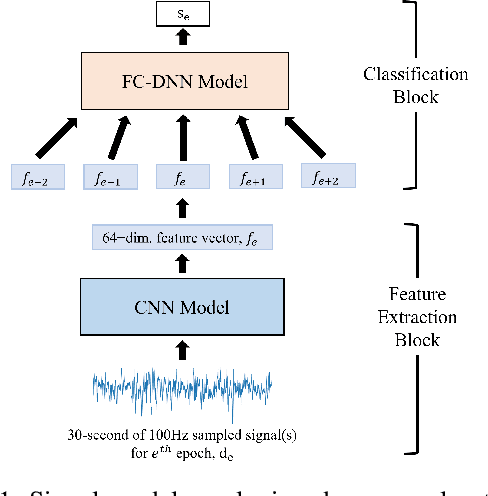
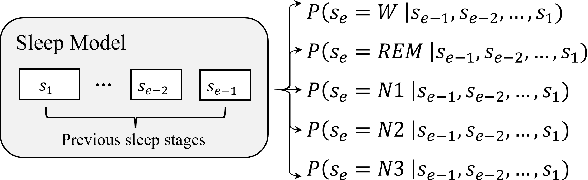
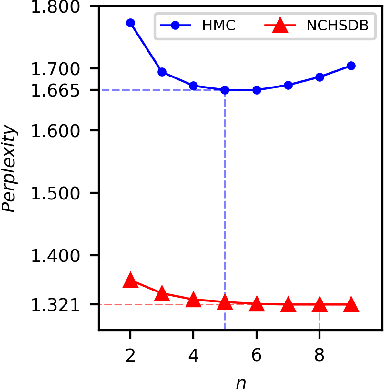
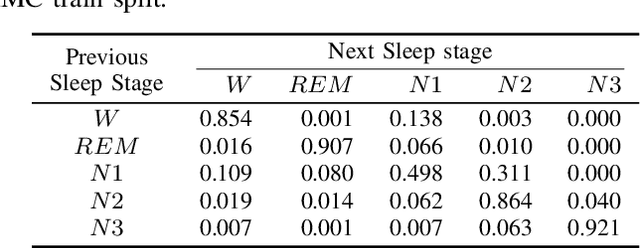
As sleep disorders are becoming more prevalent there is an urgent need to classify sleep stages in a less disturbing way.In particular, sleep-stage classification using simple sensors, such as single-channel electroencephalography (EEG), electrooculography (EOG), electromyography (EMG), or electrocardiography (ECG) has gained substantial interest. In this study, we proposed a sleep model that predicts the next sleep stage and used it to improve sleep classification accuracy. The sleep models were built using sleep-sequence data and employed either statistical $n$-gram or deep neural network-based models. We developed beam-search decoding to combine the information from the sensor and the sleep models. Furthermore, we evaluated the performance of the $n$-gram and long short-term memory (LSTM) recurrent neural network (RNN)-based sleep models and demonstrated the improvement of sleep-stage classification using an EOG sensor. The developed sleep models significantly improved the accuracy of sleep-stage classification, particularly in the absence of an EEG sensor.